Deep Dive Into LLM
LLM Training
주요 단계
1. Pre-Training
- 설명: 인터넷 텍스트에서 대규모 데이터를 수집해 모델에게 "Next Token Prediction"을 학습.
- 결과물: 인터넷 텍스트 흐름을 확률적으로 흉내 내는 Base Model
2. Supervised Fine-Tunning(SFT)
- 설명: 대화형태("사용자-어시스턴스"쌍)의 고품질 데이터를 보정해, 모델이 "대화형 어시스턴스" 역할을 하도록 추가 학습
- 이 단계부터 General 한 Model을 만들거나 특화된 Model로 SFT
- 결과물: 실제 질문에 대답해주는 Instruct Model
3. RL, RLHF, Post-Training
- 설명: 답변을 실제로 평가(정답 비교 혹 인간의 피드백) 뒤, "점수를 높이는 방식"으로 모델이 스스로 똑똑해지도록 학습
- 수학 문제와 같이 명확한 정답이 있을 경우 "강화학습"으로 모델이 스스로 만든 다양한 풀이를 발견하게 가능함. (DeepSeek R1)
- 시/소설/요약과 같이 정답이 명확하지 않은 경우 인간 평가가 주로 수행되며, Reward Model을 훈련해 이를 기준으로 하는 RLHF 방식을 사용
(1) Pre-Training
바닥부터 모델을 굽기.
a. Prepare Data-Set: FineWeb
Pre-train 단계에서는 엄청난 데이터 양이 필수, Foundation Model을 굽는 회사(ex. OpenAI, Google ...)은 양질의 큰 Data-Set을 구성
이러한 역할을 하는 Open Data-Set 중 하나는 HuggingFace FineWeb
FineWeb Recipe
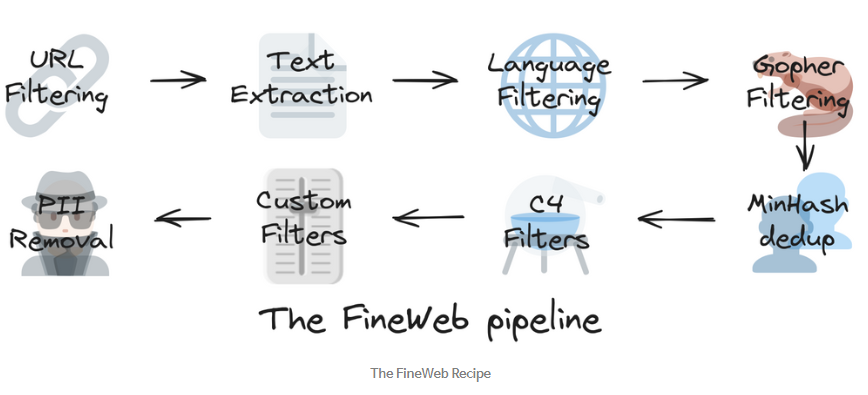
작업 과정:
- 스팸/악성/음란성/품질 낮은 사이트 제외(블랙리스트 필터링)
- HTML 태그 제거 후 순수 텍스트만 추출
- 언어 classifier로 영어 텍스트만 남기거나, multi-lingual 타겟인 경우 다양한 언어를 비율에 맞춰 조절
- 개인정보나 중복 문서 제거 등
토큰 수: 15T tokens
데이터 크기: 44TB
b. Tokenize Text
수 많은 글을 토큰 단위로 쪼개야함. 인간 기준으로 "단어"로 재정의 한다고 이해하면 된다. 토큰화하는 방식은 목적에 따라 다르며, 같은 모델이어도 버전마다 호환이 잘 되지 않는다.
(ex. (0,1), utf-8 ...)
관련 링크: https://tiktokenizer.vercel.app/
c. Next Token Prediction: Neural Net I/O
Info
LLM: Predicts what the next token will be among all possible tokens.
Current LLM Model: Decoder-Only Transformer
Transformer
Transformer 게시물: https://velog.io/@park2do/Transformer-Attention
GPT Transformer: https://bbycroft.net/llm
d. Base Model - Intruction Model
CPT (Continued Pre-Training)
파인 튜닝 과정에서 기존 사전 훈련된 모델을 특정 도메인 또는 특정 작업에 맞게 추가적으로 사전 학습하는 과정
Base Model과 Instruction Model을 구분하는 이유
Intruction 모델에 CPT를 하려고 할 때, 추가 도메인 지식이나 작업이 잘 적용되지 않음.
Base Model에 따로 SFT나 RL을 진행해야함.
https://www.hyperbolic.ai/
(2) SFT
SFT 단계는, LLM이 "질문-답변" 형태의 사용자가 원하는 포맷으로 대화하는 능력을 만들어주는 단계.
a. Instruction Tunning
사람이 만든(혹은 편집한) 대화형 데이터(User-Assistant)를 모델이 직접 학습하게 하면, 모델이 "대화"를 흉내내는 어시스턴트가 됨.
Multi Turn Conversation: 대화 데이터, 대본
- 역할
- SOS, EOS
Multi Turn DataSet:
- 수작업: https://huggingface.co/datasets/OpenAssistant/oasst1
- 자동화: https://github.com/thunlp/UltraChat
- Synthetic: Alpaca
b. Hallucination Problem
- I Don't Know
- Tool Use
c. Giving Identification
- System Prompt
d. Supervised finetuning to Reinforcement Learning
- How many 'r's in strawberry?
- Which is bigger, 9.11 or 9.9s
(3) Reinforcement Learning
이전 Learning 방식을 비교하면,
Pretraining - 책을 읽는 것
Supervised Finetuning - 예제 문제와 이미 작성된 해설을 보는 것
Reinforcement Learning - 해설이 없는 문제를 직접 풀어보는 것.
a. DeepSeek R3 RL
Just gives ANSWER and QUESTION, makes the solution approach in various ways.
Incentivizing Reasoning Capability in LLM
Step (meaning in RL): Trying to Solving a Problem(Question).
Incentive Learning: 보상 개념을 통해 머신러닝을 진행하는 것. 보상이 높은 방식으로 다시 학습을 함.
이렇게 진행했더니 답변을 길게 할 수록 맞출 확률이 높아지며, 그렇게 진화됨.
수학 문제를 풀 때, 풀이과정을 구체적으로 작성하는 것과 비슷한 원리.
많이 알아서 답변을 길게 하는 것이 아니라, 답변에 접근을 길게 하면서 생각을 하는 것.
AHA moment: RL만 했음에도 혼자 써내려가면서, 다양한 생각의 변곡점을 스스로 만드는 것. 다양한 방법을 추론 (Reasoning Model)
b. Alphago RL
MCTS: Monte Carlo Tree Search
MCTS 관련 링크: https://gusals1620.tistory.com/3
SL Policy: 지도학습 -> 사람이 두었던 기보를 기반으로 학습
RL Policy: 강화학습 -> 사람이 두었던 기보를 기반으로 기계끼리 대국을 하며 더 나은 수에 대한 기보를 학습 -> 사용한 알고리즘: Reinforece
Value Network: RL Policy를 따랐을 때 누가 이길지 예측하는 네트워크
https://www.youtube.com/watch?v=a4H-P10pVz4
c. Distillation
RL을 통해서 생긴 풀이과정을 SFT 과정을 생략하고 Pre-Training 모델에서 직접적으로 RL을 완료한 모델을 thinking을 학습시키면 SFT과정을 생략하고 RL과 비슷한 성능을 낼 수 있다.
d. RLHF Reinfrocement Learning by Human Feedback
Reward Model: RL 단계에서 사람이 직접 모든 것을 평가하기 어렵기 때문에 사람을 기반으로 평가를 해주는 모델.
Reward Model을 사용한 RLHF(PPO)의 단점은 RL이지만 포텐셜이 RL이 아니라는 것.
Reward Model이 실제 사람과의 Align이 완벽하지 않기 때문에, LLM이 RewardModel을 해킹하는 개념으로, 너무 잘 뚫어버린다. (RewardModel이 점수를 잘주는 방식을 쉽게 만들어낸다.)
현 시점으로는 그렇기 때문에 학습하다 중간에 멈춰야한다.
RLHF의 두가지 방식
PPO (Proximal Policy Optimization)
- Reward Model이 준 점수를 최대화하려고 정책을 강화학습으로 조정함.
DPO (Direct Preference Optimization) - 인간이 선호한 응답 쪽의 확률을 더 높이도록 직접 최적화함.
- 보상 모델 없이, 단순한 응답 쌍 비교로 학습 가능.
출처:
https://sudormrf.run/2025/02/27/pretraining/
https://sudormrf.run/2025/02/27/reinforcement-learning/
