구성
- 쿠키
- 프록시 서버
- 데이터 최신 여부 확인 방법
- 요약
이 정리는 23-2에 수강한 컴퓨터 네트워크 강의를 기반으로 하였습니다.
cookie
유저의 접속 이력을 저장하는 파일. 그리고 사이트가 사용자를 추적할 수 있도록 하기 위한 기술이다.
대부분의 웹사이트는 쿠키를 사용한다. 원래 HTTP는 stateless로 과거에 대한 이력이 없었지만, 쿠키를 사용하면 stateful한 프로토콜로 바꿔줄 수 있는 장점이 있다.
쿠키는 아래 4가지 요소를 갖고 있다.
- HTTP 응답 메세지 쿠키 헤더 라인
- HTTP 요청 메세지 쿠키 헤더 라인
- 사용자의 브라우저에 사용자 종단 시스템과 관리를 지속시키는 쿠키 파일
- 웹사이트의 백엔드 DB
1. HTTP 응답 메세지 쿠키 헤더 라인
HTTP 응답 메세지는 서버가 보내는 것이다. 그리고 이 메세지에는 헤더 라인이 있다는 것을 배웠다. 만약 쿠키 기능이 있는 웹 서버라면 이 헤더라인에 특별한 라인이 하나 더 추가되는데 이게 쿠키 헤더라인이다.
2. HTTP 요청 메세지 쿠키 헤더 라인
HTTP 요청 메세지를 보낼 때 만약 응답에 쿠키 헤더 라인이 있었다면 이걸 포함시켜서 요청을 날린다는 의미이다.
3. 사용자의 브라우저에 사용자 종단 시스템과 관리를 지속시키는 쿠키 파일
쿠키 파일은 유저 호스트(client pc)에 저장된다. 파일이므로 공간을 차지하니 쿠키를 지울 수 있는 기능이 브라우저에 존재하는 것이다.
쿠키 파일은 브라우저가 접근하고 관리한다.
4. 웹사이트의 백엔드 DB
예시
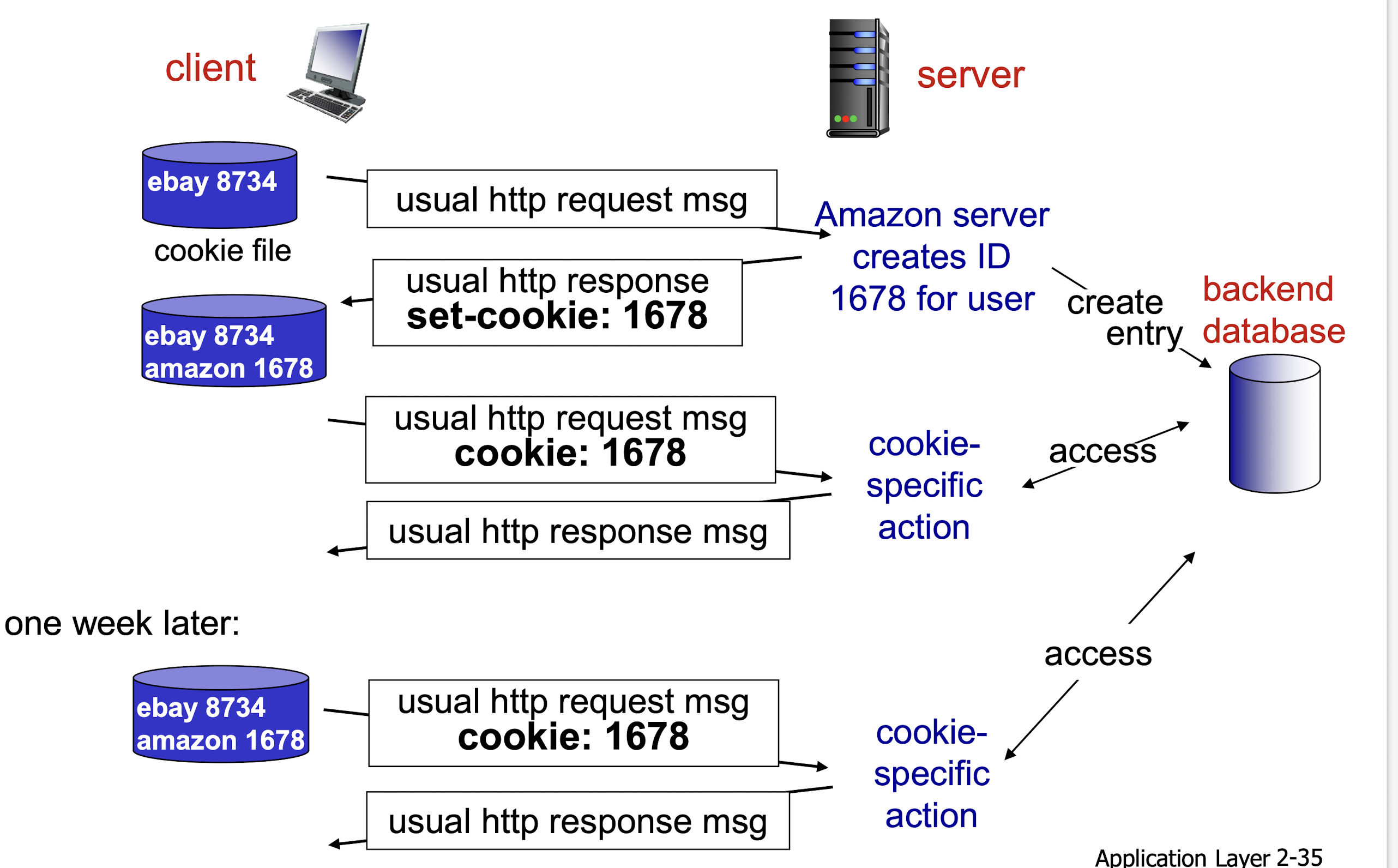
한 유저가 본인의 pc를 이용해서 쿠팡에 처음 방문했다. 그러면 initial HTTP request(쿠팡 메인 페이지를 보여달라는 내용)가 쿠팡 웹 서버에 도착한다(이 요청에는 쿠키 헤드라인이 없음). 그러면 웹 서버가 다른 유저와 중복되지 않는 유니크한 아이디를 만들고 이를 백엔드 데이터베이스에 저장한다.
그리고 서버는 쿠키 헤더라인을 추가하고, set-cookie로 만들었던 유니크한 아이디를 포함시켜 응답 메세지를 보낸다. 이렇게 한번의 round-trip이 발생한다.
아래 이미지는 실제로 쿠키 헤더가 포함된 response message이다. (회색 영역 타이틀 확인)
(이미지에서 가려진 부분이 유니크한 아이디이다. 보통은 암호화되어 전달된다)
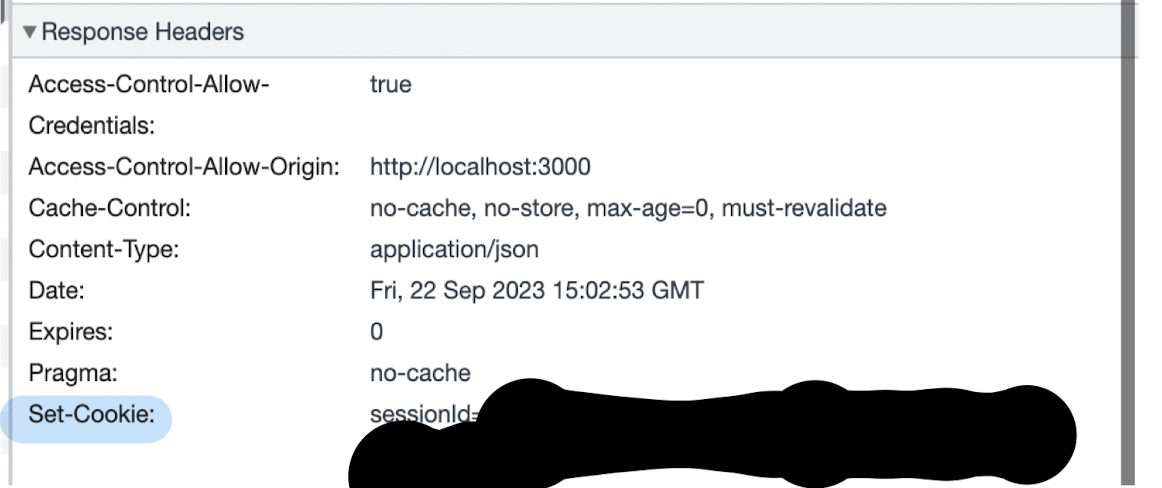
응답 메세지를 받으면 브라우저는 관리하는 특정한 쿠키 파일에 이 라인을 덧붙인다. ( + 만약 다른 웹사이트에 접근했던 기록이 있고 쿠키를 받았다면 이 웹사이트의 쿠키 또한 이 파일의 엔트리를 갖고 있다.)
아래 이미지는 실제 request message이다. (회색 영역 타이틀 확인)
request header에 cookie가 달려있는 것을 볼 수 있다.
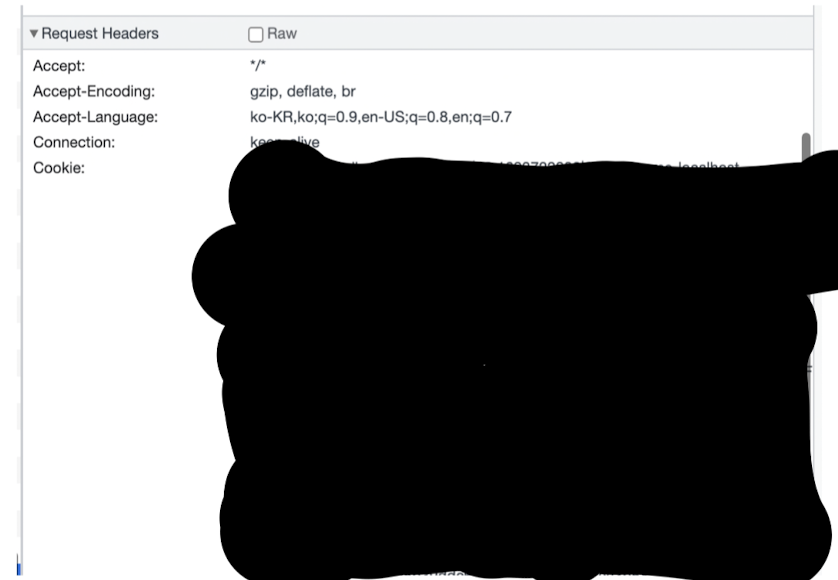
그 이후 바로 요청이 아니더라도 언젠가 요청할 때 브라우저가 과거 응답 메세지에 담겨있던 쿠키 헤더라인을 추가해서 서버에 요청한다.
이런 방식으로 웹 서버가 유저의 쿠팡 사이트에서의 활동을 추적할 수 있다.
왜 유니크한 아이디?
기기를 식별하는 데에는 IP 주소를 사용하는데 굳이 번거롭게 유니크 아이디를 만들어서 유저를 기억할 필요가 있을까?
이는 클라이언트의 특성을 생각해보면 당연한 얘기다. 클라이언트는 한 곳에 머물러 있지 않을 수 있어 동적 IP 주소를 갖는데, 이렇게 되면 이동할 때마다 유저는 IP가 바뀌고 쿠키도 새로운 것이 되기 때문에 결국 쿠키의 stateful한 장점이 사라지게 된다.
따라서 구태여 아이디를 만들어 유저를 식별하고 관리하는 것이다.
웹 캐시(web caches, 프록시 서버)
프록시 서버(proxy server)의 proxy는 가짜라는 의미를 갖고 있다. 이는 진짜인척 하는 가짜 서버를 둔다는 뜻이다. 프록시 서버의 목적은 진짜 서버의 도움을 받지 않고 클라이언트의 요청을 응답하기 위한 것이다.
클라이언트가 요청을 오리진 서버에 보내면 중간의 프록시 서버(웹 캐시)가 일단 이 요청을 가로챈다. 다만 클라이언트는 프록시 서버의 존재를 인지하지 못하고 오리진 서버에 요청을 보냈다고 생각한다(알 필요가 없기때문).
만약 요청에 필요한 데이터가 프록시 서버에 있다면 그걸 보낸다. 만약 없다면, 오리진 서버에게 요청해 데이터를 받아오고 그것을 자신인 프록시 서버에 저장한다. 그리고 사본을 요청했던 클라이언트에게 보낸다.
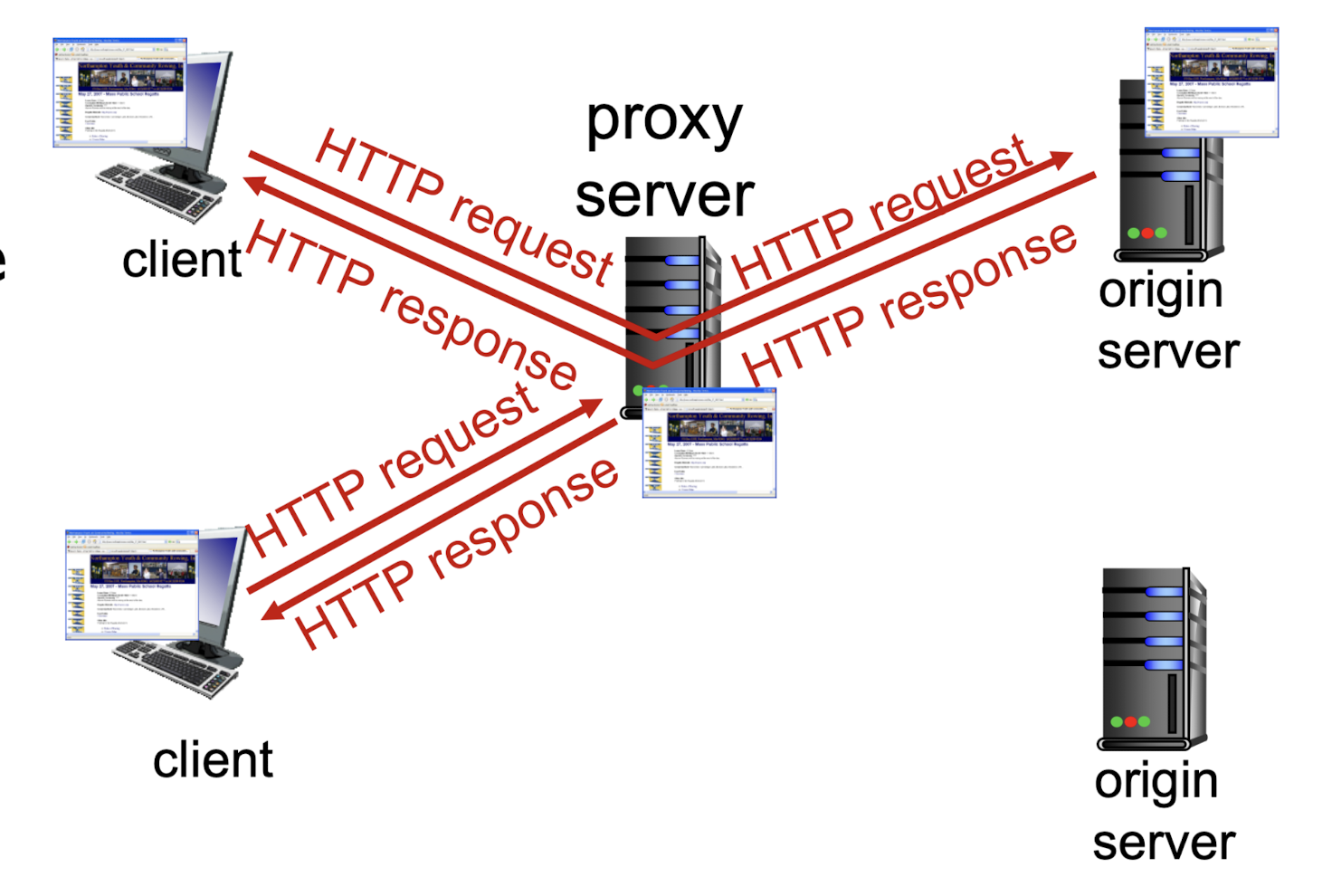
프록시 서버(웹 캐시)는 요청을 받고, 요청을 보내는 행동을 둘 다 할 수 있기 때문에 서버이면서 클라이언트이기도 하다.
장점
예로 인하대 내부와 외부 사이 라우터 근처에 프록시 서버를 둘 수 있다. 이를 통해 자주 방문하는 사이트가 저장되어 교직원과 학생들은 사이트에 빠르게 접속할 수 있다는 장점이 있다. 요청과 응답이 먼 거리를 왕복하지 않아도 되어 빨라지는 것이다.
그리고 먼 거리까지 링크를 타고가는 것은 비용이 드는 행위이다. 따라서 인하대학교가 프록시 서버를 두고 요청을 가로챈다면 더 멀리 오리진 서버로 가서 요청과 응답을 받아야하는 비용을 줄일 수 있다.
또한 오리진 서버는 트래픽을 줄어 부담이 낮아지므로 이득이다.
실제 딜레이 감소 예측
프록시 서버를 사용하면 교직원과 학생들은 더 낮은 딜레이로 원하는 사이트에 접속할 수 있다고 했다. 그러면 실제로 얼마나 빨라지는 걸까?
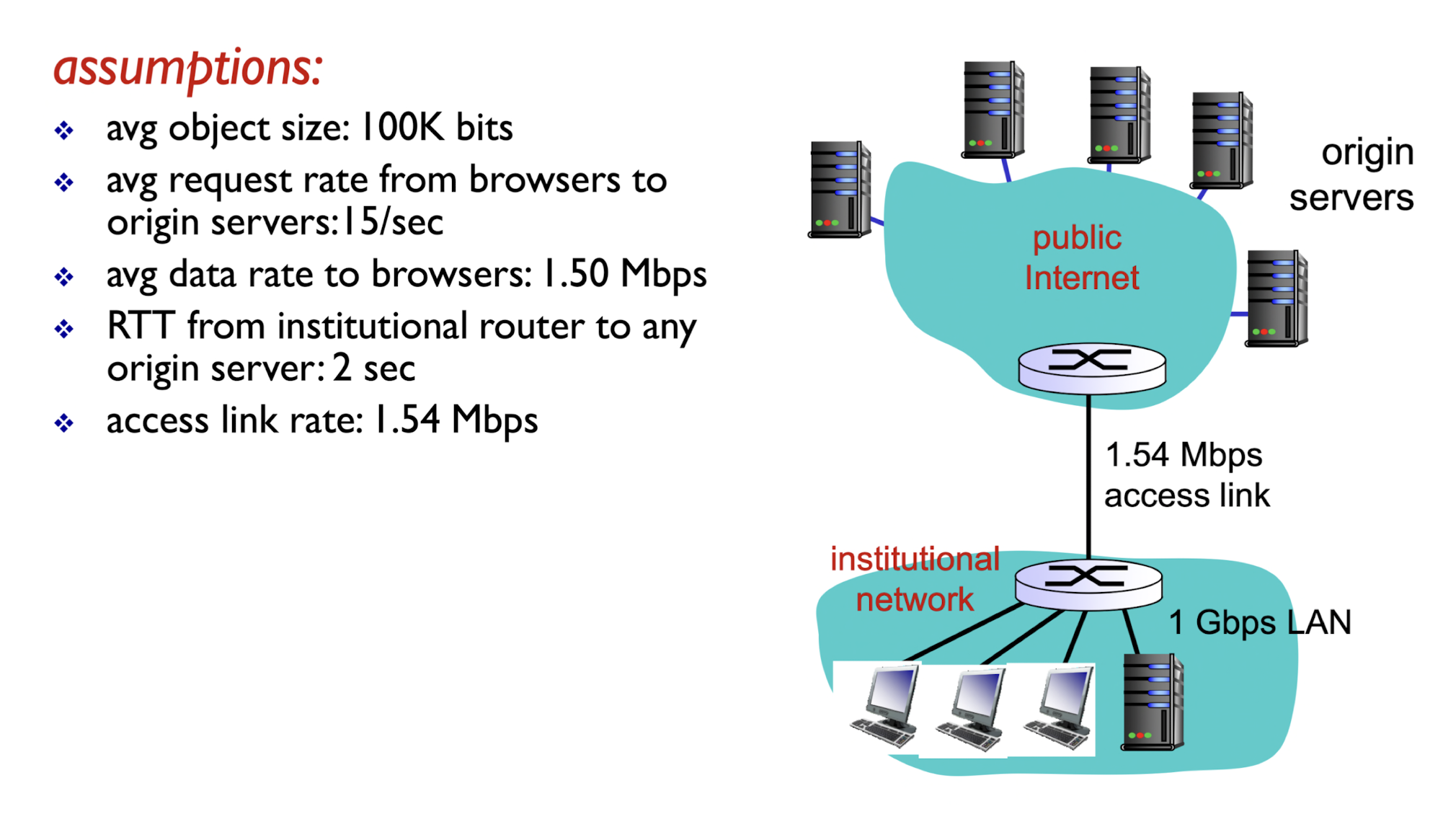
평균 오브젝트 사이즈 = 100K bits / 클라이언트들에서 오리진 서버로의 평균 요청 비 = 15/sec / 평균 데이터 전송 속도 = 1.5 Mbps / 서버-클라이언트 링크의 데이터 전송 속도 = 1.54 Mbps / RTT from instituitional router to any origin server = 2 sec
이렇게 조건을 설정해보자.
1.5 Mbps는 평균적으로 1초에 1.5Mb씩 전송이 되고있다는 의미인데 이게 링크의 전송률과 거의 비슷하다. 이는 Traffic intensity가 거의 1에 가깝다는 뜻이다. 즉 평균적으로 저렇다는 거지 실제로 갑자기 요청이 쏟아질 수도 있으므로, 실제 딜레이는 이전에 배웠듯이 매우 클 것이다.
하지만 클라이언트 쪽은 1Gbps 랜을 사용하고 있어 Traffic intensity가 약 15% 정도로 널널하다.
이 경우 총 딜레이는 오리진(코어) 쪽은 RTT -> 2초이고, 액세스 링크를 통과할 때 트래픽 강도가 매우 높으므로 딜레이를 n 분이라고 가정해보자. 클라이언트 쪽은 트래픽 강도가 15% 정도 밖에 안되므로 n 분에 비해서 매우 낮은 수치일 것이다. 따라서 총 딜레이는 최소 n 분이다.
sol 1
그럼 액세스 링크를 증설해 해결할 수 있을까?
1.54Mbps -> 15.4Mbps로 100배 증가시켰다고 해보자. 이렇게 되면 트래픽 강도가 9.9 정도로 낮아진다.
다만 이렇게 해도 총 딜레이에 최소 RTT 2초가 필요한건 여전하다. 실제 클라이언트 관점에서 2초도 매우 큰 딜레이이므로 좋은 해결책은 아닌 것 같아 보인다.
sol 2
sol 1의 10배 또는 100배 만큼의 링크 증설은 많은 비용이 든다.
돈을 많이 쓰는 것 보단 프록시 서버(로컬 캐싱 서버)를 둬서 해결할 수 있을 것 같다. 이렇게 되면 액세스 링크 사용률이 감소한다. 굳이 오리진 서버까지 갈 필요가 없으니까 링크를 탈 필요가 없는 것이다. 그럼 원래의 사용률인 99%를 더 떨어뜨릴 수 있다.
여기서 관건은 클라이언트가 요청하는 것이 얼마나 프록시 서버에 저장이 되어있느냐이다. 프록시 서버가 텅 비어있다면 결국 초기의 상태(태초마을)로 돌아가는 것과 똑같아 n분의 딜레이를 맞이하게 된다. 따라서 이 요청에 필요한 데이터를 갖춰 오리진 서버를 대신해 얼마나 서포트 할 수 있느냐를 hit ratio이라고 한다.
hit ratio가 1이면 모든 요청에 필요한 데이터를 다 갖추고 있다는 뜻이므로 액세스 링크를 탈 필요가 없어져 딜레이 감소에 큰 이득을 얻을 수 있다. 따라서 이 hit ratio가 성능의 척도가 된다.
hit ratio가 0.4만 되도 99%의 사용률에서 58%로 감소하기 때문에 비교적 널널해진다. 순간 요청이 많아져도 여유가 있게됐다.
이때의 총 딜레이는 0.4(캐시 접근 딜레이) + 0.6(오리진 서버 딜레이)로 계산할 수 있다. 대충 계산해봐도 원래의 상태보다 딜레이가 줄어든 걸 알 수 있다. 이래서 프록시 서버를 많은 곳에서 사용한다.
또한 더 딜레이를 감소시키기 위해선 hit ratio를 높이기 위한 알고리즘이 필요하다.
업데이트 확인
다만 의문이 들었을 수 있다.
프록시 서버가 갖고 있는 데이터가 오리진 서버의 데이터와 비교해서 과연 최신화(업데이트)가 된 데이터인지를 어떻게 아는 것일까? 만약 과거의 데이터라면 큰 혼란가 생길 수도 있으므로 이는 중요한 문제다.
sol 1
단위 시간마다 요청을 보내 확인하는 방법이 있다.
다만 이 단위 시간이라는걸 어떤 기준으로 잡는지, 그리고 단위 시간이 지나기 전에 이미 수정이 되었을 수도 있으므로 실효성이 없어보인다.
sol 2
오리진 서버가 업데이트 될 때마다 프록시 서버에게 알리는 방법도 있다.
하지만 서버는 프록시 서버와 진짜 클라이언트를 구분할 수 없다. 왜냐면 프록시 서버도 클라이언트와 똑같은 요청 메세지를 보내기 때문이다. 결국 프록시 서버만을 지목해서 응답을 보낼 수 없기에 만약 클라이언트가 10억명이라면 이 10억명 모두에게 새로운 정보로 바뀌었음 메세지를 보내야해 비효율적이다.
sol 3 = sol 1 + sol 2
세번째 방법은 1과 2방법을 합쳐보는 것이다.
클라이언트가 요청이 와서 프록시 서버가 데이터를 확인한다. 프록시 서버는 히트가 되더라도 오리진 서버에 HTTP request를 보낸다. 단 액세스 링크의 트래픽을 줄이기 위해 데이터의 헤더 파일만 요구한다. 헤더 파일에 실제 데이터는 포함되지 않아 크기가 작다. 프록시 서버는 헤더 파일을 응답받고 여기에서 last-modified 만 확인하여 프레시한 데이터인지 확인할 수 있는 것이다.
그런데 만약 프레시한 데이터가 아니라면 다시 요청을 해서 시간을 들여 받아와야하는 문제가 생긴다. 이를 해결하기 위해 contitional get을 사용할 수 있다.
요청을 보낼 때 프록시 서버가 갖고 있는 데이터의 업데이트 날짜를 담아 요청을 보내는 것이다. 오리진 서버에서 받은 업데이트 날짜가 프레시하지 않으면 실제 데이터를 담아 보내고, 프레시하다면 헤더만 보낸다. 이렇게 두 번 왕복할 필요 없이 한 번으로도 프레시한 데이터를 받아올 수 있다.
2번 방법을 응용해서, 오리진 서버가 데이터를 줄 때 언제까지 이 페이지가 유효할지에 대한 정보를 응답에 포함해서 주는 방법도 있다. 1시간 또는 1일 주기로 바뀐다고 알려주는 것이다. 그러면 적어준 라이프타임을 기준으로 업데이트할지 말지를 알 수 있다.
요약
- 쿠키: 브라우저 탐색 기록을 저장, 유저 식별 용도로 사용
- 프록시 서버: 오리진 서버 복사 창고
- 데이터 최신 여부 확인 방법: 컨디셔널 겟 || 라이프 타임
잘못된 내용이 있으면 pigkill40@naver.com 으로 연락주시기 바랍니다

잘 읽었습니다. 혹시 컴퓨터 네트워크 강의는 어디에서 볼 수 있나요? 책이나 사이트가 있다면 알려주실 수 있나요?? 감사합니다:)