부스트코스 : '파이썬으로 시작하는 데이터 사이언스' 코칭스터디 8기 2주차

인공지능 동아리에서 팀원분들과 함께 처음으로
부스트코스 활동을 하게 되었습니다!
예전에는 시간이 부족하지 않을까 라는 걱정에 이런 것들을 하지 않았지만
우리 팀원분들과 함께 도전해봤습니다 :D
원래는 개인 노션에만 정리하고 노션 페이지를 다른 분들과 공유할 생각이었는데
팀원분께서 하신 것처럼 velog에 정리하는 것도 정말 좋은 방법인 것 같아서 정리해봅니다!
(그래서 1주차는 패스..ㅎㅎ)
<2주차 활동 내용>
결측치 다루기
수치 데이터 요약하기
문자열 데이터 요약하기
데이터 시각화
원하는 데이터만 추출하기
🎓데이터 요약하기
🦭결측치 다루기
- 결측치 확인 : isnull, sum 활용!
null_count = df.isnull().sum()
null_count
위와 같이 행별로 결측치의 수를 알 수 있다!!
데이터프레임으로 나타내는 것도 가능하다.
#reset_index()를 이용해 데이터프레임으로 변경
df_null_count = null_count.reset_index()
#컬럼명 변경
df_null_count.columns = ["컬럼명", "결측치수"]
#내림차순으로 정렬
df_null_count.sort_values(by="결측치수", ascending=False)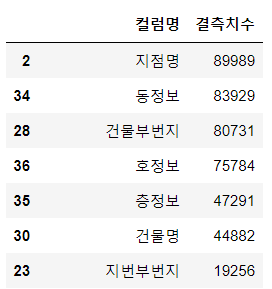
🔔수치 데이터 요약하기
🦭기초 통계값 요약하기
#평균
df["위도"].mean
#중앙값
df["위도"].median()
#최대값
df["위도"].max()
#최소값
df["위도"].min()
#개수
df["위도"].count()
#요약값 확인
df["위도"].describe()
#두개 이상의 column 요약
df[["위도", "경도"]].describe()- 1개의 데이터 출력 : series 데이터 타입
- 2개 이상은 DataFrame 으로 출력
🦭특정 데이터만 요약
# 숫자로 된 데이터만 요약
df.describe(include="number")
#문자열 데이터만 요약 : object
df.describe(include="object")
#모든 데이터 요약
df.describe(include="all")결측치는 요약하지 않는다!!
📑문자열 데이터 요약하기
🦭중복값 다루기
- unique(), nunique() : 겹치지 않는 값들의 종류와 개수!
#겹치지 않는 값들의 종류 보여줌
df["상권업종대분류명"].unique()
#출력 : array(['의료'], dtype=object)
#개수 출력 : 몇개의 값을 가지고 있나
df["상권업종대분류명"].nunique()
# 출력 : 1🦭그룹화된 요약값 보기
- value_counts() : 각 value의 수를 센다.
df["시도명"].value_counts()
경기도 21374
서울특별시 18943
부산광역시 6473
경상남도 4973
인천광역시 4722
대구광역시 4597
경상북도 4141
전라북도 3894
충청남도 3578
전라남도 3224
광주광역시 3214
대전광역시 3067
충청북도 2677
강원도 2634
울산광역시 1997
제주특별자치도 1095
세종특별자치시 353- normalize : 비율을 계산해준다.
df["시도명"].value_counts(normalize=True)
경기도 0.234993
서울특별시 0.208266
부산광역시 0.071166
경상남도 0.054675
인천광역시 0.051915
대구광역시 0.050541
경상북도 0.045528
전라북도 0.042812
충청남도 0.039338
전라남도 0.035446
광주광역시 0.035336
대전광역시 0.033720
충청북도 0.029432
강원도 0.028959
울산광역시 0.021956
제주특별자치도 0.012039
세종특별자치시 0.003881🧵데이터 시각화
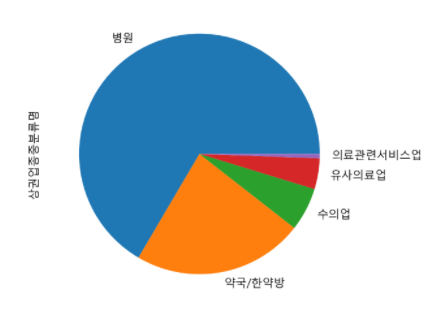
c = df["상권업종중분류명"].value_counts()
c.plot.bar(rot=0)
n.plot.pie()
c = df["상권업종소분류명"].value_counts()
c.plot.bar()
#사이즈 조절 & 그리드
c.plot.bar(figsize=(7,8), grid=True)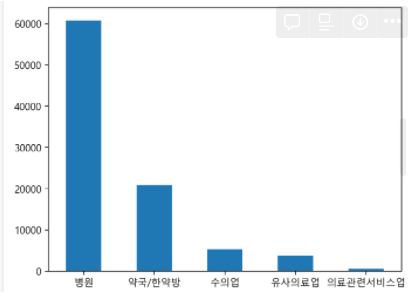
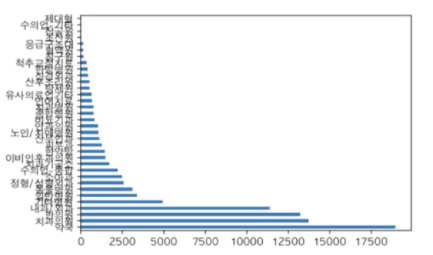
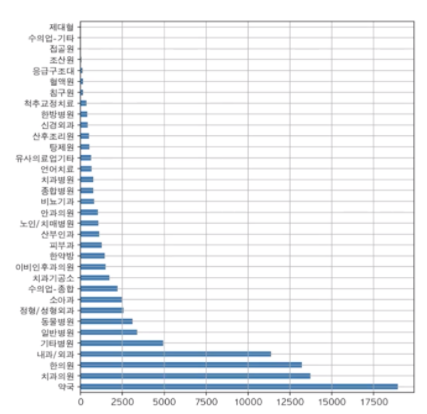
🦭seaborn으로 시각화하기
sns.countplot(data=df, y="시도명")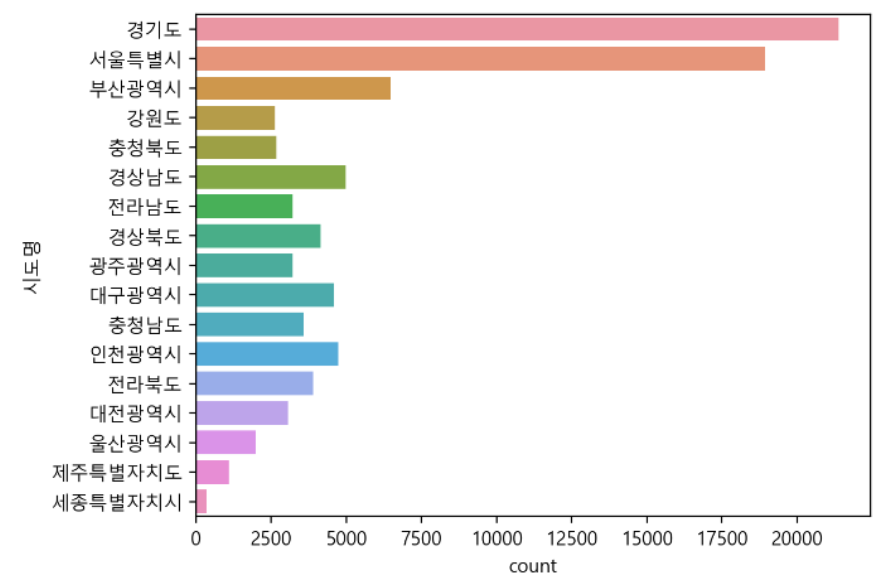
🎯원하는 데이터만 추출하기
- copy()를 해야 warning이 뜨지 않거나 원본에 영향을 미치지 않는다.
df_medical = df[df["상권업종중분류명"] == "약국/한약방"].copy()🦭2개 조건 사용하기
- loc : 상권업종대분류명이 의료인 데이터의 상권업종중분류명을 가져오고 싶을 때
df.loc[df["상권업종대분류명"] == "의료"]["상권업종중분류명"]
#첫 번째 방법은 두 번 검색해서 속도가 느리다!
df.loc[df["상권업종대분류명"] == "의료", "상권업종중분류명"]🦭연산자 사용
- &, | : and, or
(df["상권업종소분류명"] == "약국") & (df["시도명"] == "서울특별시")🦭텍스트 데이터 색인하기
- str.contains()
#상호명에 "종합병원"이라는 문구가 들어간 데이터만
df_seoul_hospital["상호명"].str.contains("종합병원")
#상호명에 종합병원이 들어간 데이터의 상호명을 중복 없이 가져온다.
df_seoul_hospital.loc[~df_seoul_hospital["상호명"].str.contains("종합병원"), "상호명"].unique()🦭제거할 데이터 지정하기
- .index : 인덱스 번호를 뽑기
- tolist() : 리스트 형태로 변환
#상호명에 여러개의 데이터(꽃배달, 의료기, 장례식장, 상담소, 어린이집)이 들어간 데이터의 인덱스 번호를 리스트 형태로 변형
drop_row = df_seoul_hospital[
df_seoul_hospital["상호명"].str.contains("꽃배달|의료기|장례식장|상담소|어린이집")].index
drop_row = drop_row.tolist()
#상호명에 의원이 들어간 데이터의 인덱스 번호를 리스트 형태로 변형
drop_row2 = df_seoul_hospital[df_seoul_hospital["상호명"].str.endswith("의원")].index
drop_row2.tolist()- drop : axis = 0 -> 행 기준 / axis = 1 -> 열 기준
#데이터 합치기
drop_row = drop_row + drop_row2
#데이터 제거
df_seoul_hospital = df_seoul_hospital.drop(drop_row, axis=0)📌scatterplot으로 표현하기
전에 barplot, seaborn 복습ㅎ
🦭barplot
- figsize : 그래프 크기 지정
- rot : 글자 기울기 지정
df_seoul ["시도명"].value_counts().plot.bar(figsize=(10, 4), rot=30)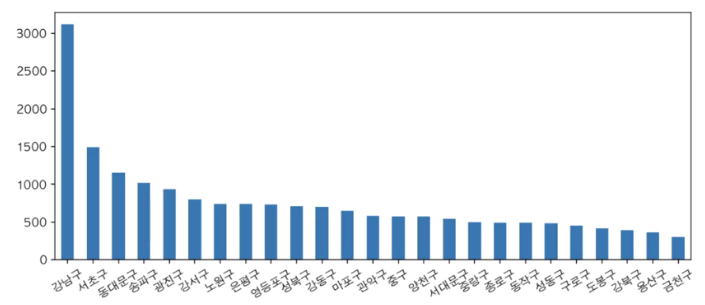
🦭seaborn
plt.figure(figsize=(15, 4))
sns.countplot(data=df_seoul, x="시군구명")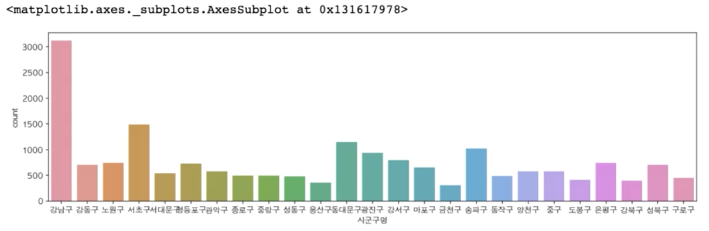
🦭scatterplot
df_seoul[["경도", "위도", "시군구명"]].plot.scatter(x="경도", y="위도", figsize=(8, 7), grid=True)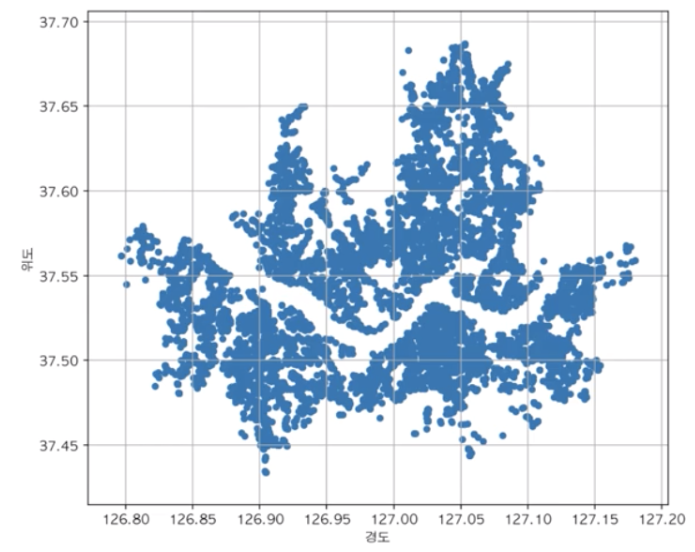
- hue를 활용하여 상권업종중분류 별로 다른 색상을 적용
plt.figure(figsize=(9, 8))
sns.scatterplot(data=df_seoul, x="경도", y="위도", hue="상권업종중분류명")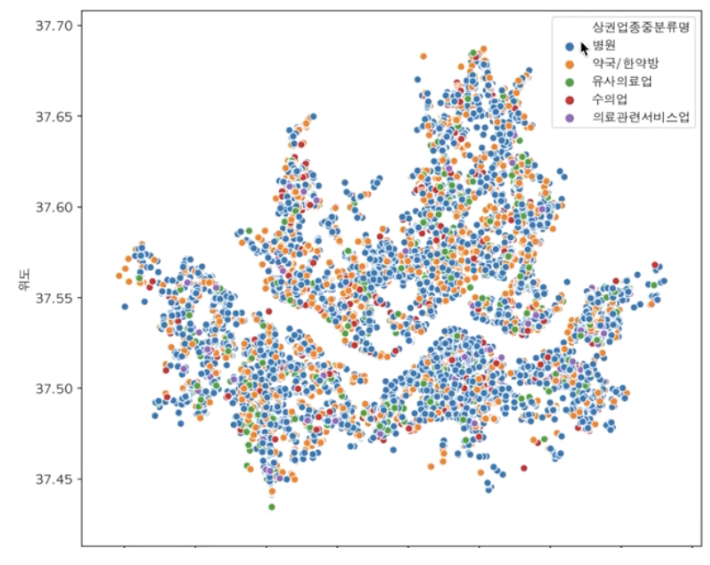
😂folium
아직도 헷갈리는 folium ㅜㅠㅠㅠㅠㅠ
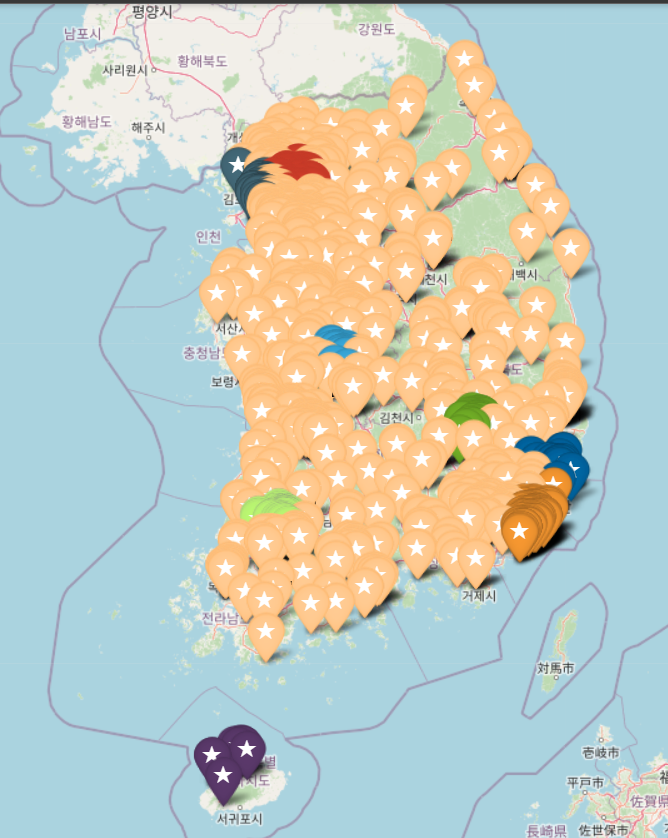
## 상권업종소분류명이 '노인/치매병원'인 데이터만 추출
silver_pos = df.loc[df['상권업종소분류명']=='노인/치매병원']
## 지도에서 광역시별로 색칠하기 위해서 color라는 열을 추가 한 후, 광역시별 색정보 추가
### 서울특별시 : red, 부산광역시 : orange, 광주광역시 : lightgreen
### 대구광역시 : green, 인천광역시 : cadetblue, 대전광역시 : blue
### 울산광역시 : darkblue, 제주특별자치도 : darkpurple, 그외 : beige
for i in silver_pos.index :
if "서울특별시" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'red'
elif "부산광역시" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'orange'
elif "광주광역시" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'lightgreen'
elif "대구광역시" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'green'
elif "인천광역시" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'cadetblue'
elif "대전광역시" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'blue'
elif "울산광역시" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'darkblue'
elif "제주특별자치도" in str(silver_pos.loc[i,'시도명']) :
silver_pos.loc[i,'color'] = 'darkpurple'
else : silver_pos.loc[i,'color'] = 'beige'
pos = [silver_pos['위도'].mean(),silver_pos['경도'].mean()] # 평균 위도/경도 추가
import folium
map = folium.Map(location = pos, zoom_start=6)
for n in silver_pos.index:
name = silver_pos.loc[n, "상호명"]
address = silver_pos.loc[n, "도로명주소"]
popup = f"{name}-{address}"
location = [silver_pos.loc[n, "위도"], silver_pos.loc[n, "경도"]]
col = silver_pos.loc[n, "color"]
folium.Marker(
location = location,
icon=folium.Icon(color=col,icon='star', size=1), # 아이콘의 색은 위에서 지정해준 색으로 설정, icon모양은 별표로 설정
popup = popup,
).add_to(map)
map