서론
나는 프로젝트를 진행하면서 관계형 데이터베이스 테이블을 작성하는 경우 대부분 정수 식별자를 PK로 사용했다. 특별한 이유가 있는 것은 아니지만 간단하고 AUTO INCREMENT 가 가능하며 익숙하기 때문에 활용하곤 하는데 지난번 면접에서 들었던 얘기가 있다.
어차피 unique 하고 nullable 하지 않은 값이라면 해당 컬럼을 PK로 쓸 수 있지 않은가?
데브코스에서 진행했던 프로젝트를 언급할 때 사용자 테이블에 대한 얘기가 나와서 설명하다가 PK 말고도 unique not null 한 컬럼(natural key, 이메일)으로 구분할 수 있는 레코드라면 굳이 정수 식별자(surrogate key)를 활용할 필요가 없지 않느냐는 얘기가 나왔었다.
면접이 끝나고 곰곰히 생각해보니 틀린 말은 아닌 것 같은데 그러면 두 방식이 어떤 차이가 있는 것일까? 이에 대해서 조금 조사해보았다.
본론
키의 종류
데이터베이스에서 사용하는 키는 레코드(row)를 구분하는데 사용할 수 있는 컬럼으로 다음과 같은 종류가 있다.
- Composite Key: 두 가지 이상의 컬럼으로 이루어진 키.
- Natural Key: 현실 세계의 속성으로 적용된 키. 이메일, 주민등록번호 등.
- Surrogate Key: 비즈니스적 의미가 없는 키. 정수형 식별자 등.
- Candidate Key: Primary Key가 될 수 있는 unique 한 키의 모음. Composite Key도 해당될 수 있음.
- Primary Key: 해당 엔티티의 식별자 키.
- Alternate Key: Primary Key 대신 사용할 수 있는 레코드의 unique 키.
- Foreign Key: 외부 엔티티의 PK를 가리키는 키.
여기서 이번 포스트에서 다룰 Natural Key, Surrogate Key는 간단히 말해서 비즈니스적인 의미, 애플리케이션에서 활용할 여지가 있는 unique한 데이터로 이루어진 컬럼인지 차이다. 언급했듯이 이메일, 주민등록번호 같은 데이터는 어떤 의미(전자메일 주소, 개인 식별 번호)가 있는 데이터기 때문에 Natural Key에 해당하지만 1, 2, 3, ... 으로 증가하는 AUTO INCREMENT 정수형 식별자는 어떤 의미도 없기 때문에 Surrogate Key에 해당하는 것이다.
어떤 키를 사용할 것인가?
면접관이 언급한 것처럼 이메일도 unique not null 하고 정수 식별자도 unique not null 하다면 이런 경우에는 무조건 정수형 식별자같은 Surrogate Key 대신 이메일 같은 Natural Key를 사용하면 되는 것일까?
애플리케이션 특성마다 다르겠지만 때에 따라서는 이런 사용자 식별자, 특히 개인정보에 해당할 수 있는 이메일이나 아이디같은 부분을 클라이언트가 식별자로 사용하도록 노출하고 싶지 않을 수도 있다. 이런 경우에는 Surrogate Key를 활용하는 것이 좋은 방안이 될 수 있다.
반대로 클라이언트에게 이런 정보를 노출하고 싶다면 사용에 혼란이 올 수 있는 정수형 식별자 대신 이메일 같은 Natural Key를 활용하는 것이 좋은 방안이 될 수 있다.
오히려 한 가지 키만 사용하도록 강제하지 않아도 된다. 정수형 식별자로 간단하게 다룰 수 있는 경우라면 id 필드를 사용하고 이메일이 필요하다면 email 필드를 사용하면서 유연하게 참조하면 되지 않을까?
말이 애매해졌지만 중요한 차이는 이메일 주소는 데이터베이스 레코드 상으로는 unique not null하지만 현실 세계에서는 소실될 수 있는, stable 하지 않은 키라는 것이다. 대개 그럴 일이 없지만 만에 하나 이메일 서비스가 종료된다면 해당 이메일 주소는 더 이상 유효하지 않기 때문에 추후 사용자가 비밀번호 복구 등에 이메일 주소를 사용할 시 난감할 수 있다.
즉 레코드를 구별하는 식별자가 현실 세계의 영향을 받을 수 있다는 점은 이메일 컬럼을 PK로 사용하기 전에 충분히 고려해볼 만한 점이라 할 수 있다. 물론 정수형 식별자도 분산 데이터베이스 환경에서 문제가 될 수 있는 부분이 있지만 이 포스트에서는 단일 데이터베이스의 테이블을 가정했다.
unique 컬럼의 인덱스
unique 컬럼을 가진 테이블을 몇 번이고 생성하면서도 몰랐던 점인데 MySQL에서는 unique 컬럼에 대하여 UNIQUE INDEX를 생성한다. JPA에서 아래처럼 디자인한 엔티티는 아래처럼 쿼리가 실행된다.
@Entity
public class UserAccount {
@Id @GeneratedValue
private Long id;
@Column(name = "email", unique = true, nullable = false)
private String email;
@Column(name = "name", nullable = false)
private String nickName;
...create table user_account2 (id bigint not null, email varchar(255) not null, name varchar(255) not null, primary key (id)) engine=InnoDB
alter table user_account2 add constraint UK_gig8560dcl8rp20ak28x7pjki unique (email)엔티티의 email 필드에 @Column 어노테이션의 unique 속성을 설정했기 때문에 테이블을 생성한 후 unique constraint를 거는 것을 볼 수 있다. MySQL Workbench에서 확인해보면 역시 인덱스가 생성된 것을 볼 수 있다.
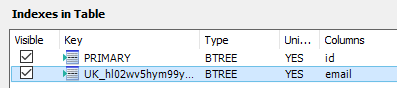
그렇기 때문에 약 10000 건의 레코드가 저장된 데이터베이스에서 식별자 컬럼을 기반으로 조회하든 이메일 컬럼을 기반으로 조회하든 같은 실행 계획을 가지는 것을 볼 수 있다.
# 식별자 기반 조회
select * from user_account where id=1234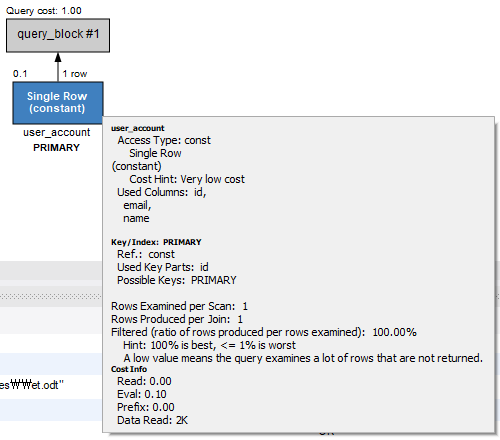
# 이메일 기반 조회
select * from user_account where email="tempore_dolores\\et.odt"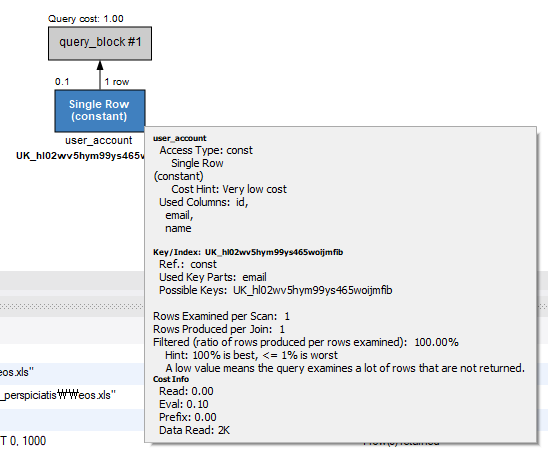
만약 이메일 컬럼의 인덱스를 제거한다면 다음처럼 Full Table Scan을 수행하는 것을 볼 수 있다.
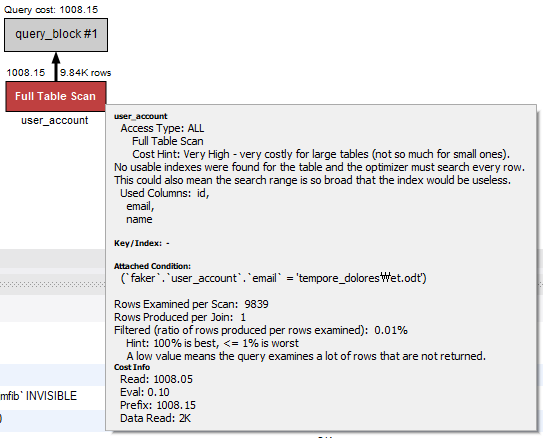
저장 공간의 차이?
만약 데이터 저장 공간에 민감한 상황이라면 정수 식별자를 제거하고 이메일 컬럼을 PK로 사용해서 불필요한 인덱스를 없앨 수도 있지만 그럴 경우가 그렇게 많지는 않을 것이라 생각한다.
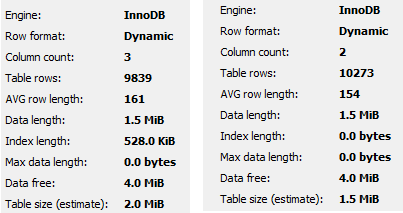
위의 테이블에 10000건의 데이터를 집어넣고 정수 식별자와 이메일 컬럼을 둘 다 사용하는 경우와 이메일 컬럼을 PK로 사용하는 경우를 비교하면 데이터 저장공간의 3분의 1 정도를 차지하는 인덱스 저장공간이 사라졌기 때문에 용량이 확실히 줄어든 것은 볼 수 있다.
키 자체의 크기 차이(정수, 문자열 자료형)도 스택오버플로우에 달린 25년 경력의 DBA의 답변으로는 전체 성능에 그렇게 큰 영향을 주지 않는다고 한다.
결론
결론이 좀 얼렁뚱땅 내려지긴 했지만 결국 어떤 방법을 사용하든 그렇게 큰 차이는 없다는 것이 결론이다. 정수 식별자와 이메일 컬럼이 둘 다 unique 하더라도 테이블에 unique 한 컬럼이 하나만 있어야 한다는 제약사항은 없는 만큼 취향에 맞게 사용하면 될 것이다.
그렇지만 이메일 컬럼은 비즈니스적인 의미 때문에 현실 세계의 영향을 받을 수 있는 Natural Key 라는 점에서 아무래도 정수 식별자인 Surrogate Key 를 테이블의 PK로 설정하는 습관은 좀 더 유지해도 좋지 않을까 싶다.
참고
web application user table primary key: surrogate key vs username vs email vs customer Id
Choosing a Primary Key: Natural or Surrogate?
