
개요
영화 리뷰 및 소셜 플랫폼 서비스 개발 당시 영화 검색 기능을 구현했다. 검색에 자동완성 기능까지 붙이려했었다. 개발할 때부터 MySQL로는 무리가 아닐까 생각헀지만 n-gram이라는 기능을 한 번 써보고 싶었기 때문에 우선 MySQL로 검색기능을 구현했다. 하지만 역시나 만족할만한 성능이 나오지 않았고, ElasticSearch를 도입하였다.
결론을 말하자면 속도가 약 4배 상승했으며 오타보정 및 자동완성 기능까지 붙일 수 있었기에 만족했다.
기술 소개
MySQL n-gram
MySQL에는 full-text parser가 내장되어 있다. 이는 fulltext 인덱스를 사용해 텍스트를 검색할 때 입력된 텍스트를 토큰으로 나누는 기능이다. 이는 띄어쓰기를 기준으로 단어의 시작과 끝을 파악하기 때문에 영어같은 언어에는 적합하다. 하지만 한국어의 경우에는 띄어쓰기만으로 텍스트를 토큰화하기 어려우므로 이는 우리가 원하는 검색 기능을 구현하기에 부적합하다.
한국어, 중국어, 일본어 같은 언어를 위해 MySQL에는 n-gram이라는 기능 또한 내장되어 있다. 이는 미리 설정해둔 토큰화 단위에 따라 단어를 토큰화 한다.
예를 들어 ‘abcd’라는 단어의 경우
n=1: 'a', 'b', 'c', 'd'
n=2: 'ab', 'bc', 'cd'
n=3: 'abc', 'bcd'
n=4: 'abcd'
로 분석된다.
만약 한 글자라도 일치하면 검색결과를 내고싶다면 토큰화 단위를 1로 설정하면 된다.
설정 방법은 아래를 콘솔에서 명령하면 된다.
mysqld --ngram_token_size=1
ElasticSearch (이하 ES)
분산형 검색 및 분석 엔진
데이터베이스처럼 사용할 수 있지만 검색과 분석에 특화된 도구
이렇게 속도가 빠를 수 있는 이유는 역색인(inverted index) 구조를 사용하기 때문이다. 이는 단어 중심으로 인덱스를 만드는 방법을 말한다. (MySQL은 행 구조)
MySQL에서 특정 단어를 검색을 하면 모든 행을 읽어가며 해당 단어가 포함되어있는지 검사한다. 하지만 역색인 방식은 단어별로 인덱스를 생성하기 때문에 속도가 높다.
역색인
나는 처음에 이 개념이 이해가 좀 안 됐다.
쉽게 말하자면, 각 단어를 key로, 그 단어가 포함된 문서 ID값을 value로 저장하는 방식이다.
예를 들어
- 나는 강아지를 좋아해
- 나는 고양이를 좋아해
- 강아지와 고양이는 귀엽다
라는 문장이 있다면 ES에서 역색인을 생성하는 방식은
강아지 [1, 3]
고양이 [2, 3]
좋아해 [1, 2]
귀엽다 [3]
과 같이 각 단어가 어느 문장에서 등장하는 지 저장한다. 이미 토큰별로 분류해서 인덱스가 만들어져 있기 때문에 문서를 하나하나 읽지 않아도 되는 것이다.
한국어에서 역색인의 사용
사실 위 문장을 띄어쓰기대로 나누면
나는, 강아지를, 좋아해
단어 단위로 저장되지 않는다. 그렇기에 형태소 분석기를 사용해야하는데 대표적인 한국어 형태소 분석기로는 nori가 있고 우리또한 그것을 사용했다.
이를 사용하면
나,는,강아지,를,좋아,해
와 같이 형태소마다 분리되기 때문에 한국어 검색 결과의 정확도를 더욱 높일 수 있다.
구현
MySQL
테이블에
ALTER TABLE movie
ADD FULLTEXT (title) WITH PARSER ngram;속성을 추가해준다.
SELECT * FROM movie
WHERE MATCH(movie) AGAINST('바람' IN BOOLEAN MODE);이런식으로 쿼리문을 작성해주면 ‘바람’이라는 단어가 포함된 제목을 가진 영화가 검색되게 할 수 있다.
ElasticSearch
이건 환경세팅부터 document생성 및 nori 플러그인 추가 등 한 일이 너무 많으므로 나중에 다른 게시글로 작성하여 붙여두겠다.
성능 비교
테스트 도구: Jmeter
요청이 몰렸을 때 처리 성능보다는 평균적 검색 성능을 보고싶었기 때문에 100번 반복으로 설정했다
데이터 7800개일 때
MySQL
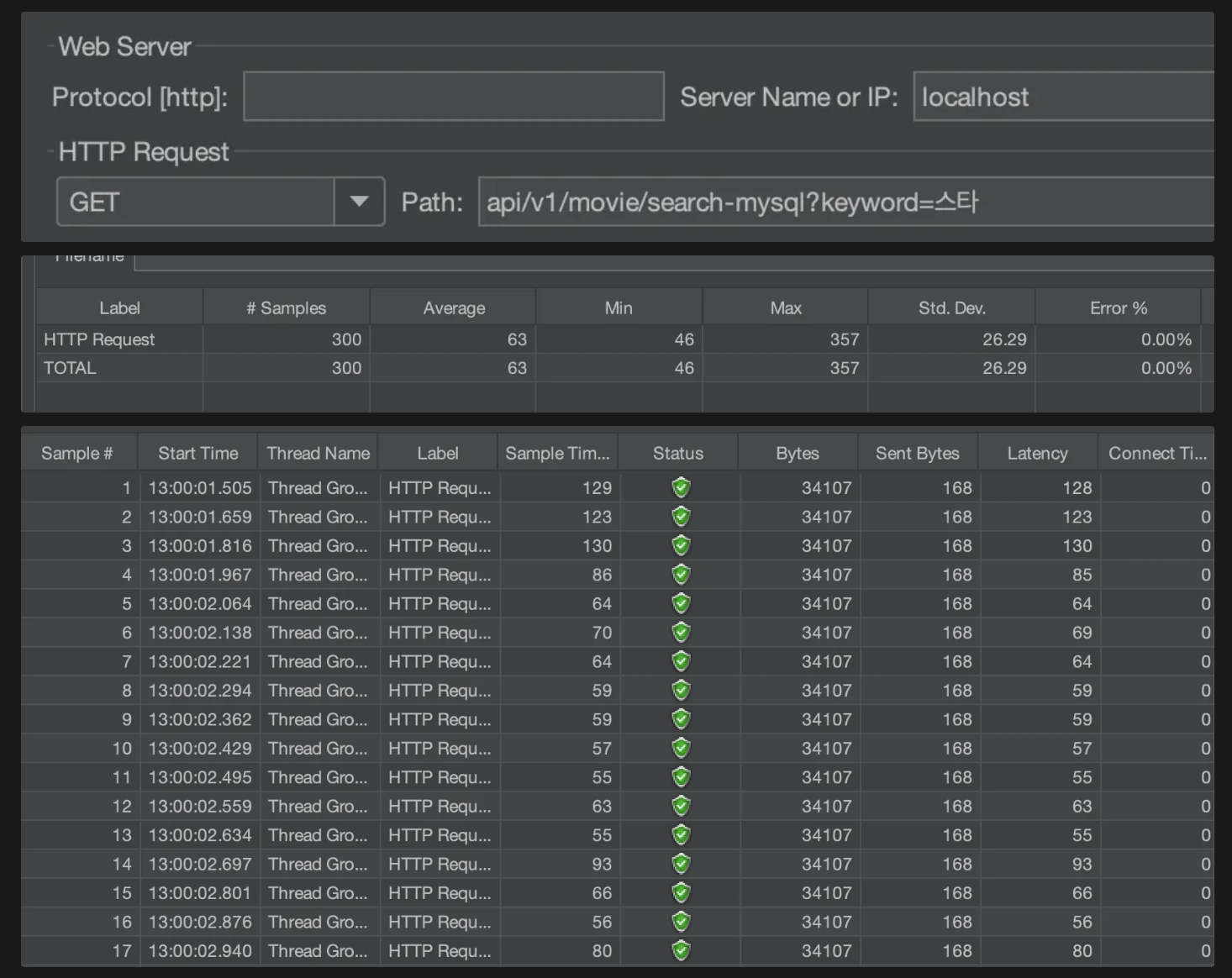
평균 63ms
반복할 수록 소요시간이 짧아지는 경향을 보였다
ElasticSearch
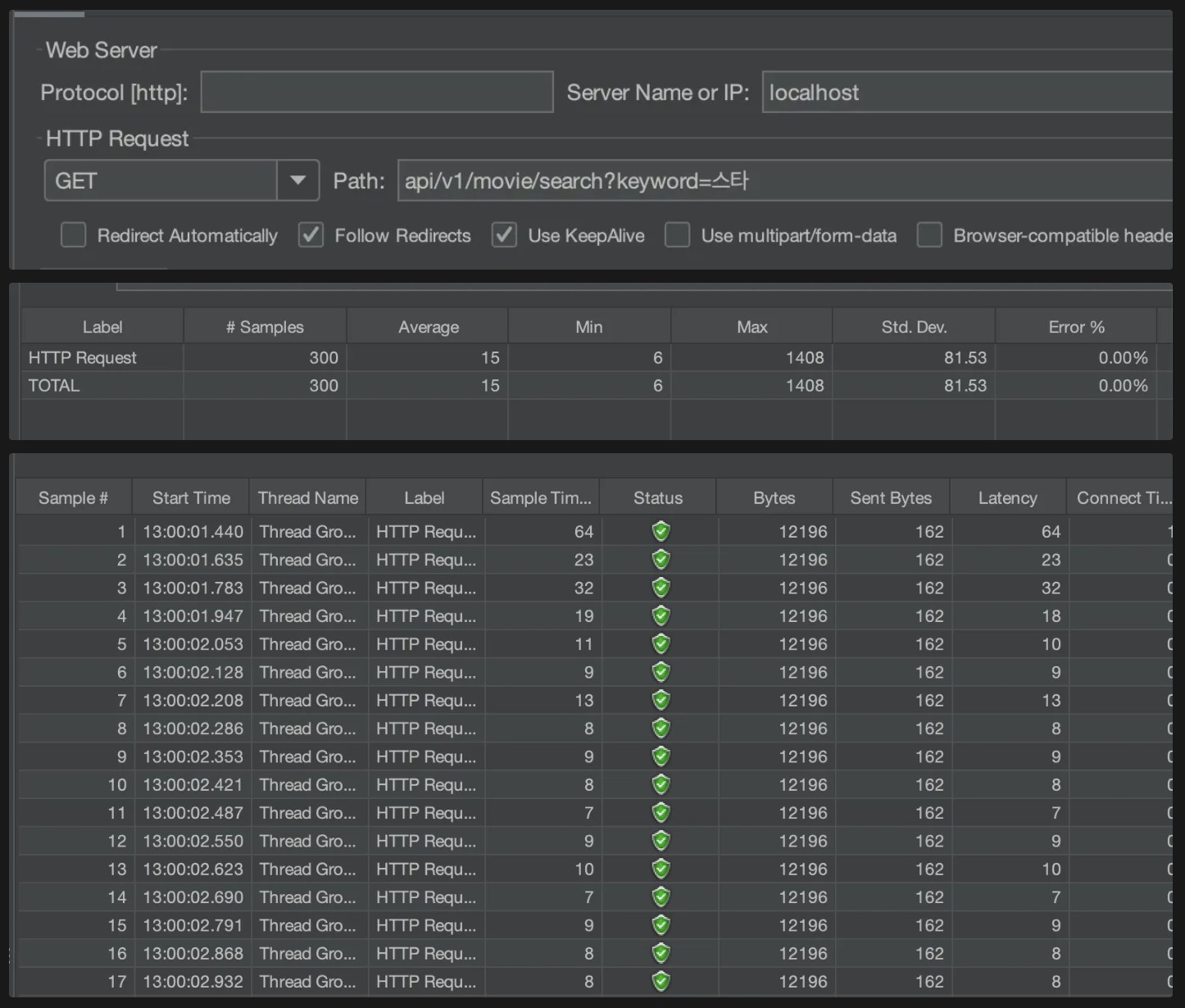
평균 15ms
마찬가지로 반복할 수록 소요시간이 짧아지는 경향을 보였다
데이터 15000개일 때
MySQL
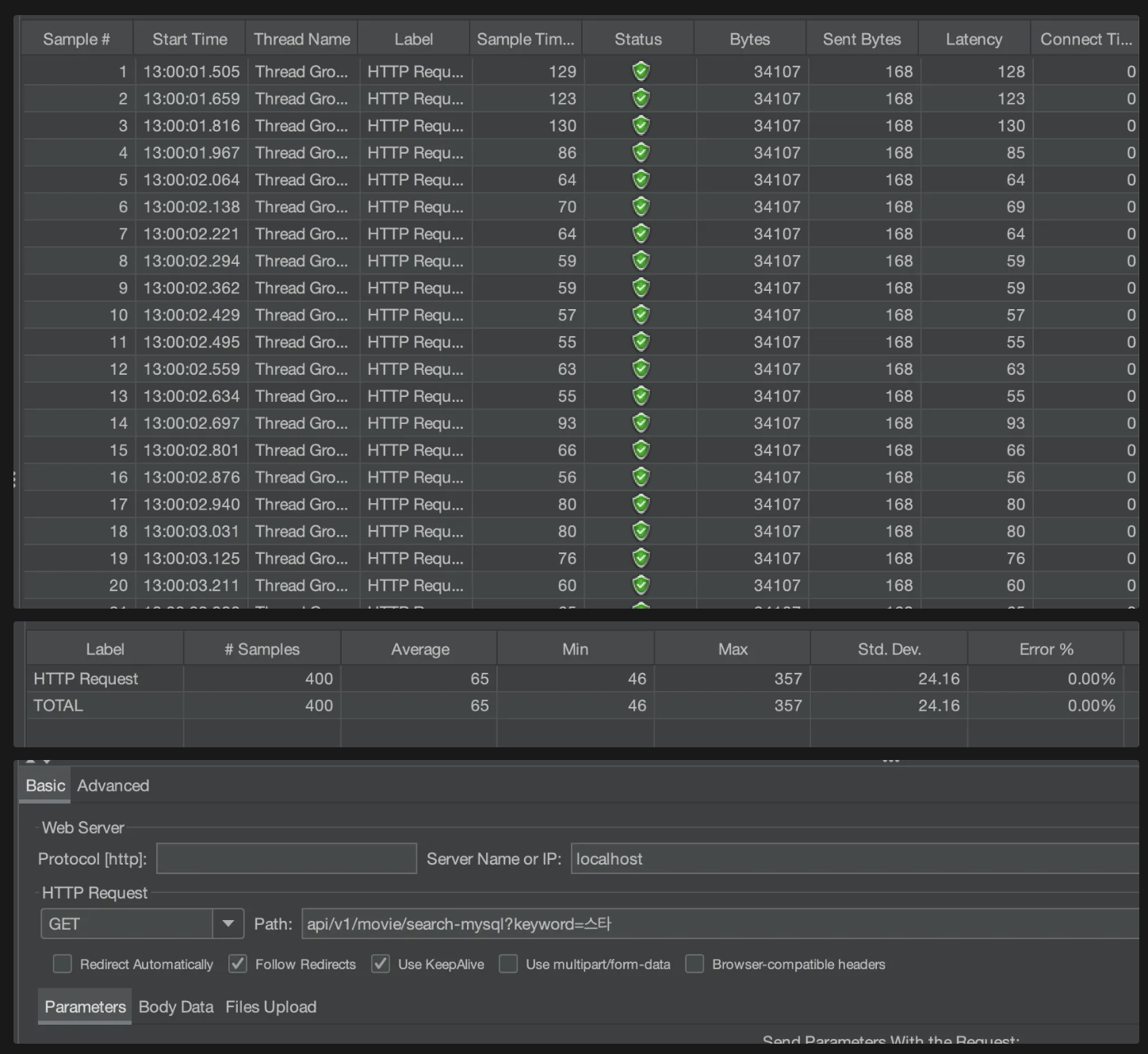
평균 65ms
ElasticSearch
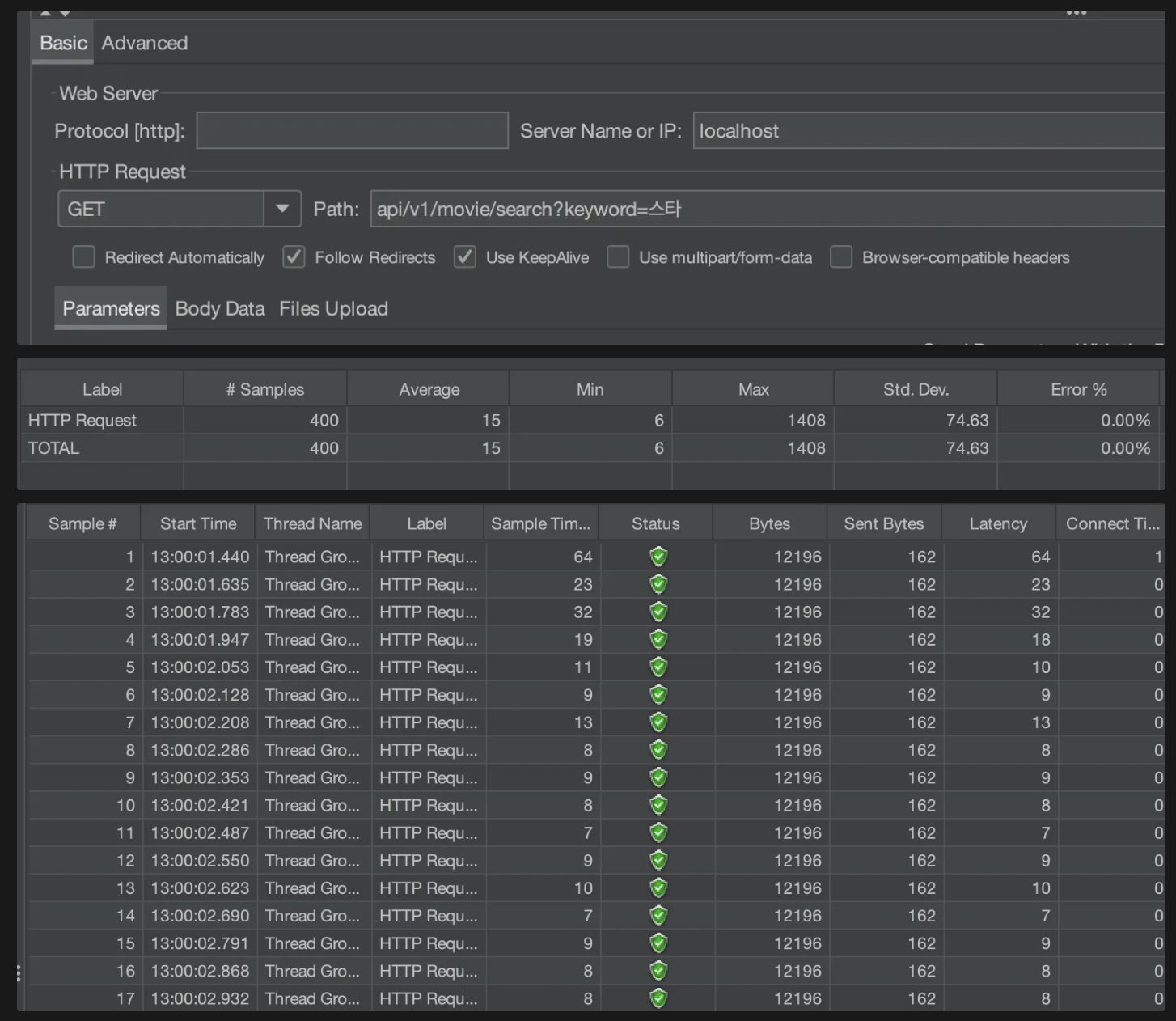
평균 15ms
데이터 양에 따른 성능 비교
데이터는 약 2배 늘어났는데 MySQL에서 2ms정도 느려진 걸 볼 수 있었다. 더 많은 데이터로 비교해본다면 더 명확한 성능을 볼 수 있을 것 같다.
결론
속도
ElasticSearch가 약 4배 빨랐다.
ElasticSearch와 MySQL 성능을 비교해놓은 글들을 보면 약 20배의 속도 차이가 났다고 하는데 아마 이건 mysql의 n-gram이 아닌 like와 같은 쿼리를 날렸을 때의 결과 아닐까 추측해본다.
기능
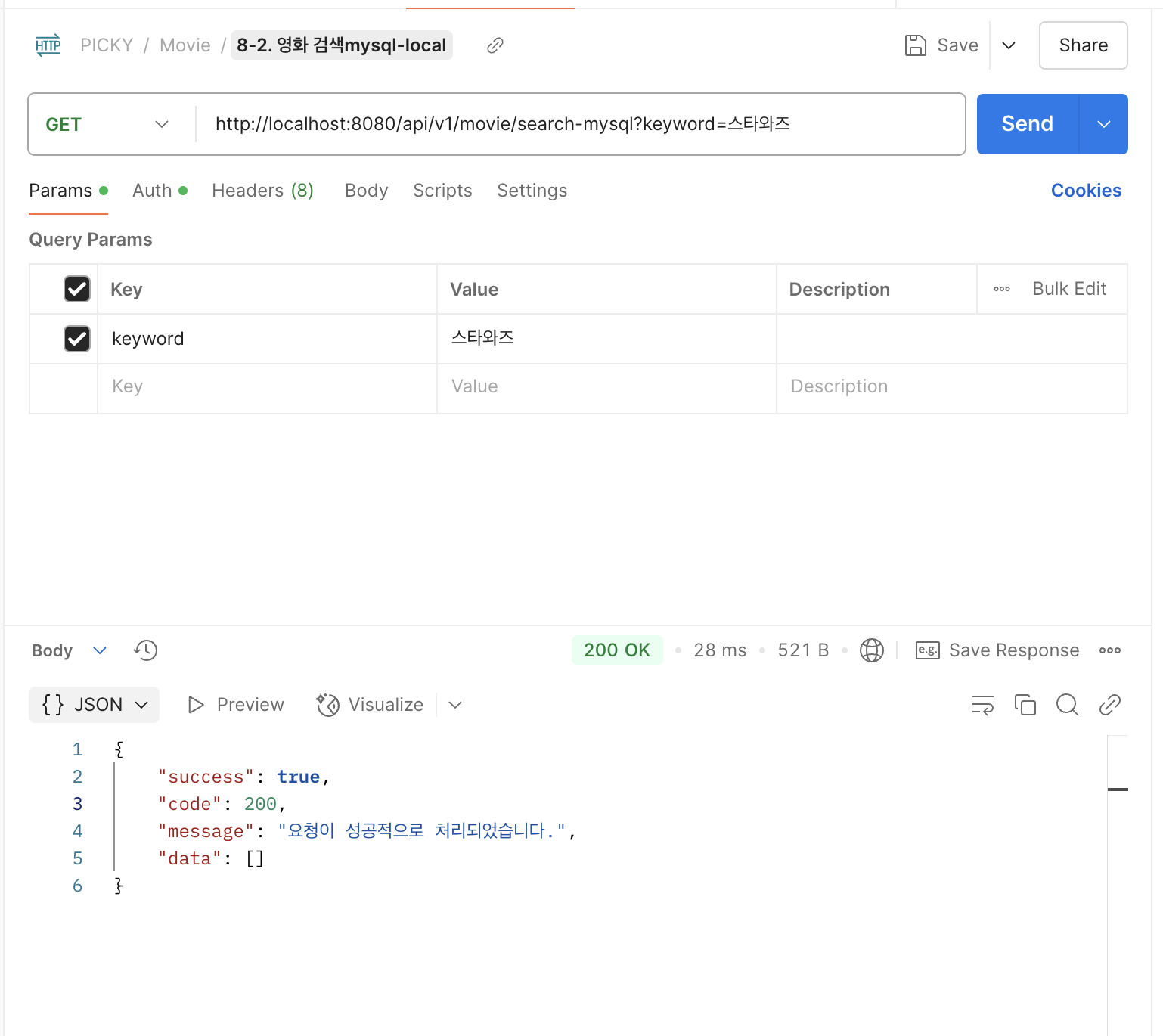
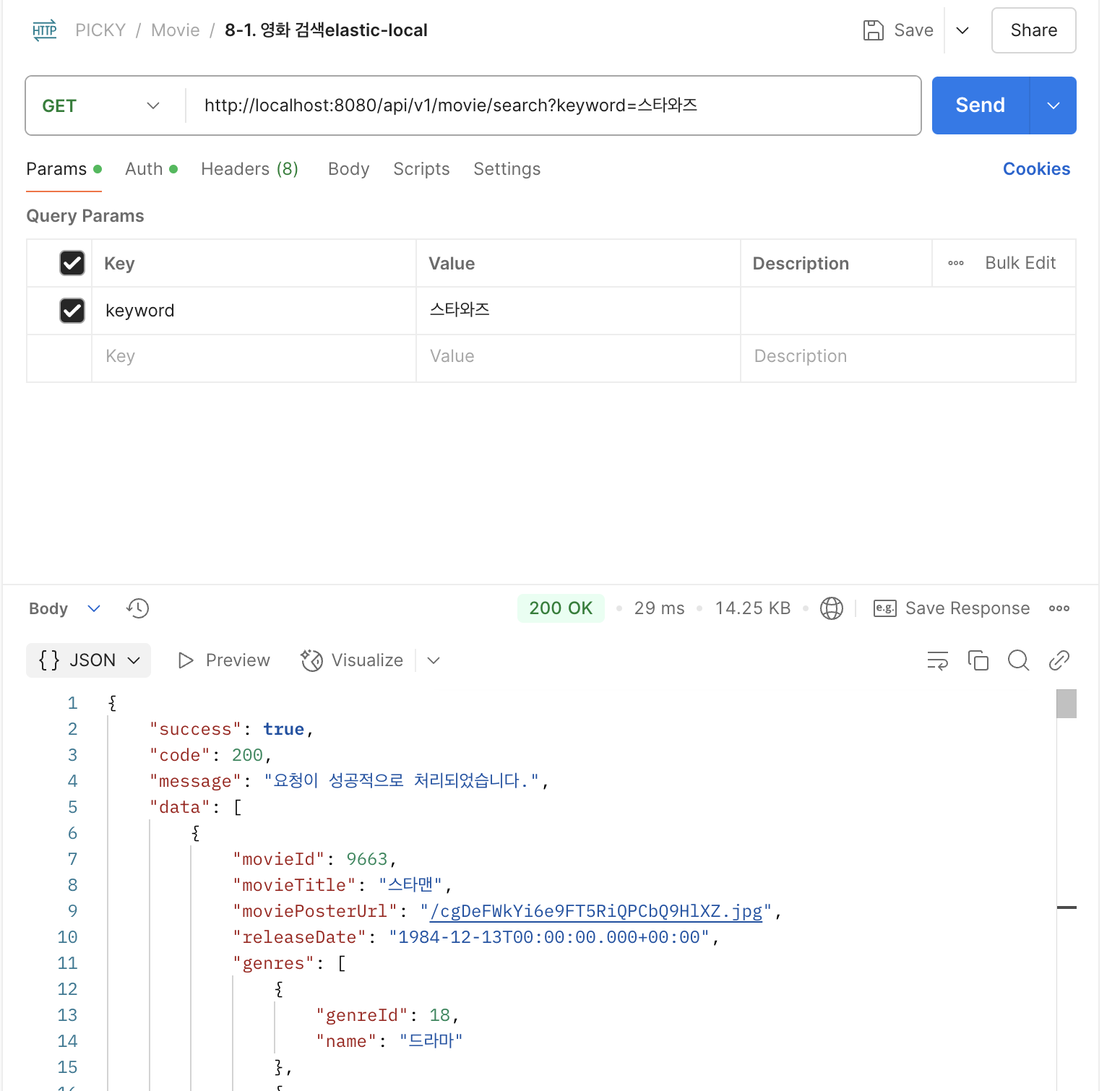
mysql은 오타가 있을 경우 검색 결과가 나오지 않는다.
ES 형태소 분석때문에 오타가 있더라도 비슷한 결과들을 보여준다. 오타 민감도는 설정에서 마음대로 조절할 수 있기 때문에 조금만 비슷해도 보여줄 것인지, 한 글자만 살짝 다를 때만 보여줄 것인지 등을 설정할 수 있다.
자동완성과 오타보정을 생각해본다면, ES를 사용한 검색결과가 사용자 경험에 긍정적 영향을 끼칠 것이라 생각한다.
후기1 - ES적용 까다로움
사실 ES 적용하기가 상당히 까다로웠다. 처음 접하는 기술이기 때문에 처음부터 끝까지 공부해야했고, ES 버전8 이후에는 SSL 사용이 필수이기 때문에 보안관련 문제때문에 세팅하는데 시간이 더 오래 걸렸다.
혼자 쓰는 세팅이라면 내가 편한대로 했겠지만, 팀원들의 환경 세팅 통일을 위해서는 프로세스를 최대한 간편화 해야했다. 지금은 docker-compose up -d 와 명령어 두 개 던지면 로컬에서는 설정이 완료되게 해두었다.
며칠을 고생해가며 설정해서 결국은 보이는 것처럼 성공했다. 지금은 로컬과 서버에서 문제없이 돌아간다.
후기2 - 웹 애플리케이션 및 docker 전반의 공부
보안 문제 때문에 웹 애플리케이션 전반의 흐름에 대해 많이 공부해야했고 특히나 보안은 이번에 다시 한 번 정리할 수 있어서 좋았다.
팀원과의 환경 통일 및 배포시에 충돌 최소화를 위해 docker도 사용하고 있었는데 ES를 도입하면서 컨테이너의 개념을 다시 정리하고 이해할 수 있는 기회였다.
총평
고생하긴 했지만 성능과 기능적 측면에서 ElasticSearch가 mysql의 n-gram보다 월등함을 보았기에 꽤 만족스럽다.
번외) 더미데이터 생성
성능 비교를 위해서 MySQL과 ES 모두에 데이터를 넣어줘야했다. 우리 DB의 영화 테이블에는 상당히 많은 컬럼이 있고, 또 다른 테이블과의 연관관계도 많기 때문에 일반적인 더미데이터 생성 방식으로는 원하는 양질의 데이터는 얻기 힘들다고 판단했다.
그런데 우리 프로젝트에는 이미 TMDB에서 데이터를 가져와 자동으로 영화를 추가하는 코드가 있다.
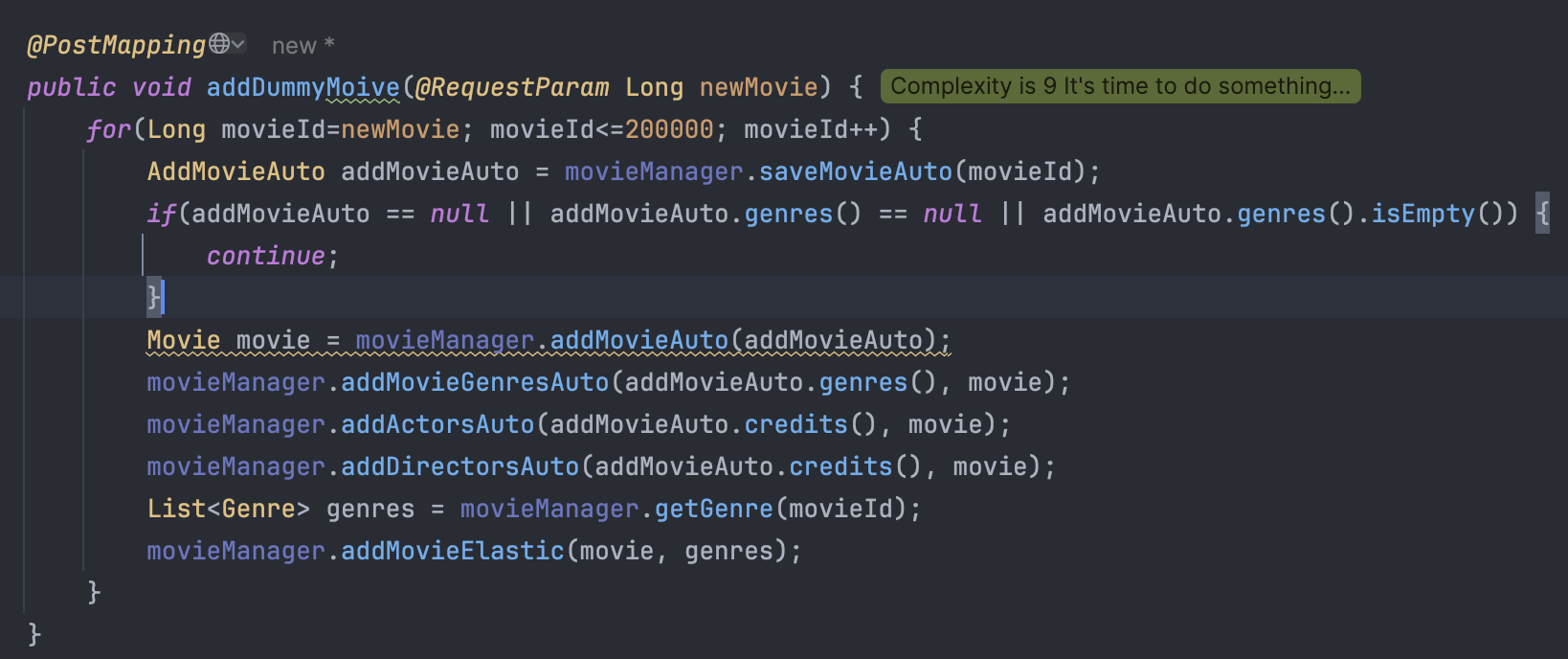
하지만 안타깝게 TMDB에서는 본인들이 가지고있는 영화id의 리스트를 제공하지는 않는다. 그리하여 조금 무식한 방법이긴하지만 이렇게 반복문 걸어놓고 돌렸다.
우리는 MySQL과 ES의 데이터를 주기적으로 동기화 해주고 있었기 때문에 양쪽 모두에 동일한 데이터를 넣을 수 있었고 성능 테스트 환경을 구성할 수 있었다.
물론 이는 성능 테스트 뿐만이 아닌, 서비스 운영에 필요한 데이터를 넣는 작업이라고도 볼 수 있겠다.
Reference
MySQL
https://dev.mysql.com/doc/refman/8.4/en/fulltext-search-ngram.html
ElasticSearch
https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro-what-is-es.html
