
Redis에 대해 학습하고, 왜 사용하고 장단점과 이유에 대해서 알아보겠습니다.
우리는 항상 더 빠른 애플리케이션을 원합니다. 사용자 경험을 향상시키고, 시스템 리소스를 효율적으로 사용하며, 비즈니스 가치를 높이기 위해서죠. 이러한 요구를 충족시키기 위해 많은 애플리케이션에서 Redis를 선택합니다. Redis가 왜 사용되는 걸까요?
Redis (Remote Dictionary Server)
Redis는 Remote(원격) 에 위치하고 프로세스로 존재하는 In-Memory 기반의 Dictionary(key-value) 구조 데이터 관리 Server 시스템이다.
여기서 key-value 구조 데이터란, mysql 과 같은 관계형 데이터베이스가 아닌 비 관계형 구조로서 데이터를 그저 '키-값' 의 형태로 단순하게 저장하는 구조를 말한다.
그래서 관계형 데이터베이스와 같이 쿼리 연산을 지원하지 않지만, 대신 데이터의 고속 읽기와 쓰기에 최적화 되어있다.
Redis가 기본으로 지원하는 데이터 타입은 다음과 같다.
- String
- Hash
- List
- Set
- Sorted set
- Stream
- Bitmap
- Bitfield
- Geospatial
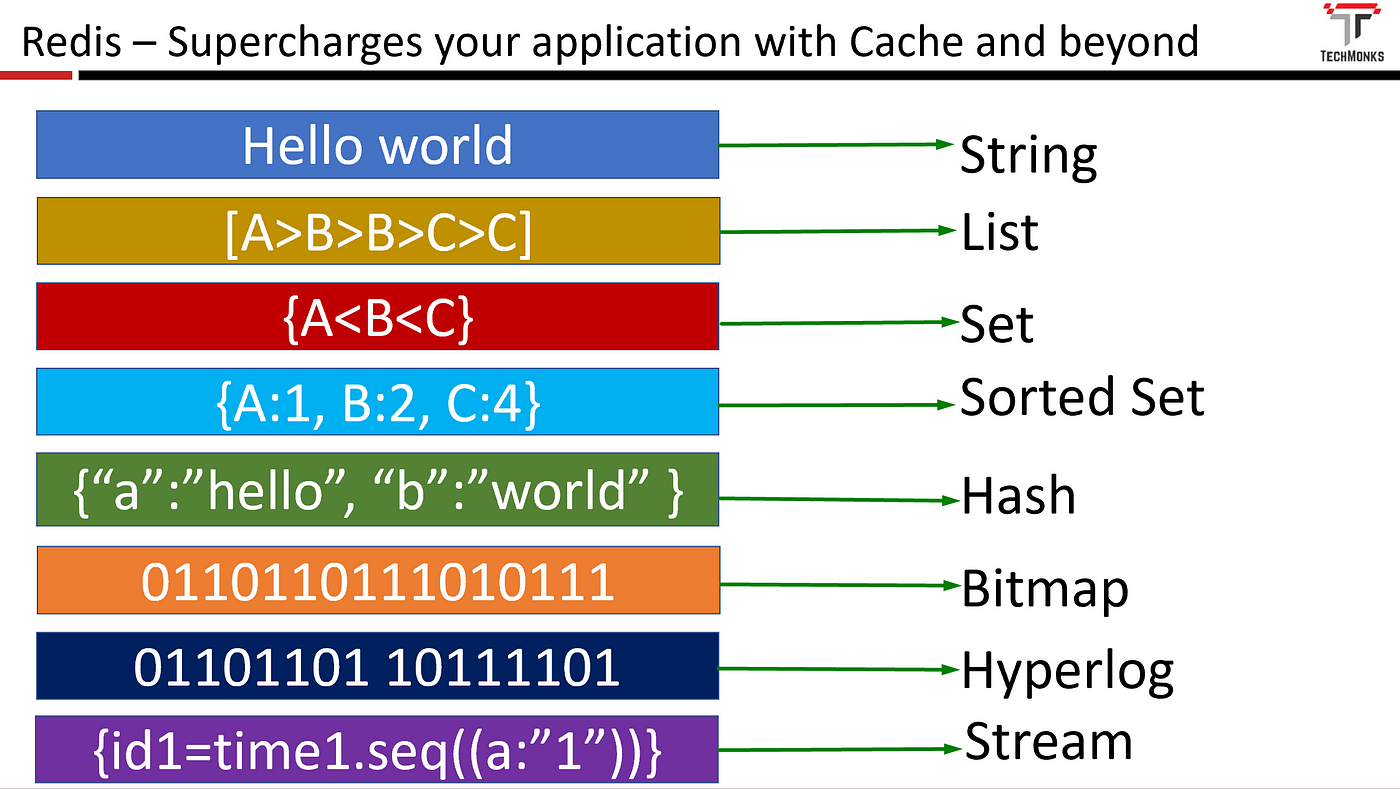
이외에도 json과 같은 타입은 레디스 엔터프라이즈에서 지원한다.
Redis의 빠른 속도의 이유
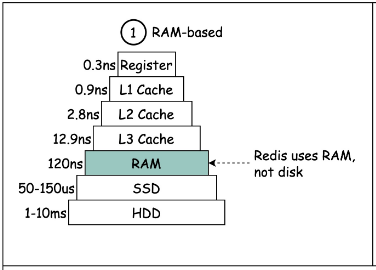
Redis의 핵심은 바로 인메모리 데이터 저장 방식이다. 모든 데이터를 RAM에 보관함으로써, 디스크 I/O로 인한 병목 현상을 원천적으로 제거한다. 하지만 이것만으로는 Redis의 엄청난 성능을 설명하기 부족하다.
Redis의 또 다른 비결은 단일 스레드 아키텍쳐에 있다. 멀티스레드 환경에서 흔히 발생하는 컨텍스트 스위칭과 락(lock) 관련 오버헤드를 완전히 제거했다. 여기에 비동기 I/O 모델을 채택하여 이벤트 처리의 효율성을 극대화했다.
Redis 활용 - 캐시(Cache)
캐시란?
Cache란 한번 조회된 데이터를 특정 메모리 저장해놓고, 똑같은 요청이 발생하게 되면 서버에게 다시 요청하지 않고 특정 메모리에 저장된 데이터를 제공해주는 것을 말한다.
즉, 애플리케이션에 요청이 왔을 때 메모리에 데이터가 존재한다면 DB를 조회하지 않고 Cache된 데이터를 가져와 처리하는 방법이다.
처음 서비스를 운영하면 작은 인프라를 구축하는데, 사용자가 늘어나 수백 ~ 수천만의 조회 요청이 발생한다면 DB에 무리가 간다.
DB는 데이터를 물리 디스크에 직접 쓰기 때문에 서버에 문제가 발생해도 데이터 손실이 되지 않지만, 매 트랜잭션마다 디스크에 접근해야 하므로 I/O 오버헤드가 발생하여 성능이 떨어지게 된다.
이런 경우 DB를 Scale-up, Scale-out, 캐시 서버 도입을 고려하게 된다.
Redis Cache는 메모리에 저장하기 때문에 용량이 작지만 접근 속도가 매우 빠르다. 하지만 저장하려는 데이터의 크기가 메모리의 크기보다 크다면 디스크에 저장하는 것이 올바르다.
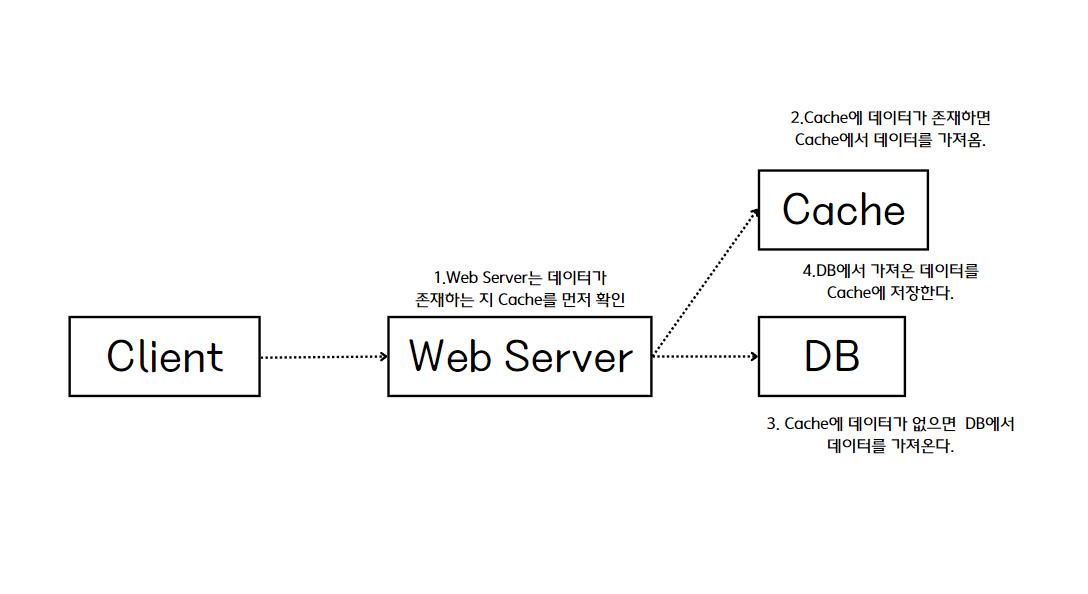
캐시의 구조 패턴 - 1. Look aside Cache 패턴
캐시를 사용하는 패턴은 첫 번째로 Look aside Cache 패턴이다.
위에서 말한 일반적인 캐시 정의를 그대로 구현한 구조이다.
Look aside Chche 쿼리 순서
1. 클라이언트에서 데이터 요청
2. 서버에서 캐시에 데이터 존재 유무 확인
3. 데이터가 있다면 캐시의 데이터 사용 (Cache Hit)
4. 데이터가 없다면 실제 DB 데이터에 접근 (Cache Miss)
5. 그리고 DB에서 가져 온 데이터를 캐시에 저장하고 클라이언트에 반환
캐시의 구조 패턴 - 2. Write Back 패턴
Write Back은 주로 쓰기 작업이 많을 때, INSERT 쿼리를 일일이 처리하지 않고 한꺼번에 배치 처리를 하기 위해 사용한다.
INSERT를 기준으로 하나의 INSERT를 1000번 날리는것과 한번에 1000번을 한번에 묶어서 쿼리를 날리는것은 차이가 많이 나기 때문이다.
단점은 Cache를 관리하는 서버에 장애가 발생하거나 리부팅이 발생하게되면 증발해버릴수가 있다. 그래서 로그 관련 데이터 저장할때 많이 사용한다.
따라서 재생 가능한 데이터나, 로그 같은 데이터를 저장할 때 주로 사용한다.
Look aside Chche 쿼리 순서
1. 모든 데이터를 캐시에 저장
2. 캐시의 데이터를 일정 주기마다 DB에 한꺼번에 저장 (배치)
3. DB에 저장됐다면 남아있는 데이터를 캐시에서 제거
Redis 활용 - 세션 스토어(Session Store)
웹 애플리케이션 서버를 1개를 이용하게 되면 단일 서버에서 세션을 관리할 수 있겠지만 실제 운영되는 서버는 여러 개의 서버를 사용한다. 이 때 세션 정보의 동기화 문제가 발생한다.
이러한 문제를 해결하기 위해 개발자들이 Redis를 선택한다. Redis는 중앙 집중식 세션 스토어 역할을 한다. 이를 통해 세션 데이터에 대한 동기화 문제를 처리할 수 있다.
중앙 집중식 세션 저장소
Redis는 모든 애플리케이션 서버에서 접근 가능한 중앙 저장소 역할을 한다. 각 서버는 세션 데이터를 로컬에 저장하는 대신 Redis에 저장하고 조회한다. 이 방식으로 모든 서버가 항상 최신의 세션 데이터에 잡근할 수 있다.
세션 ID를 이용한 key-value 저장
Redis는 세션 ID를 key로 사용하고, 세션 데이터를 value로 저장한다. 예를 들어
key: "session:1234567890abcdef"
value: {user_id: 100, username: "john_doe", last_access: "2023-05-01 10:00:00"}이 구조를 통해 동일한 세션 ID로 세션 데이터에 접근할 수 있다.
세션은 주로 로그인한 사용자의 정보를 저장하는데 사용한다, 이 정보는 영원히 저장되어야 하는 정보가 아니다. 게다가 세션에 데이터 유실로 인해 발생하는 피해가 다른 데이터에 비해 적다. 만약 Redis에 세션 정보가 유실된다면 사용자는 재 로그인만 수행하면 된다.
따라서 세션 스토리지로서 Redis는 아주 적합하다.
Redis vs Memcached

In-Memory DB에도 다양한 데이터베이스가 존재한다. 캐싱을 위해 사용하는 데이터베이스에는 Redis말고 Memcached 가 있다.
두 개의 공통점으로는 In-Memory 저장소라는 점, key-value 의 저장 방식을 가지고 있다는 점이다.
(Memcached는 key-value 저장만 지원)
하지만 Redis는 String, List, Set, Hash, Sorted Set 등 복잡한 데이터를 저장할 수 있기 때문에 단순 캐싱을 넘어 다양한 용도로 활용될 수 있다.
영속성
영속성이란 데이터를 디스크에 저장하여 서버 재시작 후에도 데이터를 유지할 수 있는 기능을 말한다.
Memcached는 순수한 인메모리 캐시로, 영속성을 지원하지 않습니다. 서버가 재시작되면 모든 데이터가 사라진다.
Redis는 두 가지 방식의 영속성을 제공한다
- RDB (Redis Database): 특정 시점의 스냅샷을 생성한다.
- AOF (Append Only File): 모든 쓰기 작업을 로그 파일에 기록한다.
단, AOF는 모든 명령어를 기록하기 때문에 더 안전하지만, 파일의 크기가 커질 수 있다. RDB는 파일 크기가 작지만, 스냅샷 사이의 데이터는 손실될 수 있다.
고가용성 (High Availability)
고가용성이란 시스템이 지속적으로 정상 운영될 수 있는 능력을 말한다. 즉, 일부 서버에 문제가 생겨도 서비스가 중단되지 않는 것을 말한다.
Memcached는 기본적으로 고가용성 기능을 제공하지 않는다. 클라이언트 측에서 여러 Memcached 서버를 관리하는 방식으로 부분적으로 고가용성을 구현할 순 있지만, 너무 복잡하고 제한적이다.
Redis는 Redis Sentinel이라는 시스템을 통해 고가용성을 제공한다. Sentinel은 마스터 노드를 모니터링하고, 마스터에 문제가 생기면 자동으로 슬레이브를 새로운 마스터로 승격시킨다.
# Sentinel 설정 예시
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 5000이 설정은 127.0.0.1:6379의 Redis 인스턴스를 모니터링하고, 5초 동안 응답이 없으면 장애로 간주한다.
따라서 Redis와 Memcached는 각각의 장단점이 있다. Memcached는 단순하고 빠른 캐시 시스템이 필요할 때 좋은 선택일 것이고, Redis는 복잡한 데이터 구조, 영속성, 고가용성이 필요한 경우에 적합하다.
Redis 활용 - 메시지 브로커
Redis는 Pub/Sub (게시/구독) 모델을 지원하여 효과적인 메시지 브로커로 활용될 수 있다. 이 기능을 통해 실시간 메시징 시스템이나 이벤트 아키텍처를 구현할 수 있다.
Pub/Sub 모델이란?
Pub/Sub 모델은 메시지의 발행자(Publisher)와 구독자(Subscriber) 사이의 중개자 역할을 한다. 발행자는 특정 채널에 메시지를 보내고, 해당 채널을 구독하고 있는 모든 구독자가 그 메시지를 받게 된다.
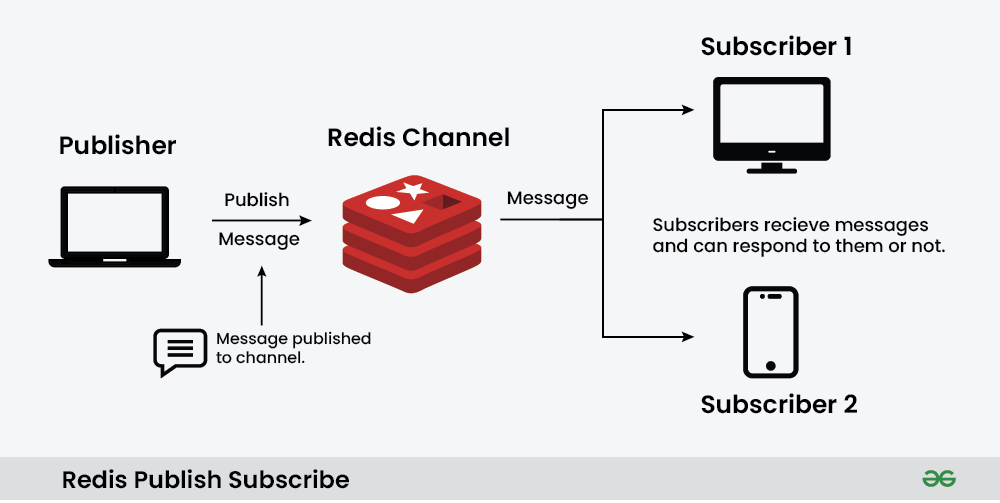
Redis Pub/Sub 특징
- 비동기 통신: 발행자와 구독자는 서로 알 필요가 없고, 비동기적으로 통신한다.
- 확장성: 하나의 메시지를 여러 구독자에게 동시에 전달할 수 있어 화갖ㅇ성이 뛰어나다.
- 실시간 처리: 메시지가 발행되면 즉시 구독자에게 전달된다.
Redis Atomic 연산
Redis Atomic 연산은 DB 원자성을 보장하는 중요한 특성이다. '원자적'이라는 말은 DB에서 연산이 완전히 수행되거나 전혀 수행되지 않는 것을 의미한다. 즉, 부분적 실행이 불가능하다.
DB 트랜잭션 특징 - ACID
원자성(Atomic): 트랜잭션과 관련된 작업들이 부분적으로 실행되다가 중단되지 않는 것을 보장한다는 것을 의미한다.
일관성(Consistency): 트랜잭션 처리 전과 처리 후 데이터 모순이 없는 상태를 유지하는 것을 의미한다.
격리성(Isolation): 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미한다.
지속성(Durability): 성공적으로 수행된 트랜잭션은 영원히 반영되어야 함을 의미한다.
왜 Atomic 연산일까?
- 데이터 일관성: Atomic 연산은 여러 클라이언트가 동시에 같은 데이터에 접근할 때 데이터의 일관성을 보장한다.
- Race Condition 방지: 여러 프로세스나 스레드가 동시에 같은 데이터를 수정하려 할 때 발생할 수 있는 Race Condition을 방지한다.
- 단순성: 복잡한 락(lock) 메커니즘 없이도 안전한 데이터 조작이 가능하다.
왜 쪼갤 수 없을까?
Redis의 Atomic 연산은 단일 스레드 모델에서 실행된다. 이는 한 번에 하나의 명령만 처리됨을 의미한다.
따라서
1. 중단 불가능: 연산이 시작되면 완료될 때까지 다른 연산이 끼어들 수 없다.
2. 전체성: 연산은 항상 전체로서 실행되며, 부분적인 실행 상태가 외부에 노출되지 않는다.
3. 일관성: 연산 중간에 시스템 장애가 발생하더라도, 데이터는 연산 전 상태나 연산 후 상태 중 하나만을 가진다.
Redis 클러스터 vs 단일 Redis 서버
Redis를 사용하다 보면 언젠가는 단일 서버의 한계에 부딪히게 된다. 데이터가 늘어나고 트래픽이 증가하면서 더 많은 용량과 처리 능력이 필요해진다. 이때 고려할 수 있는 것이 바로 Redis 클러스터다.
단일 Redis 서버의 한계
단일 Redis 서버는 구성이 간단하고 관리가 쉽다는 장점이 있다. 작은 규모의 프로젝트나 간단한 캐싱 용도로는 충분하다. 하지만 모든 데이터가 하나의 서버에 저장되기 때문에 확장성에 한계가 있다. 서버의 메모리 용량이 곧 저장할 수 있는 데이터의 한계가 된다.
또한 단일 서버는 단일 실패 지점이 됩니다. 이 서버에 문제가 생기면 전체 서비스에 영향을 미치게 되죠. 물론 마스터-슬레이브 구조로 일부 이런 문제를 완화할 수 있지만, 근본적인 해결책은 되지 못한다.
Redis 클러스터의 장점
Redis 클러스터는 이러한 단일 서버의 한계를 극복한다. 여러 Redis 노드로 구성되어 데이터를 분산 저장하기 때문에 훨씬 더 많은 데이터를 처리할 수 있다. 필요에 따라 노드를 추가하여 Scale-out(수평적으로 확장)이 가능하다.
가용성 측면에서도 큰 이점이 있다. 클러스터의 일부 노드에 문제가 생겨도 전체 서비스는 계속 운영될 수 있다. 자동 장애 조치(failover) 기능을 통해 마스터 노드에 문제가 생기면 자동으로 슬레이브 노드가 그 역할을 대신하게 됩니다.
클러스터 사용 시 주의할 점
하지만 Redis 클러스터가 만능은 아니다. 클러스터 구성은 단일 서버에 비해 훨씬 복잡하고, 관리에 더 많은 노력이 필요하다. 네트워크 통신도 증가하기 때문에 약간의 성능 오버헤드가 발생할 수 있다.
또한 Redis의 일부 기능은 클러스터 환경에서 제한될 수 있다. 예를 들어, 여러 키에 걸친 트랜잭션은 클러스터에서 사용할 수 없다. 이는 데이터가 여러 노드에 분산되어 있기 때문이다.
언제 클러스터를 고려해야 할까?
Redis 클러스터로의 전환은 신중히 결정해야 한다. 다음과 같은 상황이라면 클러스터를 고려해볼 만하다.
- 데이터 양이 단일 서버의 메모리 용량을 초과할 것으로 예상될 때
- 높은 수준의 가용성이 요구될 때
- 읽기/쓰기 성능을 더 높여야 할 때
- 미래의 확장을 고려한 아키텍처 설계가 필요할 때
참고
[REDIS] 📚 레디스 소개 & 사용처 (캐시 / 세션) - 한눈에 쏙 정리
https://tecoble.techcourse.co.kr/post/2021-09-01-redis/
