
당부의 말씀
프로덕션환경으로 DynamoDB를 사용하면서 겪었던 경험에 대해서 많은 사람과 공유하기 위해 작성한 글입니다.
지극히 개인적인 경험을 토대로 작성된 글이므로 많이 부족하거나 잘못된 정보를 안내할 수 있습니다. (그런 일 없도록 노력하겠습니다.) 내용에 관련된 피드백은 환영이며, 많은 도움이 되길 바랍니다.
DDB의 지식이 있다고 가정하에 작성됨을 알립니다.
DynamoDB(DDB)란?
Amazon DynamoDB는 종합 관리형 NoSQL 데이터베이스 서비스로서 원활한 확장성과 함께 빠르고 예측 가능한 성능을 제공합니다. DynamoDB를 사용하면 분산 데이터베이스를 운영하고 조정하는 데 따른 관리 부담을 줄일 수 있으므로 하드웨어 프로비저닝, 설정 및 구성, 복제, 소프트웨어 패치 또는 클러스터 조정에 대해 걱정할 필요가 없습니다.
DynamoDB는 테이블의 데이터와 트래픽을 충분한 수의 서버로 자동 분산하여 처리량 및 스토리지 요구 사항을 처리하면서도 일관되고 빠른 성능을 유지합니다.
참고: AWS DDB 안내서
DDB 선택이유
위의 내용처럼 종합관리 + 확장성 + 빠른성능 + 관리 부담 제로라는 엄청난 메리트와 Serverless 아키텍처 선택 + 인프라관리 인력 부족이라는 삼박자가 맞아서 선택.

이미지 출처: 드레이크진님
겪은 문제
러닝커브
생각보다 러닝커브가 제법 가파르다. 테이블 설계, 쿼리, 인덱스, 파티셔닝, 쓰기용량, 읽기용량 등등 DDB를 사용한다면 하나도 놓칠 수 없는 부분이다.
어느 데이터베이스가 테이블 설계가 중요하지 않겠냐만은 DDB가 상대적으로 더 중요하다고 생각한다.
테이블 설계에 따라 쿼리 능력, 인덱스 여부, 파티셔닝, 쓰기용량, 읽기용량이 변하게되고 이는 비용과 직결된다.
쓰기용량
개인적으로 가장 중요한 부분이라고 생각한다. DDB는 일관된 성능을 제공하기 때문에 요청한 쿼리가 용량(쓰기,읽기)을 초과할 경우 성능을 지연시키지 않고 요청을 거부한다. 이 문제는 심각한 결과를 초래한다.
위 이미지는 프로덕션환경에서 에러가 났을 경우 오는 슬랙 알람이다. 메시지 내용은 쿼리요청이 프로덕트 테이블에 프로비저닝된 용량을 초과했기 때문에 요청을 거부한다는 것인데, 이렇게 될 경우 소프트웨어에 대한 사용자의 경험은 뚝-뚝 떨어진다.
이 문제를 해결하기 위해 용량을 초과할 것 같은 테이블에 대해서 오토스케일링을 사용해 순식간에 용량을 올려 해결할 수 는 있지만 오토스케일된 용량은 24시간안에 최대 4번만 조절할 수 있기때문에 비용이 굉장히 많이 나올 확률이 높아 부담스럽다.
간단히 말해서 테이블마다 필요로하는 용량을 잘 찾아서 설정해주는게 좋다. 아니 이게 말이나 되는 소린가?
이 말도 안되는 문제를 해결하기 위한 방법으로
현재 프로젝트에선 DDB에 쓰기 전에 쿼리요청의 쓰기용량을 미리 계산해서 프로비저닝된 용량을 넘지 않게 사용중이다.
예를 들어, product테이블에 쓰기용량을 10으로 설정했다면, product테이블은 초당 10kb의 데이터를 쓸 수 있다
- 한개의 쓰기 용량은 초당 1KB를 쓸 수 있다.
product테이블에 대한 쿼리요청의 쓰기용량이 40KB라면 이 요청을 실행한 뒤 4초뒤에 다음 쿼리요청을 수행하는 것이다.
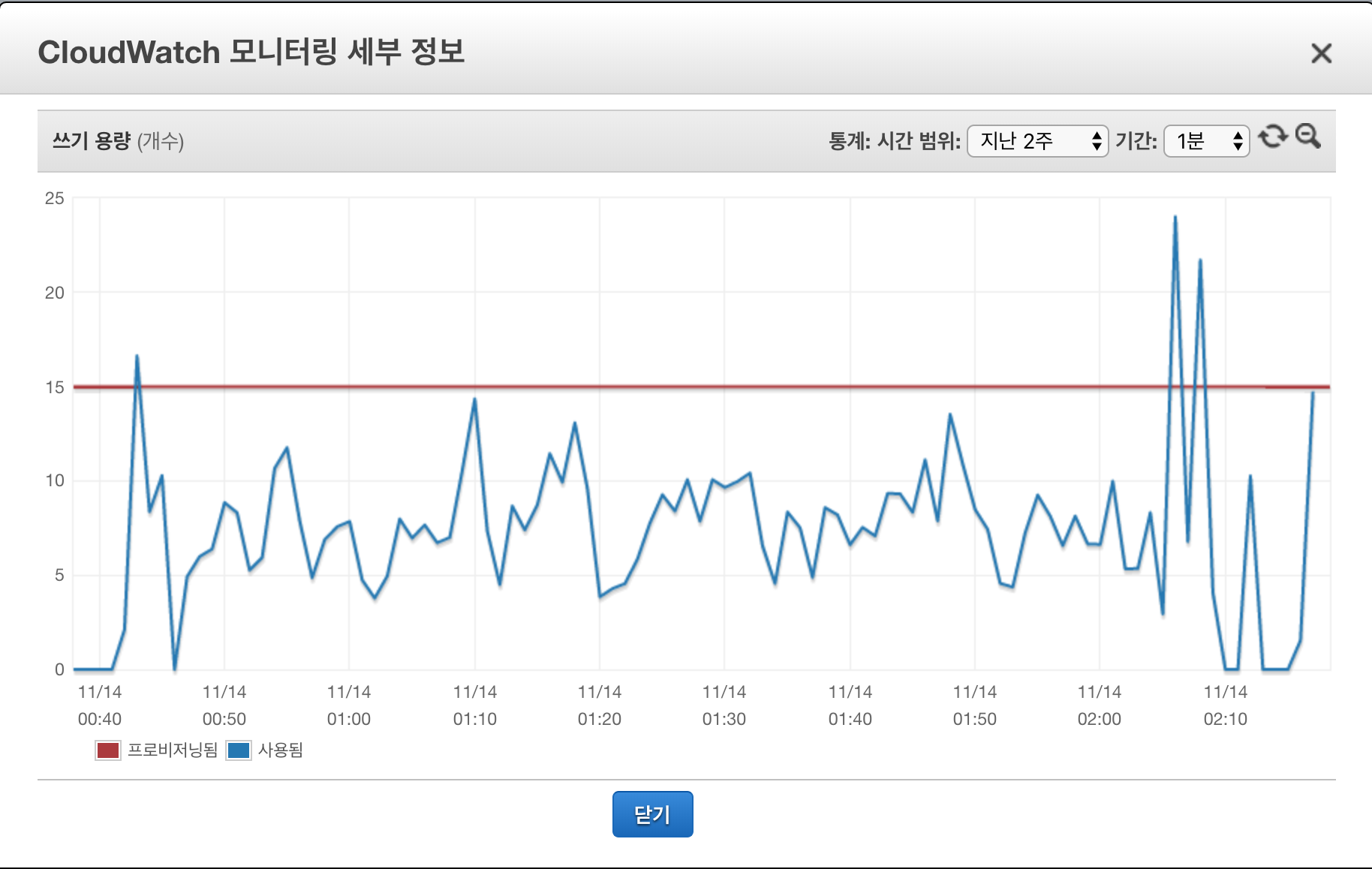
위 그래프는 방법이 적용된 테이블의 통계치이다. 아름답지 않은가 ? 실제로 잘되면 프로비저닝된 쓰기용량을 넘지않기 때문에 요청을 거부하지 않는다. 이 방법은 비용면에서도 좋고 사용자 경험면에서도 좋은 방법이다. (좀 느려지긴 하지만)
쿼리
DDB는 쿼리를 하는데 있어서 불편함이 많다. RDBMS를 경험한 사용자면 더더욱이 그렇게 느낀다. 쿼리도 제한적인데 커맨드까지도 낯설어 힘들다. 또 쓰기용량 읽기용량을 고려하지 않은채 사용할 경우 예상치 못한 문제가 생긴다.
"아니 대체 쿼리하나 요청하는데 뭐이리 신경쓸게 많아?"
데이터 조회시 읽기 용량을 고려해서 쿼리요청을 날림과 동시에 쿼리 자체도 제한적이라 원하는 데이터를 얻기가 쉽지 않다. 이는 테이블 설계에서부터 문제가 있을 확률이 높다. 필자 또한 프로젝트 초기에 테이블 설계에 테이블을 수시로 갈아 엎었다. 테이블 설계를 잘해도 쿼리 자체가 유연하지 않기 때문에 원하는 값을 정확히 얻기가 힘든 경우도 많다.
이 문제를 해결하기 위해 GSI와 LSI를 추가해 해결이 가능하다. GSI와 LSI는 쿼리의 유연성을 극대화 해주는 좋은 기능이다. 그러나 GSI와 LSI는.. 꽤 비싸다. 쿼리의 유연성을 올리기 위해 생각외로 무식한 방법을 쓴다. 이미 존재하는 테이블에 GSI를 생성할 때 파티션키와 소트키를 설정하는데 설정된 파티션키와 소트키로 테이블에 있는 데이터를 재조립하는 방법을 사용한다. 이 말은, 하나의 테이블에 서로 다른 파티션키-소트키 짝이 있는 것이므로 스토리지 비용이 2배로 증가하게 된다. ~결국 돈이냐?~
쿼리의 유연성 + 읽기용량에 대한 비용문제 + 읽기용량 초과 문제를 해결하기 위해 AWS Elasticsearch Service(ES)를 도입했다.

DDB Stream로 발생한 스트림 데이터를 가공한 뒤, ES에 Insert한다. 이 방법은 위에 나열한 3가지 문제를 한번에 해결해주는 좋은 솔루션이다. ES는 검색엔진이므로 쿼리의 유연성은 두말할 것 없고 읽기용량에 대한 개념이 없기 때문에 비용문제, 요청거부문제를 한번에 해결해줬다. 저 3가지 문제를 해결해주긴 했지만 ES자체에서 발생한 문제도 있었다.
Mapping 문제
간단히 말해서 ES는 검색 최적화를 위해 각 컬럼에 대한 정보를 매핑한다. 만약 새로 들어오는 데이터가 매핑정보와 맞지 않다면 ES는 데이터를 입력하지 않고 오류를 뱉는다.
예를 들어 userName이라는 컬럼은 256자 아래이고 text타입이라고 매핑이 되어있는데, 새로 들어오는 userName 값이 integer라면 이 값은 ES에 입력되지 않는다.
이 문제는 생각보다 심각한 문제를 초래한다. DDB의 테이블내 컬럼은 이름만 지정되어있고 그 타입은 로우별로 지정되어 있다. 사실 지정되어있는것도 아니다. 언제든지 그 타입이 수정 가능하다. 그렇다 보니 DDB상에선 userName이 integer타입이 되는게 이상하지 않는데, 이렇게 되면.... 당연히 ES는 변경이 적용되지 않으므로 검색 결과에 반영되지 않는다.
속성에 대한 추가와 변경이 자유로운 NoSQL의 장점을 완전하게 지워버리는 ES의 Mapping시스템........(좌절)
문제를 해결하려고 하는데 자꾸 문제가 발생한다. 이게 뭐지 대체 ?
Plugin 문제
ES는 지원하는 플러그인이 굉장히 많은데, AWS Elasticsearch Service는 꼴랑 10개만 지원한다. 서버를 관리할 필요가 없다는 면에서 굉장히 좋은 선택이지만 그만큼 제약사항이 있었다. 대표적인 플러그인만 지원하기 때문에 힘든 부분이 있었다. ES의 ORM같은 플러그인을 적용시킬 수 없었다는 점이 가장 컸다. 결국 쌩으로 쿼리를 짜서 해결했다.
로우당 저장 가능한 데이터 사이즈
정말 특이하게도 DDB는 데이터 로우당 저장 가능한 데이터 사이즈가 정해져 있다. 400KB를 초과하는 데이터 로우는 입력이 되지 않는다. 텍스트로 400KB를 넘기가 쉽지 않지만 프로덕션 상황에서 간혹 있다. 이럴 경우 데이터가 아예 들어가지 않기 때문에.. 사용자 경험이 떨어지게 된다. 이 문제는 DDB Best practice에 나와 있는데, 400KB를 초과하는 데이터는 S3에 올리고 링크정보를 가져와서 DDB 컬럼에 추가하는 것이다.
이 방법에 대해서 별 다른 이슈는 크게 없었다. 그러나 속도가 느려졌다. 조회할 경우 DDB조회 -> 링크를 이용해 S3접근 -> 다운 -> 리스폰스. 2단계나 추가 되다보니 속도가 느렸다.
후기
약 10개월간 DDB를 쓰면서 발생한 문제들에 대한 해결법을 작성해봤다. 쓰다보니 DDB를 쓰지말라는 글이 된 것 같다. 만약 쓴다고 하면 말리고 싶다. 특히 프로덕션이라면.. 더더욱이..
지금에 와서 우리 프로젝트를 보면 배보다 배꼽이 더 커진 겪이 됐다.
분명 서버리스 아키텍처를 표방하고 있는데 쓰기 용량 아끼자고 서버를 한대 띄웠고 쿼리 좀 편하게 하자고 또 서버를 띄웠다.
솔직한 심정으로 DDB가 좋은게 맞나 싶다. 심각하게 고민 중이다. RDS로 가야하는지.. (퓨ㅠㅠ풒ㅍ)


10개의 댓글

고생 많으셨겠어요~
상상속에서의 완벽한 조합이 이런 문제가 있네요ㅠㅠ(DynamoDB + Serverless)
Serverless+로 다른 DB를 사용하신다면 어떤 서비스를 사용하실건가요?

안녕하세요~ 좋은 포스트 감사합니다
write capacity초과시 에러나는 문제는 on-demand가 생기고 스켈링 된다고 들었는데 요즘도 같은 문제가 발생하고 계신가요?


ㅋㅋㅋㅋ 프로덕션에서 바로 DynamoDB 를 사용하셨다니..!
고생 많이 하셨겠네요~
양질의 포스트 감사합니다!
혹시 피노키오 짤의 출처는 여기 일까요?!
그냥 궁금해서요...!