부스트코스 : '파이썬으로 시작하는 데이터 사이언스' 코칭스터디 8기 4주차

4주의 여정 끝에 부스트코스가 끝났다!!🎉🎉🎉🎉🎉🎉
4주가 긴 시간일 줄 알았는데 진짜 눈 깜빡하니 끝나버렸다ㅋㅋ
어쨌든 무사히 수료까지 했으니 마지막으로 정리하면서 잘 마무리해야겠다 :D
4주차 공부 내용
- 데이터 전처리
- 데이터 시각화
- heatmap 표현
📚데이터 전처리
📌melt 함수
열에 있는 데이터를 행으로 옮길 때 사용
- id_vars로 id 값으로 사용할 열을 지정, value_vars에 value로 들어갈 값 지정
- id_vars에 들어가지 않은 열들은 value_vars에 들어간다.
df = df_raw.melt(id_vars=["국가(대륙)별", "상품군별", "판매유형별"], var_name="기간", value_name="백만원")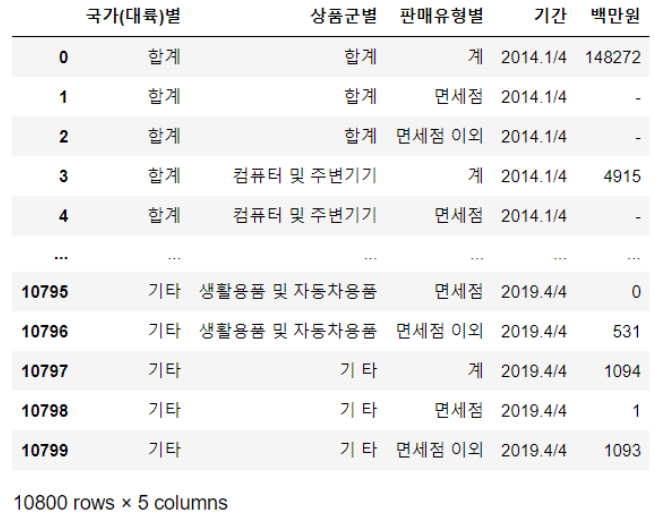
✂문자열 분리
- 기간에서 연도 분리
“.”을 기준으로 split 한 첫 인덱스를 int 형으로 변환 후 가져오면 된다.
df["연도"] = df["기간"].map(lambda x : int(x.split(".")[0]))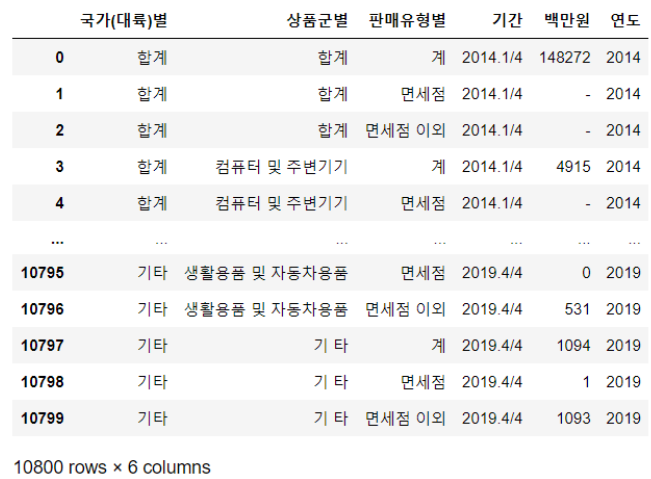
- 기간에서 분기 분리
“.”과 “/” 기준으로 split 후 첫 인덱스
df["분기"] = df["기간"].map(lambda x : int(x.split(".")[1].split("/")[0]))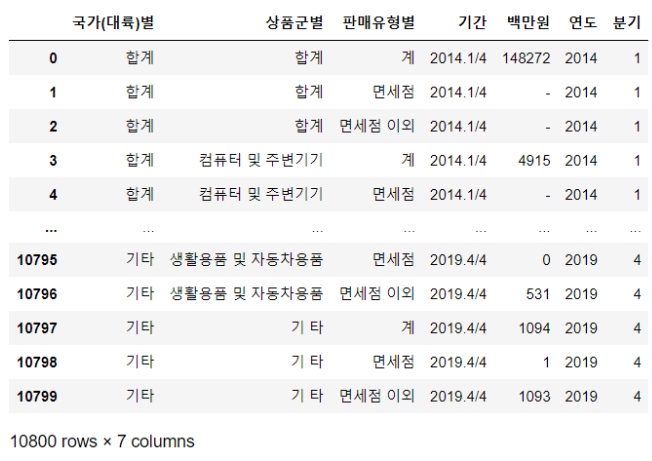
🔋데이터 타입 변경
- astype
빈 값을 NaN값으로 바꾸고 astype이용해 float으로 데이터 타입 변경
df["백만원"] = df["백만원"].replace("-", np.NaN).astype(float)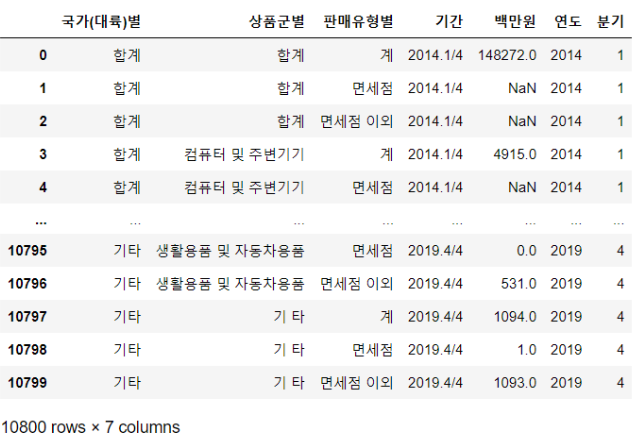
📊데이터 시각화
🎨기본 예제
- 결측치 있는 행 제거 후 상품군별로 나눠서 시각화하기
df_total = df[df["판매유형별"] == "계"].copy()
sns.lineplot(data=df_total, x="연도", y="백만원", hue="상품군별")
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)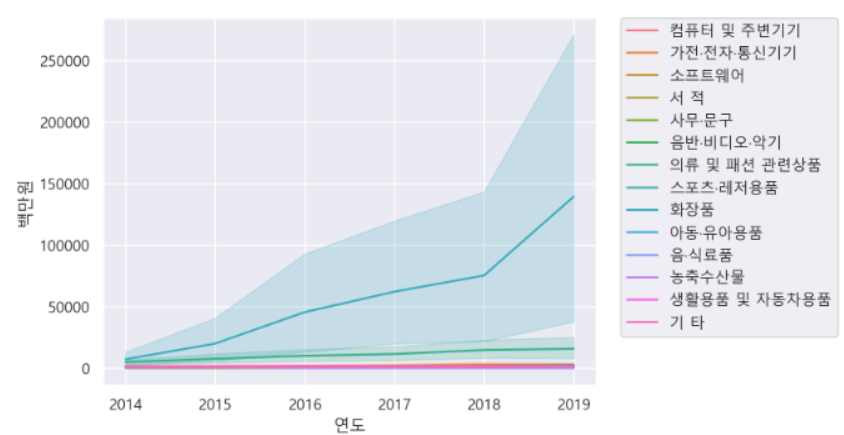
🧵replot
위 사진처럼 아래에 겹친 데이터들은 제대로 확인하기 힘들 때 사용한다.
sns.relplot(data=df_total, x="연도", y="백만원", hue="상품군별", kind="line", col="상품군별", col_wrap=4)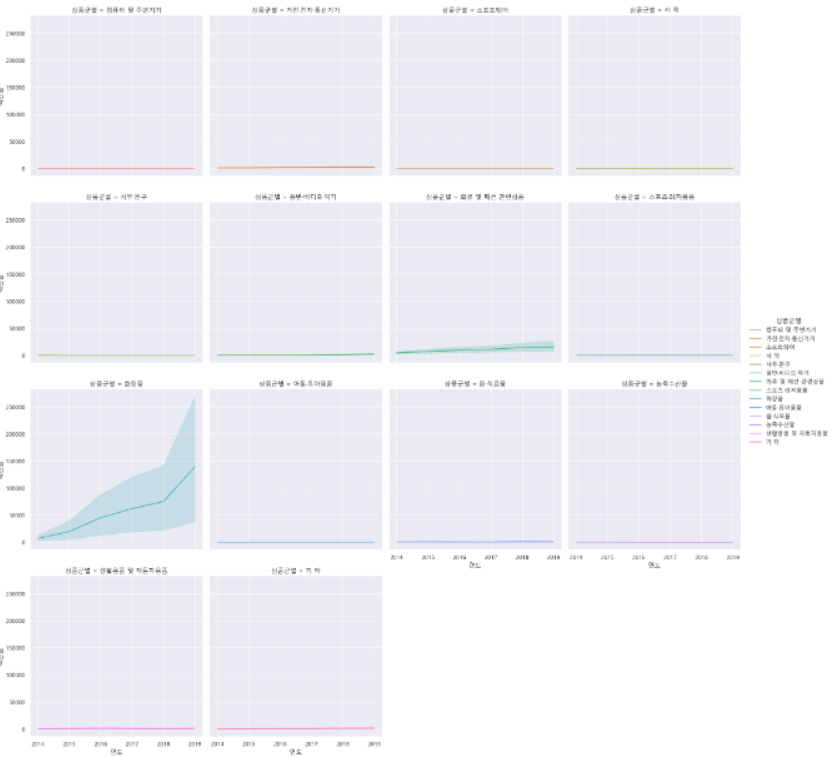
📣heatmap
- annot : 그래프에 수치 표시
- fmt : 소수점 없이 float 형 숫자 표기
result = df_fashion.pivot_table(index="국가(대륙)별", columns="연도", values="백만원", aggfunc="sum")
plt.figure(figsize=(10, 6))
sns.heatmap(result, cmap="Blues_r", annot=True, fmt=".0f")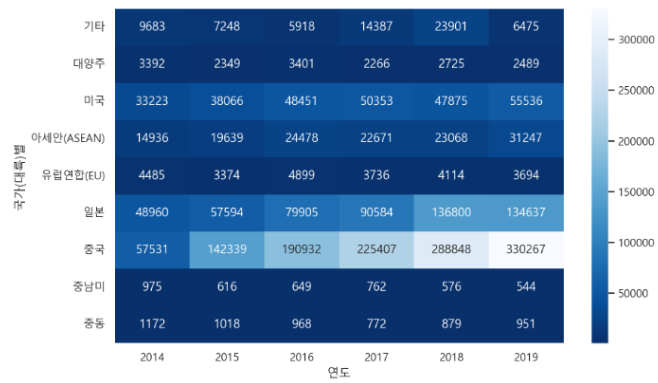
중국에서 구매액이 가장 많고 미국, 일본에서 구매액이 증가하고 있다는 사실을 알 수 있다!!
이렇게 해서 드디어 정리까지 모두 끝났다..!!!!
4주차에서도 되게 많은 시각화 실습을 했는데 겹치는 내용이 많아서 적당히 몇개만 뽑아서 정리했다ヾ(^▽^*)))
우리 2조 팀원들만이 아니라 다른 동아리 분들에게도 도움이 될 수 있길 바란다 :D
