설명
LeetCode의 Task Scheduler 문제다.
처리해야 하는 작업의 목록과 동일 작업을 처리하는 데 필요한 대기 시간이 주어질 때 모든 작업을 가장 빨리 처리하려면 몇 초나 걸리는지 계산하는 문제다.
예를 들어 작업이 [A, A, A, B, B, B]가 주어지며 대기 시간은 2초라면 A -> B -> 대기 -> A -> B -> 대기 -> A -> B 순서로 총 8초가 걸린다.
풀이
구현 1 (실패)
그냥 돌아가면서 작업을 아무거나 실행시키고 대기 시간에 걸린다면 다른 작업을 실행시키면서 총 걸린 시간을 구하면 되는게 아닌가 싶지만 아래와 같은 반례에서 바로 걸린다.
작업: [A, A, A, B, B, B, C, C, C, D, D, E]
대기 시간: 2
실행 결과: [A, B, C, A, B, C, A, B, C, D, E, 대기, D]로 총 13초.
정답: [A, B, C, D, E, A, B, C, D, A, B, C]로 총 12초.
즉 그냥 돌아가면서 작업하면 안되고 일정한 기준으로 실행해야 한다. 아마 이 정도로 풀렸으면 Medium이 아니라 Easy 문제였을 것이다.
import collections
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
jobs = collections.defaultdict(int)
lastProcessed = dict()
# 동일한 작업의 수량 확인.
for task in tasks:
jobs[task] += 1
# 작업 최근 수행 시각.
for job in jobs:
lastProcessed[job] = -9999
tick = 0
while len(jobs) > 0:
# 특별한 기준 없이 모든 작업을 탐색하면서
for job in jobs:
# 대기 시간이 지난 작업이라면 실행.
if (tick - lastProcessed[job]) > n:
lastProcessed[job] = tick
jobs[job] -= 1
# 작업이 끝났다면 자료구조에서 제거.
if jobs[job] < 1:
jobs.pop(job)
break
# 시간 증가
tick += 1
# 시간 반환
return tick구현 2 (2340ms)
그래서 두 번째로 생각해 본 방법은 작업량이 가장 많은 작업을 우선으로 실행시키고 대기 시간이라면 그 다음으로 많은 작업을 실행시키는 방식이었다. 이 경우 작업을 실행한 후 남은 작업량에 따라 우선순위를 변경해야 했기 때문에 정렬된 리스트에서 탐색을 통해 교환하는 방식으로 구현했다.
결과적으로 풀이는 통과할 수 있었지만 하위 5% 성능에 그치고 말았다. 이를 기반으로 작성한 코드는 다음과 같다.
import collections
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
jobs = collections.defaultdict(int)
lastProcessed = dict()
for task in tasks:
jobs[task] += 1
# 가장 종류가 많은 작업 순서대로 정렬.
sortedJobs = sorted([[jobs[job], job] for job in jobs], reverse=True)
# 최근 수행 시간.
for job in jobs:
lastProcessed[job] = -9999
tick = 0
while sortedJobs:
# 가장 많은 작업부터 처리.
for index, job in enumerate(sortedJobs):
jobName = job[1]
# 대기 시간이 지났다면 작업 수행.
if (tick - lastProcessed[jobName]) <= n:
continue
lastProcessed[jobName] = tick
job[0] -= 1
if job[0] < 1:
sortedJobs.pop(index)
break
# 정렬 상태를 유지하도록 현재 작업과 다른 작업 비교.
# 남은 작업의 갯수가 현재 작업 이하인 곳까지 탐색.
compareIndex = index
while compareIndex < len(sortedJobs)-1 and job[0] < sortedJobs[compareIndex+1][0]:
compareIndex += 1
# 만약 이동이 필요하다면 삽입 후 원래 요소는 삭제.
# insert 시 1을 더해서 기존 요소 다음에 삽입.
if compareIndex != index:
sortedJobs.insert(compareIndex+1, job)
sortedJobs.pop(index)
break
tick += 1
return tick아무래도 문제에서는 작업이 약 1만개 까지 주어질 수 있기 때문에 위처럼 리스트에서 탐색 및 삽입, 삭제 연산을 수행하면 시간을 많이 소모하는 것 같다.
그렇지만 일단 풀이의 대전제인 많은 작업부터 수행해야 한다는 것은 맞는 것 같은데 그렇다면 이를 어떻게 최적화할 수 있을까?
Greedy (392ms)
영어로 된 풀이를 찾아본 결과 파이썬은 아니지만 알고리즘을 제일 잘 설명했다고 생각하는 이 풀이를 보고 조금이나마 이해할 수 있었다. 먼저 문제를 접근하는 관점은 작업들을 모두 처리할 때 대기 시간이 얼마나 걸리는지다.
이전에는 실제로 작업들을 자료구조에 넣어서 처리하고 우선순위를 변경시켰다면 이 풀이는 좀 더 수학적으로 접근하는 것인데 일단 기본적인 방법은 다음과 같다.
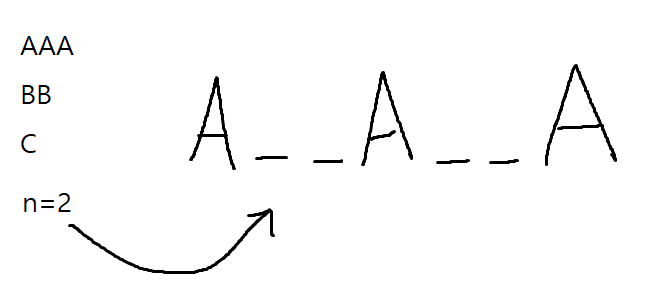 먼저 작업이 [A, A, A, B, B, C] 처럼 주어지고 대기 시간이 2일 때 제일 많은 작업인 'A'를 대기 시간만큼 띄워서 작업 슬롯을 배치(스케줄링)한다. 그러면 저 대기 시간에 CPU는 작업 A가 아닌 다른 작업을 수행할 수 있으며 이때 B나 C를 실행할 수 있다.
먼저 작업이 [A, A, A, B, B, C] 처럼 주어지고 대기 시간이 2일 때 제일 많은 작업인 'A'를 대기 시간만큼 띄워서 작업 슬롯을 배치(스케줄링)한다. 그러면 저 대기 시간에 CPU는 작업 A가 아닌 다른 작업을 수행할 수 있으며 이때 B나 C를 실행할 수 있다.
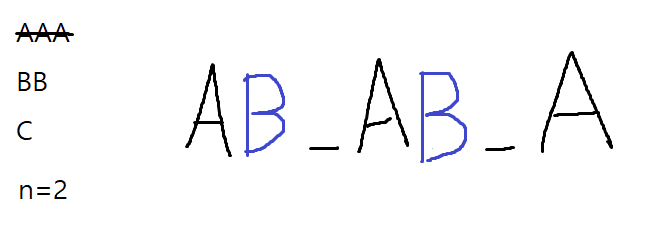 그 다음으로 가장 많은 작업인 B를 대기 시간에 배치한다.
그 다음으로 가장 많은 작업인 B를 대기 시간에 배치한다.
 그리고 마지막으로 남은 C를 두 공간 중 아무 곳에나 배치한다. 그러면 모든 작업을 처리하도록 스케줄링할 수 있다. 이 경우 모든 작업을 처리하고도 대기 시간 슬롯이 하나 필요하다. 즉 가장 많은 작업부터 대기 시간을 기준으로 배치하고 대기 시간 슬롯에 다른 작업들을 역시 많은 순서대로 스케줄링하는 것이다.
그리고 마지막으로 남은 C를 두 공간 중 아무 곳에나 배치한다. 그러면 모든 작업을 처리하도록 스케줄링할 수 있다. 이 경우 모든 작업을 처리하고도 대기 시간 슬롯이 하나 필요하다. 즉 가장 많은 작업부터 대기 시간을 기준으로 배치하고 대기 시간 슬롯에 다른 작업들을 역시 많은 순서대로 스케줄링하는 것이다.
그렇다면 가장 많은 작업부터 스케줄링하는 이런 Greedy한 방식이 최적의 해라고 어떻게 알 수 있을까? 이 댓글을 참조하면 조금 이해가 갈 수 있는데 일단 가장 많은 작업이든 적은 작업이든 대기 시간은 지켜야 한다. 그렇기 때문에 가장 많은 작업(위의 예시에서는 A)을 먼저 대기 시간을 포함한 작업 목록을 스케줄링(A__A__A)한다. 그리고 나머지 작업(위의 예시에서는 B, C)들을 그 대기 시간에 최대한 포함시켜서 대기 시간을 줄이는 방식으로 스케줄링하는 것이다.
그럼 만약 가장 많은 대기 시간의 작업이 복수라면 어떨까? 이 때는 별도의 대기 시간을 갖지 않고 기존의 대기 슬롯에 스케줄링한다. 물론 이 작업들도 동일한 대기 시간을 가져야 하기 때문에 아래 그림처럼 맨 처음 작업 슬롯 근처에 스케줄링할 수 있다.
 그런데 이러면 첫 번째 풀이처럼 작업 D와 E가 대기 시간을 갖게 되기 때문에 안되지 않을까? 여기서 중요한 것은 꼭 맨 처음에 상정했던 대기 슬롯에만 넣어야 하는 것이 아니라는 것이다. 작업 A와 그 사이의 대기 슬롯은 문제에서 요구하는 최소한의 제약조건이기 때문에 그 사이에 추가적으로 다른 작업(D, E 등)을 집어넣어도 된다.
그런데 이러면 첫 번째 풀이처럼 작업 D와 E가 대기 시간을 갖게 되기 때문에 안되지 않을까? 여기서 중요한 것은 꼭 맨 처음에 상정했던 대기 슬롯에만 넣어야 하는 것이 아니라는 것이다. 작업 A와 그 사이의 대기 슬롯은 문제에서 요구하는 최소한의 제약조건이기 때문에 그 사이에 추가적으로 다른 작업(D, E 등)을 집어넣어도 된다.
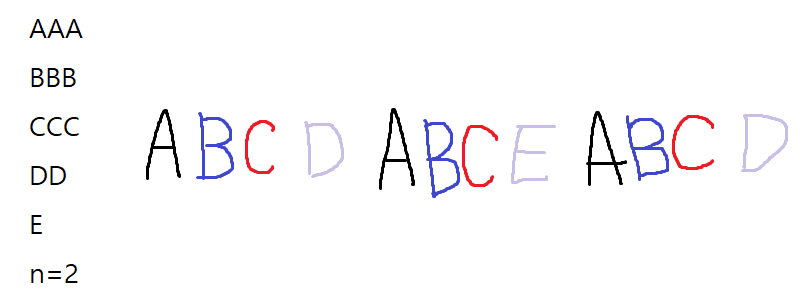 즉 위의 그림처럼 작업 A, B, C 쌍의 사이 사이에 다른 작업들을 스케줄링할 수 있다. 이 경우 별도의 대기 시간이 필요하지 않기 때문에 모든 작업들을 처리하는 데 걸리는 시간을 그대로 반환하면 된다. 그럼 대기 시간이 걸리는 작업은 어떨까?
즉 위의 그림처럼 작업 A, B, C 쌍의 사이 사이에 다른 작업들을 스케줄링할 수 있다. 이 경우 별도의 대기 시간이 필요하지 않기 때문에 모든 작업들을 처리하는 데 걸리는 시간을 그대로 반환하면 된다. 그럼 대기 시간이 걸리는 작업은 어떨까?
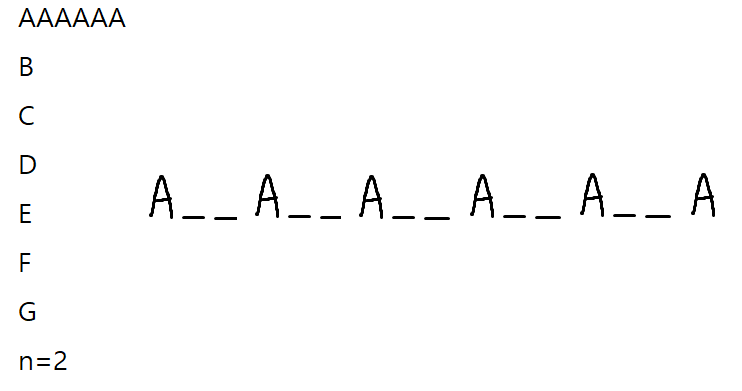 [A, A, A, A, A, A, B, C, D, E, F, G] 작업이 있고 대기 시간이 2일 때 먼저 가장 많은 작업인 A는 위처럼 배치할 수 있다. 나머지 작업들은 모두 한 개씩 있기 때문에 이 대기 시간 슬롯들에 그대로 배치할 수 있다.
[A, A, A, A, A, A, B, C, D, E, F, G] 작업이 있고 대기 시간이 2일 때 먼저 가장 많은 작업인 A는 위처럼 배치할 수 있다. 나머지 작업들은 모두 한 개씩 있기 때문에 이 대기 시간 슬롯들에 그대로 배치할 수 있다.
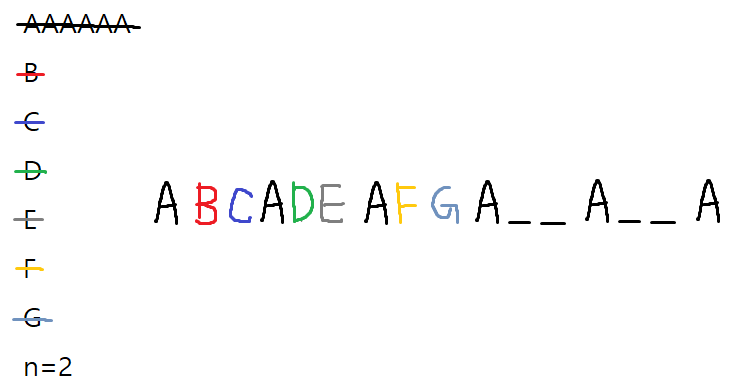 이 경우 모든 작업을 배치하고도 4개의 대기 시간이 남기 때문에 모든 작업의 갯수 + 4가 모든 작업을 처리하는 데 걸리는 시간이 될 것이다.
이 경우 모든 작업을 배치하고도 4개의 대기 시간이 남기 때문에 모든 작업의 갯수 + 4가 모든 작업을 처리하는 데 걸리는 시간이 될 것이다.
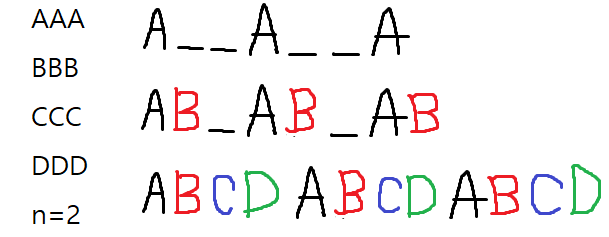 다른 예시로 처음에 생성되는 대기 슬롯이 가장 많은 작업들을 모두 담을 수 없는 경우도 위처럼 작업 그룹 사이마다 집어넣을 수 있기 때문에 별 문제가 되지 않는다.
다른 예시로 처음에 생성되는 대기 슬롯이 가장 많은 작업들을 모두 담을 수 없는 경우도 위처럼 작업 그룹 사이마다 집어넣을 수 있기 때문에 별 문제가 되지 않는다.
제일 중요한 것은 가장 많은 작업의 수와 그 작업이 얼마나 있는지, 대기 시간 슬롯에 다른 작업들을 얼마나 채워넣을 수 있는지다. 이는 풀이에서 볼 수 있듯이 공식으로 나타낼 수 있다.
- 가장 많은 작업의 종류(A, B, ...): jobs
- 가장 많은 작업의 갯수(3개, ...): works
- 대기 시간: n
- 대기 슬롯: (works-1) * (n-(jobs-1))
- 대기 슬롯에 스케줄링되어야 하는 작업: 전체 작업 - jobs * works
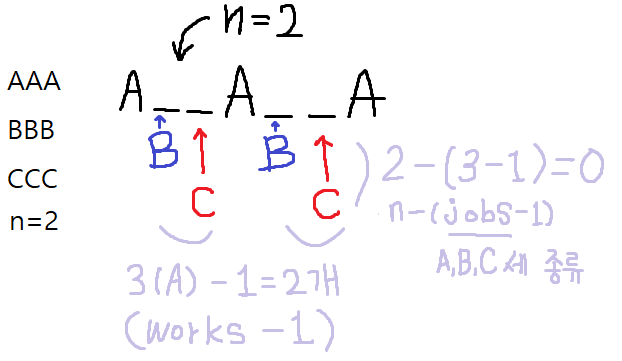
남은 대기 슬롯을 계산할 때 works-1, 가장 많은 작업의 갯수에서 하나를 빼는 이유는 작업 사이의 대기 공간에 다른 작업들을 스케줄링해야 하기 때문이다. 예를 들어 3개의 작업 A가 있다면 A__A__A처럼 작업 사이에 두 개의 대기 공간이 생기기 때문에 하나를 빼주는 것이다.
비슷하게 n-(jobs-1), 대기 시간에서 작업의 종류에 하나를 뺀 값을 빼는 이유는 위에서 언급했듯이 가장 많은 작업이 여러개일 경우 그 옆의 대기 공간에 스케줄링하기 때문이다. 가장 많은 작업 중 하나(A)는 이미 대기 공간을 만들기 위해 스케줄링됐기 때문에 이를 빼고 나머지 작업들을 스케줄링해야 하기 위해서다.
이 둘을 곱하면 풀이의 핵심인 필요한 대기 슬롯의 갯수를 구할 수 있다. 대기 슬롯에 배치할 작업의 갯수를 구해야 하는데 [A, A, A, B, B, B, ...]처럼 가장 많은 작업이 여러 개 있을 경우 이 작업들은 미리 대기 슬롯에 배치해야 한다. 그래서 대기 슬롯에 배치할 작업의 갯수를 구할 때 전체 작업에서 가장 많은 작업(3개)의 모든 작업(A, B 2개)을 곱한 만큼 빼면 된다. 위의 예시에서 A 옆에 B, B 옆에 C를 스케줄링하던 그림을 보면 이해할 수 있을 것이다.
최종적으로 대기 슬롯에서 대기 슬롯에 스케줄링되는 작업을 빼면 작업 외에 대기 슬롯이 얼마나 필요한 지 알 수 있다. 모든 작업을 처리하는 것 외에 필요한 대기 시간을 구하려면 모든 작업의 갯수에 이 대기 슬롯의 크기를 더하면 된다. 이를 그림으로 나타내면 다음과 같다.
 [A, A, A, B, B, B, C, C, C]와 대기 시간 2의 작업을 나타낸 그림에서 볼 수 있듯이 작업 A를 스케줄링해서 얻은 4개의 대기 공간에는 다른 작업들이 모두 들어올 수 있고 남은 작업들도 없기 때문에 대기 시간은 필요하지 않다.
[A, A, A, B, B, B, C, C, C]와 대기 시간 2의 작업을 나타낸 그림에서 볼 수 있듯이 작업 A를 스케줄링해서 얻은 4개의 대기 공간에는 다른 작업들이 모두 들어올 수 있고 남은 작업들도 없기 때문에 대기 시간은 필요하지 않다.
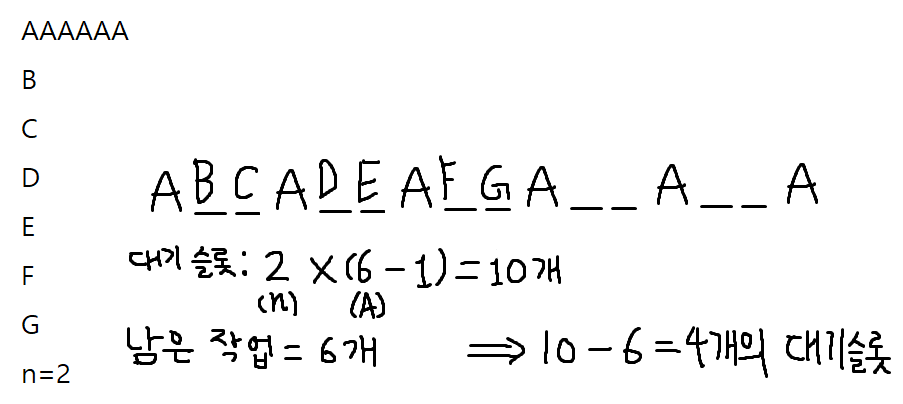 비슷하게 [A, A, A, A, A, A, B, C, D, E, F, G]와 대기 시간 2의 작업 스케줄링은 위처럼 계산될 수 있다. 이 경우 4개의 대기 슬롯이 추가적으로 필요하기 때문에 전체 작업의 갯수(12)에 4를 더한 16이 모든 작업을 처리하는 데 걸리는 시간이 된다.
비슷하게 [A, A, A, A, A, A, B, C, D, E, F, G]와 대기 시간 2의 작업 스케줄링은 위처럼 계산될 수 있다. 이 경우 4개의 대기 슬롯이 추가적으로 필요하기 때문에 전체 작업의 갯수(12)에 4를 더한 16이 모든 작업을 처리하는 데 걸리는 시간이 된다.
이를 기반으로 구현한 코드는 다음과 같다.
import collections
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
# 작업 목록 등록.
jobs = collections.defaultdict(int)
for task in tasks:
jobs[task] += 1
# 연산을 위해 각 작업 별 갯수를 리스트로 변환.
counts = list(jobs.values())
# 가장 많은 작업의 갯수는 얼마나 되는지
works = max(counts)
# 가장 많은 작업의 종류는 얼마나 되는지
jobs = counts.count(works)
# 가장 많은 작업 사이에 대기 슬롯 배치 및 미리 가장 많은 작업 등록.
waitingSlots = (works - 1) * (n - (jobs - 1))
# 남은 대기 슬롯에 들어가야 할 작업들의 갯수
processedJobs = len(tasks) - jobs * works
# 작업들을 다 담고 남은 대기 슬롯들의 갯수
# 작업이 더 많다면 뺄셈 연산에 의해 음수가 되기 때문에 예외 처리.
remainWaitingSlots = max(0, waitingSlots - processedJobs)
# 전체 작업의 갯수 + 필요한 대기 슬롯의 갯수 반환.
return len(tasks) + remainWaitingSlots훨씬 더 간단하면서도 빠른 성능을 얻을 수 있었다. 상위권 풀이를 보니 대부분 이런 식으로 푼 것 같다.
후기
미리 주어진 작업을 스케줄링한다는 점에서, 그리고 최대 1만 개의 작업을 처리해야 한다는 점에서 2번 풀이는 지양했어야 했다. 하지만 3번 풀이같은 분석, 수학 공식을 스스로 찾아내기란 여간 쉽지 않을 것 같다.
다만 작업이 실시간으로 삽입되는 게 아니라 미리 딱 정해져 있기 때문에 계산을 활용할 수 있지 않을까라는 생각을 떠올릴 수 있으면 좋을 것이다.
