
1. 기본 셋팅
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')2. 제목 가져오기
URL 주소 Ctrl누른 상태로 클릭하기
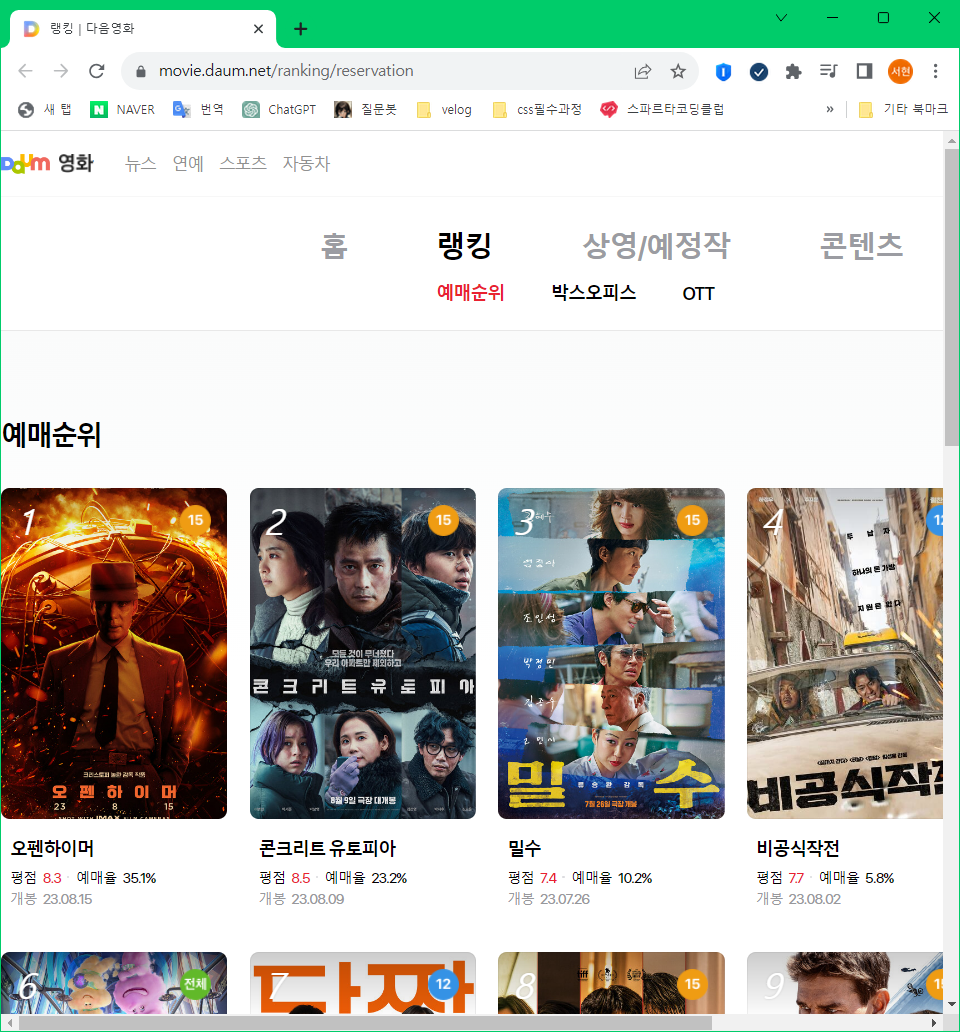
f12(마우스 우클릭 후 검사 누르기
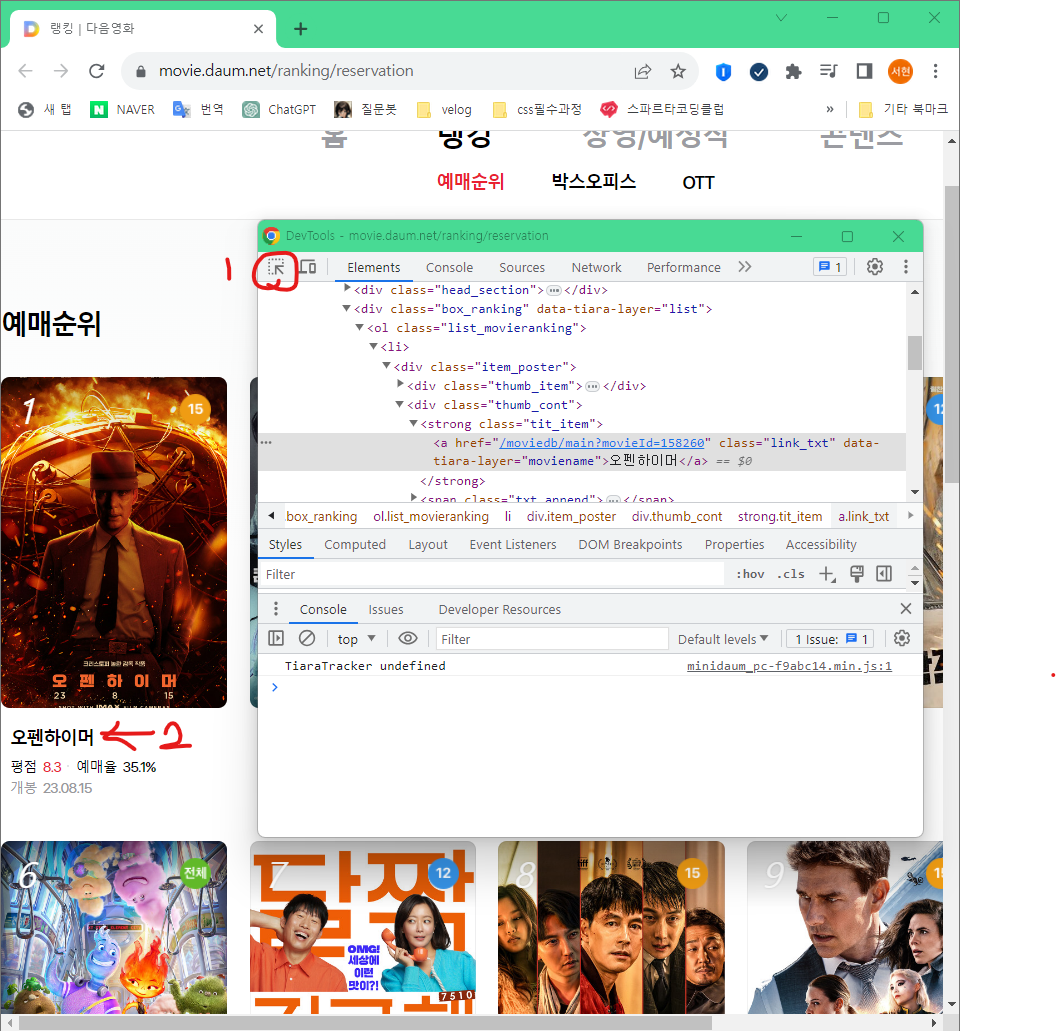
영화 제목 가져올거기때문에 영화 제목 누른 후
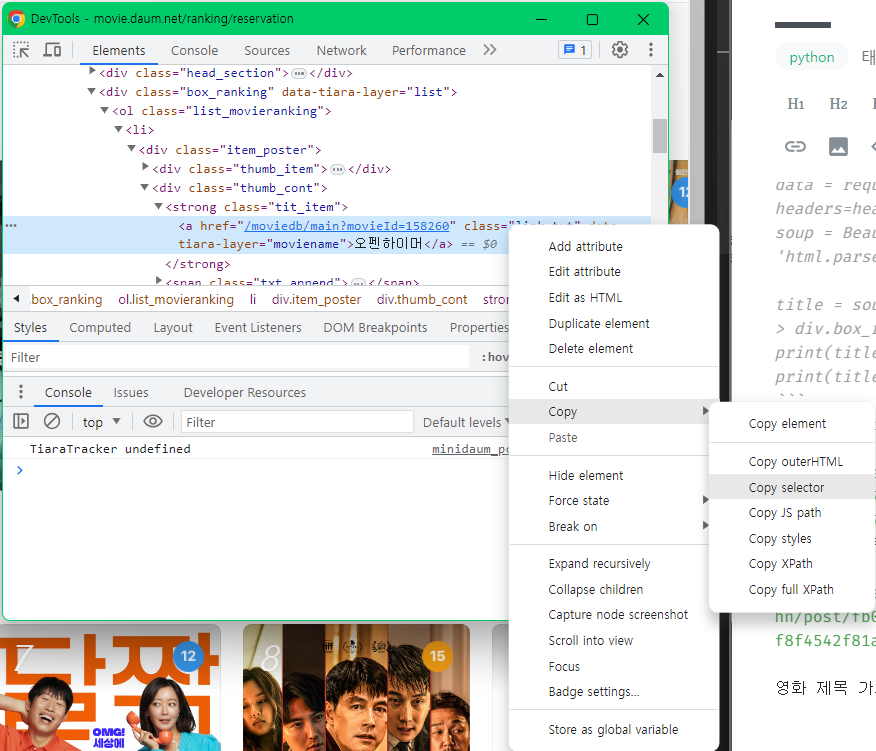
copy selecter
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('#mainContent > div > div.box_ranking > ol > li:nth-child(1) > div > div.thumb_cont > strong > a')
print(title.text)
print(title['href'])터미널에서 실행 후 확인
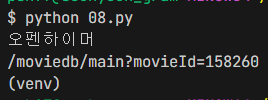
print(title) 로 하면
<a class="link_txt" data-tiara-layer="moviename" href="/moviedb/main?movieId=158260">오펜하이머</a>이렇게 출력된다
3. 영화 제목 여러개 가져오기
가지고 오고 싶은 것의 class명을 가져온다.
import requests
from bs4 import BeautifulSoup
URL = "https://movie.daum.net/ranking/reservation"
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(URL, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
lis = soup.select('#mainContent > div > div.box_ranking > ol > li')
for li in lis:
title = li.select_one('.link_txt')
print(title.text)
4. 문자열 깔끔하게 출력하기
🔻strip() : 문자열의 앞, 뒤 공백을 지워준다
for li in lis:
title = li.select_one('.link_txt').text.strip()
rank = li.select_one('.rank_num').text
rate = li.select_one('.txt_grade').text
print(rank, title, rate)🔻replace(',','') : 문자열 바꾸기
for li in lis:
title = li.select_one('.link_txt').text.replace(',','')
rank = li.select_one('.rank_num').text
rate = li.select_one('.txt_grade').text
print(rank, title, rate)