설명
프로그래머스의 숫자 게임 문제다.
두 정수 배열이 주어질 때 한 배열을 기준으로 정수를 하나씩 비교해서 더 크면 승점을 얻는 게임이 있을 때 배열의 순서를 조합하여 얻을 수 있는 가장 큰 승점을 반환하는 것이 목적이다.
예를 들어 [5,1,3,7]과 [2,2,6,8]이 주어질 때 [2,2,6,8]을 [8,2,6,2]로 조합하면 최대 점수인 3점을 얻을 수 있다.
배열 1: [ 5 ][ 1 ][ 3 ][ 7 ]
배열 2: [ 8 ][ 2 ][ 6 ][ 2 ]
원소 8은 원소 5보다 크다. 원소 2는 원소 1보다 크다. 원소 6은 원소 3보다 크다. 원소 2는 원소 7보다 작다. 결과적으로 3번 우승하기 때문에 3점을 얻을 수 있는 것이다.
풀이
DFS(실패)
처음으로 시도했던 방법은 이 배열을 트리처럼 구축해서 첫 번째 원소부터 마지막 원소까지 모든 조합을 시도해보면서 최고 점수를 계산하는 방법이었다. 이를 위해서는 아래와 같은 트리 구조로 노드를 구축하여 각 노드의 높이에 맞는 배열의 원소끼리 비교하여 점수를 증가시켰다.
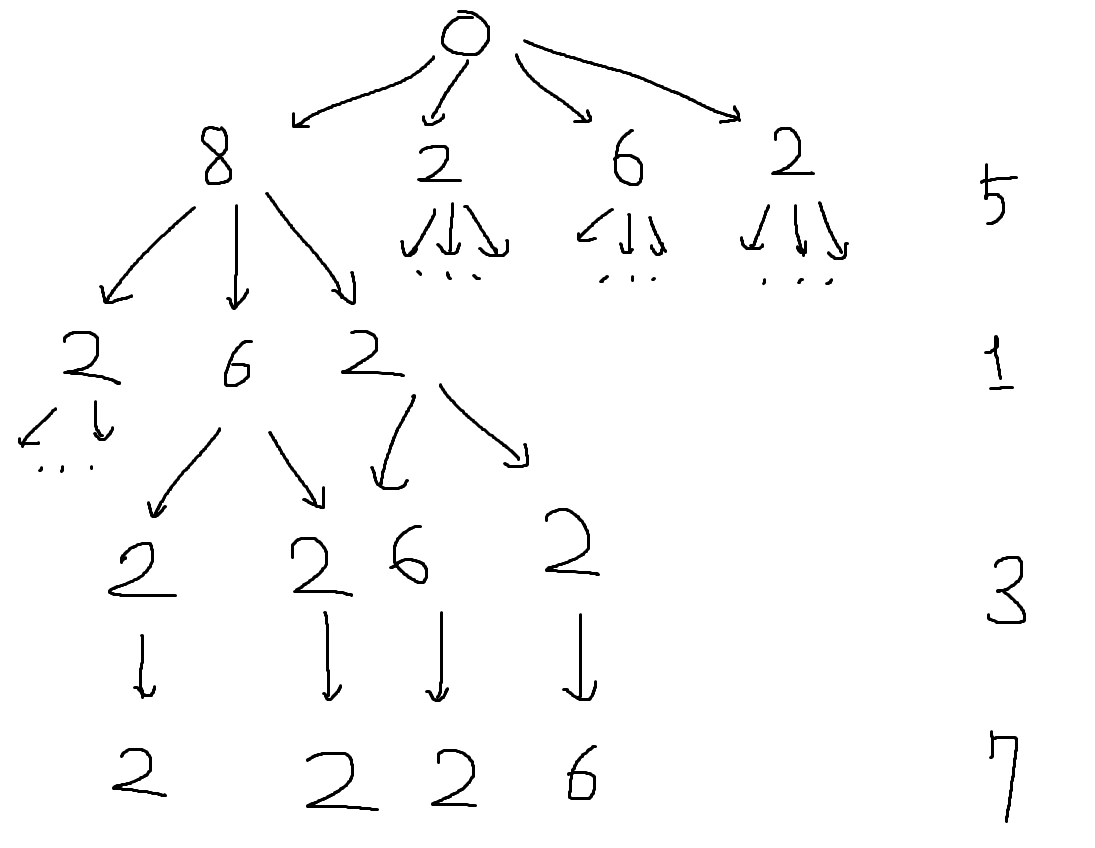 트리의 각 노드를 탐색하면서 비교 대상 배열(위의 예제에서는 [5, 1, 3, 7])과 비교하면 8, 2, 6, 2 시점에서 3점으로 최대 점수를 갱신할 수 있다. 그리고 나머지 노드에서는 현재까지의 얻은 점수와 앞으로 얻을 수 있는 모든 점수를 계산해서 최대 점수를 넘지 못한다면 더이상 탐색하지 않는 식으로 최적화하였다.
트리의 각 노드를 탐색하면서 비교 대상 배열(위의 예제에서는 [5, 1, 3, 7])과 비교하면 8, 2, 6, 2 시점에서 3점으로 최대 점수를 갱신할 수 있다. 그리고 나머지 노드에서는 현재까지의 얻은 점수와 앞으로 얻을 수 있는 모든 점수를 계산해서 최대 점수를 넘지 못한다면 더이상 탐색하지 않는 식으로 최적화하였다.
이를 구현한 코드는 다음과 같다.
import collections
# 최고 점수를 저장하는 전역 변수.
highestScore = 0
# DFS 함수에서 비교 대상 배열에 접근하기 위한 전역 변수.
competitors = None
# 최고 점수 탐색.
def findHighestScore(nodes, usedCount, currentScore):
global highestScore
global competitors
# 만약 앞으로 얻을 수 있는 점수가 최고점을 넘지 못한다면 탐색 종료.
# 승점은 1점씩이기 때문에 노드의 갯수로만 비교해도 점수로 취급할 수 있음.
if (len(nodes) - usedCount + currentScore) <= highestScore:
return
# 필요 시 최고 점수 갱신.
highestScore = max(highestScore, currentScore)
# 모든 노드를 탐색했을 경우 즉 모든 원소를 비교했을 경우 탐색 종료.
if usedCount == len(nodes):
return
# 다음 원소와 비교할 조합 생성.
for index, node in enumerate(nodes):
# -1로 설정된 원소는 이미 부모 노드에서 비교하는데 사용된 값.
if node < 0:
continue
# 자식 노드에서 사용하게 될 원소는 -1로 비활성화 처리.
# 다음 원소랑 비교할 때 기존에 사용한 값은 사용하지 않도록 하기 위함.
_nodes = nodes.copy()
_nodes[index] = -1
# 비교 대상 배열의 원소와 비교하여 누적 점수 갱신.
# usedCount 변수는 트리에서 현재 노드의 높이와 동일하며
# 비교 대상 배열에서 비교할 원소의 인덱스와도 동일함.
findHighestScore(_nodes, usedCount+1, currentScore+1 if node > competitors[usedCount] else currentScore)
def solution(A, B):
global highestScore
global competitors
# 비교 대상 배열에 A 등록.
competitors = A
# 맨 처음 원소부터 비교하여 탐색 시작.
for index, b in enumerate(B):
_B = B.copy()
_B[index] = -1
findHighestScore(_B, 1, 1 if b > A[0] else 0)
# 최고 점수 반환.
return highestScore이론상으로는 가능한 방법이었지만 문제에서 간과했던 점이 배열 A, B는 1부터 100000개까지 주어질 수 있다는 점이었다. 위의 DFS 탐색에서는 배열의 크기가 수십개만 되도 탐색해야 할 노드가 기하급수적으로 늘어나기 때문에 계속 시간초과 문제가 발생했다.
Sort(성공)
그래서 풀이를 찾아보니 배열을 정렬한 후 처음부터 하나씩 비교해나가는 풀이로 구현한 것을 많이 볼 수 있었다. 아쉬웠던 점은 나도 처음 시도한 풀이에서 해답에 거의 근접했었다는 것이다. 문제에서는 배열 A는 고정되어 있고 배열 B의 원소들을 조합하여 가장 높은 승점을 계산해보라고 했기 때문에 배열 B의 원소들을 어떤 순서로 비교하던지 상관이 없었다. 그래서 둘 다 정렬해서 각 원소가 어느쪽이 더 큰지 비교하는 방식으로 시도했었다.
그러나 그때는 단순히 sort 메서드로 정렬한 후 배열의 원소들을 그대로 비교하는 방식으로 구현했었다. 그렇기 때문에 다음과 같은 경우를 처리할 수 없었다.
배열 1: [ 2 ][ 3 ][ 4 ][ 5 ][ 6 ][ 7 ]
배열 2: [ 3 ][ 4 ][ 5 ][ 6 ][ 2 ][ 7 ]
배열 1과 배열 2는 완전히 같은 원소(2, 3, 4, 5, 6, 7)들로 이루어져 있다. 그래서 두 배열을 정렬해서 비교하면 같은 원소들끼리 비교하기 때문에 0점으로 계산되지만 실제로는 다음과 같이 조합해서 5점을 얻을 수 있다.
배열 1: [ 2 ][ 3 ][ 4 ][ 5 ][ 6 ][ 7 ]
배열 2: [ 3 ][ 4 ][ 5 ][ 6 ][ 7 ][ 2 ]
여기서 이런 풀이를 포기하고 DFS로 건너갔던 것 같은데 만약 두 배열에 인덱스를 두고 하나씩 비교하는 방식으로 접근했다면 쉽게 풀 수 있었던 문제였다. 이 방식의 코드는 다음과 같다.
def solution(A, B):
# 만약 원소 1에 대해 승점을 얻기 위해 원소 7을 사용한다면 낭비일 것이다.
# 하지만 원소 1에 대해 원소 2를 사용한다면 제일 효율적일 것이다.
# 즉 원소 n과 비교하기 위해 n+1부터 하나씩 비교하기 위해 두 배열을 정렬한다.
A.sort()
B.sort()
# A의 제일 작은 원소가 B의 제일 큰 원소보다 크다면 B가 얻을 수 있는 점수는 없다.
# 구현되어 있진 않지만 반대의 경우도 이렇게 예외로 처리할 수 있을 것이다.
if A[0] > B[-1]:
return 0
# 점수, 비교를 위한 인덱스 변수.
answer = 0
indexA, indexB = 0, 0
# 두 배열의 원소를 하나씩 비교하며 B의 원소가 A의 원소보다 크다면 점수 증가.
while indexA < len(A) and indexB < len(B):
if B[indexB] > A[indexA]:
indexA += 1
answer += 1
indexB += 1
# 최종 점수 반환.
return answer후기
생각보다 훨씬 간단한 문제였으며 DFS만 고집하다가 많은 시간을 허비하게 된 문제였다. 무조건 복잡한 알고리즘을 쓴다고 좋은 것도 아니고 레벨 3라고 해서 항상 어려운 알고리즘을 요구하는 것도 아니란 걸 느낄 수 있었다.
