서론
이전에 인터넷에서 아래와 같은 글을 본 적이 있다.
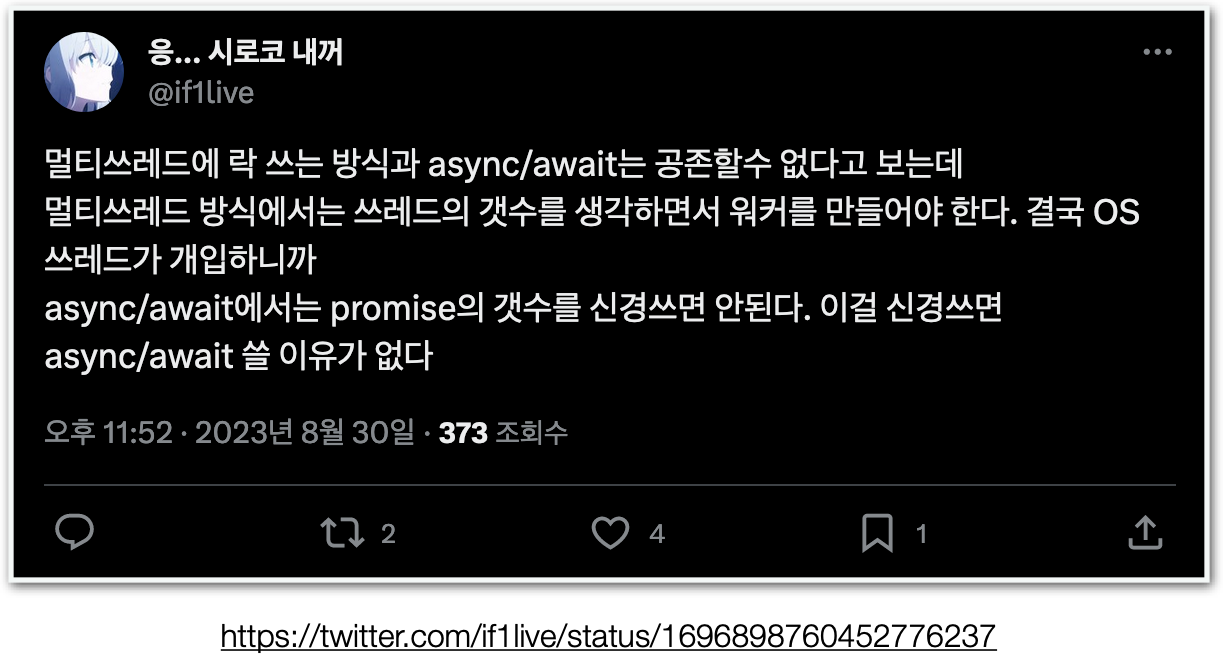
멀티스레딩에서 동기화를 위해 락을 거는 것과 논블로킹에서 async, await의 차이에 대해서 다루는 것 같은데 멀티쓰레드 방식에서는 쓰레드의 갯수를 생각하면서 워커를 만들어야 한다. 결국 OS 쓰레드가 개입하니까라는 문장과 async/await에서는 promise의 갯수를 신경쓰면 안된다. 이걸 신경쓰면 async/await 쓸 이유가 없다라는 문장에서 흥미를 느껴서 좀 더 알아보기로 했다.
파고들어가면 끝도 없기 때문에 대학교 교재처럼 개념에 대한 자세한 설명이나 원리를 적고자 하는 것은 아니지만 실무에서 애플리케이션 레벨만 다루던 것에서 벗어나 오랜만에 하위 계층으로 내려가보는 것에 의의를 두고자 한다. 애초에 블로그를 몇 개월만에 쓰는 것인지...
본론
멀티스레딩과 OS 스레드
첫 번째로 멀티스레딩에서 OS 스레드가 개입하기 때문에 스레드의 갯수를 생각하면서 워커를 만들어야 한다는 문장을 살펴보자. 내가 생각하기에 이것은 애플리케이션 코드를 실행시키는 스레드, 프로세스가 운영체제를 통해 최종적으로는 하드웨어(CPU)에 의존한다는 것을 말하는 것 같다.
프로세스가 뭐니 스레드가 뭐니 하는 개념은 다른 훌륭한 도서, 사이트 등에서 이미 잘 설명하고 있으니 프로세스는 CPU 코어, 메모리 등 시스템 자원을 할당받아 동작하는 프로그램 코드, 스레드는 프로세스 내부에서 시스템 자원을 일부 공유하며 동작하는 더 작은 프로그램 코드라 정의하고 넘어가겠다.
한 프로세스는 한 스레드만 가지고 동작할 수도 있지만 작업의 효율성과 편의성을 위해 여러 스레드를 생성하여 멀티스레딩 방식으로 동작할 수 있다. 예를 들어 톰캣같은 서블릿 웹 서버같은 경우 HTTP 요청 하나를 받았다고 다른 요청을 기다리게 하면 안 되기 때문에 요청마다 스레드를 생성하곤 한다.
그러나 스레드의 갯수가 작업의 효율성에 비례하진 않는데 실제로 어셈블리, 기계어 코드를 읽어서 명령을 실행하는 CPU 코어는 한 번에 하나의 작업밖에 할 수 없기 때문이다
찾아보니 가상 스레드, Hyper-V 등으로 한 코어가 여러 스레드를 동시에 실행할 수도 있다고 한다. 하지만 지금은 하나밖에 실행할 수 없다고 가정하겠다.
여러 스레드가 있을 때 순서대로 스레드 하나를 끝내고 다른 스레드로 넘어가는 방식은 응답성 측면에서 적합하지 않으니 코어는 스레드의 프로그램 코드를 번갈아가면서 처리하게 된다. 하지만 이 과정에서 ‘컨텍스트 스위칭’이란 추가 비용이 발생한다. 앞서 언급했듯이 스레드는 시스템 자원을 공유하며 각자 자신만의 영역(스택 등), 프로그램 코드의 실행 위치를 갖기 때문에 프로세서가 한 스레드에서 작업하다가 중간에 다른 스레드의 작업을 처리하려면 이 스레드의 ‘영역’을 코어가 다시 읽어와야 한다. 그렇기 때문에 프로세스 내 스레드가 많아질수록 코어가 실제로 일해야 하는 시간에 컨텍스트 스위칭을 하고 있으니 오히려 처리가 늦어지는 것이다.
이것 말고도 공유자원을 처리하는 문제도 있다. 예를 들어 여러 스레드가 같은 값을 바라보고 있고 값에 따라 분기되는 코드를 실행하는 수십개의 스레드가 있다고 하자. 한 스레드가 값이 맞아서 분기를 타고 들어왔다가 스케줄링에 의해서 코어를 다른 스레드에게 뺏겼는데 나중에 다시 자신의 차례가 됐더니 값이 안맞는 상태로 변해있는 경우가 발생할 수 있다. 로직상으로는 진입할 수 없는 구간에 경쟁 상태로 인해 진입하게 된 것이다. 그래서 자기가 작업중일 때는 다른 스레드에게 뺏기지 않도록 하거나 특정 구간을 한 번에 한 스레드만 진입할 수 있도록 막는 등 여러가지 동기화 기법을 적용할 수 있는데 이는 필수적인 기능이지만 필연적으로 애플리케이션 성능의 발목을 잡는 부분이 된다.
그래서 대개 프로세스 내에서 스레드를 생성할 때는 애플리케이션이 실행되는 실제 하드웨어 환경의 CPU 스펙을 넘지 않도록 하는 것이 일반적인 의견이다. 정해진 공식은 없고 최적의 값을 찾으려면 여러 경우의 수로 테스트해보는 수 밖에 없지만 대개 이론적으로 CPU가 갖고 있는 물리적 스레드 갯수만큼 스레드를 생성하는 것이 좋다는 글이 많다.
그리고 이런 점에서 여러 스레드가 동작하는 멀티스레딩은 OS가 관리하는 하드웨어 자원인 스레드가 개입하기 때문에 지나친 컨텍스트 스위칭 등으로 자원이 낭비되지 않도록 스레드의 갯수를 생각하면서 워커를 만들어야 한다고 이해할 수 있다.
멀티스레딩과 락
그렇다면 “멀티쓰레드에 락 쓰는 방식”이란 건 무슨 말일까? 이는 앞서 언급했듯이 여러 스레드가 공유자원을 처리할 때 사용하는 동기화 방식이다. 말 그대로 자물쇠처럼 특정 코드 블록을 걸어잠궈서 스레드의 접근을 제한하는 것인데 먼저 락을 얻은 스레드만 접근하고 나머지는 대기하는 advisory 락과 한 스레드가 락을 얻었으면 나머지는 접근하지 못하고 바로 예외처리가 되는 mandatory 락이 있다. 용어 출처
경쟁이 별로 심하지 않으면 상관없겠지만 매우 많은 스레드가 락을 두고 경쟁하는 경우 소프트웨어적으로 처리가 안되기 때문에(기계어 라인 단위로 경쟁 상태가 일어나는 등) 하드웨어의 도움을 받아서 여러가지 전략을 적용할 수 있다.
더 깊게 들어가면 운영체제 교재를 갖고와야 할 것 같아서 간략하게 이 정도로 하고, 그러면 왜 위의 글에서 이 동기화 기법인 락을 언급했을까? 내 생각에는 그냥 멀티스레드 환경에서는 락을 쓰는 경우가 잦기 때문에 언급했던 것 같다. “멀티스레딩 환경의 락”이라는 주제는 “OS 스레드의 갯수를 생각하면서 스레드를 생성하는 멀티스레딩”과 “promise의 갯수를 생각하지 않고 생성하는 async/await”의 대립 구도에 어울리지 않는다고 생각하기 때문이다. 그것보다 “async/await에서는 promise의 갯수를 신경쓰면 안된다.”는 문장을 좀 더 살펴보자.
async/await과 promise
프로그래밍 패러다임에는 blocking, non-blocking으로 구분되는 종류가 있다. 작성한 코드가 한 라인씩 실행되면서 결과를 받을 때까지 다음 라인으로 진행하지 않는 익숙한 blocking 방식과 일단 실행하고 결과를 기다리지 않고 다음 라인으로 넘어가는 non-blocking 방식이 있다.
그렇지만 함수를 호출했으면 결과를 받아서 언젠가는 활용해야 하는데 그냥 넘어가버리면 어떻게 받을 수 있을까? 여기서 Promise 란 것을 활용할 수 있다.
async, await, Promise 세 가지 언급을 통해 Javascript 환경이라 추측하였으며 멀티스레딩과 비교하고 있기 때문에 브라우저가 아닌 백엔드, 서버 런타임이라 가정하였다.
async, await를 키워드로 사용하는 자바스크립트 환경을 예로 들어보자. 자바스크립트에서는 async 함수를 호출하면 아래처럼 Promise 라는 것을 받게 된다.
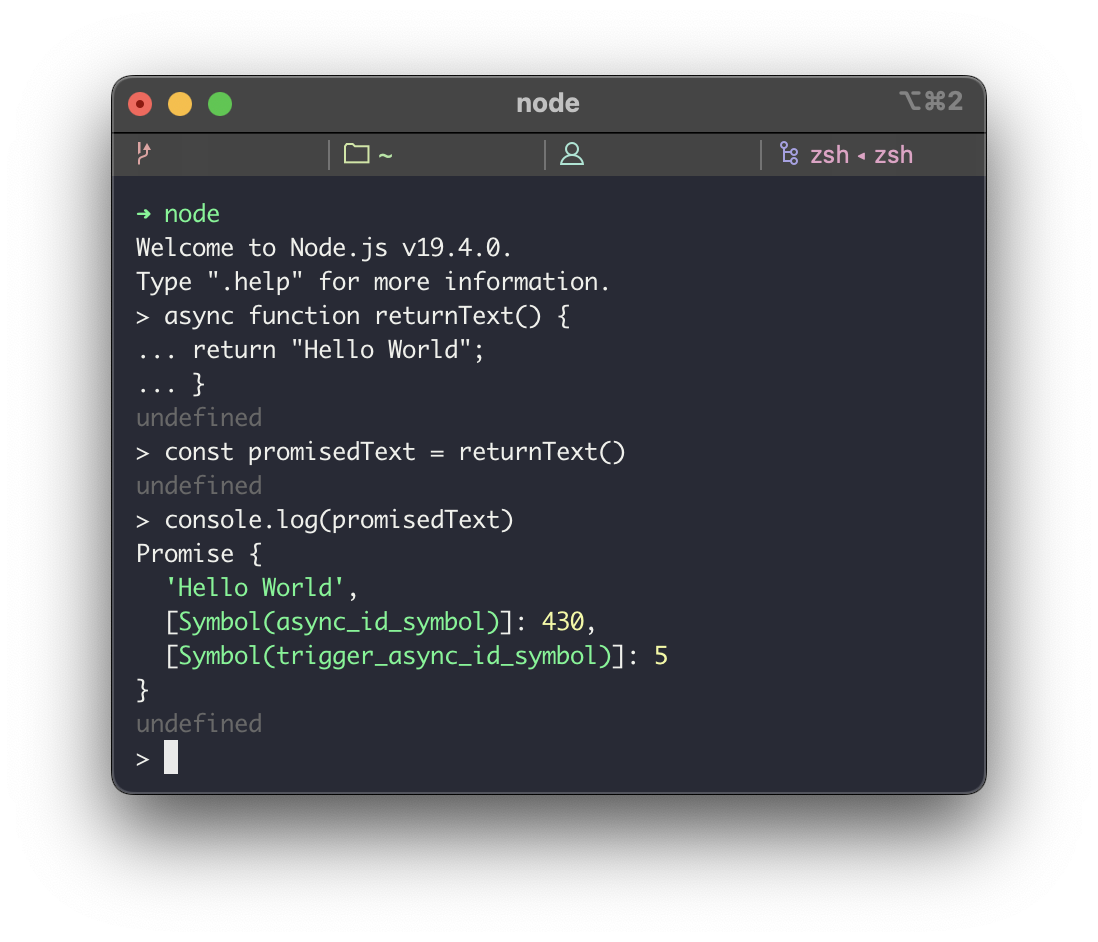
이 Promise는 언젠가는(eventual) 성공이든 실패든 끝날 비동기 작업을 감싸고 있는 프록시 객체라 할 수 있다. 비동기 작업이라 하면 대개 외부 네트워크 요청이나 디스크에 파일 쓰기같은 I/O 요청을 예로 들 수 있는데 대개 몇십 ms에서 몇백 ms까지 걸리기 때문에 이걸 기다리느라 코드를 더 실행하지 못하는(즉 blocking 하는) 것은 바람직하지 못하다. 게다가 요청을 여러개 보내야 하는데 이렇게 직렬로 처리하게 된다면 그 대기시간은 기하급수적으로 늘어나게 된다. 그래서 일단 요청을 보내놓고 그 결과는 나중에 받도록 약속(promise)하고 애플리케이션을 계속 실행시키는(즉 non-blocking 하는) 것으로 문제를 해결할 수 있다.
그러면 이 Promise와 async, await은 무슨 상관이 있을까? 자바스크립트에서는 async 키워드로 함수를 생성하면 함수의 반환값을 자동으로 Promise로 감싸주며 await으로 async 함수를 호출하면 아래처럼 Promise가 감싸고 있는 반환값을 꺼내서 돌려준다. 마치 비동기 함수를 동기적으로(synchronous) 호출한 것처럼 동작하는 것이다.
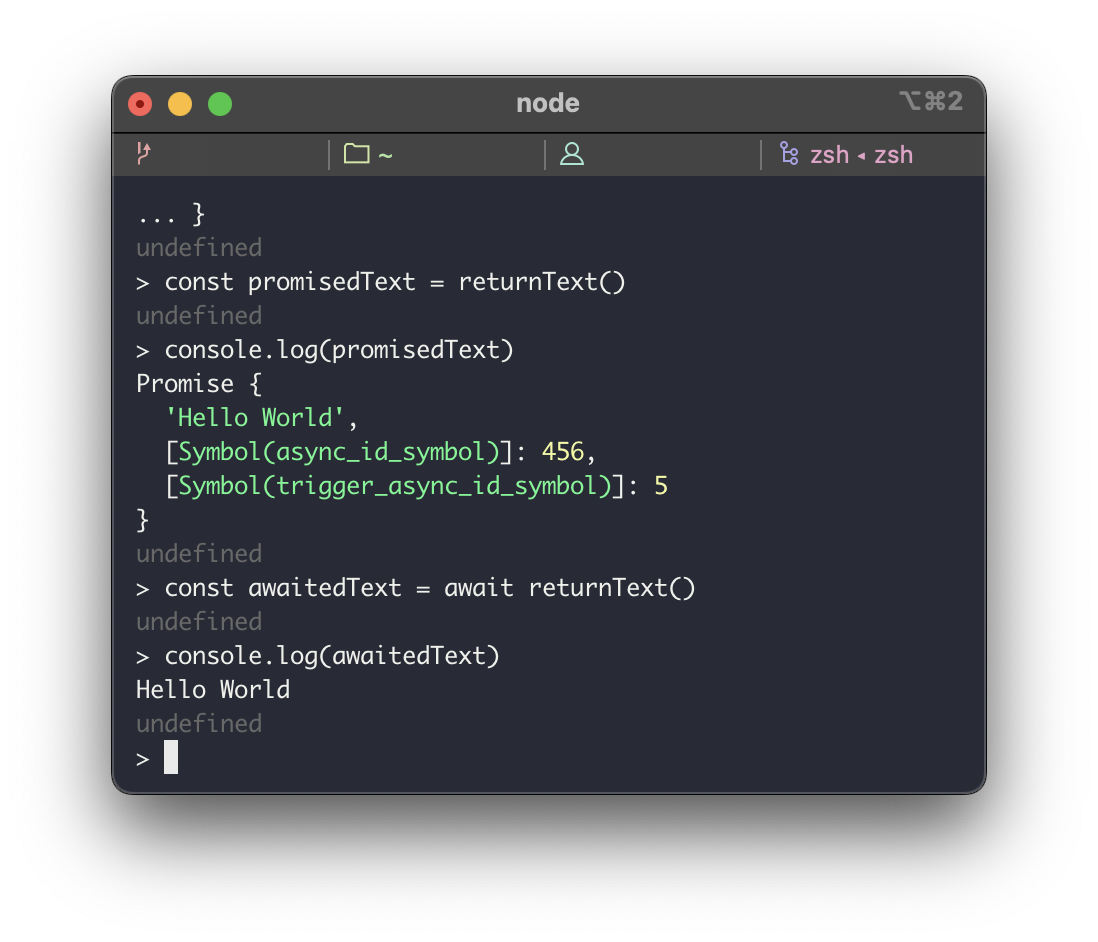
즉 async, await은 Promise를 사용하기 위한 키워드, syntactic sugar에 불과하며 비동기 작업을 생성하고 결과를 받아오는 방법이다. 그런데 비동기적으로 작업을 실행하려면 blocking되지 않아야 하니 애플리케이션을 실행하는 메인 스레드가 아니라 다른 스레드에서 작업해야 하는데 싱글 스레드 구조인 자바스크립트에서 멀티스레딩을 어떻게 할 수 있을까? 이를 위해 자바스크립트 런타임(Node.js 기준)에서는 클라이언트의 요청을 조율하는 이벤트 루프와 실제로 작업을 처리하는 스레드 풀을 활용하고 있다.
순수 자바스크립트 코드들은 싱글 스레드에서 처리가 가능하지만 asynchronous하게 실행되는 위의 async, promise function 이라던가 타임아웃이 걸린 콜백, 외부 I/O 같은 blocking 함수들은 애플리케이션이 실행되는 싱글 스레드 자체를 막아버리기 때문에 C 라이브러리(Node.js 기준 libuv 등)로 작성된 스레드 풀에 위임하는 것이다.
그러면 스레드 풀을 쓰는게 promise의 갯수를 신경쓰지 않는 것과 어떤 상관이 있을까? 이는 스레드 풀의 장점인 멀티스레딩처럼 매 작업마다 스레드를 직접 생성하고 관리하지 않아도 이미 ‘풀’이라는 특정 자료구조에 생성되어 있는 스레드들을 재사용할 수 있다는 것을 생각해볼 수 있다. 이 스레드 풀에 들어가는 ‘작업 큐’에 작업들만 넘긴다면 스레드 풀이 알아서 놀고있는 스레드에게 작업을 전달하면서 스레드의 생성, 파괴 비용 없이 수행할 수 있다. 즉 스레드의 갯수를, 위 트윗의 말을 빌리자면 “promise의 갯수를 신경쓸 이유가 없는” 것이다.
결론
그래서 간단하게 요약하면 다음과 같다.
- 멀티스레딩은 실제로 하드웨어 스레드를 활용하기 때문에 컴퓨팅 스펙을 고려하여 생성하는 스레드의 갯수를 제한해야 한다.
- async/await은(Node.js의 경우) non-blocking한 패러다임과 소프트웨어 스레드 풀을 활용하기 때문에 Promise의 갯수를 제한할 필요가 없다.
결론이 좀 어영부영 나온 것 같은데… 아무래도 간단한 인터넷 검색과 짤막하게 기억하는 대학교 시절 운영체제 수업의 내용을 떠올리면서 이 글을 적었기 때문에 탐구과정이 깊지 못해서 그런 것 같다. 그리고 이렇게 뭔가 주저리주저리 늘어놓을 줄은 몰랐는데 더 쉽게 설명할 수 있도록 이론적인 공부를 더 해야 할 것 같다.
이런 글을 자주 쓰면서 공부하는 습관을 다시 들이면 더 좋을 것이다.
