
RUST 로 공부하는 비동기 프로그래밍 시리즈
백엔드 개발자라면 비동기프로그래밍에 대해서 정말 많은 이야기를 들어보셨을거에요. 면접 단골 질문인 Node.js의 Event Loop부터 GoLang의 Goroutine까지 정말
비동기 라는 말을 안 들어봤으면 백엔드 개발자가 아니라는 말도 있을 정도니 정말 중요한 주제임을 틀림이 없는것 같습니다. 그럼 과연 비동기 프로그래밍은 무엇이고 왜 알아야하고 어떻게 사용하는게 좋을까요? 저는 이 시리즈에서 비동기 프로그래밍에 대해서 간략한소개를 해볼까 합니다. 비동기 프로그래밍을 소개한 다른 글은 많지만 이 시리즈는 개념부터 실제로 비동기 런타임을 코드로 구현을 해서 최대한 자세하기 설명 하는것을 목표로 합니다. 제가 지금 현업에서 러스트를 사용하고 있고 러스트를 좋아하기 때문에 이 글에서의 코딩 부분은 러스트로 할 예정입니다~
먼저 시리즈의 순서는
-
비동기 프로그래밍은 무엇인가?
-
Scheduler 이해하기
-
Rust에서의 비동기 프로그래밍
-
Rust Tokio 이해하기
입니다. 이 중 오늘은 Scheduler에 대해서 알아보겠습니다. 틀린 부분이나 설명이 모호한 부분이 있다면 댓글 혹은 이메일로 알려주시면 감사하겠습니다~
Scheduler의 필요성?
1편에서 저희는 Green Thread Scheduler에 개념에 대해서 간단하게 정리하고 마무리했습니다. 잠시 복습을 하자면 스케쥴러는 여러 작업들을 non blocking 하게 실행하고 작업들의 결과값을받으면 다시 어떤 행동을 취할지는 결정해주는 비동기 프로그래밍의 코어입니다. 여기서 Scheduler는 스케쥴러의 핵심으로 모든 작업들을 orchestrate 하는 역할을 합니다. 작업들을 orchestrate 하는게 무슨 의미나요고? 예를 통해 한번 살펴보죠.
저는 지금 웹 서버를 하나 만들고 싶습니다. 이 웹 서버의 역할을 단순합니다. REST API를 사용해서 /info 에 post request 를 보내게 되면 들어온 info data를 제 컴퓨터 파일에 append 하고 그 결과에 따라 success/fail을 보내주면 됩니다. 이 웹 서버가 /info API를 통해 하는 일들을 순서대로 적어보면
- request 받기
- file에 write 하기
- 2번의 결과에 따라 성공이면 success 메세지를 실패라고 하면 fail 메세지를 리턴하기
입니다. 만약 비동기 프로그래밍을 사용하기 않고 동기로 이 작업들을 처리한다면 어떤 일이 발생할까요? 만약 한 쓰레드로 1번에서 네트워크 수신을 받고 2번의 file I/O가 끝날때까지 기다렸다가 3번 작업을 해야됩니다. 일반적인 상황에서는 2번의 file I/O가 필요하는 자원의 양이 압도적으로 많기 때문에 해당 스레드는 2번 작업이 끝날때까지 더 이상 작업을 진행하지 못하는 비효율적인 상태에 이르게 됩니다. 만약 제 서버의 스레드가 1개 밖에 없고 file I/O가 꽤 오랜시간 걸린다고 하면 /info API를 호출하는 사용자들은 앞에 다른 사용자의 작업이 끝날때까지 더 이상 작업이 진행되지 못하게 되는 최악의 상황이 발생하게 됩니다. 그렇다면 비동기 프로그래밍을 사용하게 되면 어떻게 이런 요청들을 효율적으로 처리할수 있을까요? 지금까지 글을 쭉 읽어오셨다면 아마 대략적인 답을 아시고 계실겁니다. 그래도 더 자세히 이해하기 위해서 비동기 프로그래밍의 코어인 Scheduler의 구조를 한번 같이 알아보겠습니다.
Scheduler 이해하기
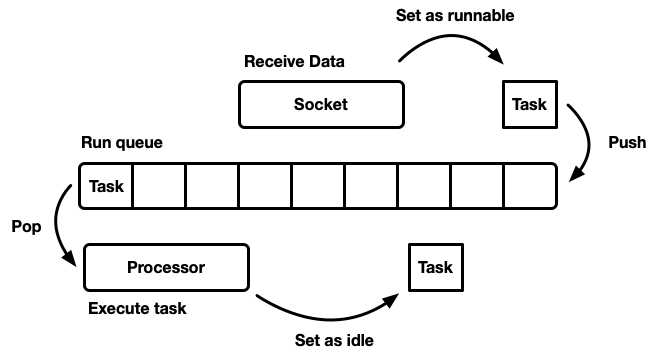
Disclaimer: Js의 Event loop 에 대해서 알고 계신분들은 위 그림이 조금 이질적으로 느껴지실수도 있습니다. Node의 Event loop을 설명하는 이미지에서 자주 등장하는 Web apis, dom 같은 설명들이 없기 때문에 Node의 Event loop이랑 Scheduler의 개념이 다른가? 라고도 느끼실수 있습니다. 그러나 사실 Scheduler의 핵심은 위 이미지에서 나온 Run queue이고 이를 다양한 프레임워크에서 어떤 방식으로 적용하냐에 따라서 이름과 구조가 조금 다를 수 있습니다!
그림을 보시면 먼저 Scheduler에서의 핵심이 되는 run queue의 역할을 대충 알수 있습니다. 하나의 task는 runnable과 non-runnable 의 상태를 가지고 있는데 runnable 인 task 들은 run queue에 올라올수 있습니다. runnable 인 task들이 run queue 에 순차적으로 들어오게 되면 run queue 는 이를 여러 개의 Processsor에 분배를 하게 됩니다. Processor는 task를 실행하고 만약 추가적인 작업이 필요하다면 task를 다시 runnable 형태로 run queue에 넣습니다. 여기서 Processor가 task를 실행한다고 할때 이는 단순히 CPU를 사용해서 task를 실행하는것이 아닙니다. 대부분의 작업은 CPU의 연산이 주를 이루는 CPU Intensive task와 I/O 작업이 주를 이루는 I/O Intensive task로 나뉘게 되는데 간략한 그림을 위해서 둘다 Processor 에서 처리를 한다고 했는데 이에 대해서는 부가 설명이 필요합니다. CPU Intensive task의 경우 연산이 많이 필요하기 때문에 실제로 thread 하나를 꽤 긴시간 동안 사용하게됩니다. 이 경우 해당 thread는 해당 task 를 진행하는 동안에는 다른 일을 할 수 없게 됩니다. 이에 비해 I/O Intensive 한 task는 작동 방식이 조금 다릅니다. I/O 작업에는 CPU 연산이 필요하지 않기 때문에 i/o 작업의 경우 CPU가 hard drive 에 I/O 작업을 요청한 후 즉시 리턴을 해서 다른 task를 진행할수 있는 상태가 됩니다. 이 후 I/O 작업이 끝나게 되면 drive 는 CPU에 interrupt signal 을 보내서 자신의 작업이 종료되었음을 알리고 이 결과물이 다시 task가 runnable로 바뀌어서 run queue 에 올라가게 됩니다. 즉, I/O intensive task 의 경우 green thread들은 I/O 작업이 끝날때까지 기다릴 필요가 없고 drive 에 I/O 작업을 요청한뒤 바로 다음 task 를 처리할수 있는 상태가 됩니다.
그렇다면 이를 통해 위에서 예시로 보았던 /info REST API를 Scheduler 이 어떻게 처리하는지 쉽게 알아볼수 있습니다.
- /info 라는 리퀘스트를 통해 파일A 가 socket buffer에 채워집니다.
- 이 작업은 하나의 task 로 포장이 되어서 run queue 에 올라가게 됩니다.
- run queue에서는 이 작업을 받아서 앞의 있는 task부터 순차적으로 processor에 넘기게 됩니다.
- /info 리퀘스트는 먼저 파일A를 드라이브에 써야 하기 때문에 프로세서는 drive 에 fileA를 드라이브에 쓰라는 명령을 내리고 자신은 리턴합니다.
- 그 후 drive 에서 파일A를 다 쓴 후 interrupt signal 을 보내 작업이 완료되었음을 알립니다.
- 그러면 다시 이 task 는 run queue에 올라가게 됩니다.
- run queue에서 다시 processor 로 보내지게 되고 이번에는 drive에 파일을 쓴 결과를 가지고 성공이었으면 success, 실패했으면 fail 의 메세지를 리턴하게 됩니다.
하나의 작업을 처리하는데 7개의 step을 거치게 되어서 Scheduler가 오히려 비효율적인것 아니야? 라는 생각을 하실수도 있습니다. 물론 만약 제 서버가 항상 제 컴퓨팅 자원(cpu의 개수)보다 더 적은수의 네트워크 리퀘스트를 받는다면 이 Scheduler는 제 서버의 성능 개선에 도움이 되지 않습니다. 그러나 만약 한정된 자원에서 많은 양의 리퀘스트를 처리해야 한다면 Scheduler을 사용해서 더 효율적으로 많은 수의 리퀘스트를 빠르게 처리할수 있게 됩니다. 여기서 짚고 넘어가야 할점은 Scheduler의 장점은 실행하는 작업이 I/O intensive 한 task 여야 한다는 점입니다. 만약 제가 하려는 작업들이 cpu intensive task 여서 어쩔수 없이 CPU 연산을 계속 사용해야 한다면 Scheduler에서의 장점을 가져가기 어렵습니다.
여기까지 읽으셨다면 아마 이런 생각이 드실겁니다. 그렇다면 어떤 방식으로 scheduler는 task 들을 processor에 분배를 하지? 프로세서가 여러개라면 그냥 단순히 round robin 방식으로 하나씩 task 를 전달해주는 방식인가? 매우 훌륭한 질문이십니다! 제가 명쾌하게 어떤 방식이 가장 좋다!라고 말씀드리고 싶지만 안타깝게도 이 부분에 대해서는 아직까지도 많은 연구들이 이루어지고 있어서 아직 명쾌하게 best practice 라고 정해진 알고리즘은 없습니다. 가장 쉬운 round- robin 방식의 task scheduling 부터 Goroutine과 Tokio가 사용하고 있는 work-stealing scheduling 방식까지 매우 다양한 알고리즘이 있습니다. 이 글에서는 work-stealing algorithm에 관해 간단하게 짚고 넘어가도록 하겠습니다!
Fair Scheduling
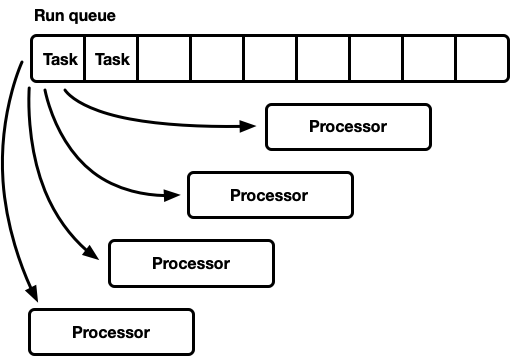
위 그림처럼 일반적으로 하나의 컴퓨터에는 여러 개의 cpu 가 존재합니다. 이런 상황에서 run queue는 task 를 어떤 processor에 할당하는지는 매우 중요한 문제입니다. 각각의 task 의 예상 소요 시간을 run queue 에서 예상을 하는것은 매우 어렵기 때문에 만약 round robin 방식으로 task 들을 분배하게 되면 몇몇 프로세서들은 매우 빨리 task 들을 처리하지만 몇몇 프로세서들은 연산 작업이 많은 task를 받아서 병목현상이 발생할수 있기 때문입니다. 비동기 프로그래밍에서 궁극적인 목적은 한정된 자원을 효율적으로 사용하는것이기 때문에 이와 같은 병목 현상은 최대한 피해야 합니다. 이를 해결하기 위해 나온 알고리즘이 바로 Work-stealing algorithm 입니다. Work-stealing algorithm 의 기본 아이디어는 각각의 thread각 자신의 run queue를 가지고 있다는 점입니다. (물론 scheduler는 global run queue 를 가지고 있습니다!) 각각의 프로세서는 기본적으로 global run queue로부터 task 를 받아오되 만약 자신의 현재 run queue가 비어있다면 다른 thread들의 run queue에서 task 들을 뺏어올수 있습니다. 이를 통해 작업이 먼저 끝난 프로세서들은 작업량이 많은 다른 프로세서들의 일을 대신 해줌으로써 전체적으로 프로세서들이 cooperative 하게 작업들을 진행시킵니다. 물론 work stealing algorithm 에서도 얼마나 많은 task를, 얼마나 자주 뺏어오는지에 대한 최적화는 각 프레임워크마다 다르게 적용하고 있습니다. 이 work-stealing algorithm을 실제로 rust code로 구현해보는 일은 이 시리즈가 끝난 후 다른 글로 다시 한번 자세히 다루도록 하겠습니다!
마치면서
이번 편을 통해 Scheduler에 대해서 공부를 해보았습니다. 제가 부족한 부분이 많아 설명이 잘못되었거나 모호한 부분이 있을수 있습니다. 댓글로 편하게 지적해주시면 바로 수정하겠습니다~ 감사합니다~
이 글은 제가 근무하고 있는 크래프트테크놀로지스의 지원을 받아 작성되었습니다. 저희 회사에서는 여러 제품들에서 rust를 사용하고 있으며 Rust를 사용해서 더 멋있는 제품을 만드려고 노력중입니다. 같이 빠르고 안전한 금융 서비스분들을 아래 링크를 참조해주세요!
Reference

와 정말 쉽게 설명해주시네요.. 감사합니다!!