데이터 엔지니어링에서 흔히 등장하는 ETL과 ELT, 과연 어떤 차이가 있을까?
데이터 파이프라인 구축에서 필수적인 두 프로세스를 비교해보자
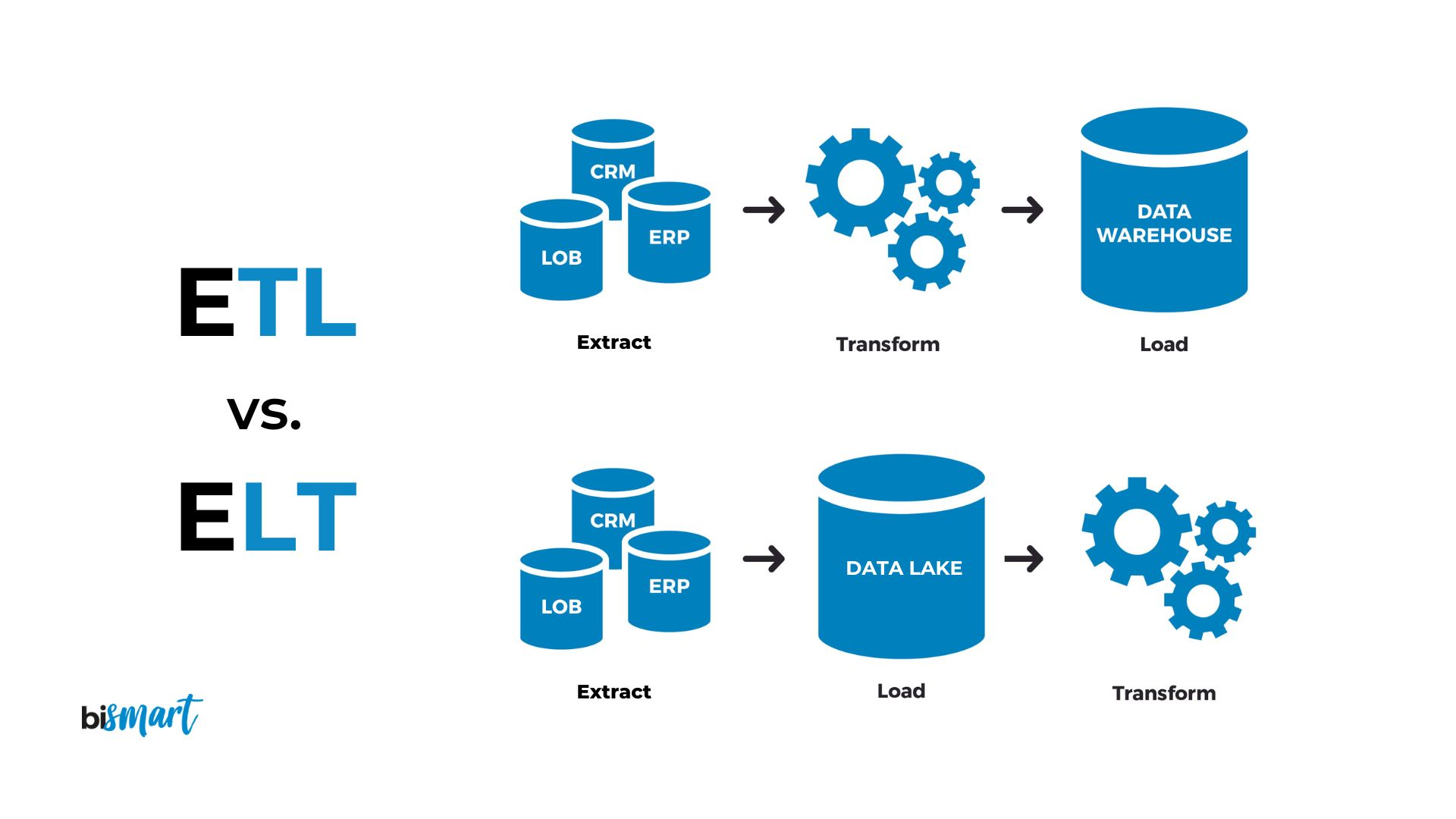
출처: Blog de Bismart
1. E, T, L 이란?
- Extract(추출) : 원시 데이터에서 데이터 소스를 가져오는 것이다.
- Transformation(변환) : 데이터 구조를 변경하는 프로세스다. 용도에 맞는 필터링, Resahping, 정재 등의 단계를 통해 필요한 형태로 변환한다.
- Loading(적재) : 데이터를 스토리지에 저장하는 프로세스다.
2. ETL/ELT를 진행하는 이유
우리가 원하는 건 쓸모있는 데이터다. 데이터를 그냥 쌓아두기만 하면 무의미한 숫자 덩어리에 불과하다. 회사마다, 시스템마다 제각각인 데이터를 하나로 통합하고, 그 과정에서 중복된 값, 오류, 불필요한 데이터들을 걸러내는 정제 과정이 필요하다. 이 정제된 데이터가 있어야만 비로소 의미 있는 분석과 인사이트 도출이 가능해진다. 그렇기 때문에 ETL이나 ELT 같은 데이터 처리 과정이 데이터 파이프라인 구축에서 중요한 역할을 한다.
3. 데이터 웨어하우스(Data Warehouse)와 ETL
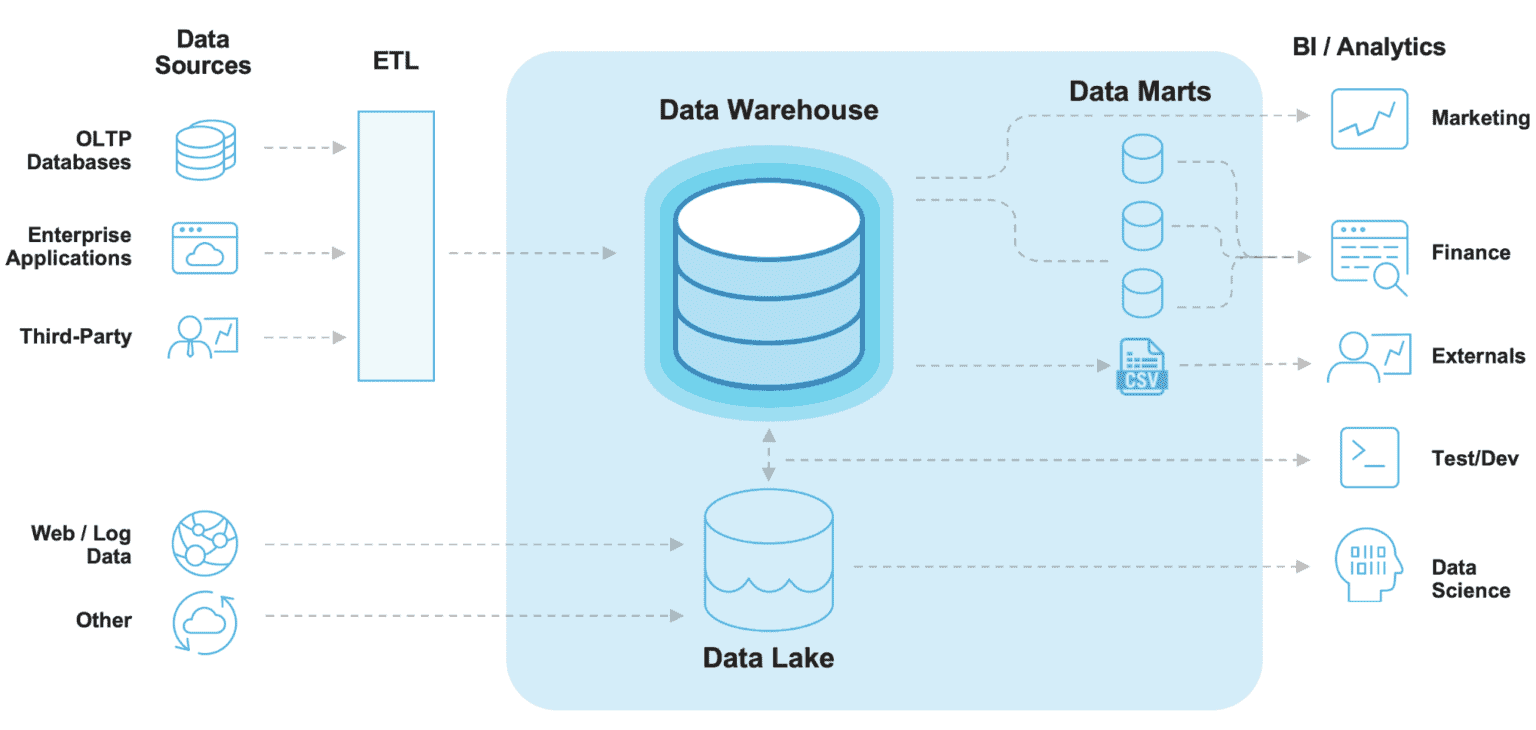
출처 : Modern Data Architecture (Source: Beyond “Modern” Data Architecture, Jeremiah Hansen, 2020.04.09.)
데이터 웨어하우스는 정제된 정형 데이터를 저장하는 시스템으로 분석 및 보고 목적으로 설계되었다. 데이터는 구조화된 형태로 저장되며, BI(Business Intelligence) 도구와 통합되어 빠르고 효율적인 분석을 가능하게 한다. 주로 SQL 기반으로 데이터를 쿼리한다.
ex) 매출 보고서, 고객 분석, 재고 관리 데이터.
4. 데이터 레이크 (Data Lake)와 ELT
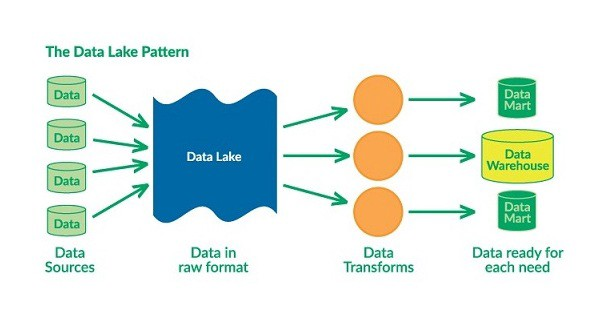
데이터 레이크는 정형, 반정형, 비정형 데이터를 원본 그대로 저장하는 시스템으로 데이터의 형태와 구조에 구애받지 않는다. 다양한 분석 기법과 머신러닝 모델을 활용하기 위한 데이터를 저장하며 대규모 데이터를 빠르게 저장하고 처리할 수 있는 유연성을 제공한다.
ex) IoT 센서 데이터, 소셜 미디어 피드, 이미지나 영상 데이터
5. ETL과 ELT의 차이
| 구분 | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
|---|---|---|
| 프로세스 순서 | 데이터 추출 → 변환 → 적재 | 데이터 추출 → 적재 → 변환 |
| 변환 위치 | ETL 도구 또는 별도 서버에서 데이터 변환 | 데이터 웨어하우스 내부에서 변환 |
| 데이터 적재 형태 | 변환된 데이터만 적재 | 원본 데이터 그대로 적재 |
| 장점 | 데이터가 정제된 상태로 적재되므로 즉시 사용 가능 | 빠른 데이터 적재, 유연한 변환 및 분석 가능 |
| 단점 | 복잡한 변환 로직이 많으면 속도 저하 및 유지보수 어려움 | 대용량 원본 데이터 저장 시 스토리지 비용 증가 가능 |
| 주요 도구 | Informatica, Talend, SSIS 등 | Snowflake, BigQuery, Redshift 등 |
| 적합한 환경 | 데이터가 정형적이고 변환 규칙이 명확한 경우 | 대용량 데이터, 실시간 분석, 클라우드 환경 |
참고
https://dining-developer.tistory.com/50
https://spidyweb.tistory.com/263
https://blog.bizspring.co.kr/%ED%85%8C%ED%81%AC/etl-vs-elt/
