개요
- 서버 성능을 향상시킬 때 중요한 지표는 처리량과 응답시간이다
- 응답시간이 짧을수록 처리량이 높아질수록 성능이 좋아진다
- DB와 연결하기 위해서 TCP/IP 연결을 해야하는데 이걸 매번 연결하고 끊으면 굉장히 비효율적이 될 것이다
- TCP/IP 연결을 하고 ID, PW와 기타 부가정보를 DB에 전달하고 인증을 완료되면 DB 세션을 생성해 응답을 받는다
- 커넥션 생성/삭제 과정이 추가된다면
SQL 처리시간 + 커넥션 생성 시간이 추가되기 때문에 응답 속도에 영향을 준다
- 미리 데이터베이스와 연결시킨 상태를 유지하는 커넥션을 만들고 이를 관리하는 것을
Connection Pool이라고 한다
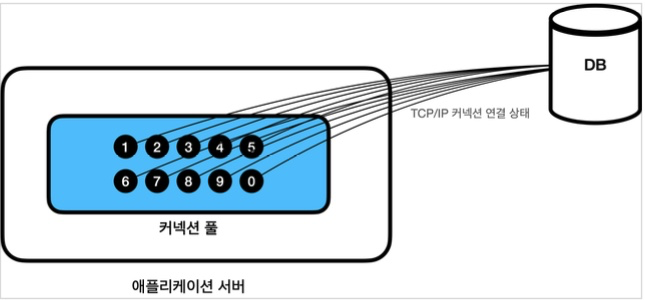
커넥션풀 크기
- 커넥션풀의 크기가 커지면 활성 커넥션도 많아질테니 CPU 리소스 사용량이 많아진다
- 각 커넥션은 메모리를 점유하기 때문에 메모리부족으로 인해 데이터베이스 과부하 상태에 이를 수 있다. 메모리 누수 또는 OutofMemory같은 심각한 문제가 발생할 수 잇다
- 모든 커넥션이 활성화되면 데이터베이스도 많은 요청을 처리해야해서 성능저하나 접속 실패가 발생할 수 있다
- 참고: https://bugoverdose.github.io/docs/database-connection-pool-sizing/
Spring Connection Pool
- Spring에서는 DataSource 인터페이스를 이용해서 추상화된 커넥션풀을 이용한다
- SpringBoot 2.0 이전에는 Tomcat-Jdbc를 사용했었고 현재는
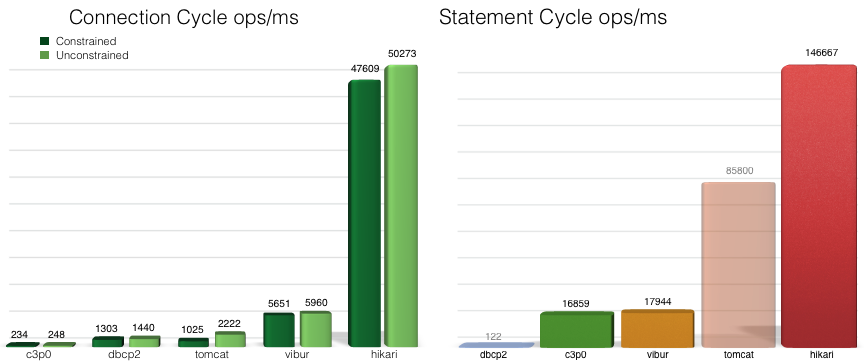
HikariCP를 사용한다 - Hikari CP 성능표 2016년에 측정한 거라 현재는 참고용으로 쓰자
동작원리
- Connection객체를 래핑한 PoolEntry로 Connection을 관리하고 이를 관리하는 ConcurrentBag이라는 구조체가 있다
HikariPool.getConnection() -> ConcurrentBag.borrow()을 통해 유휴 상태의 Connection을 반환한다- ConcurrentBag이 커넥션을 반환할 때 스레드의 정보를 확인하고 이전에 반환해준 스레드를 우선적으로 반환해주고 만약 해당 스레드가 일하고 있다면 유휴 스레드를 찾아서 반환해준다
- 커넥션 생성을 요청한 스레드의 정보를 저장해두고 다음에 접근 시 저장된 정보를 이용해 빠르게 반환해준다
- 트랜잭션이 종료(커밋, 롤백)이 되면
connection.close()가 호출되어 Pool에 반납한다
connection.close() -> concurrentBag.requite()이 실행되며 커넥션이 반납된다
설정
- Hikari 기본 설정은
HikariConfig을 통해 확인할 수 있다 - 기본 커넥션풀의 커넥션 개수는 10개이다
- 쓰레드풀과 다르게 커넥션의 풀은 초기 크기가 10이라면 시작할 때 즉시 10개의 커넥션을 생성한다
spring:
datasource:
url: 주소주소
username: root
password: Password
hikari:
maximum-pool-size: 100 #최대 pool 크기
minimum-idle: 10 #최소 pool 크기
idle-timeout: 600000 #연결위한 최대 유후 시간
max-lifetime: 1800000 #반납된 커넥션의 최대 수명참고) https://github.com/brettwooldridge/HikariCP/wiki/Down-the-Rabbit-Hole
https://techblog.woowahan.com/2664/
