서론
이번에 SimpleTodoList에 Redis를 적용하면서 처음으로 NoSQL을 사용해볼 수 있었다. 그동안 들어본 이야기로는 NoSQL이 SQL, 즉 RDB에 비해서 월등히 빠르다는 장점이 있다는데 이를 직접 입증하기란 쉽지 않았다(데이터 셋, 환경, 메트릭 등).
그래서 관련 자료를 찾아보다가 로체스터 대학교에서 학생들이 과제로 작성한 논문을 읽어보게 됐는데 짧은 내용이라 이해하기도 번역하기도 쉬워서 이곳에 적어본다.
본론
SQL, NoSQL
SQL은 관계형 데이터베이스, 즉 MySQL이나 MSSQL 같은 관계형 테이블 모델을 사용하는 데이터베이스에서 데이터를 조회하거나 변경하기 위해 사용하는 언어다. 그에 반해서 NoSQL은 Not only SQL이라는 이름답게 비 관계형 데이터베이스 시스템에서 사용할 수 있는 데이터베이스 제품군을 지칭한다.
최근 빅 데이터의 활용과 더불어 MongoDB, Cassandra 등 다양한 NoSQL 제품이 SQL보다 더 많은 인기를 얻고 있는데 NoSQL은 SQL에 비해 ACID 원칙을 조금 타협하더라도 더 빠른 속도를 얻는데 중점을 둔다.
ACID
ACID 원칙은 RDB를 공부한다면 자주 듣게 되는 4개의 원칙이다.
- Atomic: 트랜잭션에 포함된 쿼리는 나뉘지 않고(원자성) 한 번에 다 실행되거나 전부 다 실행되지 않은 상태여야 한다.
- Consistency: 데이터베이스는 트랜잭션이 완료된 후에도 유효한(valid) 상태를 유지하고 있어야 한다.
- Isolation: 트랜잭션은 설사 동시에 여러 트랜잭션이 실행되고 있더라도 마치 고립된 환경인 것처럼 동작해야 한다.
- Durability: 커밋된 트랜잭션에 의해 데이터베이스에 쓰인 데이터는 영구히 유지(persist)되어야 한다.
즉 데이터베이스라면 기본적으로 보장해야 할 4가지 속성이다.
CAP Theorem
CAP 정리는 분산 데이터베이스 환경에서 Consistency, Availability, Partition tolerance 이 세 가지를 모두 지킬 수는 없다는 것이다.
- Consistency: 모든 읽기 요청은 가장 최근의 데이터를 받는다.
- Availability: 모든 읽기 요청은 항상 정상적인(non-error) 응답을 받는다.
- Partition tolerance: 시스템은 몇몇 데이터베이스 노드가 동작하지 않더라도 정상적으로 동작해야 한다.
모든 읽기 요청이 가장 최근의 데이터를 받는다는 것은 분산 데이터베이스 환경에서 클라이언트가 어떤 환경에 접근하던지 간에 일관성(Consistency)있는 같은 데이터를 조회할 수 있어야 한다는 것이다.
가용성(Availability)은 분산된 데이터베이스 노드 중 몇 개에 장애가 발생하더라도 클라이언트가 문제없이 요청에 대한 응답을 받을 수 있어야 한다는 것이다. 이 경우 일관성과는 달리 응답을 받을 수 있는 것 자체에 좀 더 무게가 있다.
파티션 감내(Partition tolerance)는 분산된 두 노드 사이에 네트워크 장애가 발생했을 때, 즉 모두 동일한 상태가 아니라 두 개의 파티션(서로 다른 상태)으로 나뉘었을 때도 시스템은 정상적으로 동작해야 한다는 것을 의미한다.
그래서 분산된 환경이라면 모두 같은 데이터를 읽을 수 있고 언제나 문제 없이 응답하거나(CA), 모두 같은 데이터를 읽을 수 있고 네트워크 장애 시에도 정상적으로 동작하거나(CP), 항상 문제 없이 응답하고 네트워크 장애 시에도 정상적으로 동작하는 환경(AP) 셋 중 하나만 보장할 수 있다는 것이다.
그러나 네트워크 장애는 분산 시스템을 얼마나 잘 구성하더라도 여러가지 이유(단선, 트래픽 폭주 등)로 피할 수 없는, 비유하자면 Java의 checked exception 같은 존재기 때문에 CA 시스템은 존재할 수 없다고 한다.
그래서 결국 일관성과 가용성 중 하나를 고르게 되는데 일관성을 고르게 된다면 네트워크 에러가 발생했을 때 애플리케이션은 에러를 반환하게 된다. 이 경우 클라이언트는 원하는 응답을 얻지 못하기 때문에 가용성을 보장받지 못한다.
반대로 가용성을 고른다면 애플리케이션은 클라이언트의 요청에 항상 응답할 것이다. 그러나 네트워크 에러가 발생했을 때는 그 응답 데이터가 최신 데이터인지, 즉 다른 데이터베이스 노드와 일관된 상태인지 보장할 수 없기 때문에 클라이언트는 일관성을 보장받지 못한다.
NoSQL이란?
RDB는 테이블과 스키마로 이루어진 정형화된 타입이라면 NoSQL은 특별히 규정된 형태가 없으며 다음처럼 여러가지 형태로 존재할 수 있다.
- Key-value: key로 탐색하며 value에 비정형화된 데이터를 저장. 사전, 맵 자료형과 비슷. 대표적으로 Redis, BerkeleyDB 등. 데이터베이스는 value에 어떤 데이터가 어떤 타입으로 저장되어 있는지 모른다(opaque).
- Document: 비교적 간단한(semi-structured) 포맷으로 데이터를 캡슐화하여 저장. 대표적으로 JSON 형태를 사용하는 MongoDB 등. RDB 처럼 정형화된 타입이 있는게 아니라 JSON이나 XML 같은 문서 포맷으로 데이터가 정의되어 있으면 메타데이터 등을 추출해서 확인할 수 있음.
- Column: RDB와 유사하게 데이터를 컬럼별로 정의하여 저장. 그러나 같은 테이블 내에서도 row에 따라 컬럼 형태가 다를 수 있다. RDB와 차이점은 데이터를 row 단위가 아닌 column 단위로 취급하기 때문에 특정 컬럼을 기준으로 집계하거나 각종 통계를 내는 연산에 적합하다.
- Graph: 그래프 자료구조처럼 데이터를 노드에 저장하고 엣지로 잇는 방식으로 저장. 기존의 RDB에서 데이터간 연관관계를 파악하려면 JOIN 등 많은 연산이 필요하던 것과 달리 노드 간 연결 자체를 직접 다룬다. 그렇기 때문에 데이터 요소 간 관계 파악에 적합하다.
네 가지 형태 모두 RDB 처럼 정형화된 데이터 구조를 요구하지 않기 때문에 스키마 구조를 그리느라 지체될 필요 없이 빠른 개발이 가능하다. 그리고 테이블 간 JOIN이 필요없기 때문에 분산 데이터베이스 환경에서도 수평적 확장에 용이하다. 관계형 데이터베이스라면 분산 환경에서 연관 데이터가 어느 노드에 있을지 신경써야 하기 때문이다.
특히 Key-value 타입의 경우 데이터 조회 시간이 압도적으로 빠른데 이를 논문에서는 다음 실험 결과로 보이고 있다.
성능 비교 및 결론
실험 환경은 다음과 같다.
- OS: Microsoft Windows 10 Pro 64 bit
- CPU: Intel (R) Core (TM) i5-3210M CPU @ 2.50GHz
- RAM: DDR3 8GB 1333MHz
- Storage: SAMSUNG MZ7PC128HAFU-000H1
- Database Settings: InsertsPerQuery: 5000; Indexing Technology: BTree;
- Test Data: 1,000,000 Records, 100% randomness
가장 많이 사용하는 관계형 데이터베이스인 MySQL과 Key-value NoSQL인 BerkeleyDB, Document NoSQL인 MongoDB에 대하여 실험을 진행한 것을 볼 수 있다.
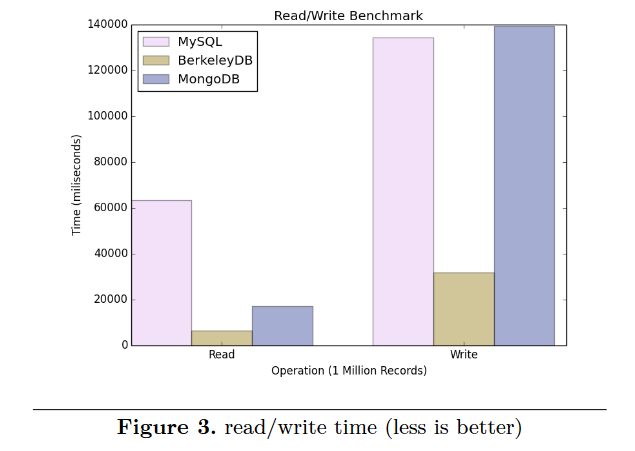
위의 막대 차트에서 볼 수 있듯이 읽기 연산에는 NoSQL이 전반적으로 3배 이상 빠른것을 볼 수 있었다. 쓰기 연산은 Key-value 타입인 BerkeleyDB가 가장 빠르고 MySQL과 MongoDB가 비슷한 속도인 것을 볼 수 있었다.
아무래도 Key-value 타입은 GET, SET 명령으로 단순히 읽고 쓰기기 때문에 속도가 낮을 수밖에 없는 것 같다.
이러한 결과로 볼 때 NoSQL은 전반적으로 RDB보다 빠른 처리 속도를 지원하는 것을 알 수 있다. 그러나 이러한 결과만으로 둘 중 어떤 데이터베이스 타입이 절대적으로 좋다고 말할 수는 없다. ACID 원칙으로 엄격하게 데이터의 형태를 유지하고 일관성을 보장하는 관계형 데이터베이스나 느슨하지만 높은 성능을 보장하는 NoSQL 데이터베이스를 비즈니스 로직에 따라 적절히 분배하여 사용하는 편이 좋을 것이다.
결론
Redis를 처음 프로젝트에 적용했을 때 제일 헷갈렸던 점이 왜 JPA에서 잘 되던 Dirty-checking이 동작하지 않느냐는 것이었다. 뭐 당연하지만 Redis 같은 NoSQL은 ORM 기술인 JPA랑 관련이 없기 때문에 엔티티 매니저가 없으니 당연한 것이었다. 거기다가 위의 CAP 정리에서 보듯이 ACID 원칙을 보장하기 않기 때문에 트랜잭션 역시 활용하지 않는다. 그래서 직접 data repository 구현체의 save 메서드로 저장해줘야 변경사항이 반영되던 기억이 난다.
NoSQL이 빠르다곤 하지만 SQL보다 얼마나 빠른지 알 수가 없었는데 이렇게 비교해보니 단순 읽기 연산에서도 굉장한 차이가 나는 것을 볼 수 있었다. 확실히 자주 접근하는 캐시 데이터같은 부분은 NoSQL에 저장하는 편이 맞는 것 같다.
참고
CAP Theorem
Document-oriented database
Why NoSQL is better at "scaling out" than RDBMS?


잘보고 갑니다 :)