
커버링 인덱스
- 쿼리를 충족하는데 필요한 모든 데이터를 갖는 인덱스
- SELECT / WHERE / GROUP BY / ORDER BY 등에 활용되는 모든 컬럼이 인덱스의 구성 요소인 경우
- 커버링 인덱스를 잘 쓰면 조회 성능을 상당 부분 높일 수 있다.
실행 계획 살펴보기
Workbench
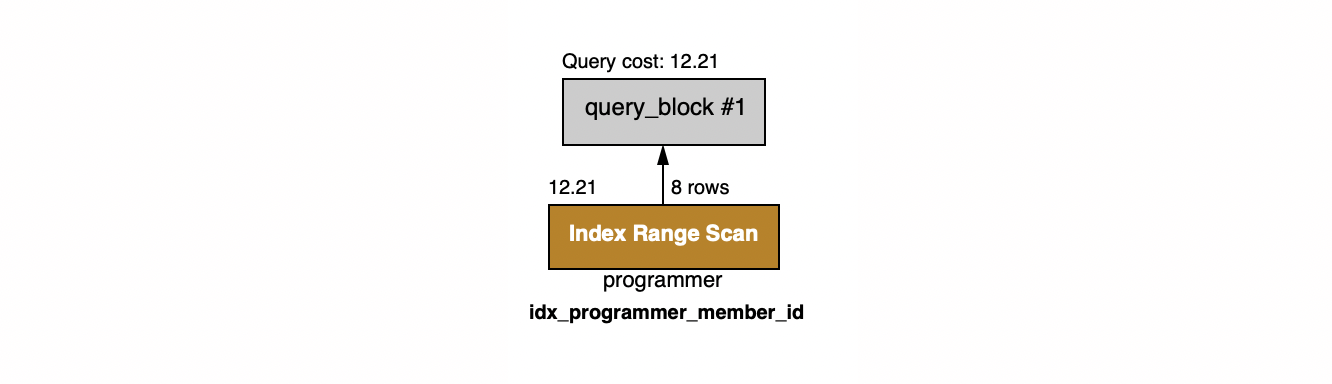
EXPLAIN
쿼리의 맨 앞에 EXPLAIN을 붙여 실행 아이콘보다 더 상세한 실행 계획을 확인할 수 있음.

id
SQL문이 실행되는 순서. 2개 행의 id가 같은 경우, 이는 조인된 것.
select_type
SELECT문의 유형
- SIMPLE: 단순한 SELECT문
- PRIMARY: 외부쿼리 또는 UNION이 포함되는 경우 1번째 SELECT문
- SUBQUERY: SELECT / WHERE에 작성된 서브쿼리
- DERIVED: FROM에 작성된 서브쿼리
- UNION: UNION 또는 UNION ALL로 합쳐진 SELECT문
type
- system: 0개 또는 1개의 데이터만 테이블에 존재하는 경우
- const: 단 1개의 데이터만 조회하는 경우
- eq_ref: 조인이 될 때, 드리븐 테이블의 PK 또는 고유 인덱스로 단 1개의 데이터만 조회하는 경우
- ref: eq_ref와 같지만, 2개 이상의 데이터를 조회하는 경우
- index: *Index Full Scan
- range: *Index Range Scan
- all: *Table Full Scan
key
옵티마이저가 실제로 선택한 인덱스.
rows
SQL문을 수행하기 위해 접근한 데이터의 모든 행 수.
extra
- Distinct: 중복을 제거하는 경우
- Using where: WHERE로 필터링한 경우
- Using temporary: 데이터 중간 결과를 위해 임시 테이블을 생성한 경우 (보통 DISTINCT / GROUP BY / ORDER BY가 포함되면 임시 테이블 생성)
- Using index: 커버링 인덱스를 사용한 경우
- Using filesort: 데이터를 정렬한 경우
실행 계획의 extra에 Using index가 나타나면, 이는 커버링 인덱스를 활용한 것으로 해석할 수 있다.
Non-clustered Key와 Clustered Key
| - | 대상 | 제한 |
|---|---|---|
| Non-clustered Key | 일반적인 인덱스 | 테이블에 여러 개 생성 가능 |
| Clustered Key | (1) PK (2) PK가 없을 땐, Unique Key (3) PK가 없고 Unique Key도 없을 땐, 6 bytes의 Hidden Key 생성 | 테이블당 1개만 생성 가능 |
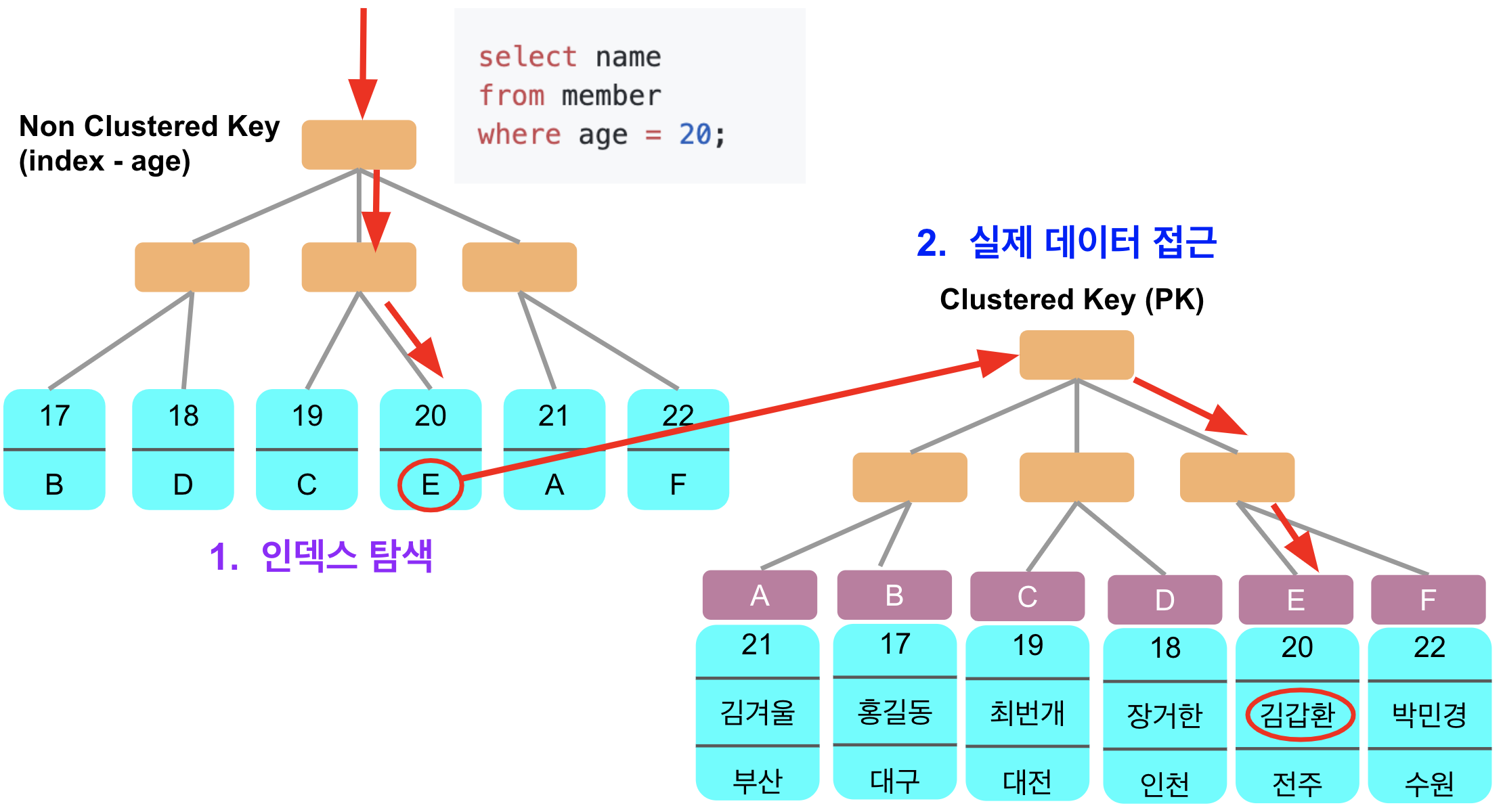
Non-clustered Key는 age에, Clustered Key는 PK에 인덱스가 존재. Non-clustered Key는 age 순으로, Clustered Key는 PK 순으로 정렬.
Non-clustered Key엔 데이터 블록의 위치가 없음. 인덱스 조건에 부합하는 WHERE가 있더라도, SELECT 문에 인덱스에 포함되어 있는 컬럼 외의 다른 컬럼 값이 필요할 때는 Non-clustered Key에 있는 Clustered Key 값으로 데이터 블록을 찾는 과정이 필요해짐.
결국 커버링 인덱스는 이미지의 2.실제 데이터 접근 과정 없이, 인덱스에 존재하는 컬럼 값으로만 쿼리를 완성하는 것을 의미.
출처
