설명
LeetCode의 Longest Substring Without Repeating Characters 문제다.
주어진 문자열에서 반복되지 않는 가장 긴 문자열의 길이를 찾는 것이 목적인데 예를 들어 "abcabcbb"같은 문자열에서는 중복되지 않는 문자들로 이루어진 가장 긴 부분 문자열이 "abc"이므로 3을 반환해야 한다.
헷갈릴 수 있지만 문제에서 Substring, 즉 부분 문자열이라고 명시하고 있기 때문에 서로 떨어진 글자로 문자열을 조합할 수는 없다.
처음 LeetCode에 입문했을 때 조건이 간단하기 때문에 쉽게 생각하고 들어왔다가 어떻게 풀어야 할지 몰라서 당황했던 기억이 있는 문제다.
풀이
리스트 활용(80 ms)
중복되지 않는 가장 긴 문자열의 길이를 반환하려면 어쨌든 중복되지 않는 가장 긴 문자열을 구축해야 하기 때문에 문자열의 모든 문자를 탐색해야 한다. 이를 위해서 슬라이딩 윈도우와 두 개의 포인터를 활용하는 방식을 생각해볼 수 있다.
간단하게 생각해서 문자열의 모든 문자를 한 글자씩 읽으면서 중복되지 않는 문자인 경우 문자열에 이어붙이고 중복된 문자가 나오면 문자열을 중복된 문자의 다음부터 잘라서 활용하는 것이다.
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 기본적인 예외 처리
if not s:
return 0
if s.isspace():
return 1
rightIndex = 0 # 문자열 탐색 인덱스
longestSubstring = [] # 중복되지 않은 가장 긴 문자열
maxLength = 0 # 중복되지 않은 가장 긴 문자열의 길이
while rightIndex < len(s):
# 만약 중복된 문자가 발견된다면
if s[rightIndex] in longestSubstring:
# 중복되지 않은 가장 긴 문자열을 해당 문자 이후로 잘라서 사용
longestSubstring = longestSubstring[longestSubstring.index(s[rightIndex])+1:]
# 중복되지 않은 가장 긴 문자열에 현재 문자를 붙이고 최장 길이 갱신.
longestSubstring.append(s[rightIndex])
rightIndex += 1
maxLength = max(maxLength, len(longestSubstring))
return maxLength;사전 활용(48 ms)
문제에서는 문자열의 길이가 5 * 10^4, 즉 50000 글자까지 주어질 수 있다. 이 경우 위의 코드처럼 O(n) 시간 복잡도를 가지는 리스트의 in 연산자를 사용하는 것보다는 사전 자료형같은 해시를 활용하면 조금 더 빠른 결과를 얻을 수 있다.
그럼 어떤 관점에서 해시를 사용할 수 있을까? 위에서는 문자열을 한 글자씩 리스트에 담아서 직관적으로 구현하였다. 그러나 문제에서 "중복되지 않는" 문자열의 최대 길이를 요구하고 있기 때문에 모든 문자, 즉 알파벳은 중복된 값을 가지지 않는다. 그러면 이 알파벳을 키로 하여 해당 문자가 문자열에서 몇 번째에 위치하는지를 값으로 사전 자료형에 저장할 수 있다.
이렇게 사전에 저장하면 어떻게 활용할 수 있을까? 이번에는 탐색 인덱스가 아니라 중복되지 않은 문자열의 시작 위치(초기값 0)를 저장해 둔다. 그리고 각 글자를 읽으면서 사전 자료형에 해당 문자의 위치를 저장하고 중복되지 않은 문자열의 시작 위치와 비교하여 중복 여부를 판단한다.
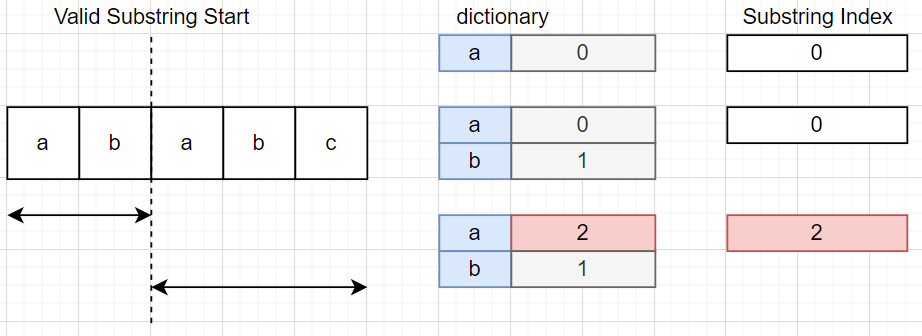 이게 무슨 소리냐면 만약 "ababc"라는 문자열이 주어졌을 때 두 번째 글자까지 읽으면 사전에는 {'a':0, 'b':1} 처럼 저장되어 있을 것이다. 그리고 세 번째 글자 'a'를 읽었을 때 이미 사전에 등록된 값이기 때문에 중복이라고 판단할 수 있으며 이 세 번째 글자부터 다시 문자열을 구축해야 하기 때문에 문자열의 시작 위치를 현재 위치로 갱신한다.
이게 무슨 소리냐면 만약 "ababc"라는 문자열이 주어졌을 때 두 번째 글자까지 읽으면 사전에는 {'a':0, 'b':1} 처럼 저장되어 있을 것이다. 그리고 세 번째 글자 'a'를 읽었을 때 이미 사전에 등록된 값이기 때문에 중복이라고 판단할 수 있으며 이 세 번째 글자부터 다시 문자열을 구축해야 하기 때문에 문자열의 시작 위치를 현재 위치로 갱신한다.
그런데 네 번째 글자인 'b'를 읽었을 때는 어떤 일이 발생할까? 이때도 'b'는 이미 사전에 등록되어 있기 때문에 문자열이 중복이라고 판단된다. 하지만 우리는 지금 세 번째 글자부터 다시 문자열을 구축하고 있기 때문에 이 'b'는 두 번째 글자의 'b'와 구분되어야 한다. 그렇기 때문에 사전에 저장된 'b'의 위치(위의 그림에서는 1)와 현재 문자열의 시작 위치(위의 그림에서는 2)를 비교하여 시작 위치 이전에 있다면, 즉 현재 슬라이딩 윈도우 바깥에 있다면 중복으로 판단하지 않아야 한다.
 그 외에는 매 탐색마다 최대 길이값을 갱신하면 어렵지 않게 구현할 수 있다. 이를 기반으로 작성한 코드는 다음과 같다.
그 외에는 매 탐색마다 최대 길이값을 갱신하면 어렵지 않게 구현할 수 있다. 이를 기반으로 작성한 코드는 다음과 같다.
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
# 기본적인 예외처리
if not s:
return 0
if s.isspace():
return 1
usedCharacter = dict() # 문자와 문자의 위치를 저장하는 사전 자료형
leftIndex = 0 # 중복되지 않는 최장 문자열의 시작 위치
maxLength = 0 # 중복되지 않는 최장 문자열의 길이
for index, character in enumerate(s):
if character in usedCharacter and usedCharacter[character] >= leftIndex:
# 현재 문자가 이미 사전에 등록된 중복된 문자며
# 문자열의 시작 위치보다 뒤, 즉 현재 문자열에 포함될 문자일 경우
# 문자열의 시작 위치를 중복된 문자의 다음으로 설정
leftIndex = usedCharacter[character] + 1
# 매 탐색마다 최장 길이 갱신
maxLength = max(maxLength, index - leftIndex + 1)
# 현재 문자의 위치를 사전에 등록
usedCharacter[character] = index
return maxLength;중복 문자일 때 문자열의 시작 위치를 중복된 문자의 다음으로 설정하는 것은 "abcbde"에서 4번째 글자 'b'로 중복이 발생했을 때 두 번째 글자 'b' 다음인 'c'부터 문자열을 구축하기 위해서다. 결과적으로 "cbde"가 구축된다.
만약 문자열의 시작 위치가 변경될 때마다 이전에 있던 문자들을 사전에서 일일히 삭제해준다면 비교해 줄 필요가 없겠지만 그것보다는 차라리 저렇게 비교하는게 더 효율적일 것이다.
참고자료
