Principal Component Analysis(1) : 필요성, 차원의 저주
어떤 알고리즘을 적용하기 전, 데이터 전처리 이후 필요한 작업이 있습니다. 먼저 알아야 할 내용은 알고리즘보다 갖추고 있는 데이터가 더 중요하다는 점입니다. 데이터 확보와 전처리가 잘 이뤄지면 어떤 알고리즘을 사용하더라도 좋은 성능을 보입니다. 그런데 데이터 확보와 전처리가 전부는 아닙니다. 확보한 데이터를 갖고 더 많은 변수를 만들어낼 수도 있습니다. 갖고 있는 변수와 변수 사이의 연산을 통해서 파생된 변수를 알고리즘에 활용할 수 있다는 의미입니다. 그런데 무작정 많은 데이터를 확보하거나 많은 변수를 생성하는 것이 좋은 것은 아닙니다.
차원의 저주
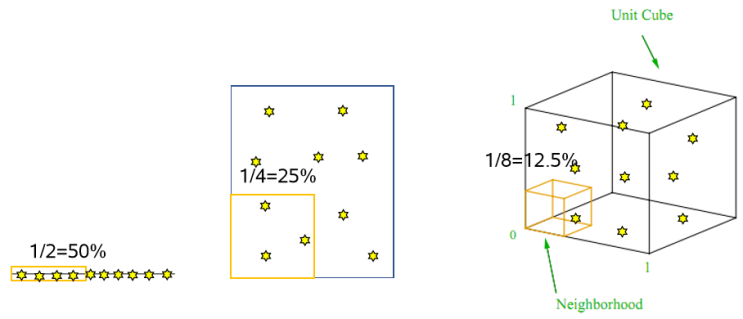
위 그림을 보면 1차원, 2차원, 3차원인 그림 세 가지가 있습니다. 차원은 변수 하나라고 생각할 수 있습니다. n차원인 경우 Xn 변수가 추가되는 것으로 설명하겠습니다. 1차원 내에 알고 있는 데이터가 그림처럼 50%라고 가정하겠습니다. 즉 X1 변수의 절반을 알고 있는 것입니다. 이때 차원이 하나 늘어나면 X2가 추가되는 것이라고 생각할 수 있고, X2 변수 역시 모든 데이터를 확보할 수 없으니 50%만을 알 수 있다고 하겠습니다. 그러면 설명해야 하는 데이터 전체의 25%만을 알고 있는 것입니다. 3차원도 같은 방식으로 설명할 수 있습니다. 극단적인 예시를 들면 만약 변수가 100개인데 데이터는 10개인 경우, 변수가 늘어남에 따라 예측하고자 하는 변수를 제외한 나머지 변수 사이에 많은 데이터가 있을 것이고 경우의 수가 지나치게 늘어나 성능이 설명력을 잃게 되는 것을 생각해볼 수 있습니다.
