부스트코스 : '파이썬으로 시작하는 데이터 사이언스' 코칭스터디 8기 3주차

팀원분들과 다같이 들으니깐 정말 열심히 정리하려고 했는데...
정말 그런 마음이었는데...
분명 쉬지 않고 과제를 하는데 과제가 끝나지 않고, 부스트코스 공부 내용도 반복되는 내용이 많아서 3주차는 간략히 정리ㅎㅎㅎㅎ😂😂😂
3주차 공부내용
- 결측치, 요약, 집계
- groupBy, pivot_table
- 데이터 자세히 표현하기 : 시각화
🔑결측치, 요약, 집계
🦭df.isnull()
결측치인 것은 True로, 아닌 것은 False로 표시된다.
#열 별로 결측치 갯수를 알려줌
df.isnull().sum()🦭특정 열만 불러오기
#열 별로 결측치 갯수를 알려줌
df["(헐청지오티)ALT"]
#두개 이상 가져올 때는 리스트로 감싸주기
df[["(혈청지오티)ALT","(혈청지오티)AST"]]하나만 가져오면 series 형태, 2개 이상 열 가져오면 dataframe 형태
🦭value_counts
category나 text 형태 데이터의 빈도수 체크
df["성별코드"].value_counts()📕groupby, pivot_table
🦭groupby 예시
df.groupby(["성별코드"]).mean()
df.groupby(["성별코드"]).count()
df.groupby(["성별코드"])["가입자일련번호"].count()
df.groupby(["성별코드", "음주여부"])["가입자일련번호"].count()
df.groupby(["성별코드", "음주여부"])["감마지티피"].mean()
df.groupby(["성별코드", "음주여부"])["감마지티피"].describe()
df.groupby(["성별코드", "음주여부"])["감마지티피"].agg(["count", "mean", "median"])🦭pivot_table 예시
#기본적으로 평균값을 구한다.
pd.pivot_table(df, index="음주여부", values="감마지티피")
pd.pivot_table(df, index="음주여부", values="감마지티피", aggfunc=["mean", "median"])
pd.pivot_table(df, index="음주여부", values="감마지티피", aggfunc="describe")
pd.pivot_table(df, index=["음주여부", "성별코드"], values="감마지티피", aggfunc="describe")- pivot_table의 연산 속도가 groupby보다 빠르다.
📢데이터 자세히 표현하기 : 시각화
🦭히스토그램
#12~23번째 행까지 그리기
h = df.iloc[:, 12:24].hist(figsize(12, 12))
#bins 옵션으로 막대 개수 잘게 그리기
h = df.iloc[:, 12:24].hist(figsize(12, 12), bins=100)
🧵barplot
카테고리형 데이터가 섞여 있는 경우에는 hue인수에 카테고리 변수 이름을 지정하여 카테고리 값에 따라 색상을 다르게 할 수 있다.
- 신뢰구간 : ci
95%의 신뢰구간을 지정하고 싶을 경우 ci=95 설정
신뢰구간 표시하고 싶지 않다면 None 설정
ci = sd : 표준편차 표시
plt.figure(figsize=(15,4))
sns.barplot(data=df_sample, x="연령대코드(5세단위)", y="총콜레스테롤", hue="흡연상태")
sns.barplot(data=df_sample, x="연령대코드(5세단위)", y="트리글리세라이드", hue="음주여부", ci=95)
#신뢰구간 표시하고 싶지 않다면 None 설정
sns.barplot(data=df_sample, x="연령대코드(5세단위)", y="체중(5Kg 단위)", hue="성별코드", ci=None)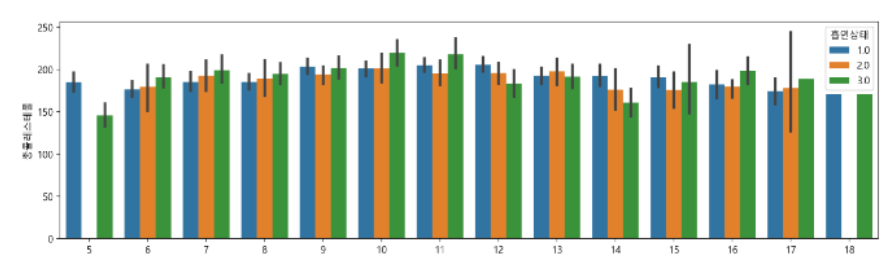
🧵lineplot
편차, 신뢰구간을 그림자로 표현한다.
plt.figure(figsize=(15,4))
sns.lineplot(data=df_sample, x="연령대코드(5세단위)", y="신장(5Cm단위)", hue="성별코드", ci="sd")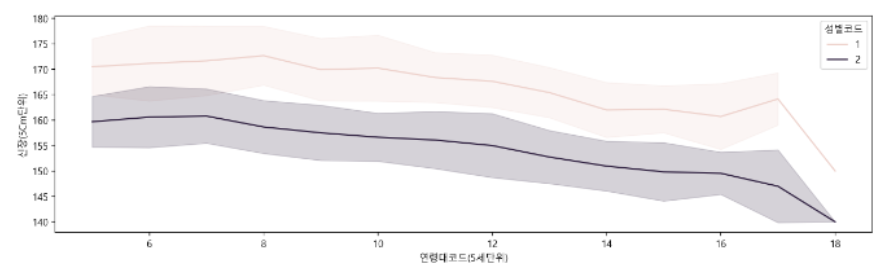
🧵pointplot
plt.figure(figsize=(15,4))
sns.pointplot(data=df, x="연령대코드(5세단위)", y="신장(5Cm단위)", hue="음주여부", ci="sd")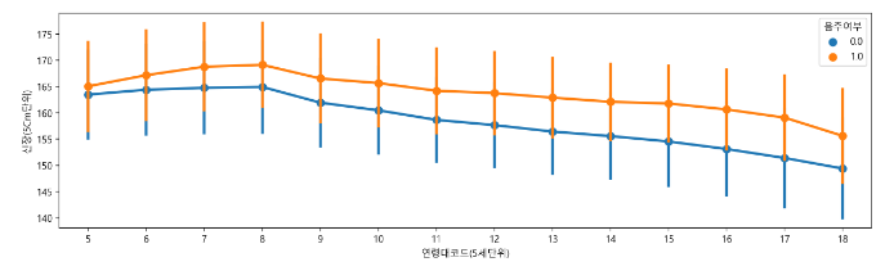
barplot은 막대로 개별값을 표현하는데 lineplot, pointplot을 통해서는 선으로 기울기까지 표현할 수 있다.
가격 데이터, 매출/재고 데이터는 대체로 lineplot, pointplot 으로 그리는 것이 좋다.
🧩boxplot
plt.figure(figsize=(15, 4))
sns.boxplot(data=df, x="신장(5Cm단위)", y="체중(5Kg 단위)", hue="성별코드")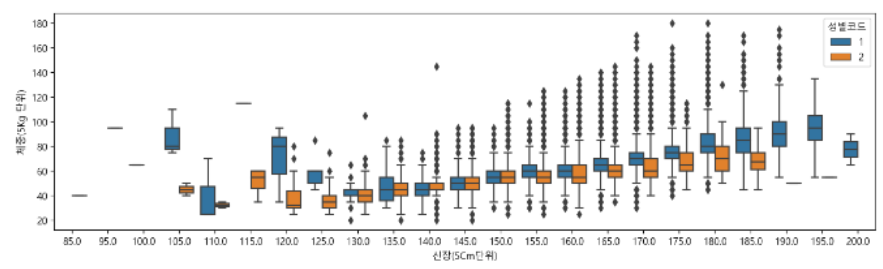
그래프에 있는 사각형 안의 분포를 자세히 그리기 어렵다는 단점이 있다.
🧩violinplot
위 boxplot의 단점을 보완한 그래프다.
plt.figure(figsize=(15, 4))
sns.violinplot(data=df, x="신장(5Cm단위)", y="체중(5Kg 단위)")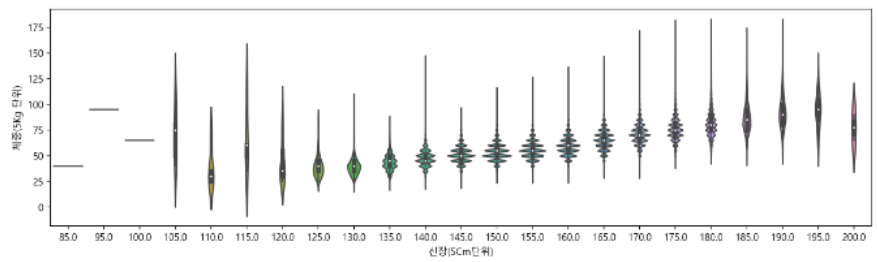
- spllit 옵션 : 두 개의 데이터를 붙일 수 있다.
plt.figure(figsize=(15, 4))
sns.violinplot(data=df_sample, x="신장(5Cm단위)", y="체중(5Kg 단위)", hue="음주여부", split=True)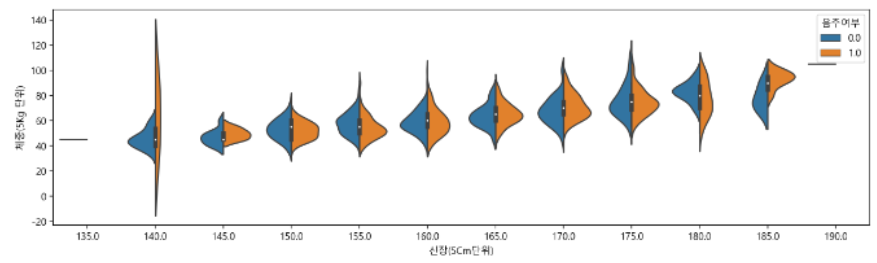
boxplot을 그리면 이상치를 확인하기 좋다. violinplot은 분포를 더 자세히 볼 수 있다.
🏹swarmplot
plt.figure(figsize=(15, 4))
sns.swarmplot(data=df_sample, x="신장(5Cm단위)", y="체중(5Kg 단위)", hue="음주여부")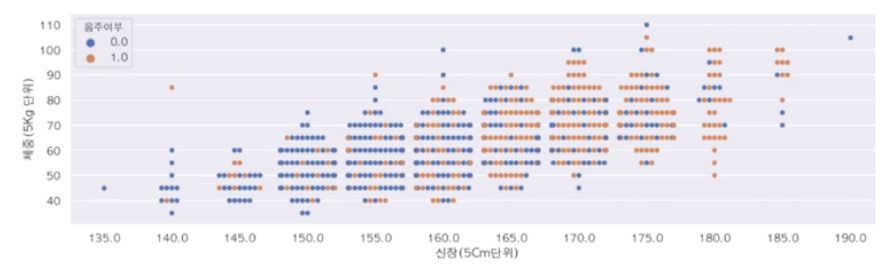
🏹lmplot
categorila 데이터로 인식해 그리드처럼 격자로 나온다.
오른쪽 위로 선이 그려지면 양의 상관관계가 있다고 표현한다.
sns.lmplot(data=df_sample, x="연령대코드(5세단위)", y="혈색소", hue="음주여부")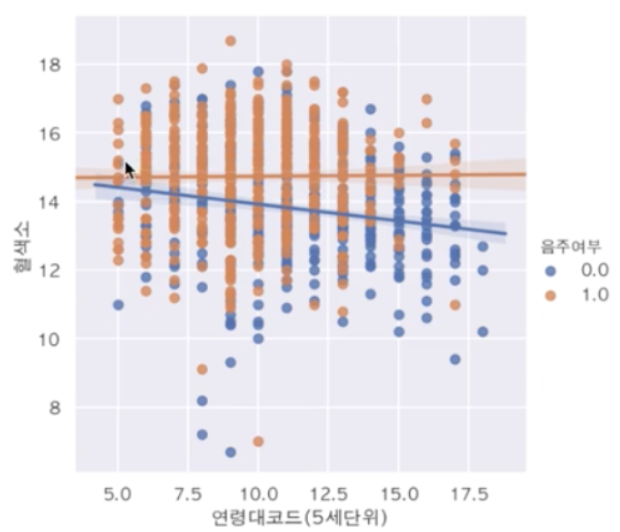
회귀선으로 상관관계를 알아볼 수 있다.
위 사진의 경우 음주하는 사람들이 혈색소가 높은 편임을 알 수 있다.
- col : 그래프 여러개로 표현하는 것도 가능하다.
sns.lmplot(data=df_sample, x="연령대코드(5세단위)", y="혈색소", hue="음주여부", col="성별코드")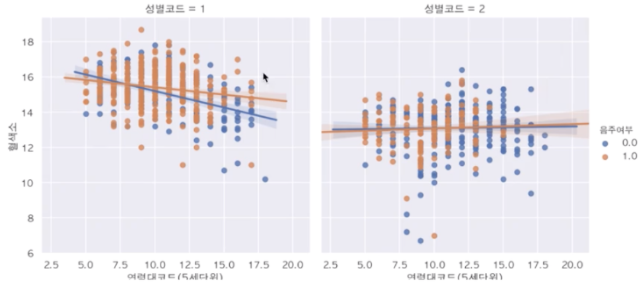
lmplot은 값들이 겹쳐서 보이는데 분포를 보고 싶다면 swarmplot을 사용하는 게 좋다.
lmplot은 회귀선을 그리거나 다변수 시각화를 할 때 좋다.
🎹scatterplot
수치형 데이터 볼 때 좋고 그래프의 이상치 파악하기 쉽다.
sns.scatterplot(data=df_sample, x="(혈청지오티)AST", y="(혈청지오티)ALT", hue="음주여부")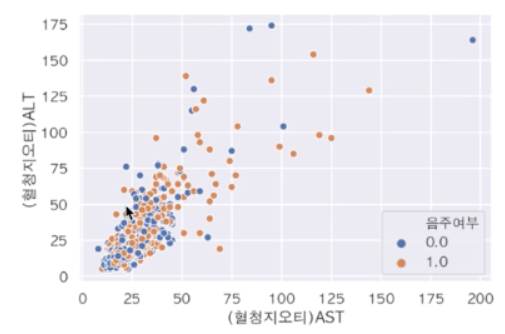
- size 옵션 : 점들의 크기 지정 가능
sns.scatterplot(data=df_sample, x="(혈청지오티)AST", y="(혈청지오티)ALT", hue="음주여부", size="체중(5Kg 단위)")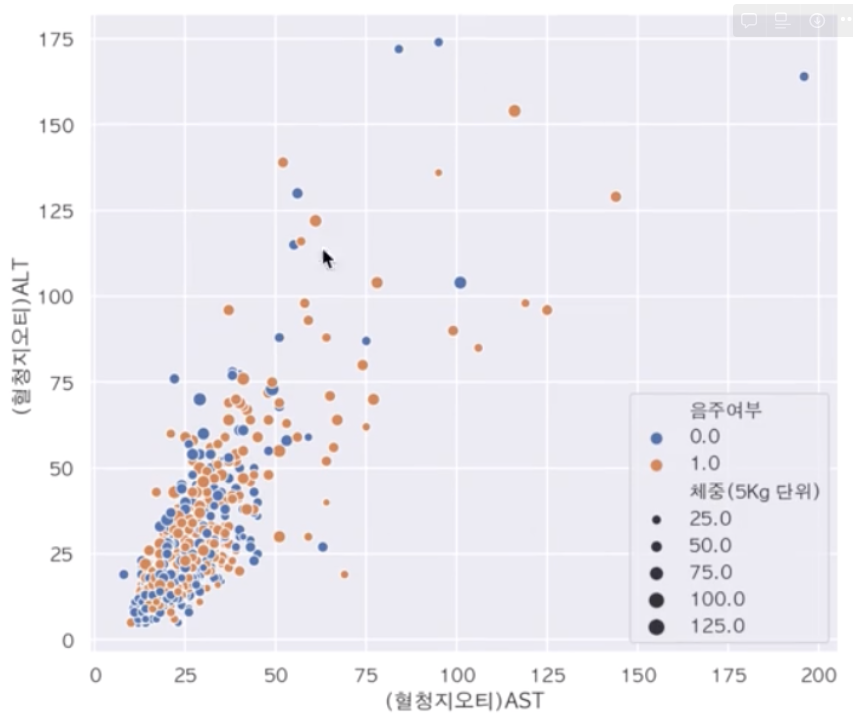
📊distplot
series 데이터를 넣으면 히스토그램을 그려준다.
결측치가 있으면 그릴 수 없다.
# df_choi 변수에 결측치가 아닌 총콜레스테롤 값을 넣는다.
df_chol = df.loc[df["총콜레스테롤"].notnull(), "총콜레스테롤"]
sns.distplot(df_chol)
#bin으로 데이터를 몇 개로 나눠 담을 것인지를 설정
sns.distplot(df_chol, bins=10)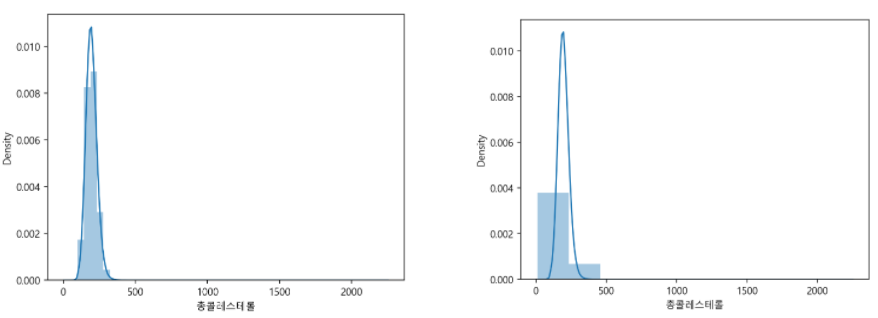
- 예시들
#음주를 하는 사람들의 총콜레스테롤 데이터
df[df["총콜레스테롤"].notnull() & (df["음주여부"] == 1)]
#음주여부가 1인 값을 총콜레스테롤 분포
sns.distplot(df.loc[(df["총콜레스테롤"].notnull()) & (df["음주여부"] == 1), "총콜레스테롤"])
#hist = False : 선만 나온다.
sns.distplot(df.loc[(df["총콜레스테롤"].notnull()) & (df["음주여부"] == 1), "총콜레스테롤"], hist=False)💡kdeplot, plt.axvline()
- kedplot : 확률밀도함수만 그리기
- plt.axvline() : 그래프에 평균값, 중앙값 선으로 표시 가능
plt.axvline(df_sample["총콜레스테롤"].mean(), linestyle=":")
plt.axvline(df_sample["총콜레스테롤"].median(), linestyle="--")
sns.kdeplot(df_sample.loc[(df_sample["총콜레스테롤"].notnull()) & (df["음주여부"] == 1), "총콜레스테롤"], label="음주 중")
sns.kdeplot(df_sample.loc[(df_sample["총콜레스테롤"].notnull()) & (df["음주여부"] == 0), "총콜레스테롤"], label="음주 안 함")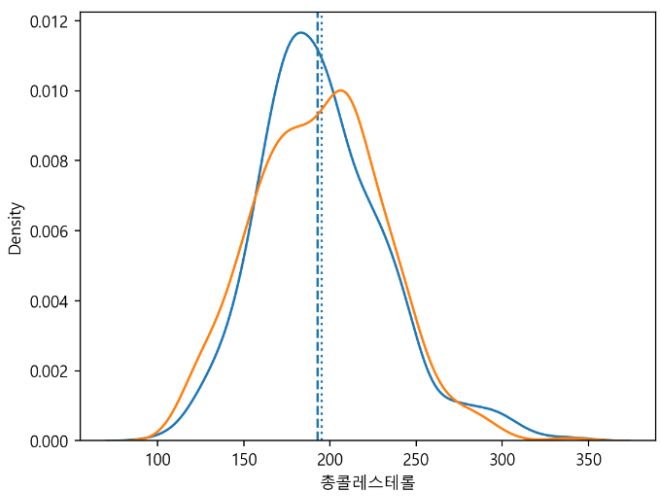
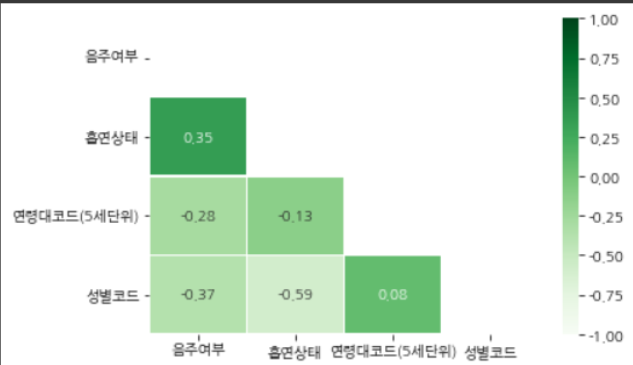
📐상관계수
- 1부터 1사이로 구성되고, 0.3부터 0.7 사이면 뚜렷한 양적 선형관계, 0.7 이상이면 강한 양적 상관관계라고 한다.
# 문제풀이에 필요한 음주여부, 흡연상태, 연령대코드(5세단위), 성별코드열만 추출
df_sub = df[['음주여부','흡연상태','연령대코드(5세단위)','성별코드']]
# 상관관계 계산 후 df_corr에 저장
df_corr = df_sub.corr()
# np.ones_like(df_corr, dtype = np.bool) : df_corr 형태(4X4)만큼 True로 채워줌
# 이를 np.triu 함수를이용하여 상삼각행렬 --> 하삼각은 False로 채움
mask = np.triu(np.ones_like(df_corr, dtype=np.bool))
sns.heatmap(df_corr,
cmap = 'Greens',
annot = True, # 실제 값을 표시
mask=mask, # 표시하지 않을 마스크 부분을 지정
linewidths=.5, # 경계면 실선으로 구분하기
vmin = -1,vmax = 1 # 컬러바 범위 -1 ~ 1
)
plt.show()