서론
이전에 JPA를 학습하면서 Spring Data JPA에서 생성한 쿼리 메서드를 활용한 적이 있었다. 그 때 정의한 엔티티 중 'name'이라는 필드를 가진 엔티티가 있었는데 해당 엔티티를 'name' 필드를 이용하여 삭제하기 위해 deleteByName 이라는 메서드를 repository에 작성하고 테스트했다.
@Test
void userDeleteTest() {
User user = User.builder()
.name("name123")
.age(25)
.hobby("hob")
.createdAt(LocalDateTime.now())
.updatedAt(LocalDateTime.now()).build();
entityManager.persist(user);
entityManager.flush();
entityManager.clear();
userRepository.deleteByName("name123");
assertTrue(userRepository.findByName("name").isEmpty());
}그리고 해당 메서드를 호출하면 쿼리가 DELETE FROM ... WHERE name=? 처럼 나가리라 생각했는데 실제로는 SELECT 쿼리로 해당 엔티티를 얻어온 후 DELETE FROM ... WHERE id=? 처럼 기본키를 기반으로 삭제하는 복수의 쿼리가 전송됐다.
Hibernate: select user0_.user_id ... from user user0_ where user0_.user_name=?
Hibernate: select posts0_.user_id ... from post posts0_ where posts0_.user_id=?
Hibernate: delete from user where user_id=?
중간에 alias, WHERE clause 등은 삭제하고 보면 위처럼 name을 기준으로 SELECT 한 후 연관관계(Post 라는 객체를 일대다 관계로 참조하고 있다)의 객체을 불러오고 그리고 name이 아닌 User 엔티티의 식별자로 DELETE 쿼리를 실행하는 것을 볼 수 있었다. 그래서 왜 이런지 알아보는 과정을 적어보고자 한다.
본론
추측
일단 리포지토리 인터페이스 메서드가 어떤 식으로 실제 메서드로 구현되는지 잘 몰랐기 때문에 스프링 공식 문서를 살펴보았다. Query Creation 문단을 참고하면 Spring Data JPA에서는 Criteria API를 사용하여 클라이언트가 정의한 메서드를 실제 구현체로 변환하고 있다고 한다.
어쨌든 인터페이스로 정의되었으면 누군가는(정확히는 Spring Data JPA가) 이를 구현체 클래스로 만들어야 하는데 어떤 클래스가 생성되어 Bean 객체로 사용되고 있는지 디버거를 통해 확인해보았다.

그 결과 SimpleJpaRepository라는 구현체를 주입받아 사용하고 있는 것을 볼 수 있었는데 그러면 이 클래스의 delete 메서드를 확인해보면 실마리를 잡을 수 있겠다고 생각했다.
공식 문서에서는 다양한 리포지토리 인터페이스(CrudRepository, JpaRepository 등)를 구현한 클래스로 소개하고 있었다. 즉 우리가 어떤 인터페이스를 상속받아서 정의하든 구현체로는 이 클래스를 사용하게 된다는 것이다. 각종 CRUD 옵션들과 페이징 등이 구현되어 있는데 지금 살펴보려는 delete 메서드는 이 곳에서 찾아볼 수 있었다.
public void delete(T entity) {
...
Class<?> type = ProxyUtils.getUserClass(entity);
T existing = (T) em.find(type, entityInformation.getId(entity));
// if the entity to be deleted doesn't exist, delete is a NOOP
if (existing == null) {
return;
}
em.remove(em.contains(entity) ? entity : em.merge(entity));
}소스 코드를 살펴보니 ProxyUtils 클래스의 getUserClass 메서드를 활용하여 엔티티의 클래스를 얻고 엔티티 매니저(em 변수로 주입받는다)의 find 메서드를 호출하여 엔티티를 찾는, 즉 SELECT 쿼리를 보내는 것을 확인할 수 있었다.
그리고 엔티티가 존재하지 않는다면 별다른 에러를 발생시키지 않고(NOOP) 종료하고 존재한다면 엔티티가 영속성 컨텍스트에 있는 경우 삭제, 존재하지 않는다면 merge 메서드를 이용하여 영속화시키고 삭제하는 것을 볼 수 있다.
@Transactional
@Override
void deleteById(ID id) {
Assert.notNull(id, ID_MUST_NOT_BE_NULL);
delete(findById(id).orElseThrow(() ->
new EmptyResultDataAccessException(
String.format("No %s entity with id %s exists!",
entityInformation.getJavaType(), id), 1)));
}다른 삭제 메서드인 deleteById 역시 먼저 findById 메서드를 호출해서 삭제하려고 하는 엔티티를 찾고 내부적으로 delete 메서드를 호출하는 모습이었다.
이 코드들로 미루어 볼 때 name 필드를 활용해서 정의했던 쿼리 메서드도 내부 구현으로는 name 필드를 이용하여 엔티티를 얻어와서 delete 메서드에 해당 엔티티를 전달하여 삭제할 것이라고 추측해볼 수 있었다.
추가 탐색
하지만 단순히 추측에 지나지 않았기 때문에 테스트 코드에서 deleteByName 메서드를 호출하는 부분에 중단점을 걸고 디버깅을 통해 좀 더 자세히 확인해보았다.
else {
// We need to create a method invocation...
MethodInvocation invocation =
new ReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
// Proceed to the joinpoint through the interceptor chain.
retVal = invocation.proceed();
}우선 리포지토리 인터페이스 구현체에 대한 프록시(AOP)를 적용했기 때문에 JdkDynamicAopProxy.java 라는 파일로 들어오게 됐다. 거기서 프록시 대상 객체, 클래스 타입, interception chain 등 다양한 AOP 관련 정보들을 수집하여 위처럼 MethodInvocation 이라는 인터페이스의 구현체를 생성하고 proceed 메서드를 활용하여 실행하는 것을 볼 수 있다.
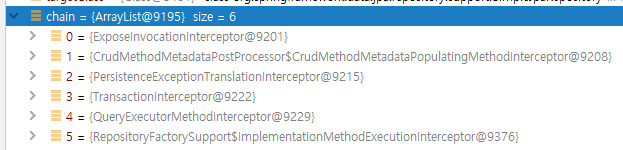
Interception chain에는 ExposeInvocationInterceptor, CrudMethodMetadataPopulatingMethodInterceptor,
PersistenceExceptionTranslationInterceptor, TransactionInterceptor, QueryExecutorMethodInterceptor, ImplementationMethodExecutionInterceptor 등이 등록되어 있다. 간략히 살펴보면 리포지토리에서 발생한 예외를 DataAccessException 같은 스프링 전용 공통 예외로 변환하는 인터셉터나 메서드 호출 관련 메타데이터, 트랜잭션 관리 등의 기능을 수행하는 인터셉터들을 볼 수 있다.
처음에 목록만 보고 관심을 갖고 살펴본 것은 맨 마지막의 ImplementationMethodExecutionInterceptor 였다. 이 인터셉터는 RepositoryComposition의 메서드를 호출하는 메서드 인터셉터인데 RepositoryComposition 은 RepositoryFragment로 이루어져 있다고 한다. 이 RepositoryFragment 는 리포지토리 메서드의 시그니처를 나타내는 Value Object 로 구현되어 있지 않은 Structural 타입, 실제로 구현된 Implemented 타입으로 구분된다고 한다.
그래서 만약 이 RepositoryFragment 에 리포지토리 인터페이스에 정의한 deleteByName 메서드가 있다면 세부 동작을 살펴볼 수 있으리라 생각하여 위의 인터셉터 체인을 쭉 따라가 보았다. 그런데 실제로 메서드가 호출되는 부분, 정확히는 deleteByName 이란 쿼리 메서드로 동작하는 코드가 실행되는 부분은 마지막 전인 QueryExecutorMethodInterceptor 였다.

위의 호출 스택에서 볼 수 있듯이 QueryExecutorMethodInterceptor 를 따라가던 도중 RepositoryMethodInvoker 라는 클래스를 만나게 됐는데 JavaDoc으로 제공되는 문서는 찾지 못했지만 소스 코드에서 클래스의 설명을 읽어보면 다음처럼 쿼리 메서드를 실행하는 Invoker 인 것을 알 수 있었다.
Invoker for repository methods. Used to invoke query methods and fragment methods.
QueryExecutorMethodInterceptor 에서 해당 클래스의 invoke 메서드를 호출하면 내부적으로 분기(reactive 쪽인 것 같다)를 거쳐 doInvoke 메서드를 호출, 내부 정적 클래스인 RepositoryQueryMethodInvoker 를 역시 내부 인터페이스인 Invokable 타입으로 invoke 하여 람다 표현식으로 실행하는 것을 확인할 수 있었다.
@Nullable
@Override
public Object execute(Object[] parameters) {
return doExecute(getExecution(), parameters);
}이를 추적하면 위와 같은 execute 메서드를 가진 AbstractJpaQuery 추상 클래스, 정확히는 이를 상속받은 구현체 PartTreeJpaQuery 클래스에 도달하게 된다. 여기서 파라미터로 getExecution 메서드의 결괏값을 전달하는데 이 메서드는 아래처럼 동작한다.
@Override
protected JpaQueryExecution getExecution() {
if (this.tree.isDelete()) {
return new DeleteExecution(em);
} else if (this.tree.isExistsProjection()) {
return new ExistsExecution();
}
return super.getExecution();
}문서를 참고하면 PartTreeJpaQuery 는 PartTree 를 기반으로 동작하는 AbstractJpaQuery 라고 한다. PartTree 는 문자열을 Part 클래스로 이루어진 트리 자료구조로 나타내는 클래스라고 한다. Part 클래스 자체는 메서드 이름에서 쿼리로 변환될 수 있는 단어를 지칭하는 클래스로 즉 리포지토리 인터페이스에서 정의한 메서드 이름이 이 Part 로 이루어진 PartTree 로 변환되어 실제 쿼리로 인식되는 것이라 생각할 수 있었다.
그래서 현재 PartTree 의 타입에 따라 위처럼 분기가 갈리는 것을 볼 수 있는데 deleteByName 메서드를 실행하는 만큼 현재 타입은 아래처럼 delete 플래그가 세워진 것을 볼 수 있다.
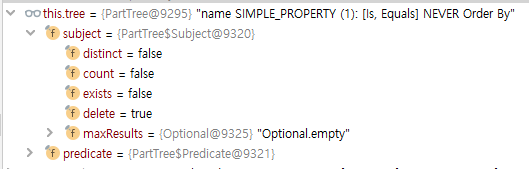
그래서 첫 번째 분기를 타서 DeleteExecution 객체를 반환하게 되고 다시 AbstractJpaQuery 의 execute 메서드로 돌아가면 doExecute 메서드에 이 DeleteExecution 객체와 파라미터(코드에서는 "name123")를 전달해서 DeleteExecution 객체의 execute 메서드를 호출하는 것을 볼 수 있다.
그러면 이 DeleteExecution 의 execute 메서드에서는 다시 doExecute 메서드를 호출하는데 그 코드를 보자.
@Override
protected Object doExecute(AbstractJpaQuery jpaQuery, JpaParametersParameterAccessor accessor) {
Query query = jpaQuery.createQuery(accessor);
List<?> resultList = query.getResultList();
for (Object o : resultList) {
em.remove(o);
}
return jpaQuery.getQueryMethod().isCollectionQuery() ? resultList : resultList.size();
}먼저 jpaQuery 파라미터의 createQuery 메서드를 이용하여 JPQL 쿼리를 생성, Query 클래스를 이용하여 다루는 것을 볼 수 있다. 그 다음 라인에서는 getResultList 메서드를 호출하여 결괏값을 가져오는데 메서드의 정의를 참고하면 다음과 같다.
Execute a SELECT query and return the query results as an untyped List.
이 메서드는 SELECT 쿼리를 실행해서 해당하는 엔티티를 조회하는 기능인 것을 알 수 있다. 즉 이 부분 때문에 deleteByName 메서드를 호출했지만 SELECT 쿼리가 실행된 것이다. query 변수가 어떤 JPQL을 실행하는지 디버거로 살펴보면 다음처럼 SELECT 쿼리에 name 필드를 활용해서 조회하는 것을 볼 수 있다.

즉, name으로 delete 하기 위해 먼저 select를 해서 삭제될 엔티티들을 불러오고 조회된 엔티티들을 엔티티 매니저의 remove 메서드로 실제로 삭제한다는 것을 알 수 있다. 이로써 첫 번째 의문이었던 출처를 알 수 없는 SELECT 쿼리는 해결할 수 있었다.
그러면 연관관계의 Post 객체들을 조회하던 두 번째 SELECT 쿼리는 어떻게 된 것일까? 이는 엔티티 매니저의 remove 메서드가 내부적으로 연관관계 속성(cascade, orphanRemoval)을 반영하여 삭제한 것이라고 추측할 수 있었다. 언급했듯이 User 클래스는 다음처럼 Post 리스트를 연관관계로 갖고 있다.
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private final List<Post> posts = new ArrayList<>();여기서 orphanRemoval 속성이 true로 설정되어 있기 때문에 User 엔티티가 삭제된 이상 고아 객체가 되버린 해당 User의 Post 들 역시 삭제되어야 하기 때문에 역시 SELECT 후 DELETE 한다고 볼 수 있다. 위의 테스트 코드에서는 별도의 Post를 등록하지 않았는데 조금 수정해서 한 개의 Post를 등록하고 삭제해보면 어떻게 될까?
Hibernate: select user0_.user_id ... from user user0_ where user0_.user_name=?
Hibernate: select posts0_.user_id ... from post posts0_ where posts0_.user_id=?
Hibernate: delete from post where post_id=?
Hibernate: delete from user where user_id=?
위처럼 User, Post 엔티티 모두 삭제되는 것을 볼 수 있었다. 그럼 orphanRemoval 속성을 해제하고 cascade 타입을 PERSIST로 설정한 후 돌려보면 어떨까? 이 경우 데이터베이스 제약 조건 문제가 발생했다.
Caused by: org.h2.jdbc.JdbcSQLIntegrityConstraintViolationException: Referential integrity constraint violation: "FK72MT33DHHS48HF9GCQRQ4FXTE: PUBLIC.POST FOREIGN KEY(USER_ID) REFERENCES PUBLIC.USER(USER_ID) (1)"
즉 Post 엔티티의 테이블에서 User 엔티티 테이블의 USER_ID 컬럼을 외래키로 참조하고 있기 때문에 삭제할 수 없다는 것이다. 그렇기 때문에 연관관계의 객체들까지 깔끔하게 제거하려면 cascade 타입을 ALL 로 해두거나 최소한 orphanRemoval 속성을 true 로 부여해야 한다.
결론
결론적으로 궁금했던 항목에 대한 답은 다음과 같다.
- 왜 DELETE를 하는데 SELECT가 나가는가?
- DeleteExecution 클래스에서 doExecute 메서드를 통해 삭제 조건에 부합하는 엔티티 목록을 SELECT 한다.
- 여러 SELECT 쿼리가 나가는 이유는 무엇인가?
- 엔티티가 삭제될 때 연관관계의 엔티티도 삭제하기 위해서다.
여러가지 인터셉터와 프록시로 싸여진 내부 로직을 찾아들어가는 과정은 길고 헷갈렸지만 좋은 경험이 됐다. 그리고 왜 DELETE를 하는데 SELECT가 나가는지에 대한 코드 레벨에서의 이해도 됐고 메서드를 직접 호출하는게 아니라 MethodInvocation 같은 클래스를 이용해서 대신 호출하는 방법을 스프링 프레임워크가 굉장히 자주 사용하고 있다는 것도 알게 됐다.
앞으로도 궁금한 점이 있으면 디버거와 오픈소스를 적극 활용하는 것도 좋은 습관이 될 것 같다.

4개의 댓글

좋은 글 잘 읽었습니다:-) 벨로그가 팔로우 기능이 있으면 좋을텐데 아쉽네요🥲 이 포스팅 즐찾해놓고 자주 와서 다른 글도 읽어볼게요! 다른 글들도 정말 잘 읽었습니다 감사해요!👍
정말 좋은 정보 감사합니다. 그런데 일대다 연관관계가 맺어진 해당 케이스에서 jpa의 딜리트메소드가 너무 비효율적이지않나요? Select없이 삭제하는 방법은 없을까요? 저는 Jpql로 시도를해봤는데 cascade가 적용이 안되서 삭제가 안되더군요.
일대다 연관관계가 여러번 걸려서 한건을 삭제하면 딸려있는 자식엔티티가30~40개인경우 대량의 select쿼리가 날라가는문제도 겪어봤구요. 이경우 Select최적화로 최소 3건의 select으로 줄이긴했는데 이런 번거로운작업없이 네이티브쿼리로 딜리트를 날리면 디비차원에서 캐스캐이드로 다 삭제해주니 지나치게 비효율적이란 생각이 들었습니다. 혹시 이런부분에서 좋은 해결책이 없을까요?