시작하기
신뢰성을 가진 프로토콜은 이미 TCP라고 우리는 이미 알고있다.
하지만 그냥 그렇다고 받아들인 것일 뿐 깊이 이해하고 있는게 아닐 수 있다. 따라서 TCP가 어떻게 순서를 맞추고, 어떻게 오류를 잡고, 어떻게 재전송을 요청하는지 등에 대한 자세한 과정을 단계별로 직접 만들어보며(FSM 정도로) 이해해보려고 한다. 최종적으로는 TCP에 가까운 protocol을 만드는 것이 목표다.
rdt
APP 계층은 본인이 reliable한 데이터 전송을 맡고싶지 않아한다. 다른 업무에 집중하기 위해서이다. 애초에 계층을 나눈 이유는 업무를 분담해 효율적인 유지보수와 편의성을 위함이니..
그래서 TP계층에서 reliable한 데이터 전송을 맡아야한다. TP의 바로 아래 계층인 NET 계층은 unreliable하다. 패킷 순서가 뒤죽박죽으로 올 수도 있고, 오류를 봐도 모르고, 패킷이 오다가 로스되도 알지 못한다는 의미다.
따라서 이 NET 계층에 재전송을 명령하고, 순서를 맞추는 등의 일을 TP가 해야한다.
APP - TP - NET 으로 직접 연결되어있으니 TP는 APP, NET 이렇게 둘만 소통할 수 있으면 된다. 이제 소통을 위한 인터페이스 함수를 배워보자.
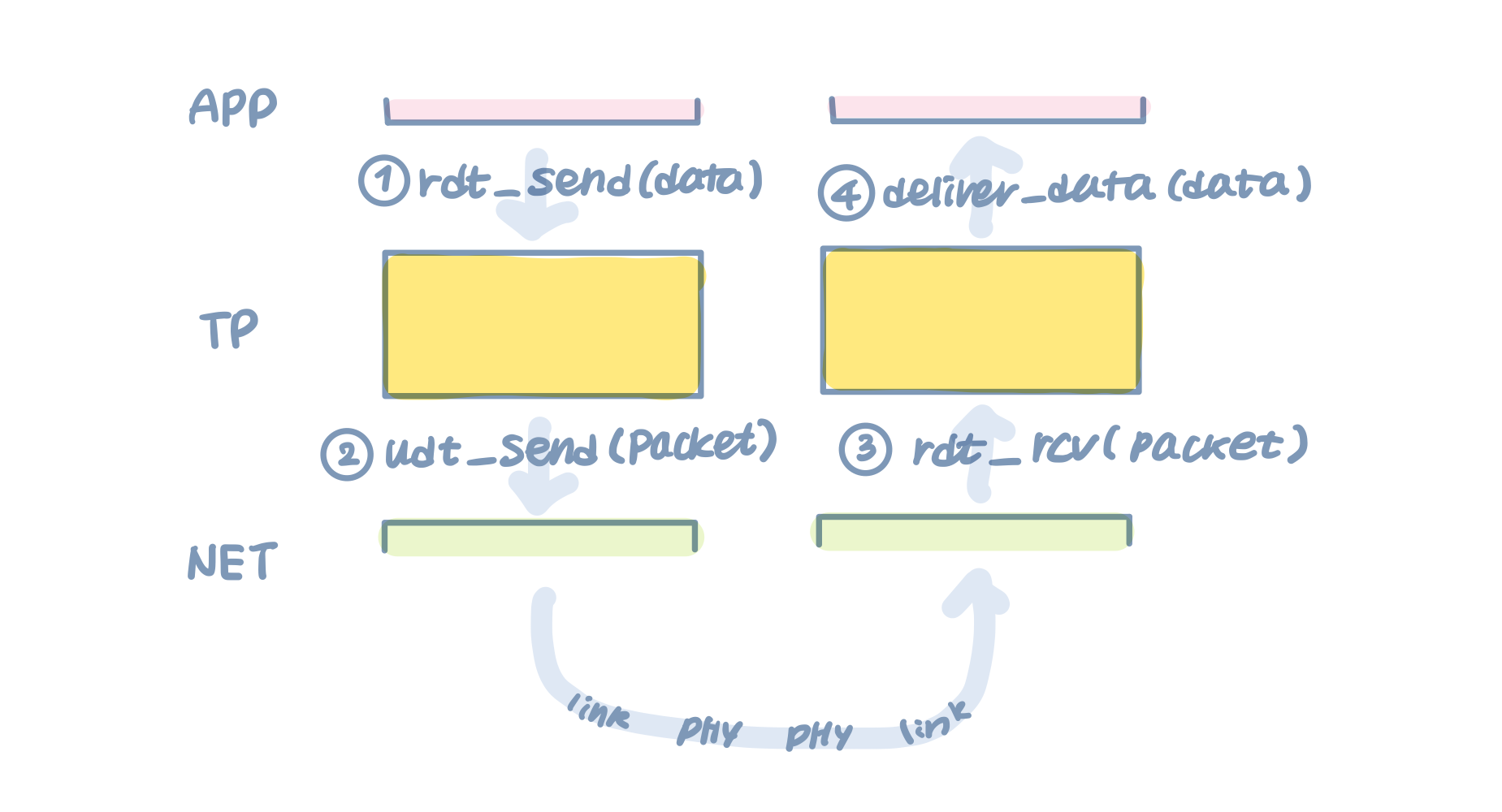
APP이 다른 APP으로 데이터를 송신하려고 한다. 그러면 TP 계층에게 data를 담아 rdt_send(data)를 호출한다. 이 데이터를 신뢰성있게(reliable) 전송(send)해달라는 의미로 rdt_send라는 이름이 붙여졌다.
그리고 그 데이터를 받은 TP는 데이터에 TP 헤더를 붙이고 아래 계층인 NET 계층으로 udt_send(packet)를 한다. NET은 unreliable이기 때문에 udt(unreliable data transfer)가 붙어있다.
그리고 하위 계층은 맡은바 충실하게 수신측의 종단으로 데이터를 보내줄 것이다.
그렇게 타고 올라와 NET까지 오면 NET은 rdt_rcv(packet)로 받아온 패킷를 올려보낸다. 신뢰성있게 데이터를 조작하란 의미에서 rdt가 붙어있다.
TP는 TP 헤더를 빼고 온전한 데이터만을 deliver_data()로 APP에게 올려보낸다.
이렇게 배운 4개의 기초적인 인터페이스 함수를 가지고 rdt를 바닥부터 설계해보자. 지금부턴 FSM(finite state machine) 개념이 필요하다.
rdt 1.0
일단 가장 간단하게 손실도 일어나지 않고 비트 에러도 일어나지 않는 reliable 네트워크 상황이라고 가정하자. 손실을 위한 재전송 요청을 할 필요도 없고, 에러 체킹도 안해도 된다는 뜻이다.
FSM은 sender와 receiver 입장 이렇게 2개를 생각해야한다.
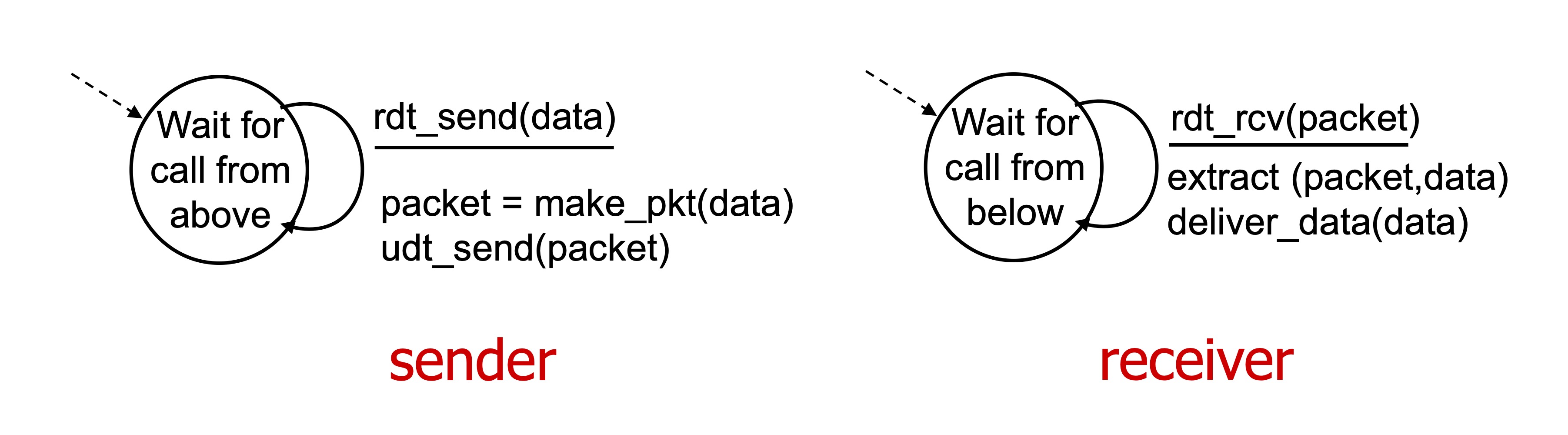
아주 간단한 FSM이다. 흐름을 따라가보면서 이해해보자.
sender는 APP 계층에서 데이터가 내려오길 기다리고 있는 상태다. 그러다 rdt_send(data)로 이벤트가 발생하면 TP에서 패킷을 만든다. 직관적이게 make_pkt(data)로 만들수 있다. 그리고 이렇게 만들어진 패킷을 udt_send(packet)으로 NET 계층에게 전달한다. 그리고 다시 APP 계층에서 데이터가 내려오길 기다리는 상태로 돌아간다.
receiver는 NET에서 패킷이 올라오길 기다리는 상태다. 그러다 rdt_rcv(packet)으로 패킷이 올라오면 extract(packet, data)로 이 패킷에서 데이터를 추출한다(TP 헤더가 붙어있으므로 이를 떼어내는 것). 이렇게 추출한 data를 deliver_data(data)로 APP 계층에게 올려보내 업무를 마치고 다시 아래 계층에서 패킷이 올라오길 기다리는 상태로 돌아간다.
이렇게 간단한 rdt 1.0을 설계했다. 하지만 실제 네트워크는 지금 가정처럼 호락호락하진 않다. 조건을 하나씩 추가해가면서 튼튼한 rdt를 설계해보자.
rdt 2.0
이번엔 이 네트워크에 비트 에러가 발생할 수 있다고 해보자. 비트 에러를 판단하고 어떤 action을 할지 생각해보자.
이 비트 에러는 체크섬 필드로 발생 여부를 파악할 수 있다. 따라서 비트 에러가 발생했다고 판단되면 재전송을 요청하면 되고, 아니라면 1.0에서 하던대로 올려보내면 되는 간단한 로직을 추가하면 된다.
비트 에러가 발생했으니 재요청을 해야하는데, 이건 어떻게 구현할 수 있을까? sender측에서 데이터가 깨끗하게 잘 보내졌는지 아닌지를 알 수 있어야 한다. 이는 지금부터 ack(aknownledgements)와 nak(negative aknownledgements)로 판단할 것이다. receiver가 잘 받았으면 sender에게 ack를 보내고, 오류 패킷을 받았으면 nak를 보내 재전송을 요청하는 것이다. 마찬가지로 sender는 데이터를 보내고, receiver에게서 오는 ack또는 nak를 기다린다. ack가 오면 잘 보내졌다고 판단하고 해당 데이터에 관한 업무를 끝낸다. 만약 nak가 오면 보냈었던 데이터를 다시 전송하고 다시 ack or nak를 기다린다.
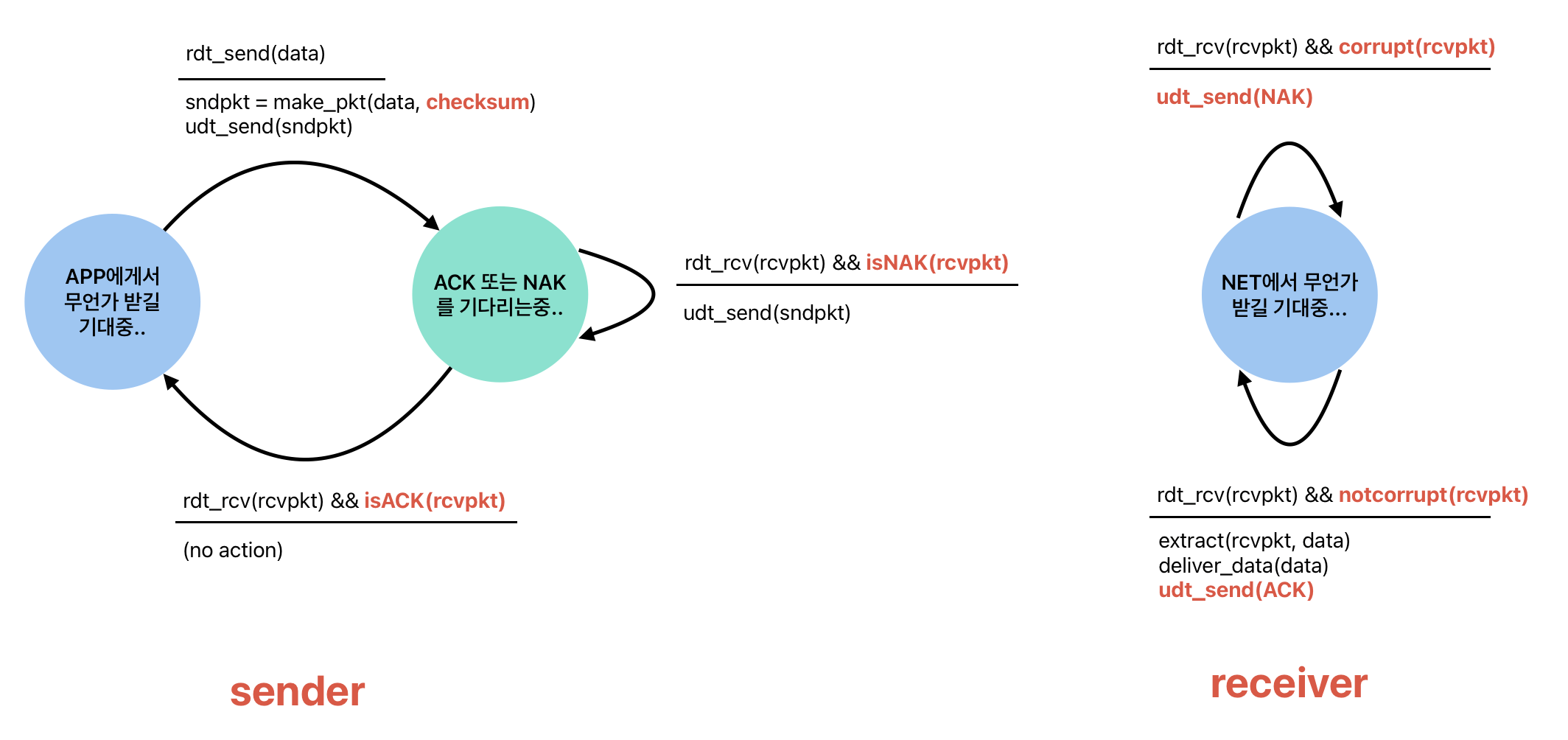
복잡해진 것 같지만 추가된 건 빨간색으로 표시한 요소들 뿐이다. 하나씩 살펴보자.
sender가 APP에게 데이터를 받으면 이를 make_pkt함수를 통해 sndpkt(send packet)을 생성한다. 이때 make_pkt에 checksum이 추가되었는데 이는 필드에 체크섬을 추가하겠다는 간략화된 표현이다. 이제 receiver가 이 체크섬을 보고 비트 에러를 파악할 수 있는 것이다. 그렇게 만들어진 패킷을 전송하고 ACK || NAK를 기다리는 상태로 이동한다. (이때 받는 패킷은 ACK || NAK이므로 가볍다.) 그리고 받은 패킷이 ACK냐 NAK냐에 따라 action이 달라진 모습을 알 수 있다.
receiver는 corrupt(rcvpkt)으로 비트 에러를 판단한다. 이 함수 내부에서 체크섬을 해독해 비트 에러 발생 여부를 알 수 있는 것이다. 이렇게 받아온 패킷에 에러가 있다면 NAK를 보낸다. 만약 없다면 1.0에서 하던대로 추출후 APP에 전달 하고 ACK 패킷을 보내 sender에게 잘 받았다고 알려준다.
이렇게 비트 에러를 확인하고 재전송 요청이 로직이 추가된 rdt 2.0이 완성되었다.
이제 다른 문제 상황도 추가해보자.
rdt 2.1
왜 다음 3.0이 아닌 2.1인지 의문이 생길 수 있다. 그 이유는 rdt 2.0에는 설계 구멍이 다수 존재하기 때문이다.
ACK, NAK도 패킷인데 비트 에러가 일어날 수 있다는 생각을 미처 하지 못했던 것이다. receiver는 멀쩡한 ACK를 보냈지만, 혼란이 가득한 네트워크를 지나오면서 ACK인지 NAK인지 구분하지 못할 정도로 많이 꼬인 패킷이 왔다고 해보자. sender입장에선 일단 재전송하는게 최선이니 다시 보낸다고 한다면, receiver는 2개의 같은 데이터를 받은 것이 된다. 그런데 receiver는 중복 패킷을 구분하지 못한다. 따라서 똑같은 데이터를 APP으로 2개 올려보낸 것이 된다. 그러니 중복 패킷이 오면 이를 discard하는 로직이 필요하다.
그말은 즉 중복 패킷 여부를 알아야 한다는 뜻이고 이는 이전 패킷을 저장하고 있다가 새로 들어온 패킷과 비교하는 로직이 필요하게 된다. 그러나 패킷이 크다면 이 과정이 오래걸릴 수 있다. 따라서 패킷들을 구분할 수 있도록 sequence number를 추가해보자. 그러면 크기가 작은 시퀀스 넘버만 저장해 중복 여부를 빠르게 판단할 수 있게된다. 이때 시퀀스 넘버는 이전 패킷만 비교 대상이므로(당연히 아니라는 걸 알겠지만 일단 try) 0과 1로만 구분하면 되겠다. (4개 패킷이 있다면 0, 1, 2, 3으로 구분되는 것이 아니라 0, 1, 0, 1로 구분된다는 의미다. 결국 중복을 바로 직전 패킷으로만 판단하는 2.1의 한계)
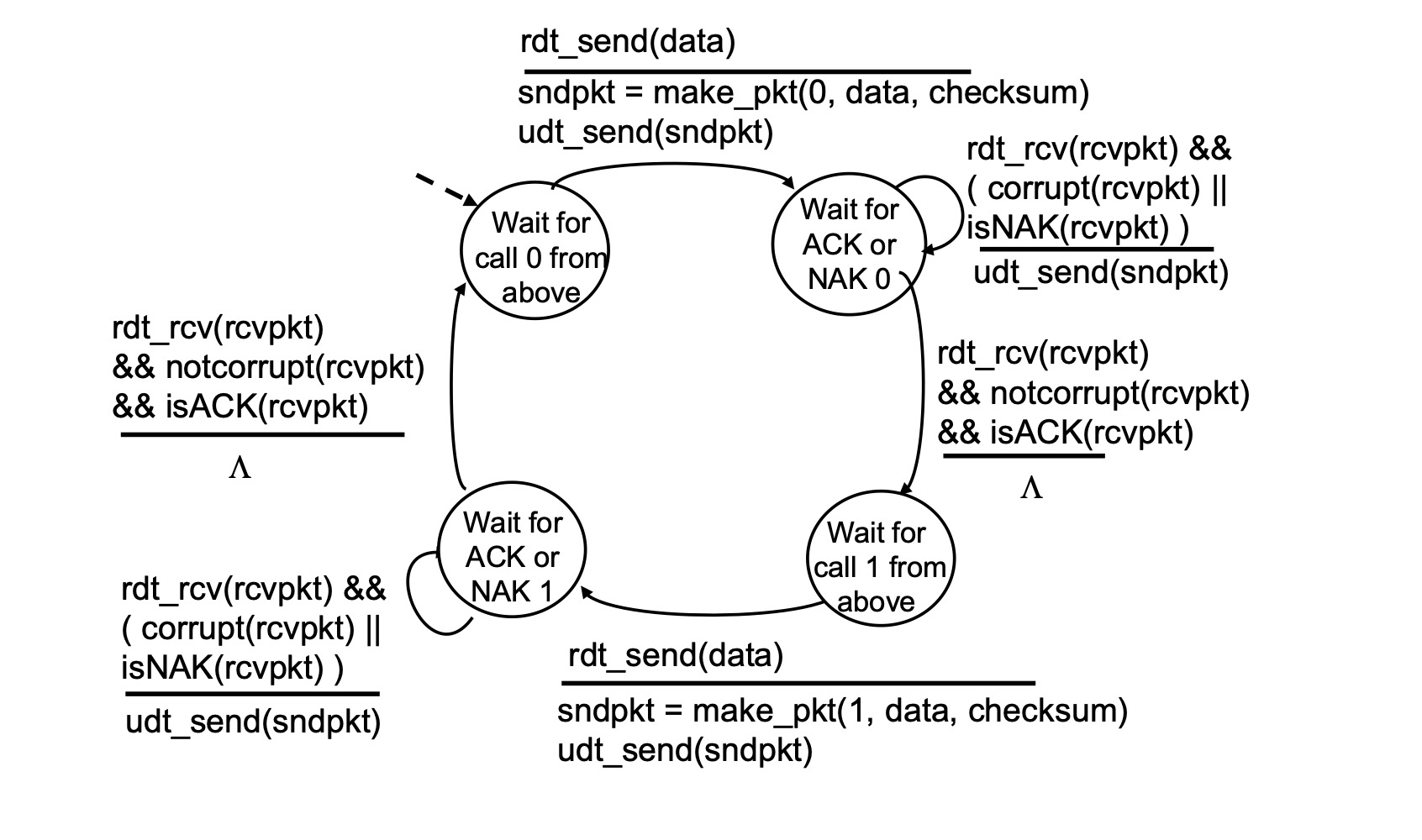
sender는 이제 패킷에 0, 1이라는 시퀀스 넘버를 담아야 한다. 0을 보낼 차례, 1을 보낼 차례가 구분되어야 하므로 상태로 분리되어있다.
0을 보내야하는 상태는 make_pkt에 0을 담아 패킷을 만들고 보낸다.
그리고 이렇게 보낸 0번 패킷이 잘 도착했는지, 아닌지 기다리는 상태인 wait for ACK or NAK 0이 된다. 이 패킷에도 비트 에러가 있는지 판단해야하기 때문에 corrupt()로 여부를 확인하는 함수가 추가됐다. 만약 비트에러가 있다면 재전송이 최선이므로 재전송한다.
멀쩡한 ACK라면 1을 보내야하는 상태로 진입해 데이터가 내려오면 1을 담아 패킷을 만들어 보낸다. 그 후 0번 때와 마찬가지로 ACK 1 || NAK 1을 기다리는 상태로 간다.
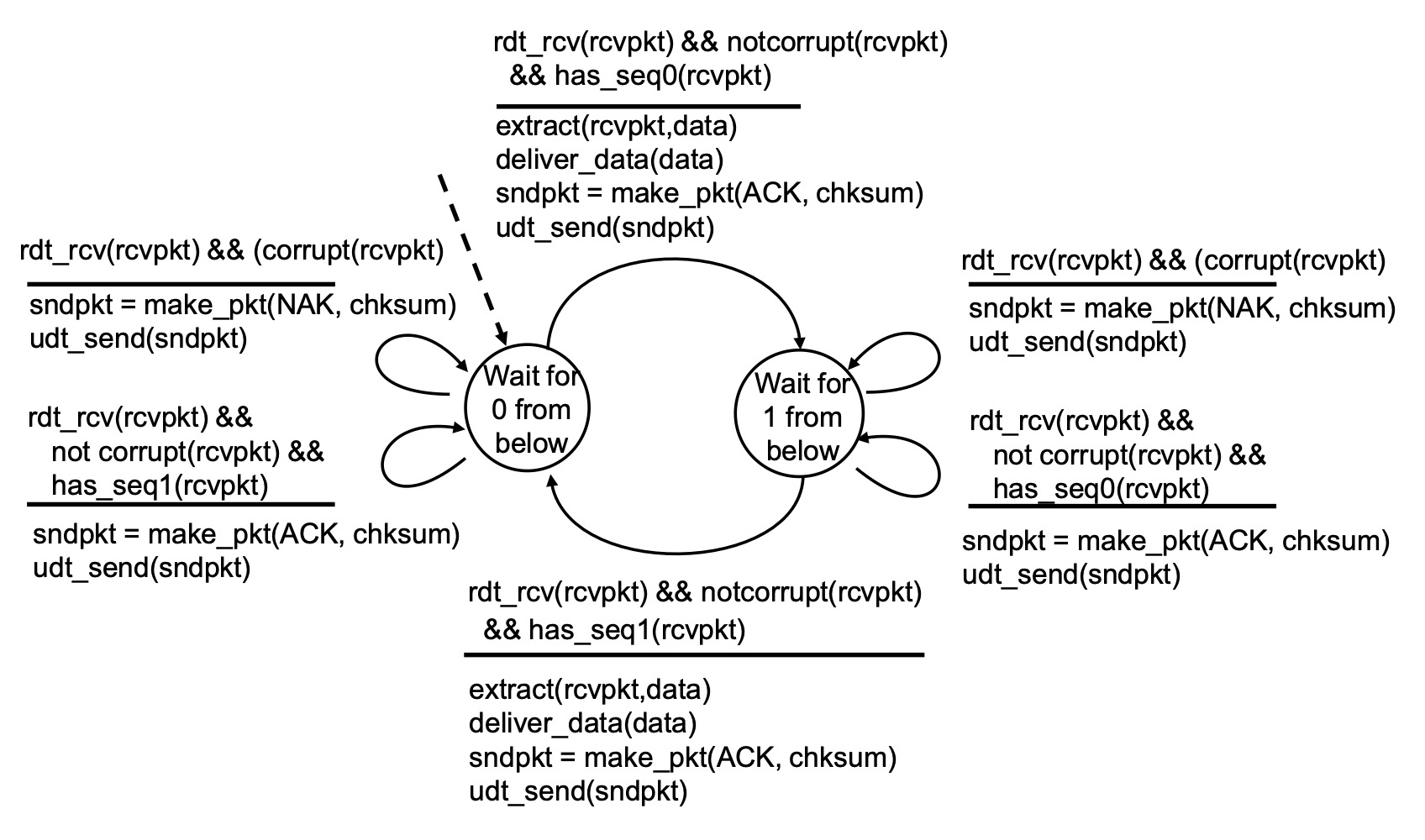
앞에서 ACK, NAK에도 비트 에러가 있을 수 있다 했으므로, 이를 판단하기 위한 체크섬을 추가해야한다.
시작은 0번 패킷을 기다리는 상태이다. 그렇게 받은 데이터 패킷에 오류가 있다면 NAK와 체크섬을 함께 보낸다. 오류가 없는데 이미 받았던 1번 패킷이 왔다면 ACK에 비트 에러가 났거나 ACK가 NAK로 변해서 도착했다는 의미다. 그러니 receiver는 최선인 재전송을 수행하고 상태는 1번 ACK또는 NAK를 기다리는 상태로 바뀌었을 것이다. 따라서 ACK를 보내 이전에 왔던 패킷 1이 잘 왔다고 알려준다. 이때 명시적으로 discard함수가 있진 않지만 아무 행동을 안하고 있으므로 암묵적으로 중복 패킷이 버려지게 된다.
만약 비트 에러도 없고 받아야할 순서도 잘 지켜진 패킷이 도착했다면, 했던대로 추출하고 위로 올리고 체크섬과 함께 ACK를 보낸다. 그리고 0번 패킷을 기다리는 상태로 바뀐다.
이때도 마찬가지로 비트 에러가 나거나 순서가 다른 패킷을 받았을 때 동일한 action을 취해 대응한다. 사실 대각선으로 나눠 대칭인 모습이다.
이렇게 ACK, NAK 패킷 비트 에러, 중복 패킷 비교, 중복 패킷 버리기 대응을 추가한 rdt 2.1이 완성되었다.
rdt 2.2
그런데 생각해보면 굳이 ACK가 있어야 할까? 2.1상황에서 receiver가 0번을 받아야하는데 이전 패킷인 1번이 온 상황에 대해서 어떻게 대응한다고 했는지 생각해보자. 답은 ACK를 보내 1번이 온전히 잘 왔다고 다시 알려주는 것이었다. 데이터 패킷에 비트 오류가 발생한 경우에 대해서도 이와 똑같이 대응해도 되지 않을까? 기껏 받은 1번 패킷에 오류가 났다면 ACK 0으로 이전 패킷까진 잘 받았다고 알려주는 것이다. 그럼 sender는 "분명 1번을 보냈는데 0이 온걸 보니 문제가 있나보네, 다시 1을 보내자"가 되어 결국 NAK가 없어도 잘 동작하는 상황이 만들어졌다.
그럼 이제부터 ACK에 시퀀스 번호를 붙여 sender에게 보내야할 것이다. 어떤 것을 잘 받았는지 알아야하기 때문이다.
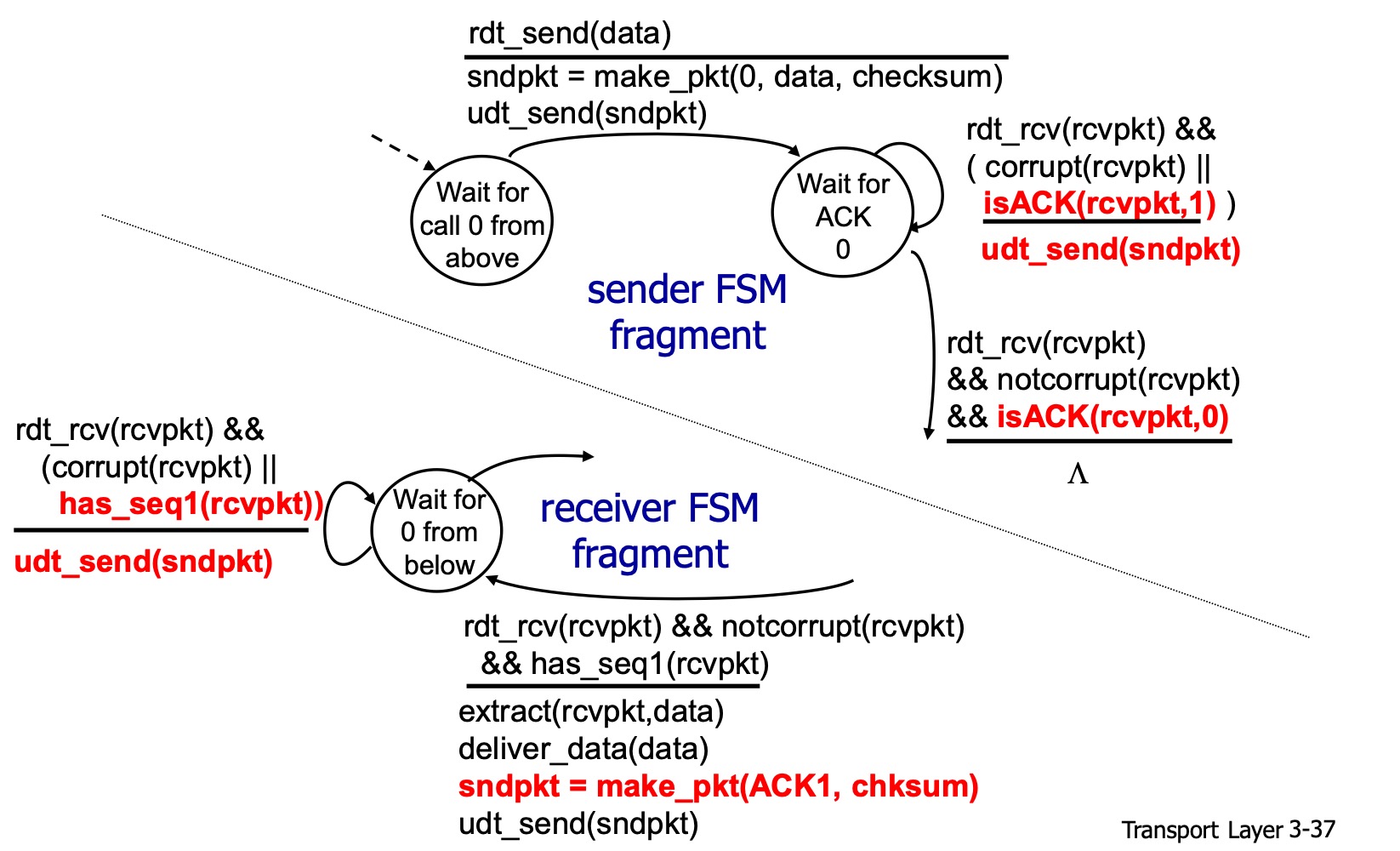
그림은 대각선을 기준으로 위쪽이 sender, 아래쪽이 receiver이다. 그리고 시퀀스 넘버 0, 1의 상태에 따라 action이 똑같으므로 0에 대해서만 축약해서 나타낸 그림이다.
sender는 0번을 보내고 정확히 ACK 0을 기다리는 상태로 간다. 그리고 기대했던 것과 다르게 ACK 1을 받게되었다면 앞에서 말했듯 문제 상황임을 판단하고 다시 재전송한다.
만약 무사히 ACK 0을 받았더라면 1을 보내는 상태로 가게되어 같은 과정이 반복된다.
receiver는 만약 1번 패킷을 받았다면 체크섬과 함께 ACK 1을 보내 1번 패킷을 잘 받았다고 receiver에게 알린다. 그리고 0을 기다리는 상태로 이동한다. 그런데 만약 0번이 와야하는데 1번이 왔다면 아까 보냈던 ACK 1을 다시보내 "1번 잘 받았으니까 이제 다음 거인 0번 줘" 라고 한다.
이렇게 rdt 2.2가 완성되었다.
rdt 3.0
지금까지는 비트 에러만 있다고 가정했지만, 실제 네트워크 상황에서는 패킷 손실이 발생하기도 한다. 따라서 이제부터 패킷 손실에 대한 대응도 만들었던 것에 추가해보자.
중요한 것은 데이터 패킷은 물론 ACK, NAK도 손실될 수 있다는 것이다. 그럼 sender는 계속 n을 기다리는 상태로 있게 된다. 이를 해결하기 위해 timer를 추가해보자. 계속 ACK, NAK를 기다리는게 아니라 일정 시간만 기다리고, 시간이 다 지날 때 까지 뭐가 안오면 네트워크 혼잡등의 상황임을 파악하고 재전송하면 된다.
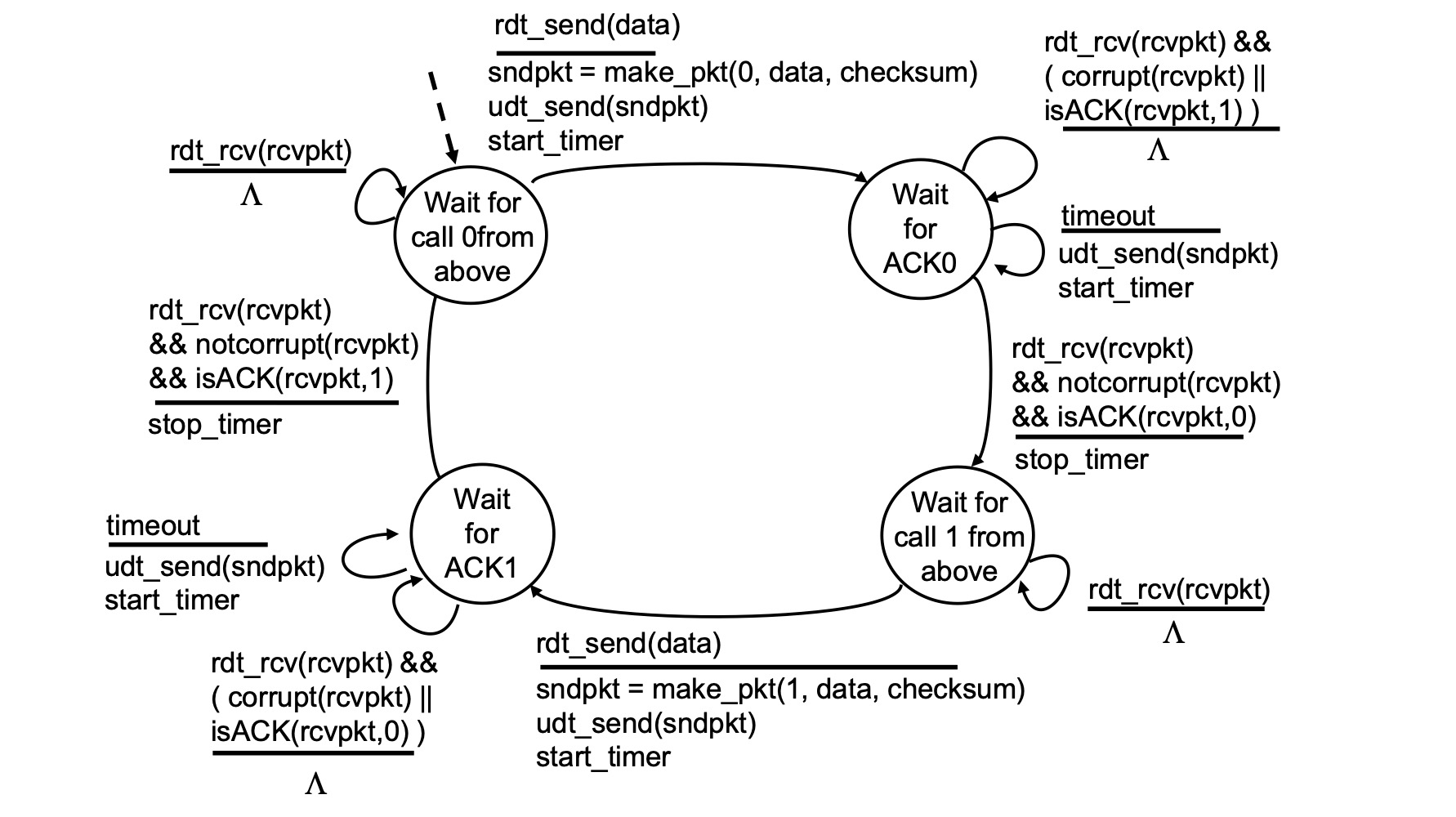
11시 방향, sender가 0번 패킷을 보내고 바로 start_timer로 타이머를 돌린다. 그리고 ACK 0을 기다리는 상태로 이동한다. 이때 timeout으로 제한 시간이 다 지났다면 다시 패킷을 보낸다. 그리고 또 start_timer 한다. 그리고 이 상태에서 중요한건 비트 에러 또는 다른 패킷을 받은 상황에서 바로 재전송 하지 않는다는 것이다. 어차피 timeout되면 재전송 할거고, 네트워크가 느릴 수도 있으니 "일단 기다려"로 시간이 끝날 때 까지 기다리는 것이다.
그리고 위에서 데이터가 내려오길 기다리는 상태는 패킷이 오길 기대하지 않는 상태다. 따라서 지연되어 늦게 도착한 패킷의 경우 무시한다. 어차피 timeout되었을 때 이 지연 패킷에 대하여 대응이 완료된 상태일 것이기 때문이다.
receiver는 2.2와 동일하다.
performance of rdt 3.0
rdt 3.0은 현대 네트워크 상황에서도 잘 동작하도록 문제 상황에 모두 적절하게 대응하는 프로토콜이 되었다. 이제는 성능 면에서도 만족이 될지 고려해보자.
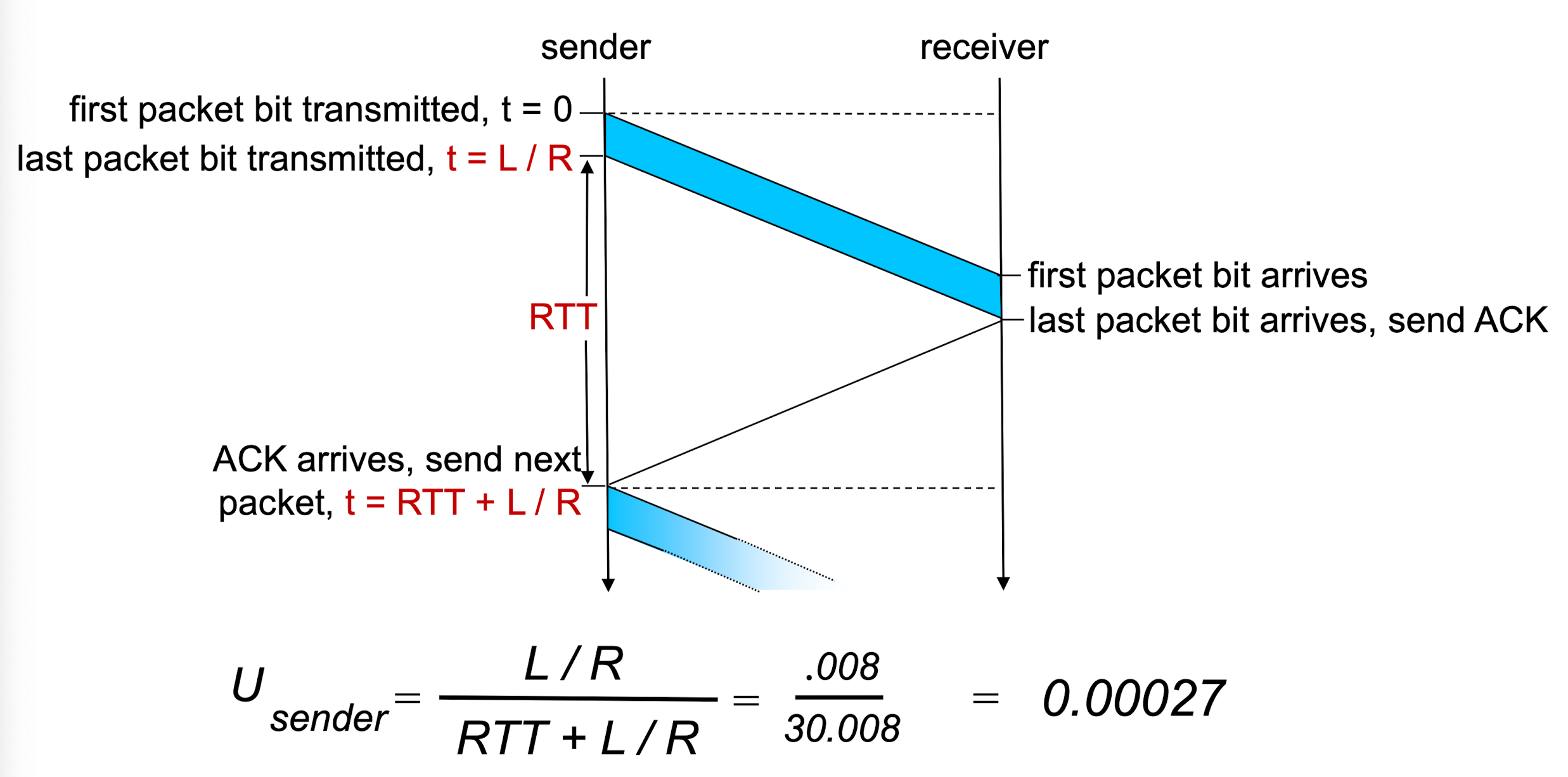
1Gbps Link, 15ms Tprop, packet length = 8000 bit 인 상황을 가졍해보자.
Dtrans = L / R = 8000 / 10^9 = 8ms그러면 전송하는 시간과 전파하는 시간 중 sender가 일하고 있는 시간의 비율(utilization)은 다음과 같다.
Usender = (L / R) / (RTT + L / R) = 0.008 / 30.008 = 0.00027매우 작은 사용율을 갖고 있다. 낭비하고 있다는 뜻이다.
stop-and-wait operation
저렇게 rdt 3.0이 낭비되는 이유는 stop-and-wait 전략을 사용하고 있기 때문이다. 0.008초 동안 패킷을 전송하고 그 이후 30초가 넘는 시간 동안 ACK를 기다리는 것 뿐 아무 일도 하지 않고 있기 때문에 사용율이 낮게 측정되었다.
그러면 한 패킷을 전송하고 바로 기다리지 말고 한번에 여러개를 전송하고 조금만 기다리는 방식을 취해보자.
pipelined protocols
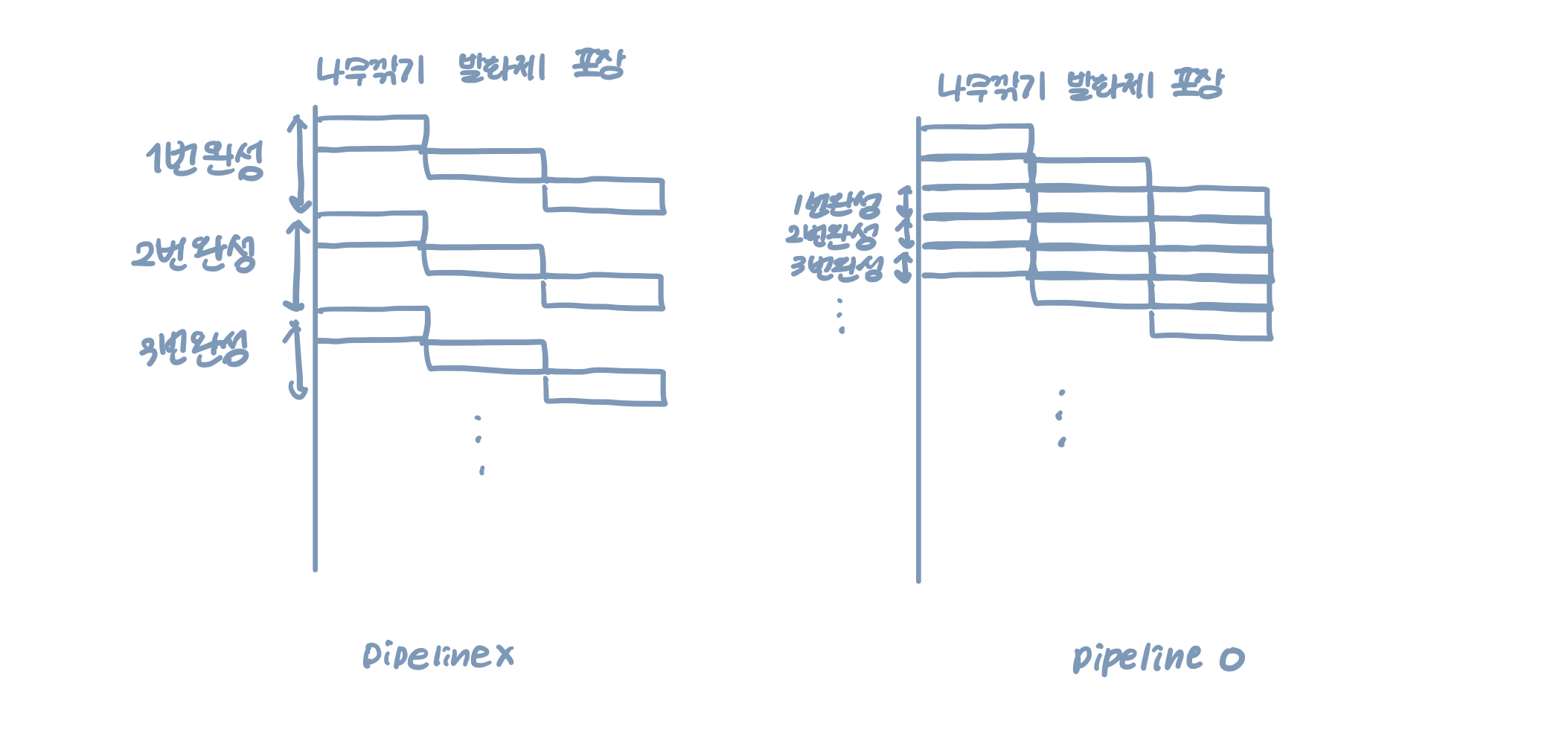
보통 공학에서 pipeline이라함은 효율을 높이기 위한 설계 방법을 의미한다. 성냥을 만든다고 하면 나무를 깎고, 발화제를 묻히고, 포장하는 과정이 필요하다. 그러면 1번 성냥이 저 과정을 거쳐 포장까지 완료하고 다음 2번 성냥을 만들까? 아니다. 1번 성냥이 나무를 깎는 과정이 끝나면 바로 다음 성냥이 나무를 깎는 과정으로 들어온다. 이렇게 공장의 기계들이 쉴 틈 없이 효율적으로 사용되는 것을 파이프라이닝 이라고 한다.
이 방식대로 rdt 3.0에 적용한다면, ACK없이 일단 뭉텅이로 데이터 패킷을 보내면 되겠다. 아래 그림처럼 말이다.
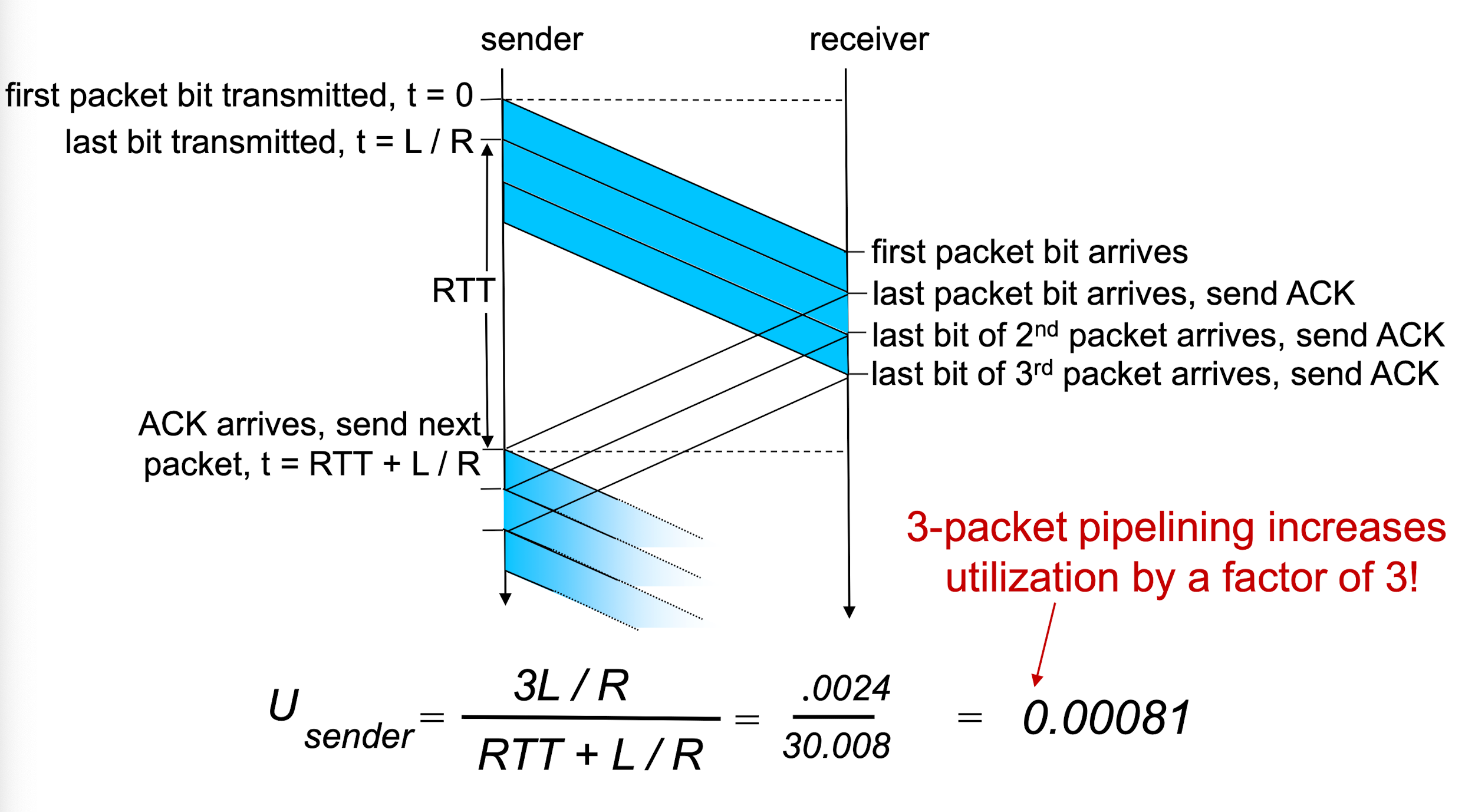
이렇게 방식을 바꾸니 사용율 = 기존 사용율 * N으로 바뀌었다. 선형으로 증가한다.
만약 이 뭉텅이에 포함된 패킷 개수가 2개를 넘어간다면 기존에 사용했던 0, 1 시퀀스 번호가 아니라, 더 확장되어야 한다. 무엇이 오류인지 판단해야 재전송 요청을 할 수 있기 때문이다.
이렇게 파이프라이닝을 적용한 방식은 두 가지 존재한다.
- go-back-N
- selective repeat
하나씩 알아보자.
go-back-N
이 방식은 ACK없이도 여러 개의 패킷을 보낸다. 그리고 cumulative ACK를 사용한다. ACK 에 시퀀스 넘버를 붙이긴 하는데, 이때 붙여지는 넘버는 receiver가 무사히 받은 시퀀스 넘버에서 1을 더한 값을 보낸다. 이 넘버를 send_base(base)라고 한다.
인 최소 넘버
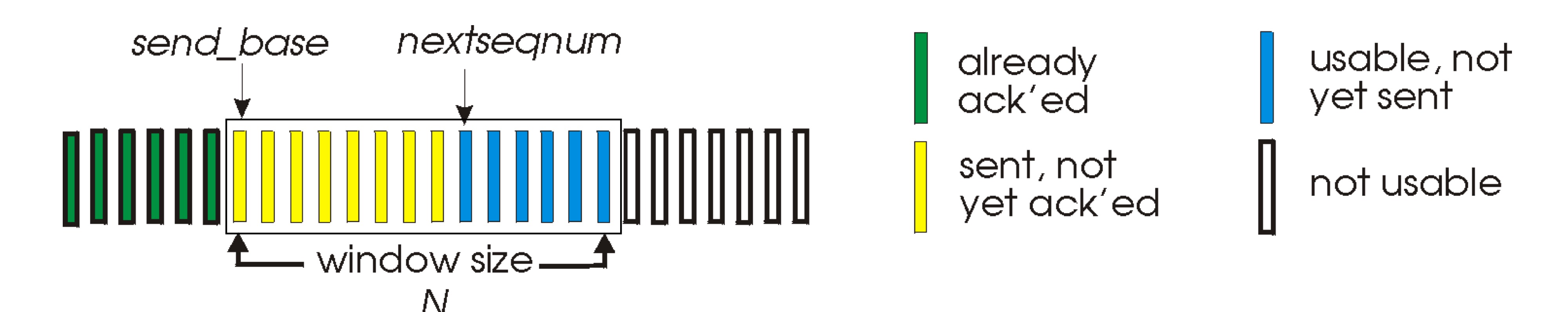
base: receiver가 어디까지 잘 받았는지를 표현하기 위한 번호이다.
window: ACK없이 보낼 수 있는 최대 개수 N 사이즈를 갖는다.
nextseqnum: 아직 보내지 않은 패킷 중 가장 앞선 패킷
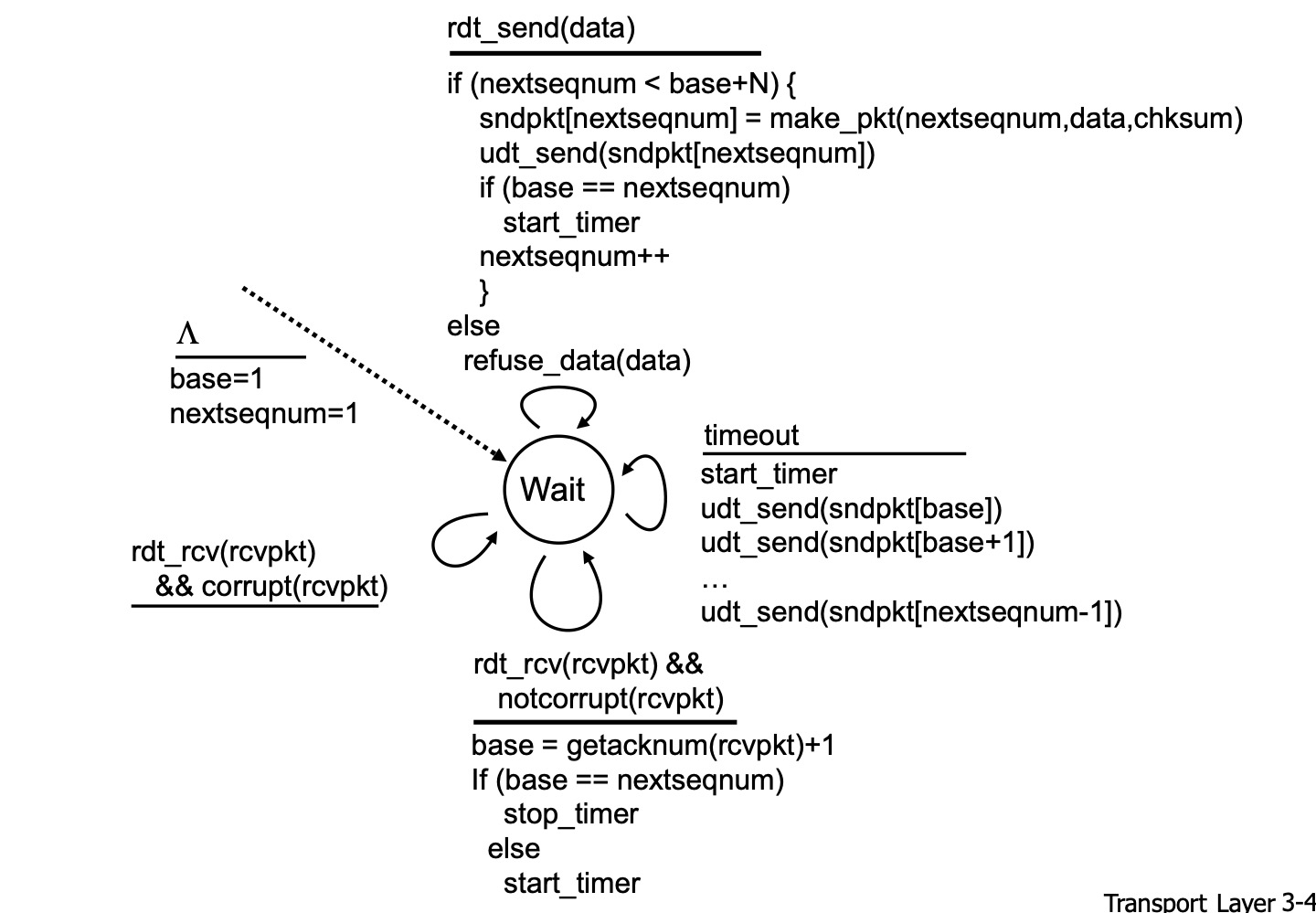
sender는 위 FSM대로 행동하게 된다.
APP 에서 보낼 데이터가 내려오면 nextseqnum < base + N으로 다음으로 보낼 패킷의 시퀀스 넘버가 윈도우 내부에 있는지 확인한다. base + N은 윈도우 크기를 의미한다. 윈도우 내부라면 보낼 수 있으니, nextseqnum을 시퀀스 넘버로 해 패킷을 만들고 NET으로 보낸다. 만약 이때 base == nextseqnum이라면 아직 보내지 않은 패킷을 보낸 것이 되므로 타이머를 시작하고 이제 해당 시퀀스 넘버 패킷을 보냈으니 nextseqnum++로 인덱스를 옮긴다.
만약 nextseqnum이 윈도우 내부가 아니라면, 잘못 온 패킷이므로 이를 refuse_data로 명시적으로 버린다.
그러다 보낸 패킷에 대한 ACK가 안오고 타임아웃이 나버린다면, 재전송이 필요하므로 다시 타이머를 초기화한다. 이때 중요한 것은 base ~ nextseqnum - 1까지의 패킷을 모두 재전송 한다는 것이다. base는 재전송을 위한 번호 즉 빵꾸가 나기 시작한 번호이니 base num을 갖는 패킷은 반드시 실패한 패킷이다. 그 이후는 빵꾸가 있던 없던 상관없다.
그렇게 여러개 패킷을 다 재전송 하지만 타이머는 base num의 타이머로서 돌아가고 있다.
그렇게 타임 이내에 패킷이 왔는데 비트 에러가 없이 무사히 도착했다면, base를 ACK 패킷에 딸려온 시퀀스 넘버 + 1로 수정한다. 딸려온 넘버까지는 잘 받았다는 의미이니까 base를 수정하는 것이다. 만약 base == nextseqnum이라면 base ~ nextseqnum - 1사이의 패킷, 특히나 보냈던 패킷 중 가장 마지막 패킷도 잘 도착했다는 의미이므로 타이머를 종료한다. 만약 그게 아니라면, 빵꾸가 났다는 뜻이므로 타이머를 다시 시작한다. base는 이미 수정되어있기 때문에 방금 시작한 타이머가 타임아웃되면, base부터 재전송될것이다.
만약 받은 패킷에 비트 에러가 있다면 일단 기다린다. 어차피 타임아웃되면 재전송 될 것이기 때문이다.
이 여러개의 패킷을 한번에 보내는 과정 후 받는 ACK는 하나이다. 빵꾸없이 잘 전송된 패킷의 시퀀스 넘버 + 1을 보낸다. 이것이 암묵적으로 시퀀스 넘버 까지의 패킷은 모두 다 잘 전송되었다는 것을 의미하기에 cumulative ACK방식이라고 하는 것이다.
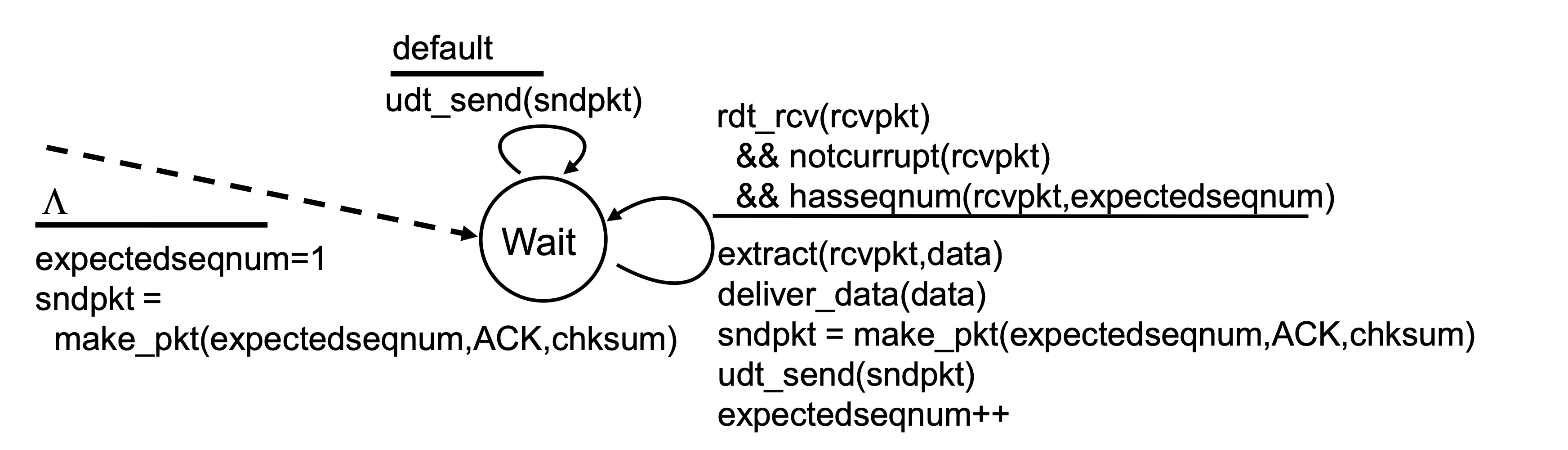
go-back-N에서 receiver는 위 FSM대로 행동한다.
receiver는 expectedseqnum이라는 변수가 있다. 받길 기대하는 패킷의 시퀀스 넘버라는 의미이다.
패킷을 받았고, 비트 에러도 없고, 그 패킷에 담긴 시퀀스 넘버가 expectedseqnum과 일치한다면 데이터를 추출해 APP으로 보낸다. 그리고 expectedseqnum을 담아 ACK를 보내고 expectedseqnum++로 다음 패킷을 기대한다.
그 외 비트에러, 기대한 시퀀스 넘버가 아닌 경우는 FSM에 명시되어 있진 않지만, 암시적으로 버리게 된다.
이 go-back-N방식은 빵꾸 이후에 패킷을 잘 받아도 빵꾸부터 모든 패킷을 보내기 때문에 낭비가 있다.
selective repeat
위 go-back-N방식은 하나의 타이머만 돌아간다. base 패킷의 타이머만 돌아가는 것이다.
하지만 selective repeat는 각각의 패킷에 대한 타이머가 돌아간다. 이는 go-back-N처럼 빵꾸난 패킷부터 보냈던 모든 패킷을 재전송하지 않고, 빵꾸난 패킷 하나만 재전송하기 위함이다.
1, 2, 3번을 순차적으로 보내고 1, 3번만 무사히 도착했다고 한다면 2번 패킷의 타이머가 타임아웃되면 2, 3번이 아니라 이 2번 패킷만 보낸다는 뜻이다.
selective repeat에는 send_base와 rcv_base가 필요하다.
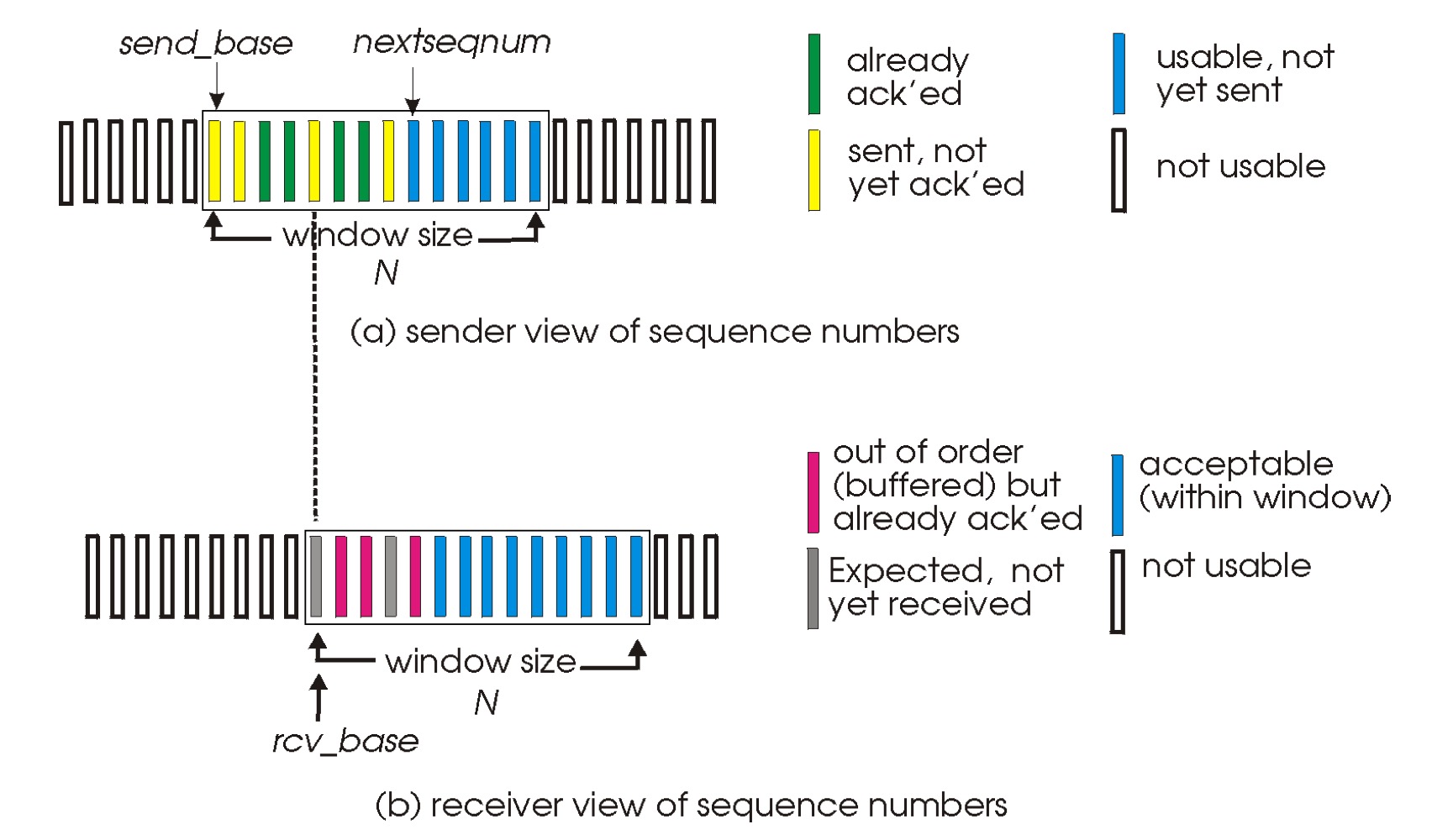
위 그림에서 send_base ~ nextseqnum - 1 까진 이미 전송된 패킷이다. 그리고 그 중 초록색은 ACK를 받은 패킷이다. 노란색은 ACK를 받지 못한 패킷이다.
ACK에 함께 온 시퀀스 넘버가 send_base ~ send_base + N 이내라면 윈도우 내부라는 의미이다. 그리고 이때 시퀀스 넘버가 지금까지 애크 안된 패킷들(노란색)중 제일 왼쪽(빵꾸를 매꿔줄)이라면 send_base를 이동시킨다.
그리고 타임아웃이 나면 그 타이머가 의미하는 시퀀스 넘버의 패킷을 다시 재전송한다.
receiver는 별도의 버퍼를 갖고 있어야 한다. 빵꾸가 나있다면 그 빵꾸가 매워지면 이전에 받은 멀쩡한 패킷도 함께 뭉쳐 APP으로 올려보내기 위해 멀쩡한 패킷을 저장해두어야 하기 때문이다.
받은 패킷의 시퀀스 넘버가 rcv_base ~ rcv_base + N - 1 이내라면 receiver window의 내부라는 의미이다. 따라서 받은 패킷의 시퀀스 넘버 그대로 ACK를 보낸다. 그리고 윈도우 제일 왼쪽이 아니라면 일단 버퍼에 저장한다. 만약 윈도우 제일 왼쪽(빵꾸를 메꿀) 시퀀스 넘버의 패킷이 도착했다면 버퍼에서 빵꾸가 안나게 짤라와 패킷 뭉치를 APP으로 올린다. 그리고 윈도우를 APP으로 올린 패킷에서 + 1로 이동한다. 만약 현재 윈도우 내부가 아닌 과거의 패킷이 왔다면 그 패킷의 시퀀스 넘버 그대로 ACK를 보낸다.
selective repeat 문제
예를들어 시퀀스 넘버를 0, 1, 2, 3으로 하고 윈도우 크기 N을 3으로 가정해보자.
아래와 같이 0, 1, 2를 모두 잘 받았지만 로스되어, 다시 0을 보낸다고 하면 sender에서 보내는 0 패킷과, receiver에서 기대하는 0 패킷은 다르다. 문제다.
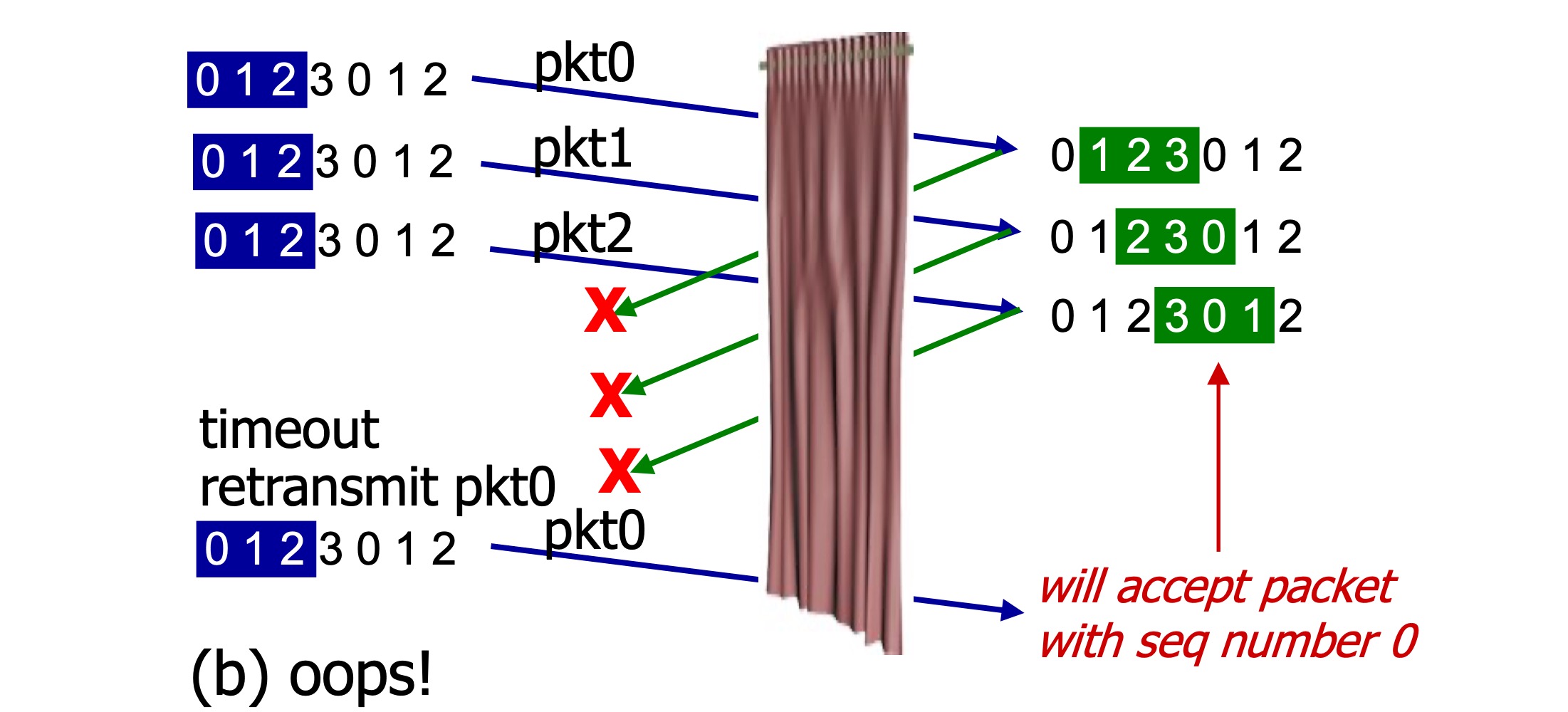
따라서 이런 문제를 벗어나기 위해선 윈도우 크기를 조정할 필요가 있어보인다.
윈도우 크기를 시퀀스 넘버 개수 / 2 이하로 한다면 해결된다.
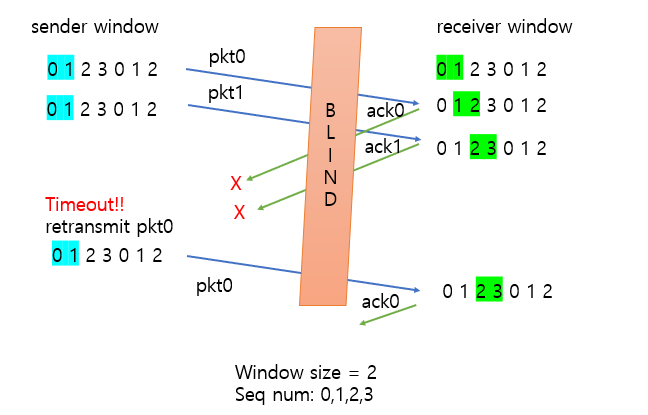
receiver는 자신의 윈도우 내부가 아닌 이전 윈도우에서 온 패킷에 대하여 그대로 시퀀스 넘버를 담아 ACK를 보낸다고 했으니 그렇게 sender의 윈도우가 0을 벗어나 이동할 수 있게될 것이다.
go-back-N 🆚 selective repeat
뭐가 더 좋은 것은 아니고, 상황에 맞게 사용하면 된다.
GBN은 한번 안되면 그 많은 패킷을 다시 보내야하므로 재전송 코스트가 높다. 하지만 구현이 간단하다.
SR은 그 많은 패킷의 타이머를 전부 돌려야한다. 그리고 버퍼에 저장도 해야한다. 다만 재전송 코스트가 낮다.
재전송 코스트는 통신비가 비싼 네트워크에서 문제가 된다. 패킷 건당 돈을 내야한다면 SR이 맞고, 한달에 얼마 내고 무제한이용이라면 GBN이 간단할 것이다.
