프리랜서로 재직 당시 실시간 Data Flow에 대한 작업을 Apache NIFI를 사용해서 프로젝트를 수행했습니다. 처음 입문하긴 어렵지만 익숙해지면 편리한 Apache NIFI에 대해서 알아보겠습니다.
Apache NIFI란?
아파치 나이파이(Apache NiFi)는 데이터 통합 및 데이터 흐름 관리를 위한 오픈소스 소프트웨어 플랫폼입니다. 실시간으로 데이터를 수집하고, 경로를 구성하여 전처리, 변환 등의 작업을 수행한 후 원하는 시스템으로 데이터를 전달할 수 있습니다.
제가 프로젝트에서 적용했던 데이터들은 실시간으로 공장에서 올라오는 설비 데이터를 전처리하여 적재하는 흐름을 구성하였습니다.
NIFI 아키텍쳐
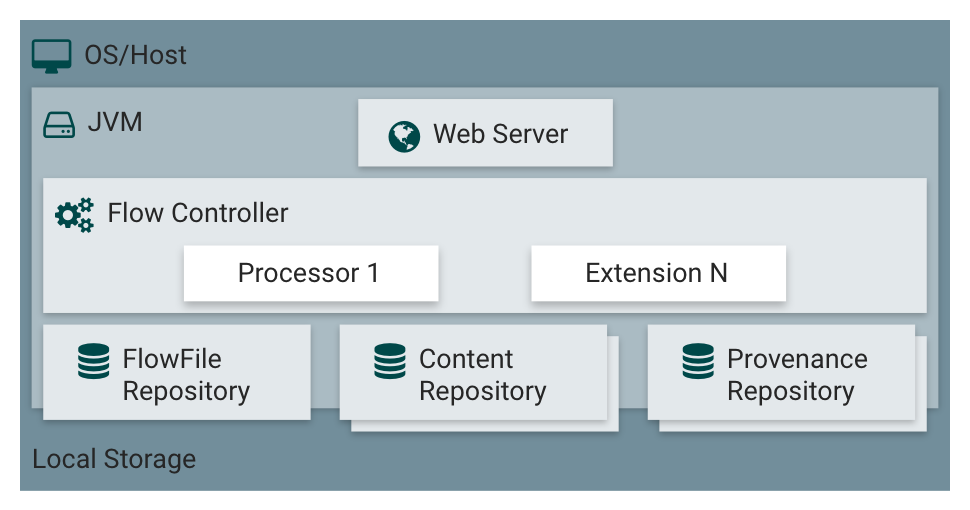
NiFi 구성 요소 요약
Web Server
- NiFi의 HTTP 기반 명령 및 제어 API를 호스팅하는 역할
Flow Controller
- 작업의 중심이 되는 구성 요소
- 확장 실행을 위한 스레드 제공 및 리소스 관리
Extensions
- 다양한 유형의 NiFi 확장 기능 제공
- JVM 내에서 작동 및 실행
FlowFile Repository
- 현재 활성화된 FlowFile의 상태 정보 저장
- 플러그 가능한 저장소 구현, 기본은 영구 미리 쓰기 로그
Content Repository
- FlowFile의 실제 콘텐츠 데이터 저장
- 플러그 가능한 저장소 구현, 기본은 파일 시스템 활용
- 다중 저장소 지원으로 부하 분산
Provenance Repository
- 모든 출처 이벤트 데이터 저장
- 플러그 가능한 저장소 구현, 기본은 물리적 디스크 볼륨 활용
- 색인화된 데이터로 검색 가능
Data Flow
NIFI의 핵심 개념은 FlowFile입니다. 이 FlowFile은 시스템을 통해 이동하는 각 객체(데이터)를 나타내며 기본 단위입니다.
구성 요소
- 데이터 내용: 실제 처리해야 할 데이터 본문입니다.
- 메타데이터: 데이터에 대한 부가 정보로, 파일 이름, 경로, 타임스탬프 등이 포함됩니다.
- 속성: 데이터 처리 과정에서 추가되는 키-값 쌍의 정보입니다.
데이터 흐름(Data Flow)은 프로세서(Processor)라는 개별 작업 단위로 구성되며, 프로세서 간에는 큐(Queue)를 통해 데이터가 전달됩니다. 프로세서는 데이터 수집, 변환, 라우팅, 전송 등 다양한 역할을 수행합니다.
웹 기반 UI
NiFi에는 직관적인 웹 기반 UI가 있어 데이터 흐름을 시각적으로 디자인할 수 있습니다. 드래그 앤 드롭 방식으로 프로세서를 캔버스에 추가하고 연결하여 원하는 데이터 흐름을 쉽게 구축할 수 있습니다.
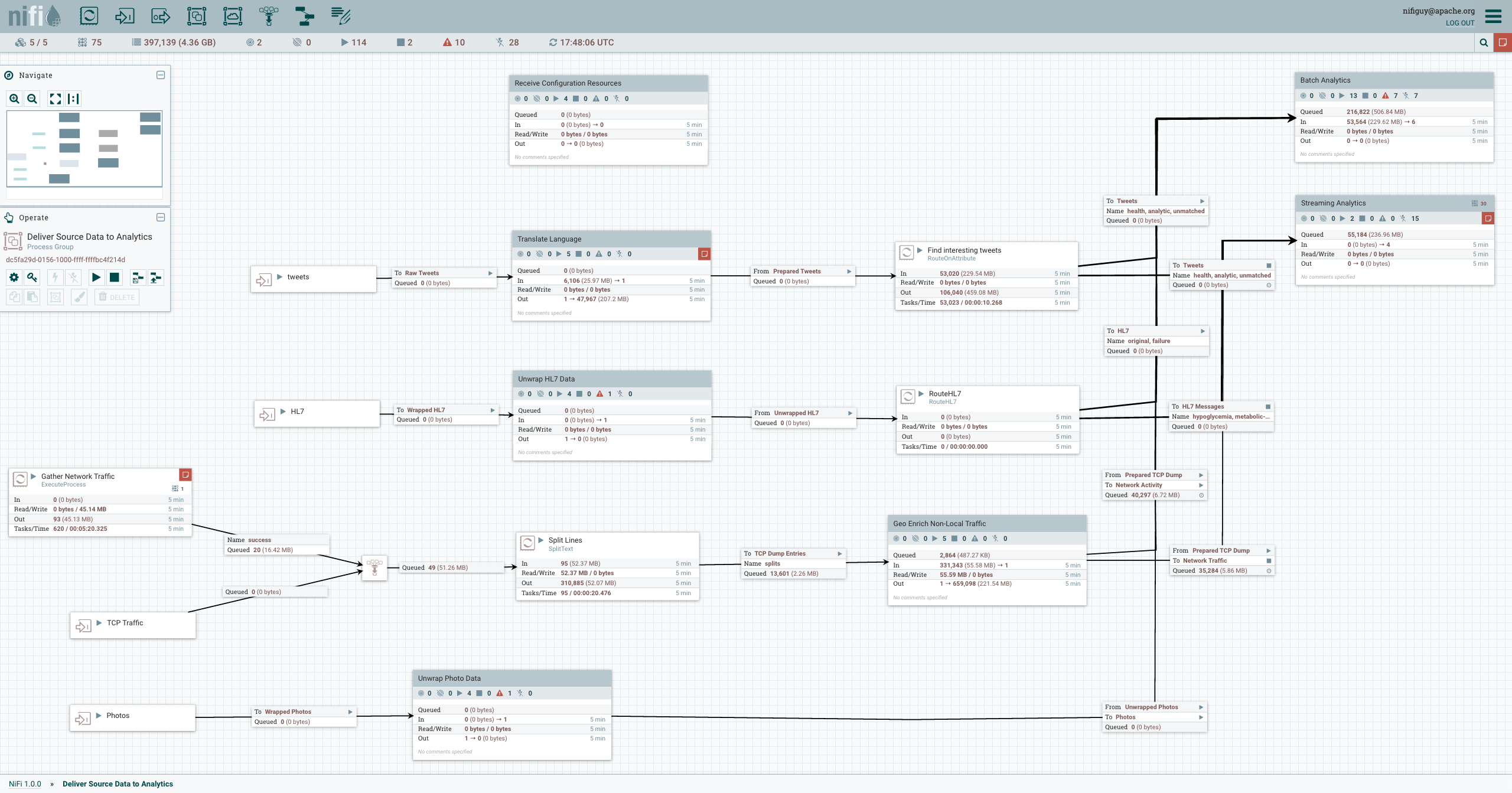
높은 확장성
NIFI는 클러스터 아키텍처를 지원하여 수평적 확장이 가능합니다. 노드를 추가하면 자동으로 로드 밸런싱이 되어 데이터 처리량을 높일 수 있습니다. 또한 노드 장애 시에도 다른 노드가 처리를 이어받아 가동 중단 없이 지속적인 데이터 흐름 처리가 가능합니다.
다양한 데이터 소스 연결
NiFi에는 500개 이상의 built-in 프로세서가 있어 다양한 데이터 소스와의 연결이 가능합니다. 예를 들어 파일, 데이터베이스, Kafka, AWS 서비스, IoT 디바이스, 소셜 미디어 데이터 등을 손쉽게 수집할 수 있습니다.
데이터 변환 기능
NIFI는 강력한 데이터 변환 기능을 제공합니다. JSON에서 XML로, CSV에서 Avro로 데이터 포맷을 변환하거나, SQL 쿼리로 데이터를 필터링하고 가공할 수 있습니다. 스크립팅 프로세서를 이용하면 Python, Ruby 등의 스크립트로도 데이터를 처리할 수 있습니다.
데이터 라우팅 및 전달
수집된 데이터는 사용자 정의 규칙에 따라 다양한 대상으로 라우팅될 수 있습니다. 특정 조건을 만족하는 데이터는 HDFS, Kafka, AWS S3 등으로 전송되고, 다른 데이터는 데이터베이스에 저장되는 식으로 라우팅 규칙을 설정할 수 있습니다.
내가 주로 했던 작업들
NIFI를 통해 주로 했던 작업들은 InvokeHTTP 프로세스를 통해 외부 API에서 데이터를 수신 한 다음 EvaluateJsonPath 프로세서를 통해 JSON으로 파싱하여 ExecuteScript 프로세서로 javascript로 전처리 후 PublishKafka 프로세서를 통해 데이터를 카프카 토픽으로 보내거나 ExecuteSQL 프로세서로 직접 데이터베이스에 저장하는 처리를 하였습니다.
느낀 단점들
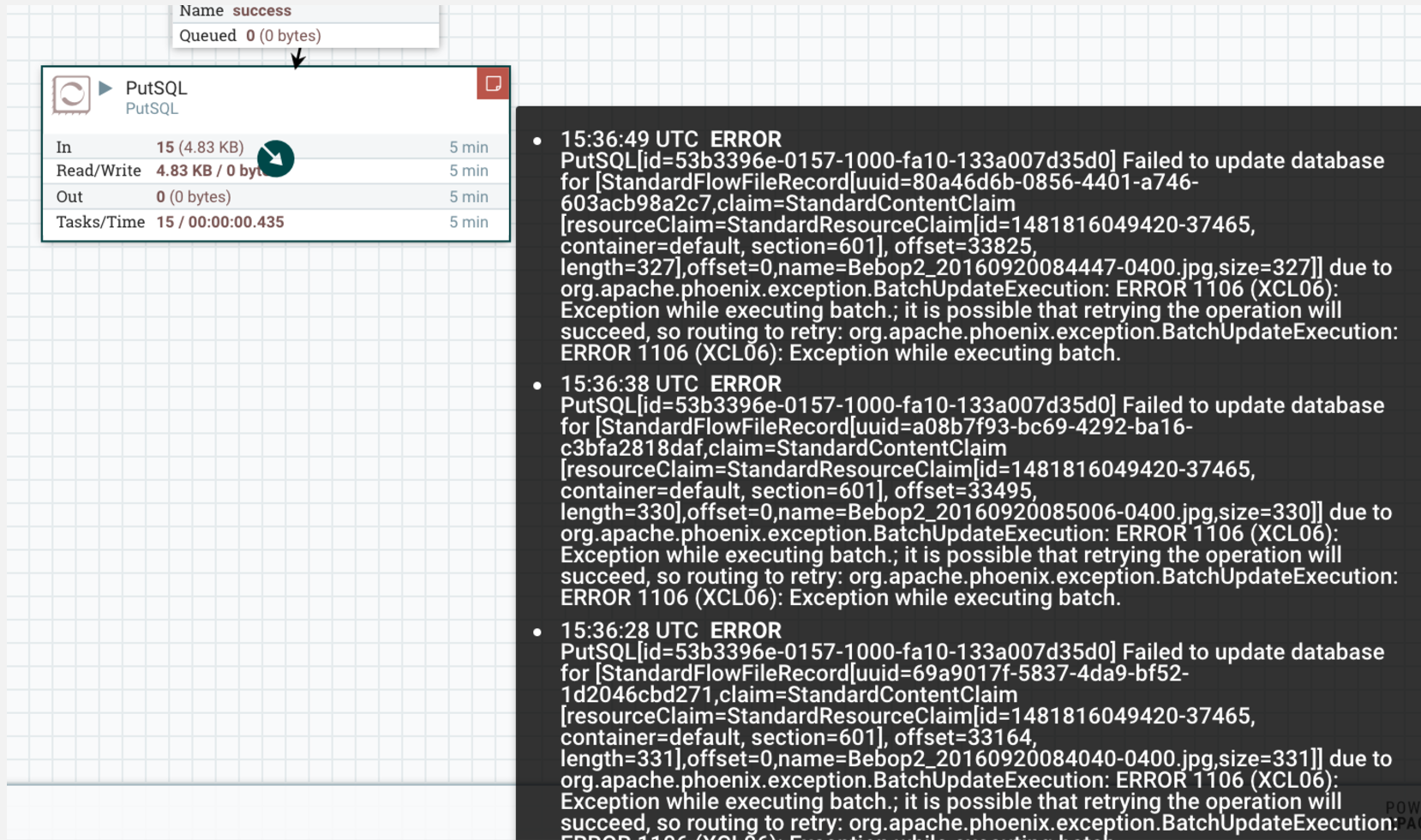
NIFI는 UI 직관적이라 프로세서를 연결하여 사용하기 편하긴 하지만 파이프라인이 크고 복잡해질 수록 유지보수하기 어려웠습니다. 왜냐하면 프로세서 도중에 문제가 발생했다면 디버깅하기 매우 어려웠습니다.
또한 아직 국내엔 도입이 많이 안되서 공식문서를 거의 찾아볼 수 밖에 없다는게 단점이였습니다.
마무리
실시간 데이터 흐름에 대한 고민이 있다면 NIFI를 사용해보는 것도 괜찮은거 같습니다. 저도 NIFI에 대한 지식이 깊이 않아 ExecuteScript 프로세스를 정말 많이 사용했습니다. 복잡한 아키텍쳐에 사용한 사례들이 많이 생기면 좋겠습니다.
