
과제 프로젝트 소개
내가 구현한 부분
- 임상정보를 수집하는 batch task
현재는 업데이트되지 않는 API지만 오픈API를 통해 데이터를 가져오는 방법을 익히는데 집중하기로했다. 또한 batch task scheduler를 만들어 볼 수 있는 좋은 기회가 될 것 같았따.
개발 과정
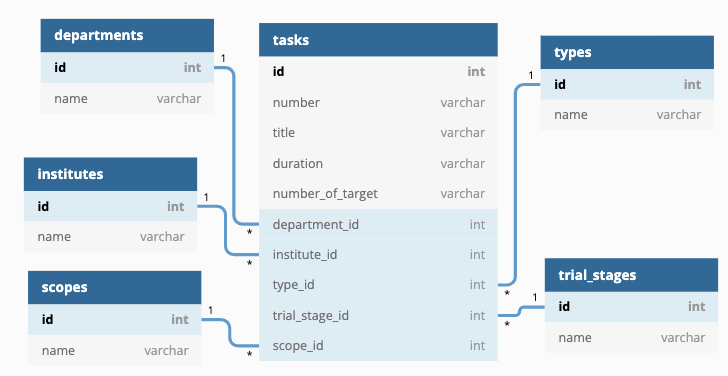
1일차 - 모델링과 crontab 세팅
-
오픈 API 데이터의 예시를 보고 모델링을 작성했는데, 중복 가능성이 많은 항목은 따로 정규화하여 관리하기로 했다.
하나의 테이블로 관리할때보다 검색이나 조회시 여러 테이블을 join해야하지만, 데이터가 많아지는 경우 확장성을 고려하면 테이블을 나누는 것이 맞다고 판단했다.
tasks 테이블이 다른 테이블들을 모두 참조하고 있는 구조인데, 외래키 데이터가 없는 경우도 있기 때문에
null=True와on_delete=models.SET_NULL옵션을 주었다.
-
django-crontab을 설치하고 settings의 apps에 추가해주었다. cron.py에daily_batch_task함수를 작성하고 정상 작동되는지 log 파일로 확인했다. 기본 시간 설정으로 1분마다 작업을 실행봤는데 제대로 오픈API에 요청을 보내고 데이터를 받아 오는 것을 확인했다.실행시 환경변수가 필요하다는 에러가 떠서
source $HOME/.zshrc;를 추가해주었다.아래
2>&1내용은 표준 에러(stderr)를 표준 출력(stdout)으로 해당 로그 파일에 나타내라는 쉘 명령어이다.

- django에서 batch task scheduler를 알아보던 중, celery-beat + crontab + redis 조합으로 비동기 스케줄링 가능하다는 내용을 보았다. 시간관계상 crontab으로만 먼저 구현해보기로했다.
2일차 - batch task 로직 작성
-
batch task의 최종 목적은 tasks 테이블의 데이터들을 업데이트 혹은 생성하는 것이다. 이를 위해 분리된 테이블 (department, institute, type 등)과 응답 데이터를 먼저 비교해서
get_or_create해주었다.빈 문자열 데이터가 들어오는 경우 None 객체로 만들기 위해 if문으로 삼항연산자를 활용했다. 이런 경우 tasks 테이블의 외래키가 null이 되는 것이다.
다음은 데이터의 고유한 키(과제번호)를 기준으로 존재하는 데이터인지 새 데이터인지 판단했다. 존재하는 경우 update하고 존재하지 않으면 create 해주었다. 이부분에서 update_or_create를 사용할 수 있을지 고민했는데, 결과적으로 사용해도 기능적 차이는 없다는 피드백을 받았다.
매번 update를 할때마다 수정사항이 없는 항목도 계속 덮어쓰고 있다는 생각이 들었다. 만약 딕셔너리 형태로 만든다면 수정된 항목만 update가 가능할지 고민해보아야겠다.
- 전체 데이터의 수만큼 요청하기 위해
get_total_count함수를 추가해주었다. 처음에는 큰 숫자로 하드코딩했었지만 좋지 않은 방법이라 느껴졌고, 첫 요청시 total_count를 받아와서 두번째 요청에서 total_count만큼 데이터를 받아왔다.
- 데이터가 없어진 경우 delete하는 기능은 생각하지 못했다. 다양한 경우를 생각하고 촘촘하게 API를 설계하지 못한 점이 아쉽다. 너무 단순한 설계와 기능만 구현했던 것 같아서 추후 삭제와 일부 수정 기능이 가능하도록 수정해야겠다.
간과한 점
update와 create 나누지 말고 upsert 이용하기 -> 어차피 덮어쓰는 로직이라면
없어진 부분을 삭제하거나 수정된 부분만 업데이트하는 로직 없음
request 라이브러리 사용시 timeout 옵션 반드시 설정하기!!!
다른팀의 로직
tasks 테이블의 각 오브젝트마다 해쉬값을 만들어서 비교하기
-> 존재여부와 difference를 찾아낼 수 있다.
다만, key 정렬을 해서 반드시 필드 순서가 동일해야하고 문자열 포맷도 동일해야한다.
느낀점과 개선점
Log 파일 관리
-
로컬 환경에서 batch job의 작동여부를 확인하기 위해 log 파일을 이용했었는데, 에러발생시 email로 log를 받는 것까지 추가하면 좋을 것 같다. 현업에서는 이런 모니터링 시스템 구축이 반드시 필요할 것이다.
cron job의 설정으로 날짜별 log 파일을 만들 수 있고, cron 작업이 실패했을 때만 로그 메일을 전송할 수 있다고 한다.
페이지네이션 피드백
- Open API를 이용해 데이터를 요청해보니 데이터의 수량, 전체 수량, 페이지 번호, 페이지당 데이터 수량 등이 응답에 담겨서 함께 왔다. 실제 현업에서 페이지네이션을 어떤식으로 구성하는지 알 수 있었다.

-
Offset 기반 페이지네이션에서 주의 할점
-
page_size (per_page)는 하드코딩하지 말고 차라리 파라미터로 받는다.
-
limit과 offset은 default 값을 정해준다.
-
limit과 offset은 DB Query에 바로 적용해서 필요한 데이터만 읽어온다.
-
count 등 general한 정보도 함께 보내준다. -> aggregation 함수를 사용하자. (ex: Model.objects.count())
-
- 프로젝트를 마치며
오픈API와 batch task를 다뤄볼 수 있는 좋은 기회였다. 크롤링을 하거나 오픈 API로 데이터를 수집하고 관리하는 프로젝트를 해보고 싶었다. 이런 batch task를 통해 데이터를 모을 수 있다면, 실존하는 데이터를 활용한 다양한 프로젝트가 가능할 것 같다.
또한 여러 작업을 동시에 진행할 수 있는 비동기 처리의 기본적인 개념을 알 수 있었고 worker 역할을 하는 celery와 message broker 역할을 하는 RabbitMQ, redis에 대해 알 수 있었다. 다음번에 비동기 작업을 해야할때는 조합해서 이용해봐야겠다. 여러개의 task를 관리하는 방법도 알아봐야겠다.
반면에 crontab job의 log를 관리하거나, batch task의 로직을 더 촘촘하게 구성하지 못한 것은 아쉬운 점이다. 짧은 시간이 문제였다고 하기에는 아예 생각하지 못한 케이스도 있었기에 앞으로 추가하고 수정해나갈 예정이다.
