싸그리 잊어버리기 전에 DFS, BFS 복습하고 Swift 코드로 풀어보려고 쓰는 틸
사전 개념 읊기
- 트리: 부모-자식 으로 연결
- 각 노드가 자식 노드 2개 이하면 이진트리
- 균형 이진 트리 자료구조: AVL Tree, B-Tree, Red-Black Tree 등
- 트리에 사이클이 생기면 그래프
- 탐색 알고리즘: DFS(깊이우선), BFS(너비우선)
사전 정리
| 항목 | DFS (재귀) | DFS (스택) | BFS (큐) |
|---|---|---|---|
| 탐색 순서 | 깊이 우선 | 깊이 우선 | 너비 우선 (레벨순) |
| 구조 | 재귀 콜 | 수동 관리 스택 | 큐 (deque) |
| 적합한 문제 | n<=1000 | 백트래킹, 구역 나누기, 모든 경로 찾기 등 | 최단 경로 탐색 등 |
| 시간 복잡도 | O(V + E) | O(V + E) | O(V + E) |
여기서 V는 노드의 개수, E는 간선의 개수로 결국 모든 노드와 간선을 탐색하기 때문에 시간복잡도는 같은 것이다.
1. Python으로 구현
1) DFS (재귀 사용)
def dfs_recursive(node, visited):
visited.add(node)
print(node)
for neighbor in graph[node]:
if neighbor not in visited:
dfs_recursive(neighbor, visited)
dfs_recursive('A', set())방문한 노드는 visited에 넣고 다른 노드 들어올 때 방문했는지 아닌지 비교
다른 노드 방문을 재귀로 처리해 코드 자체 작성은 가장 쉬움
그러나 recursionError 가 일어날 수 있어 일정 깊이 이상으로는 사용하지 않는게 나음
2) DFS (스택 사용)
def dfs_stack(start):
visited = set()
stack = [start]
while stack:
node = stack.pop()
if node not in visited:
visited.add(node)
print(node)
stack.extend(reversed(graph[node]))
dfs_stack('A')start를 stack에 넣고 다음 노드들을 탐색하는데, 다음 노드들을 stack에 넣을 때 왼쪽부터 우선 탐색하기 위해 reversed를 사용함. stack이니까 pop을 하면 리스트의 가장 마지막 값부터 나오기 때문
재귀와 같이 visited로 방문여부 관리
3) BFS (큐)
from collections import deque
def bfs(start):
visited = set()
queue = deque([start])
while queue:
node = queue.popleft()
if node not in visited:
visited.add(node)
print(node)
queue.extend(graph[node])
bfs('A')python에서 stack은 list로 구현, queue는 collections.deque로 쉽게 구현할 수 있다. deque()는 popleft()가 가능해서 reverse 하지 않아도 됨.
collections.deque는 양쪽 끝에서 빠르게 삽입/삭제가 가능하게 만든 이중 연결 리스트로 구현되었기 때문에 popleft() 메서드의 시간복잡도가 O(1) 이다.
bfs의 경우, 어떤 노드에 처음 도달하면 그 거리가 항상 최단거리이다. 이는 너비 우선 탐색이기 때문
참고) 방문 여부 관리 코드 있음에도 visited를 set으로 쓰는 이유
- 빠름: 평균 O(1), list를 쓰면 O(n)으로 느려짐
- 중복 한번 더 방지: 이미 있는 값은 자동으로 무시
- 가독성: “방문 여부 체크” 목적에 맞는 구조
2. Swift 구현 (기본 Array로 처리)
array로 쓸뿐, removeFirst()와 removeLast()가 구현되어 있어 코드는 비슷하다.
removeFirst
맨 앞의 요소를 지워주는 removeFirst() 도 있고, 입력한 개수를 다 지워주는 removeFirst(k:Int) 도 있다.
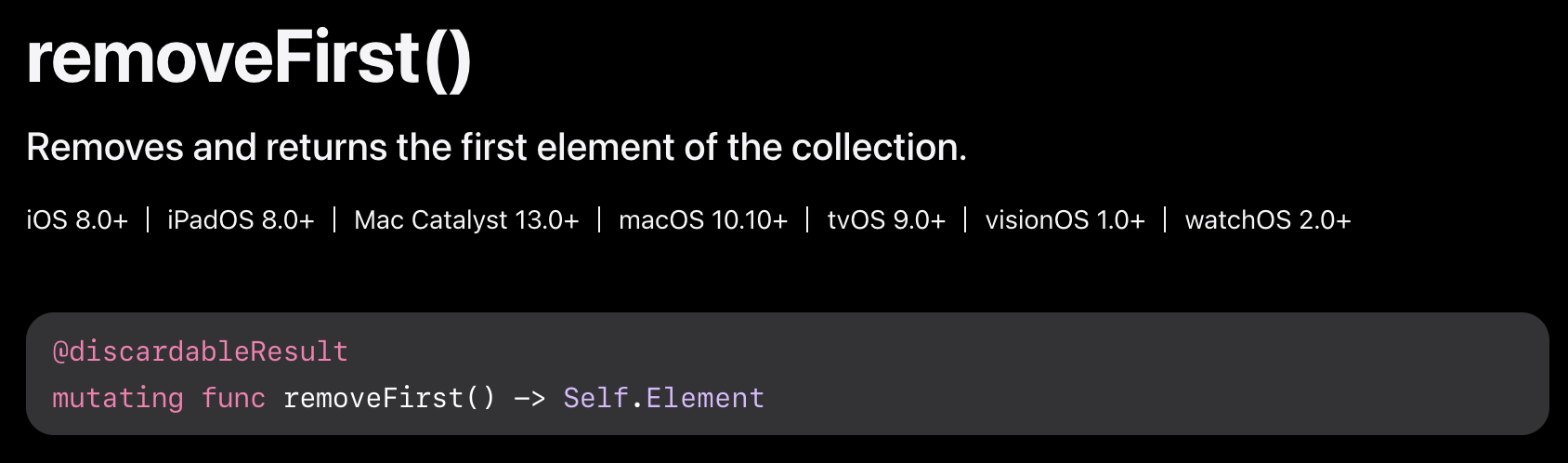

둘 다 시간복잡도는 O(n) 이다.

removeLast
removeLast(), removeLast(k:Int) 도 둘 다 있다.

이건 예상한대로, removeLast()의 시간복잡도는 O(1), removeLast(k:Int)의 시간복잡도는 O(k) 이다.
Swift로 구현하면 다음과 같다.
1) DFS (스택)
func dfsStack(start: String, graph: [String: [String]]) {
var visited = Set<String>()
var stack = [start]
while !stack.isEmpty {
let node = stack.removeLast()
if !visited.contains(node) {
visited.insert(node)
print(node)
stack.append(contentsOf: graph[node]?.reversed() ?? [])
}
}
}2) BFS (큐)
func bfs(start: String, graph: [String: [String]]) {
var visited = Set<String>()
var queue: [String] = [start]
while !queue.isEmpty {
let node = queue.removeFirst()
if !visited.contains(node) {
visited.insert(node)
print(node)
queue.append(contentsOf: graph[node] ?? [])
}
}
}코드 논리 구조는 python과 똑같은데, 차이가 있다.
앞서서도 간단히 설명했지만,
1)에서 쓴 .removeLast는 배열의 끝 요소를 제거하는 거라 내부에서 포인터 하나만 줄이면 되는 반면,
2)에서 쓴 .removeFirst는 배열의 첫 요소를 제거하면 뒤의 값들을 다 앞으로 당겨야 해서 내부에서 shift가 발생하여 시간복잡도가 O(n)이 된다.
인덱스로 이동
따라서 n이 1000 이상이 되면, front index 방식을 사용하는 큐 자료구조를 직접 만들어서 사용하는 것이 효율적이다. 이는 앞을 잘라내지 않고, 인덱스만 이동하기 때문에 시간복잡도가 O(1)이 된다.
struct Queue<T> {
private var array: [T] = []
private var frontIndex = 0
var isEmpty: Bool {
return frontIndex >= array.count
}
var front: T? {
return isEmpty ? nil : array[frontIndex]
}
mutating func enqueue(_ element: T) {
array.append(element)
}
mutating func dequeue() -> T? {
guard !isEmpty else { return nil }
let element = array[frontIndex]
frontIndex += 1
return element
}
}위 코드를 보면, 앞의 요소들을 배열에서 빼내버리는 것이 아니라 인덱스를 우측으로 이동하는 것을 알 수 있다.
참고로 swift에서 mutating func 이란:
struct는 기본적으로 값 타입이기 때문에 기본적으로는 내부 property가 바뀌지 못하게 되어있다. 이걸 바꾸는 메서드를 작성하려면 기본 func가 아닌mutating키워드를 붙여줘야 한다. 위의removeFirst()설명 내부 코드에도 mutating func이라고 되어 있는 것을 볼 수 있음.
이렇게 되면 이동할수록 남은 데이터들이 있어 메모리에 비효율적이 아닌가 싶었는데, 아래와 같은 코드를 활용해서 일정 간격으로 삭제해준다고 한다.
if frontIndex > 50 {
array.removeFirst(frontIndex)
frontIndex = 0
}여기서는 그냥 .removeFirst()를 이용해 주는 모습이다.
