공유주제 스터디 3회차
주제는 메모리인데, 범위가 너무 넓어서
기간을 2주로 잡고 범위를 나눠서 공부하기로 했다.
Swift의 메모리 관리
1. Swift의 코드-데이터-힙-스택
- Code: 프로그램의 코드, Read-Only
- Data: 전역 변수, static 변수를 저장한다. 어디서든 접근 가능하며, 프로세스가 시작과 동시에 할당되고 프로그램 종료시 해제 (static 예외: swif의 static은 lazy), Read-Write
- Heap: 데이터를 지우기 전까지는 계속 유지되는 공간으로, 반영구적으로 지속. 네 영역 중 유일하게 런타임시 결정되기 때문에 데이터의 크기가 확실하지 않을때 사용한다. 개발자가 직접 메모리 해제해줘야 하지만, Swift의 ARC가 이를 도와준다.
- Stack: 지역 변수와 파라미터, 리턴값 등 일시적인 데이터가 저장된다. 함수를 호출할 때마다 Stack에 해당 함수에 해당하는 공간이 생기고, 함수 실행이 끝나면 사라진다.
다시 한 번 정리하면, Swift에서 Value type은 Stack에, Reference type은 Heap에 저장된다.
Stack
시스템은 현재 실행하는 스레드와 관련된 컨텍스트를 Stack에 저장한다.
스택 영역의 데이터는 CPU가 관리하고 최적화한다. 메모리에 빈 공간이 발생하지 않는다.
덕분에 Stack은 매우 빠르고 효율적이다.
Heap
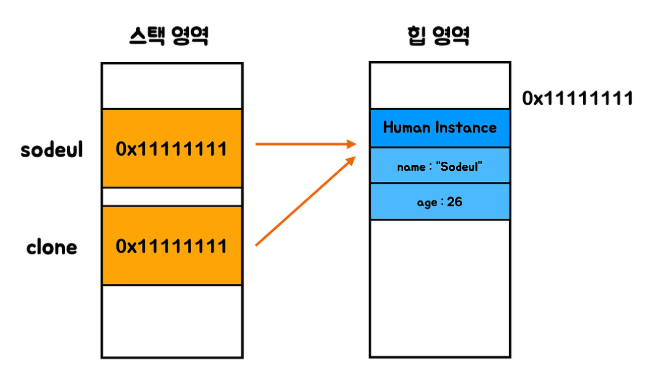
인스턴스 자체는 힙에 저장한다. 이 힙의 주소값을 식별자와 함께 스택에 저장한다. 이 주소값을 이용해 실행 중에 필요한 데이터를 가져올 수 있다.
스택과 다르게 힙에 있는 인스턴스가 더이상 필요 없어진 이후엔 직접 지워줘야 한다. 이 과정에서 힙을 검색하고, 빈 메모리를 다시 적절하게 삽입해줘야 하고, 무엇보다 동기화 문제를 막는 메커니즘을 구현해야 한다.
이 때문에 속도가 스택에 비해서 느리다.
2. Swift Collection과 COW(Copy-on-Write)
Swift의 Array, Dictionary, Set 같은 컬렉션 타입(Collection Type)은 struct로 구현되어 값 타입이지만, Copy-on-Write (COW)를 적용하여 불필요한 복사를 방지한다.
✅ Copy-on-Write (COW)
값 타입(struct)은 원칙적으로 복사됨 → 하지만 무조건 복사하면 메모리 낭비가 심함
Swift의 컬렉션은 값 타입이지만, 내부적으로 참조 타입(Reference) 카운트를 활용한다.
변경 전까지는 참조를 공유하여 불필요한 메모리 사용을 방지
3. Struct의 사용 vs Class의 사용
가급적 Stack을 쓰는 것이 빠르고, 멀티스레드 환경에서 안전성을 보장한다.
꼭 Class를 써야 하는 이유가 있을 때만 Class를 사용한다.
1) 고유성이 필요한 인스턴스일 때
어떤 객체를 바라볼 때, 이 객체의 데이터가 단순한 값(data)인지, 아니면 고유한 정체성(identity)를 가지고 있는지에 대해 생각해 보야아 한다.
📌 예제 1: 위치(Position) 데이터
struct는 단순한 값을 나타내는 데 적합하다.
struct Position {
var x: Int
var y: Int
}(10, 20) 위치와 (10, 20) 위치는 같은 값이다.
예를 들어, positionA와 positionB의 두 값이 같으면 그냥 같은 위치라고 할 수 있다.
let pos1 = Position(x: 10, y: 20)
let pos2 = Position(x: 10, y: 20)
print(pos1 == pos2) // ✅ true (값이 같으면 동일한 위치)📌 예제 2: 학생(Student) 데이터
하지만 학생(Student) 객체는 다르다.
class Student {
var name: String
var age: Int
init(name: String, age: Int) {
self.name = name
self.age = age
}
}학생은 단순한 값이 아니라 고유한 개체이다.
무슨 뜻이냐면, 학생 A와 학생 B의 이름과 나이가 같다고 해도 같은 사람이 아니다.
즉, 두 개체는 같은 데이터를 가질 수 있지만, 각각 다른 사람이므로 아이덴티티(정체성)가 중요하다.
let studentA = Student(name: "Alice", age: 20)
let studentB = Student(name: "Alice", age: 20)
print(studentA === studentB) // ✅ false (서로 다른 객체)두 학생의 name과 age가 같더라도, === 연산자로 비교하면 서로 다른 객체임을 알 수 있다.
이런 경우 class를 사용해야 한다.
2) Objective-C와 호환성이 필요할 때
3) 변경가능한 상태를 공유하는 것이 꼭 필요할 때
데이터의 상태를 계속 바꿔서 업데이트해야 할 때
예를 들어, Swift에서 Linked list를 구현하는 경우.
+Tip: Class를 사용한다면, final 키워드를 사용해서 컴파일러에게 알려주는 것이 좋다.
결론 - 상속이 필요할 때는?
상속이 필요하다면 'class'가 아니라 'struct' + 'protocol'을 쓰자.
Swift에는 상속 말고도 타입 계층을 만들 수 있는 protocol이 있다.
protocol은 상속보다 활용도가 높으며 Swift에서는 protocol을 사용하는 것을 더 권장한다. (Swift가 protocol-oriented language라고 불리는 이유다.)
class와 상속보다는, struct과 protocol을 통해 타입 계층을 구현하자.
AutoRelease
AutoRelease란?
참조 카운트를 나중으로 미루기 위한, 카운트가 나중에 감소되는 것을 보장받는 기법
객체의 참조 카운트를 감소시킬 때, release 대신 autorelease를 사용하면 예약이 된다.
You should consider using autorelease pools in situations where you perform resource-intensive tasks or create many temporary objects. Common scenarios include image processing, file I/O, and data parsing.
실제로 release를 수행하면 카운트가 바로 줄지만, autorelease는 직후에는 감소되지 않는다.
autoRelease된 객체들은 autoReleasePool에 등록된다. -> 간단한게 쓰레드풀을 떠올리면 될 것 같다.
이 autoRelease이 해제될 때, 내부의 객체들이 모두 release된다!!
해당 autoreleasePool은 foundation Framework에 있다.
func useManyImages() {
let filename = pathForResourceInBundle
for _ in 0 ..< 5 {
for _ in 0 ..< 1000 {
let image = UIImage(contentsOfFile: filename)
}
}
}이미지를 5천번 가져오는 반복문을 예로 들어보자.
메소드가 종료되기 전까지는 생성된 5000개의 image가 메모리 공간에 유지되며 함수가 종료될 때, 해당 image들을 가르키는 참조 카운트가 줄어들며 release된다.
-> 즉, 함수가 끝나기 전까지 5000개의 이미지가 메모리 안에 존재한다는 말!! -> 만약 iOS 폰 내에서 많은 메모리를 사용하고 있고, 메모리가 부족하다면 원치 않게 App이 죽는 경우가 생길 수도 있다.
이러한 상황을 막기 위해 AutoRelease를 사용한다.
func useManyImages() {
let filename = pathForResourceInBundle
for _ in 0 ..< 5 {
autoreleasepool {
for _ in 0 ..< 1000 {
let image = UIImage(contentsOfFile: filename)
}
}
}
}똑같이 이미지를 5천번 가져오는 반복문이다.
이미지 1천번을 가져오는 for문을 autoRelease로 감싸고 해당 블럭을 5회 진행한다.
-> 이미지 1000개를 메모리에 올리고, autoReleasePool이 비워지면서 해당 1000개가 메모리에서 내려가고 * 5
방식으로 작동할 것으로 예상된다.
메모리 사용량 그래프를 보면 쉽게 이해할 수 있다.
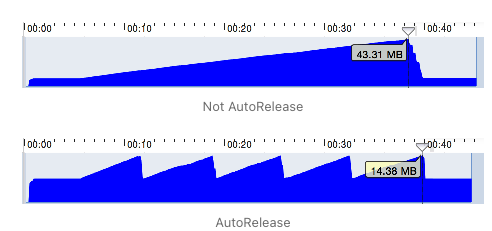
사용하지 않았을 때, 순간 메모리 사용량이 43MB을 사용했지만, 사용했을 때는, 순간 최고 사용량이 14MB로 현저히 낮은 것을 볼 수 있다.
