오늘의 주제 [재귀와 분할]
- 분할 정복
- 재귀
- 분할정복 + 재귀 예시
분할 정복 (Divide and Conquer)
분할 정복은 문제를 여러 개의 작은 문제로 나눈 뒤, 각각을 해결한 결과를 결합하는 방식이다.
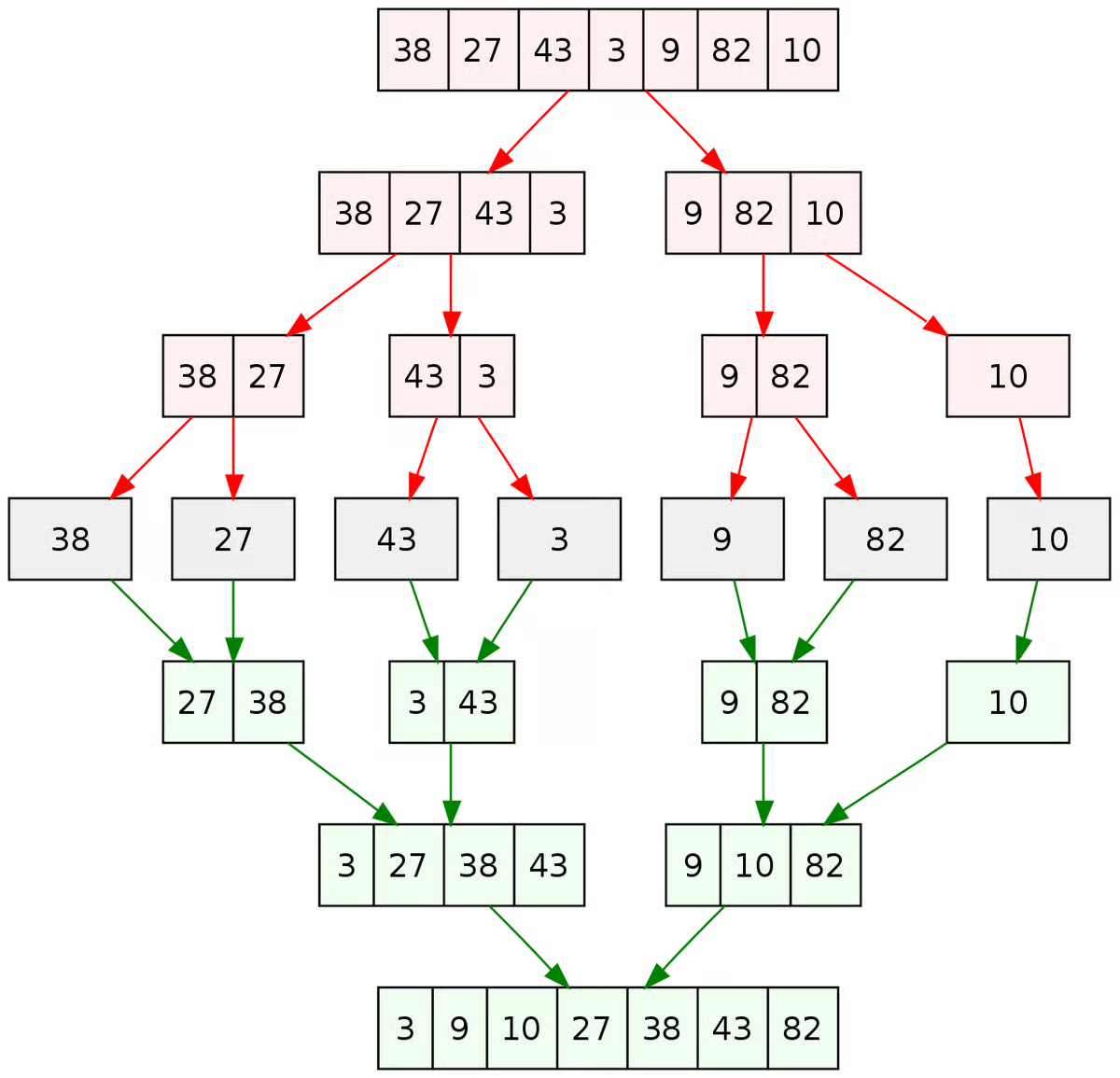
일반적인 구조는 다음과 같다.
- 문제를 여러 부분으로 분할
- 각 부분을 재귀적으로 해결
- 해결된 결과를 결합
재귀 (Recursion)
재귀 함수는 자기 자신을 호출하여 문제를 해결하는 함수이다.
문제를 같은 형태의 더 작은 문제로 나눌 수 있을 때 사용한다.
재귀 함수는 반드시 두 가지 요소를 가진다.
1) 종료 조건 (Base Case)
: 더 이상 재귀 호출을 하지 않고 값을 반환하는 조건
종료 조건이 없으면 무한 호출이 발생하기 때문에 꼭 지정해줘야 한다.
예시)
- 배열의 길이가 1 이하인 경우
- 탐색 범위가 더 이상 줄어들지 않는 경우
2) 재귀 호출 (Recursive Case)
재귀 호출이 진행되는 동안 함수 호출은 계속 쌓이고,
종료 조건에 도달한 뒤 반환되면서 계산이 수행되는 경우가 많다.
따라서 재귀 문제에서는 다음 두 가지를 구분해서 생각해야 한다.
- 내려갈 때: 문제를 어떻게 쪼개는지
- 올라올 때: 반환값으로 무엇을 계산하는지
예시
def factorial(n):
# 종료 조건 (Base Case)
if n == 1:
return 1
# 재귀 호출 (Recursive Case)
return n * factorial(n - 1)❗️ 재귀 사용 시 주의점
- 재귀 호출은 호출될 때마다 스택에 쌓이고, 종료 조건에 도달하면 반환되면서 스택에서 빠진다.
- 그래서 재귀 깊이가 깊어지면 스택 오버플로우 발생
- 종료 조건이 불명확하면 무한 재귀로 이어진다
- 동일한 하위 문제를 반복 계산하면 시간 복잡도가 급격히 증가할 수 있다.
분할정복 + 재귀 사용 알고리즘
병합 정렬 (Merge Sort)
: 중간값을 기준으로 배열을 나누고, 정렬된 결과를 다시 병합하는 방식으로 동작한다.
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left = merge_sort(arr[:mid])
right = merge_sort(arr[mid:])
return merge(left, right)- 시간복잡도:
O(n log n)- 분할 단계: 배열을 계속 반으로 나누므로 깊이는
log n - 병합 단계:각 단계마다 전체 원소
n개를 병합
- 분할 단계: 배열을 계속 반으로 나누므로 깊이는
- 공간 복잡도: 병합 과정에서 추가 배열이 필요하여, 공간 복잡도는
O(n)이 된다. - 안정 정렬
퀵 정렬 (Quick Sort)
: 퀵 정렬은 기준값(pivot) 을 기준으로 배열을 두 부분으로 나누는 정렬 알고리즘이다.
기준값보다 작은 값은 왼쪽, 큰 값은 오른쪽으로 분할한다.
- 시간 복잡도: 평균
O(n log n), 최악O(n^2) - 추가 메모리 사용이 거의 없음
- 불안정 정렬
이진 탐색 (Binary Search)
: 이진 탐색은 정렬된 배열에서, 탐색 범위를 절반씩 줄여가며 값을 탐색하는 방법이다.
-> 6주차에서 더 자세히 다룰 예정
- 정렬된 배열을 사용
- 중간 값을 기준으로 탐색 범위를 절반으로 축소
- 값이 중간 값보다 작으면 왼쪽, 크면 오른쪽을 탐색
시간 복잡도는 O(log n)이다.
문제풀이
BOJ 11729: 하노이 탑 이동 순서
BOJ 1780: 종이의 개수

정체되지 않는 성장