오늘의 주제
- 이진 트리 순회
- 이진 탐색 트리(BST)
- LCA
- Lower / Upper Bound
서론: 배열에서 트리로의 확장
4주차에 배운 이분 탐색은 "정렬된 배열에서 중간값을 기준으로 범위를 절반씩 줄여나가는 것"이었다. 근데 생각해보면 이게 배열에만 적용되는 개념은 아니다.
이번 주차의 주제는 그 사고방식을 트리 구조로 확장해보는 것이다. 배열에서 인덱스 기준으로 반으로 나눴다면, 트리에서는 노드를 기준으로 좌/우로 분기한다. 표현 방식만 다를 뿐 근본적인 아이디어는 똑같다 - 탐색 범위를 효율적으로 줄이는 것.
1. 이진 트리 순회
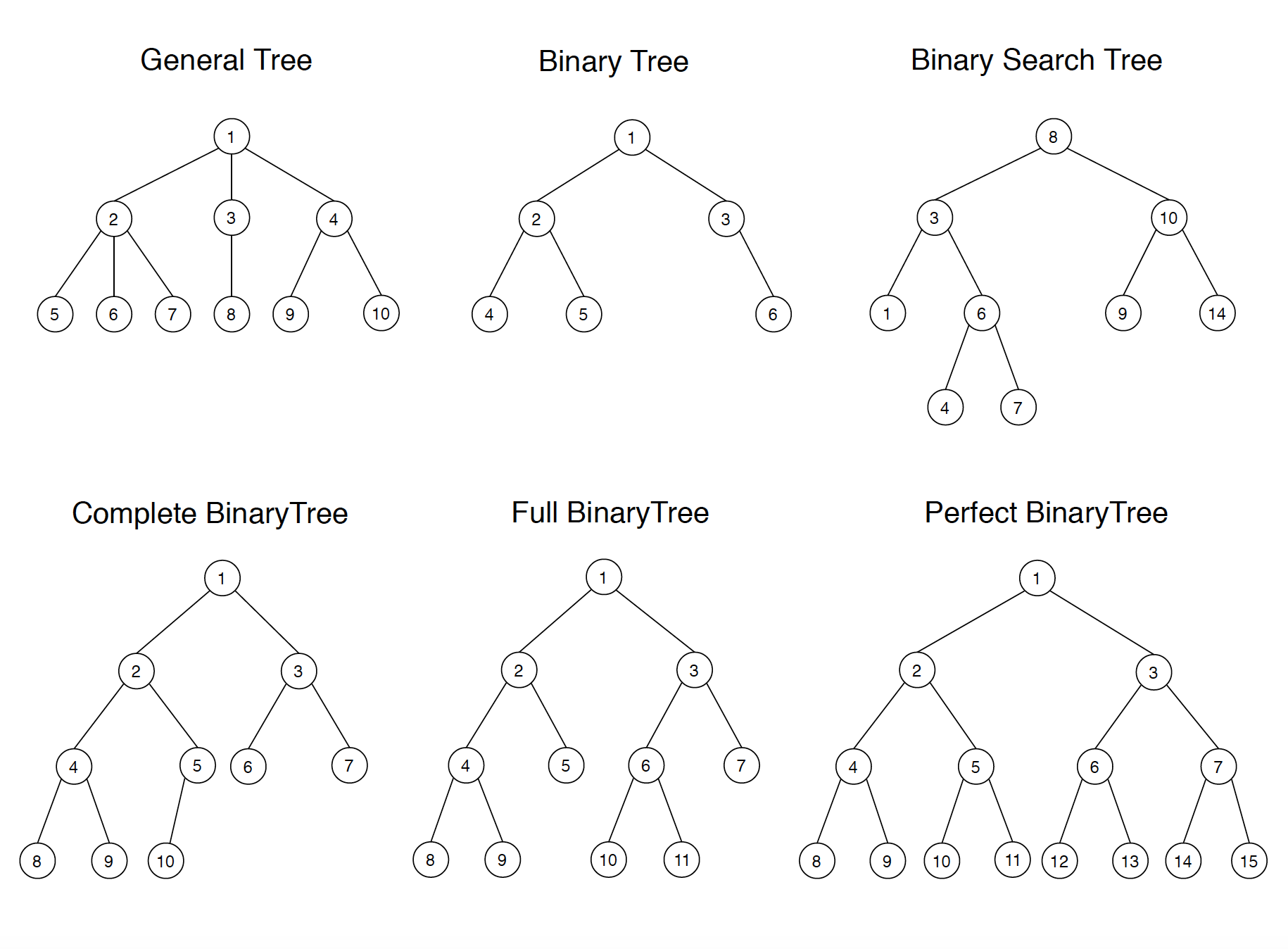
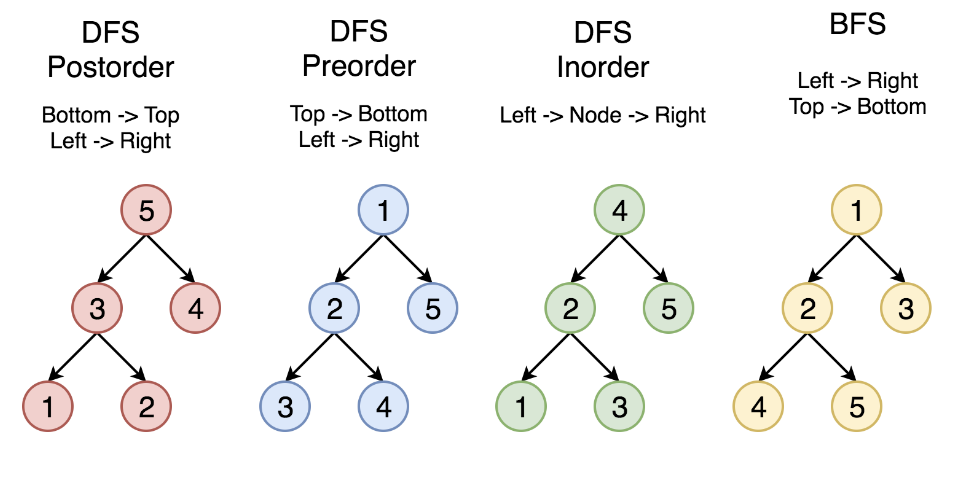
이진 트리는 각 노드가 최대 두 개의 자식만 가질 수 있는 트리다. 순회는 "이 노드들을 어떤 순서로 방문할 것인가"의 문제인데, 크게 세 가지 방식이 있다.
기사 할 때도 지겹게 봤으니... 사진과 함께 가볍게 정리하고 넘어감
- 전위 순회 (Preorder): Root → Left → Right
- 중위 순회 (Inorder): Left → Root → Right
BST에서 중위 순회를 하면 정렬된 순서로 값들이 나오는데, 이게 바로 이분 탐색과 연결되는 핵심 포인트다. - 후위 순회 (Postorder): Left → Right → Root
2. 이진 탐색 트리 (BST, Binary Search Tree)
BST는 다음 규칙을 만족하는 이진 트리다:
- 왼쪽 서브트리의 모든 값 < 현재 노드의 값
- 오른쪽 서브트리의 모든 값 > 현재 노드의 값

배열에서의 이분 탐색이 "인덱스를 기준으로 반으로 나누기"였다면, BST는 "값 비교를 통해 왼쪽/오른쪽으로 분기"하는 방식이다.
트리의 깊이와 높이
- 깊이(depth): 루트 노드에서 해당 노드까지의 거리 (위에서 아래로)
- 높이(height): 해당 노드에서 가장 먼 리프 노드까지의 거리 (아래에서 위로)
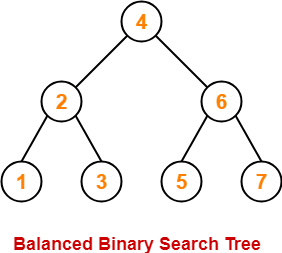
완전 이진 트리는 높이가 log₂(n)에 가깝다 (노드가 8개면 높이는 3 정도)
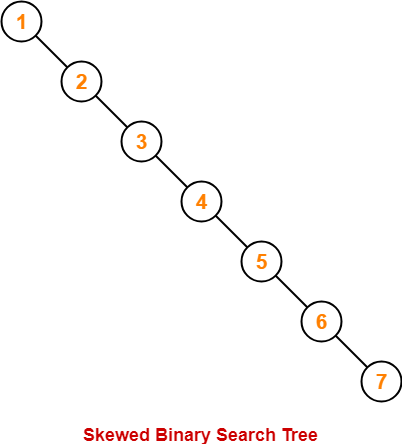
하지만 한쪽으로 치우치면 높이가 n까지 늘어나기 때문에, BST가 균형을 유지해야 시간복잡도가 개선된다.
| 균형 잡힌 이진 트리 | 한쪽으로 치우친 이진 트리 |
|---|---|
 |  |
따라서 탐색, 삽입, 삭제 모두에서 시간 복잡도는:
- 평균:
O(log n)- 트리가 균형 잡혀있는 경우 - 최악:
O(n)- 한쪽으로 치우쳐서 일직선이 되었을 경우
결국 트리의 높이 = 시간 복잡도라고 봐도 된다.
Red-Black Tree나 AVL Tree 같은 자가 균형 트리를 자주 쓴다.
3. LCA (Lowest Common Ancestor)
두 노드의 가장 가까운 공통 조상을 찾는 문제. 재귀를 활용한다.
- 왼쪽 서브트리에서 두 노드를 찾는다
- 오른쪽 서브트리에서도 찾는다
- 둘 다 발견되면 현재 노드가 LCA다
- 한쪽에서만 발견되면 그쪽 결과를 리턴한다
def lca(root, p, q):
if not root or root == p or root == q:
return root
left = lca(root.left, p, q)
right = lca(root.right, p, q)
if left and right: # 양쪽에서 다 발견됨 = 현재 노드가 LCA
return root
return left if left else right # 한쪽에서만 발견됨트리를 재귀적으로 이해하고 있는지 확인하는 전형적인 문제로, 실무에서도 조직도나 파일 시스템 같은 계층 구조 문제에서 응용된다고 한다.
4. Lower Bound / Upper Bound
정렬된 배열에서 경계를 찾는 이분 탐색 기법이다:
- Lower Bound: target 이상의 값이 처음 나타나는 위치
- Upper Bound: target 초과하는 값이 처음 나타나는 위치
def lower_bound(arr, target):
left, right = 0, len(arr)
while left < right:
mid = (left + right) // 2
if arr[mid] < target:
left = mid + 1
else:
right = mid
return left이게 왜 트리 챕터에 나오냐면, 배열 기반 이분 탐색은 암묵적으로 완전 이진 트리를 탐색하는 것과 같기 때문이다. mid를 기준으로 왼쪽 범위/오른쪽 범위로 나뉘는 게 결국 트리의 좌/우 서브트리 구조와 동일하다.
문제풀이
연습문제: 1920 - 수 찾기
응용문제: 1654 - 랜선 자르기
