❗Database Replication?
쉽게 말해 2개 이상의 DBMS에 동일한 데이터를 저장하는 전략이다.
가령 2개의 DBMS 가 존재한다면 하나는 Master, 다른 하나는 Slave 로 지칭하는 구조인데, 초기에 Master DBMS로 들어온 Query 를 logging 한 데이터를 Slave 에게 넘겨줘서 완전히 동일한 데이터를 생성하도록 한다.
이렇게 2개의 DBMS 를 운영하며 Query의 부하분산을 실현하는 것이 이 구조의 목적이다.
😐 Why???
역할 배분
자료를 조사하면서 제일 처음 들었던 의문은 2개의 동일한 데이터가 중복으로 존재하는데 오히려 비효율적인 구조 아닌가? 하는 생각이 들었다. 데이터를 빠르게 찾고자 하는데 또 다른 DB를 구축하는게 무슨 도움이 될까?
정답은 DBMS 역할의 배분에 있었다.
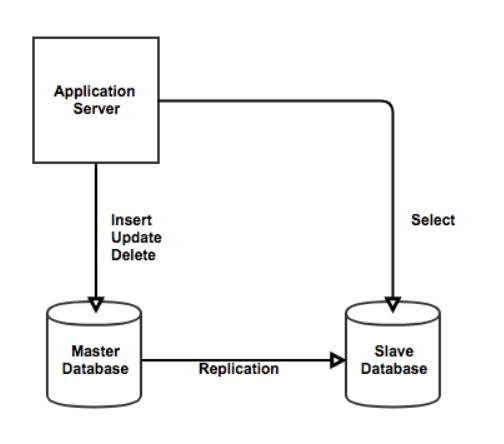
위의 그림처럼 Master DB 는 Insert/Update/Delete Query만을 수행하고
Slave DB 는 Select Query 를 수행한다는 점인데
DB 부하를 일으키는 주된 원인이 Select query 이기 때문이다.(평균 약 60%의 query 가 Select 문임)
따라서 비중이 큰 Select query만을 수행할 DBMS 를 따로 둠으로써 부하를 분산한다.
비동기 처리
중복된 데이터가 존재하기 때문에 데이터 무결성을 위해 동기적 처리를 수행한다고 생각하기 쉽다.
하지만, replication 은 비동기 방식(log 자체가 무결성의 데이터를 의미하므로)으로 진행되어 지연 속도를 최소화 한다.
다만 log 자체도 여전히 100% 무결한 데이터는 아니기 때문에 100% 동기화를 보장할순 없다.
단점이 존재함에도 Replication 방식이 선호되는 이유는
DB 성능 향상에 큰 도움이 되고, DB 자체적으로 데이터의 무결성을 위해 내부적인 처리를 진행하여 Replication 동작에 큰 오류는 없기 때문이다.
확실한 데이터의 동기화를 보장하기 위해서는 Clustering 방식을 사용하기도 한다.
