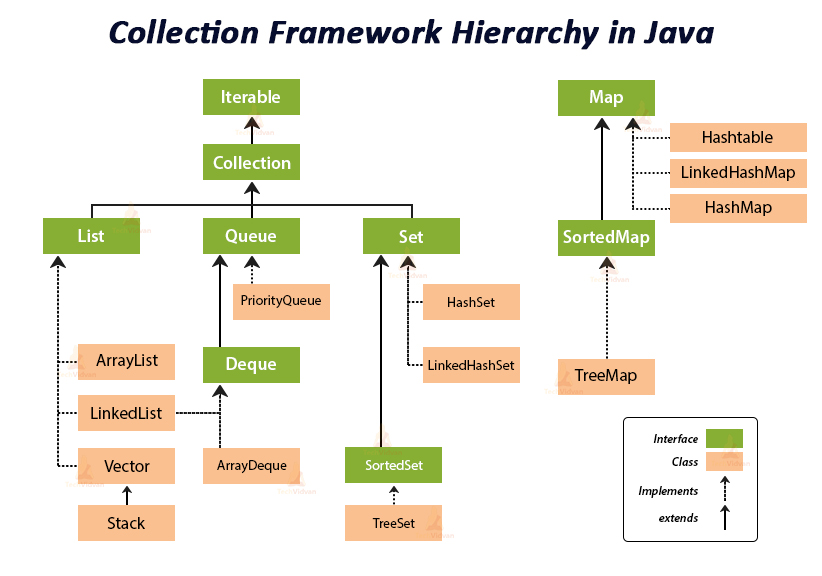
Collection
Collection 은 기본적으로 데이터의 모음을 다루고자 만들어진 인터페이스이다.
Collection 구현 클래스들은 데이터가 저장된 방식에 따라서 다시
List / Queue / Set 으로 나누어진다.
List
List 는 데이터를 순서가 있는 방식으로 저장한다.
대표적으로 ArrayList / LinkedList 을 자주 사용한다.
ArrayList 는 내부적으로는 배열로 구현되어 있으나 정적 배열과는 다르게 동적 으로 크기가 변한다는 차이가 있다.
동적으로 크기가 변하기 때문에 정적 배열처럼 컴파일 단계에서 크기를 지정해줄 필요가 없으니 유용하다는 장점이 있다.
하지만 내부 코드를 살펴보면, 일정 capacity 가 넘어가면 새로운 배열에 기존의 값들을 Arrays.copyOf 해주고, 삭제는 target Index 전 후로 Array 를 잘라 붙이는 System.arraycopy 를 해주기 때문에
삽입/삭제의 빈도가 높을 경우에는 다소 비효율적인 자료구조이다.
해당 단점을 보완하고자 존재하는 자료구조가 LinkedList 이다
말 그대로 연결리스트를 통해 값의 주소를 참조하고 있기 때문에 List 의 사이즈가 필요하지도 않고, 삽입 삭제시에 포인터 주소만 변경하면 되기 때문에 삽입/삭제시에 매우 유리하다.
단 Index 가 존재하지 않기 때문에, 데이터 검색 속도는 느리다.
Queue
맨 위 표를 보면 알 수 있듯이 LinkedList 와 Array 구조를 통해 Deque 를 구현할 수도 있다.
내가 자주 쓴 방식은
LinkedList 를 통한 일반적인 FIFO Queue
Min/Max Heap 구조를 사용하여 데이터 삽입/삭제가 이루어지면서도 가장 극값을 찾아내고 싶을 때 사용하는 Priority Queue 가 있다.
Queue 는 자주 접할 수 있는 자료형이기 때문에 설명은 생략하고
Min/Max Heap 같은 경우에는 말 그대로 Min/Max 값을 항상 O(logN) 으로 찾아낼 수 있다.
엄밀히 이야기 하자면 트리를 재구성 하는데 O(logN) 이고, 딱 필요한 값을 뽑아내는건 root 에 있는 값을 참조만하면 되니 O(1) 이 되겠다.
간혹 Priority Queue 의 시간복잡도는 O(NlogN) 으로 퉁치는 글들을 자주 접할 수 있는데, 개인적으로 잘못된 설명이라고 생각한다.
물론 N 개의 데이터에 대해 Heap 구조를 짜라~ 라고 한다면 O(NlogN) 으로 설명할 수 있다.
하지만 Min/Max Heap 의 핵심 목표는 주어진 데이터로 Heap 구조를 짜는게 아니라, 특정 시점에서 Min/Max 를 찾고, 다시 트리를 재구성 하는 것 이다.
설명이 부족할까봐 좀 더 이야기 하자면, 전체 데이터를 놓고 Heap 구조를 짤거면 사실 그냥 데이터를 정렬하는게 오히려 나을 수 있다. 하지만 특정 시점마다 데이터가 정렬된 상태를 보장해야한다면? 매 시점마다 정렬을 수행하는건 불가능하다. 이런 경우를 위해서 Heap 구조를 사용하는 것이라고 생각한다.
Map/Set
Map 과 Set 은 항상 붙어서 나올 수 밖에 없는데 왜냐하면 Set 을 Map 으로 구현하기 때문이다.
라고 한다면 Collection 구현체인데 어떻게 Map 이 또 구현하는가? 의문이 들 수 있다.
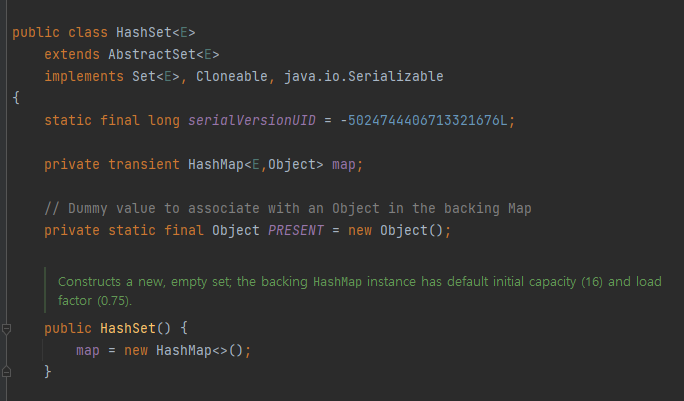
실제로 내부 코드를 보면 SetsomeObject 를 생성하면 MapsomeObject, Object 가 생성되는 것을 확인할 수 있고, 모든 동작이 Set 객체의 필드인 map 변수를 사용한다는 것을 확인할 수 있다.
즉 Set 이 Collection 구현체라는 것은 Collection 스펙(역할) 을 만족해야한다는 것이고, 역할 자체의 구현방식은 map 을 통해서 구현한다는 것이다.
이 부분을 정리하면서, 다시금 객체 지향의 캡슐화와 메세징을 상기할 수 있었는데, 외부에서 내부가 어떻게 구현 됐는지는 별 상관없고(캡슐화), Set 은 모든 역할을 map 에게 위임하는 방식(메세징) 을 택한다는 것이다.
그래서 Map 관련 객체는 stream 객체로 바로 전환할 수 없다. 왜 그런가 상상을 해보자면, stream 은 똘똘 뭉쳐 있는 원소모임(Collection)의 포장지를 뜯는 느낌인데, Map 객체 자체는 뭘 기준으로 뜯어야할지 잘 모르겠다. Key ? Value ? 어느 하나를 정할 수 없다.
하지만 entrySet 로 변환한다면 Map 객체의 모임이 되고, 지금 부터는 stream 으로 포장지를 벗길 수 있을 것이다.
내부적으로 Set 이 어떻게 작동하는지 설명을 간략하게 하자면, 우선 객체를 모으는 과정해서, 객체간 식별자가 필요할텐데 이를 Object.hashCode():int 로 계산한다.
정리
Collection 객체는 데이터의 모음을 표현하는 객체다. 크게 List / Queue / Set 으로 나눌 수 있고, 이 셋은 데이터를 모을 때 무엇을 중시하냐에 따라서 구분할 수 있다.
List 구현체는 데이터의 순서를 중요시한다.
Queue 구현체는 데이터의 순서도 중요하지만, 그 보다는 좀 더 삽입/삭제 시의 데이터 활용성에 초점을 둔 객체다.
Set/Map 구현체는 데이터간 식별해서 저장하는데 초점을 두고 있다.
