들어가며
1장에서는 한 명의 사용자를 지원하는 시스템부터 최종적으로는 몇백만 사용자를 지원하는 시스템으로 발전하는 과정을 담고 있습니다. 발전해 나가는 과정을 보며, 규모 확장성과 관련된 설계 문제를 푸는데 유용한 지식들을 얻어갈 수 있는 챕터입니다.
단일 서버
우선, 가장 간단한 단일 서버를 설계하는 과정에서 시작합니다. 일반적으로 다음 그림과 같이 하나의 서버에서 웹 서버, 데이터베이스, 캐시 등 전부 실행됩니다.
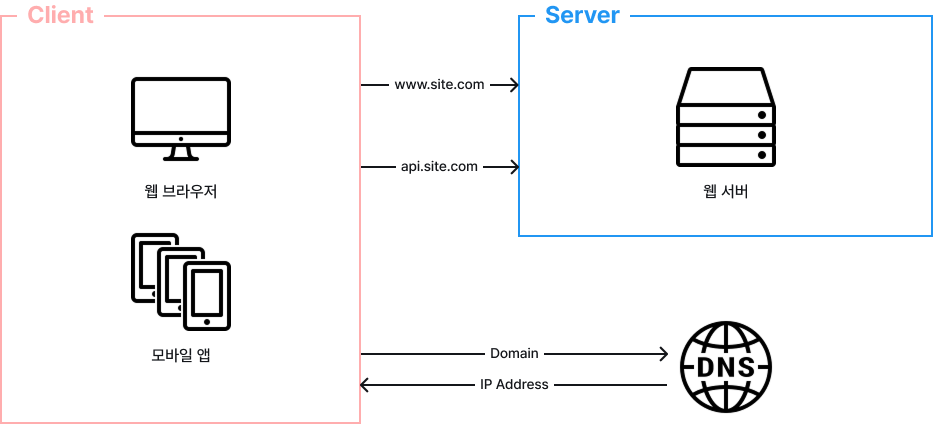
위 그림을 이해하기 위해선 사용자 요청이 처리되는 과정과 요청을 만드는 단말에 대한 이해가 필요합니다. 사용자 요청이 어떻게 처리되는지 흐름을 살펴보도록 하겠습니다.
사용자 요청 처리 흐름에 대한 이해
첫 번째, 사용자는 도메인 이름을 이용하여 웹 사이트에 접속합니다.
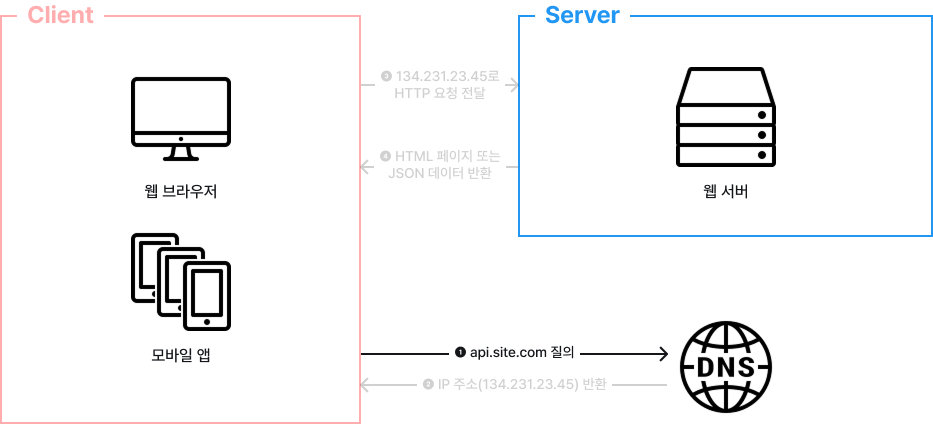
이 접속을 위해서는 도메인 이름을 DNS에 질의하여 IP 주소로 변환하는 과정이 필요합니다. DNS는 보통 서드 파티가 제공하는 유료 서비스를 이용하게 되므로, 시스템의 일부는 아닙니다.
두 번째, DNS 조회 결과로 IP 주소 반환됩니다.
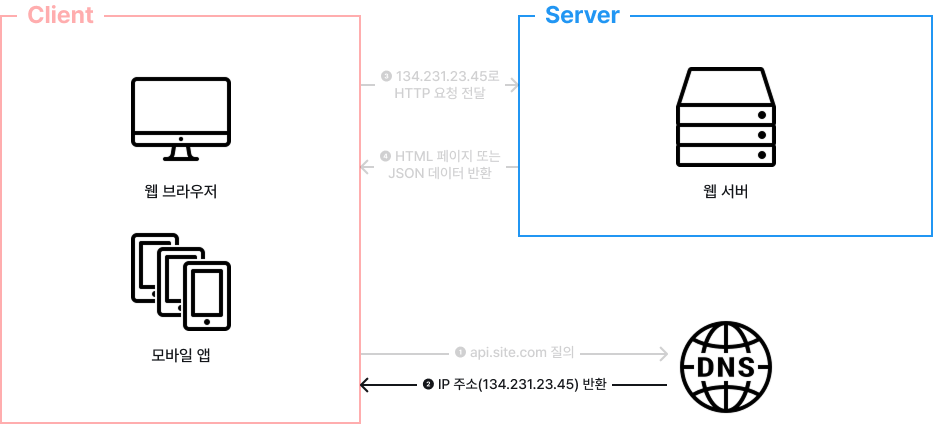
해당 그림에서는 134.231.23.45라고 되어있습니다. 이 주소는 웹 서버의 주소를 의미합니다.
세 번째, IP 주소로 HTTP 요청을 전달합니다.
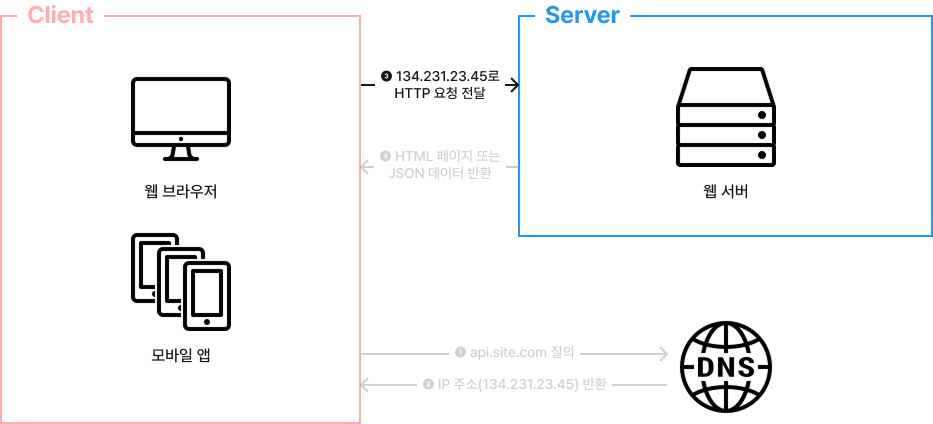
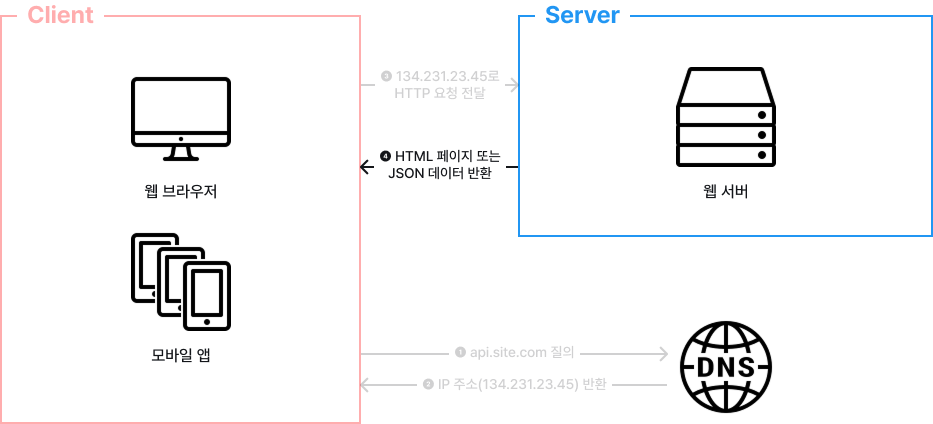
네 번째, 요청을 받은 웹 서버는 HTML 페이지 또는 JSON 형태의 응답을 반환합니다.
데이터베이스
사용자가 증가하면 서버 하나로는 충분하지 않아서 여러 서버를 두어야 합니다. 하나는 웹/모바일 트래픽 처리 용도로, 다른 하나는 데이터베이스 처리 용도로 사용합니다.
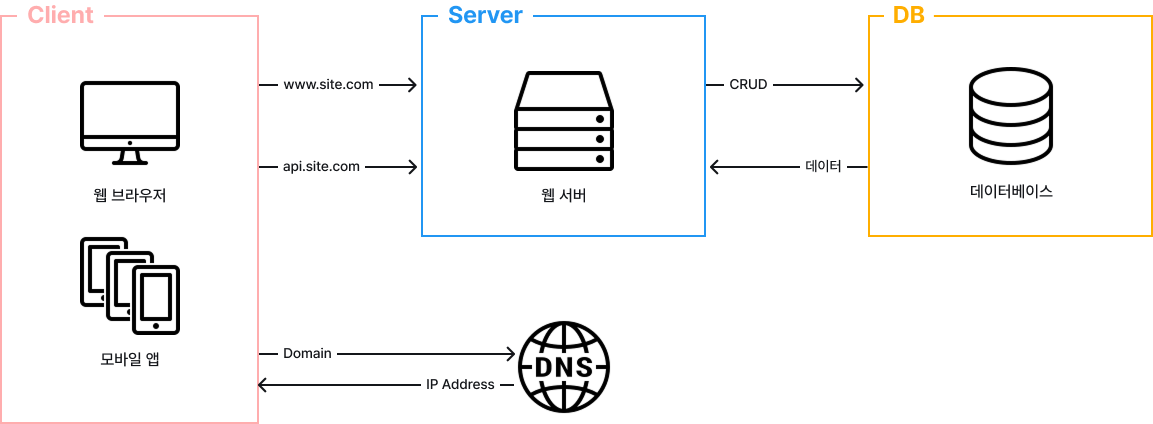
이렇게 웹 계층과 데이터 계층으로 서버를 분리하면 그 각각을 독립적으로 확장해 나갈 수 있습니다.
어떤 데이터베이스를 사용할 것 인가?
데이터베이스는 크게 관계형과 비-관계형으로 구분됩니다. 차이는 다음과 같습니다.
관계형 데이터베이스 (RDB)
종류는 MySQL, Oracle, PostgreSQL 등이 있으며, 데이터를 테이블과 열, 컬럼으로 표현합니다. SQL을 사용하면 여러 테이블에 있는 데이터를 그 관계에 따라 Join하여 합칠 수 있습니다.
비-관계형 데이터베이스 (NoSQL)
종류는 CouchDB, Cassandra, DynamoDB 등이 있습니다. NoSQL의 경우 다시 네 부류로 나눌 수 있는데 키-값 저장소, 그래프 저장소, 컬럼 저장소, 문서 저장소입니다. 이러한 NoSQL은 일반적으로 Join 연산은 지원하지 않습니다.
일반적으로 RDB를 선택해 사용하지만, 다음과 같은 경우 NoSQL 사용을 고려해 볼 수 있습니다.
- 낮은 응답 지연시간이 요구되는 상황
- 비정형 데이터를 다루는 상황
- 데이터에 대한 직렬화 또는 역직렬화만 요구되는 상황
- 데이터의 양이 아주 많은 상황
Scale Up VS Scale Out
Scale Up은 수직적 규모 확장으로 서버의 HW(CPU, RAM)을 업그레이드 하는 것을 말하고, Scale Out은 수평적 확장으로 더 많은 서버를 추가하여 성능을 분산하는 것을 말합니다.
서버로 유입되는 트래픽 양이 적을 때는 Scale Up이 가장 단순하기에 좋은 방법이지만, 다음과 같은 심각한 단점이 있습니다.
- 한계가 존재함
- 한 대의 서버에 CPU, RAM 등 HW 자원을 무한대로 증설할 방법은 없음
- 자동 복구 방안이나 다중화 방안은 없음
- 서버 장애가 발생하면 웹 사이트나 앱은 완전 중단
이러한 단점 때문에, 대규모 애플리케이션을 지원하는 데는 Scale Out을 사용하는 것이 적절합니다.
현재까지 설명하고 있었던 설계의 경우 사용자는 웹 서버에 바로 연결됩니다. 웹 서버가 다운되면 사용자는 접속할 수 없습니다. 또한, 너무 많은 사용자가 접속하여 웹 서버의 한계 상황에 도달 시 응답 속도가 느려지거나 서버 접속이 불가능해 질 수 있습니다. 이러한 문제를 해결하는 데는 부하 분산기 또는 로드밸런서를 도입하는 것이 최선입니다.
로드밸런서
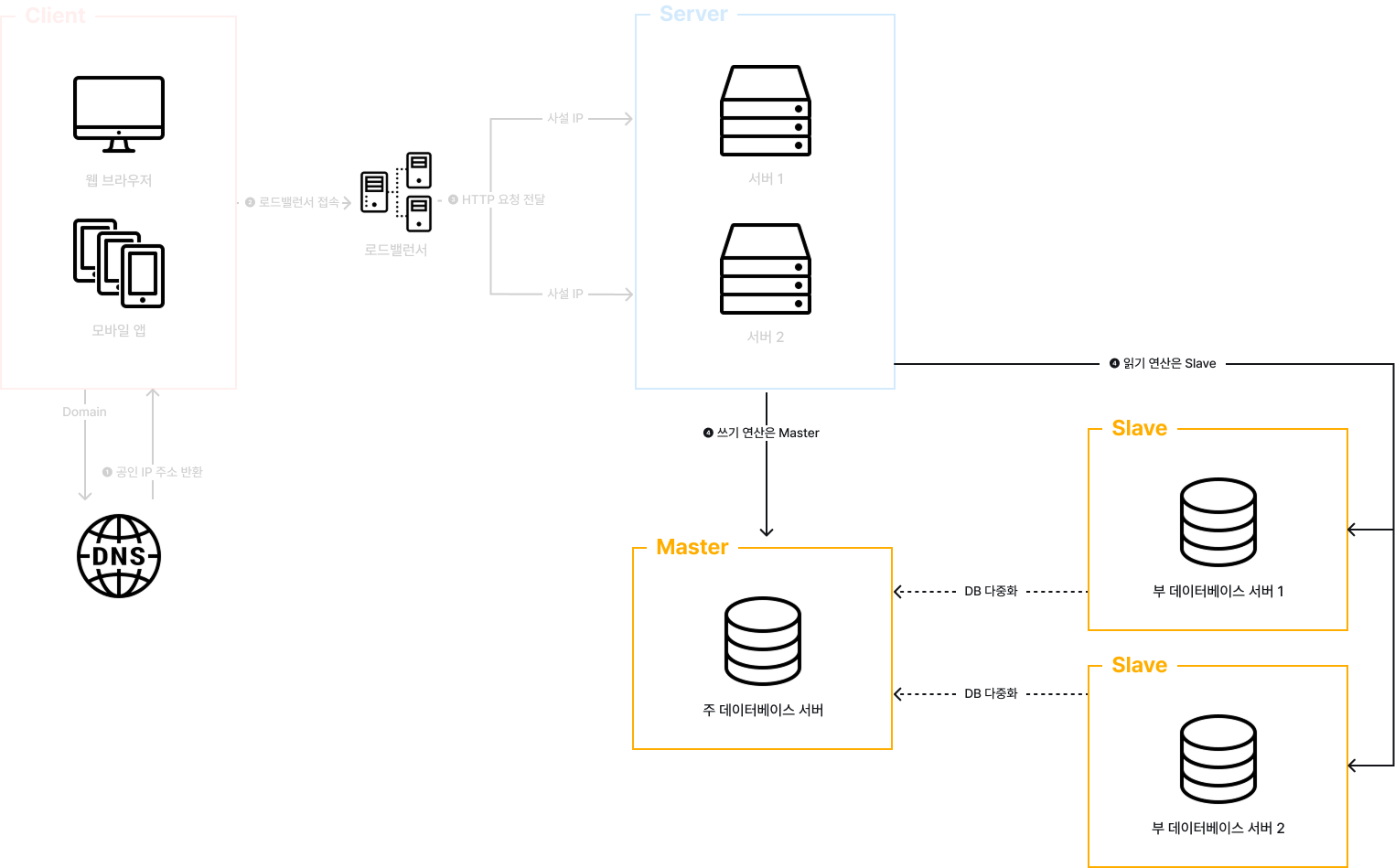
로드밸런서는 부하 분산 집합에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할을 수행합니다. 다음 그림을 참고하면 좋을 것 같습니다.
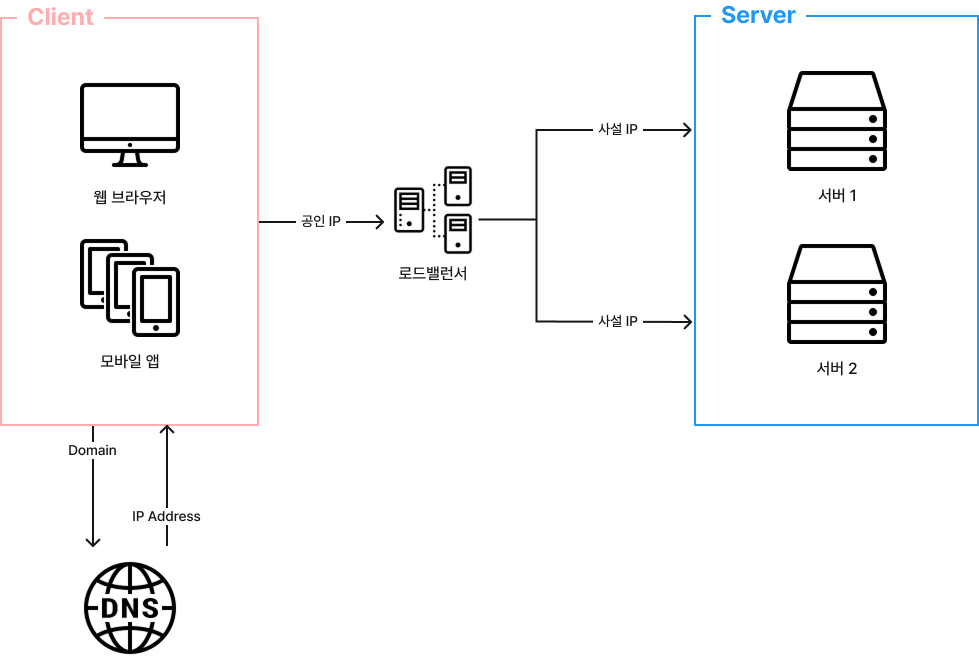
사용자는 우선 공개 IP 주소로 접속하게 되어, 웹 서버는 클라이언트의 접속을 직접 처리하지 않습니다. 더 나은 보안을 위해, 서버 간 통신에는 사설 IP 주소가 이용됩니다.
사설 IP 주소란?
같은 네트워크에 속한 서버 사이의 통신에만 쓰일 수 있는 IP 주소로, 인터넷을 통해서는 접속이 불가합니다. 로드밸런서는 웹 서버와 통신하기 위해 바로 이 사설 IP 주소를 이용합니다.
이와 같이 서버를 구성하면 장애를 자동 복구하지 못하는 문제는 해소되며, 웹 계층의 가용성은 향상됩니다. 이에 대해 더 구체적으로 살펴보면 다음과 같습니다.
- 서버 1이 다운되면 모든 트래픽은 서버2로 전송
- 따라서, 웹 사이트 전체가 다운되는 일을 방지
- 웹 사이트로 유입되는 트래픽이 급격하게 증가하면 두 대의 서버로 트래픽을 감당할 수 없는 시점이 발생
- 웹 서버 계층에 더 많은 서버를 추가함으로써 로드밸런서가 자동적으로 트래픽을 분산하여 대처 가능
로드밸런서를 추가함으로써 웹 계층에서의 부하는 해결한 것 같습니다. 하지만, 데이터 계층은 여전히 고가용성을 가지고 있다고 보기엔 어렵습니다. 이를 해결하기 위해, 데이터베이스에 대한 다중화도 필요합니다.
데이터베이스 다중화
데이터베이스의 경우 데이터 원본은 Master 서버에, 사본은 Slave 서버에 저장하는 방식인 Master-Slave 구조를 지원합니다. 이때, Master 서버는 쓰기 연산만 수행하게 되고, Slave는 Master로 부터 받은 사본을 전달 받아 읽기 연산만을 수행합니다. 이를 그림으로 표현하면 다음과 같습니다.
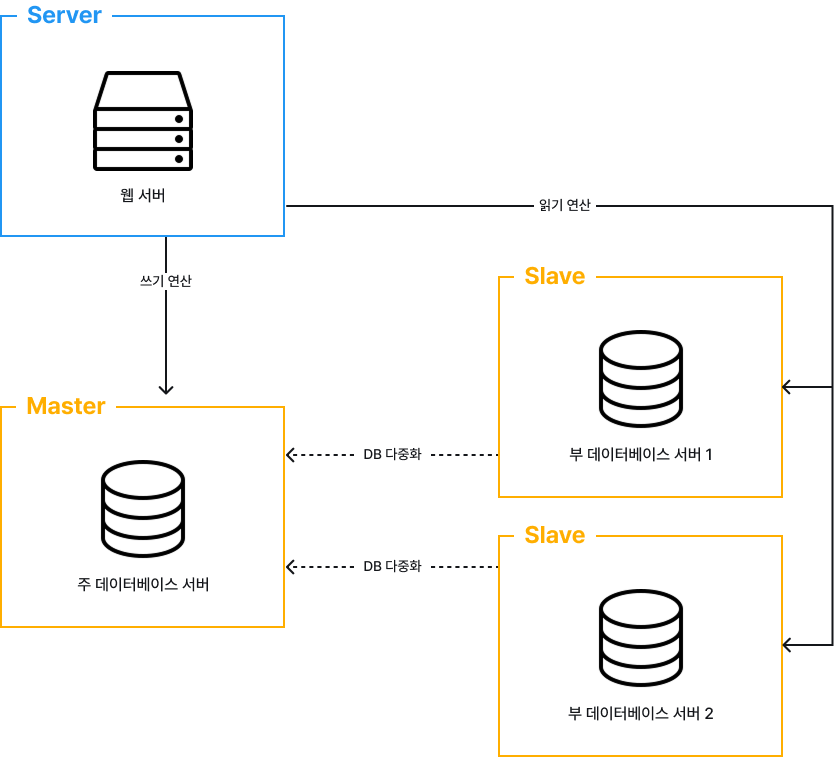
이러한 구성은 다음과 같은 이점을 가져옵니다.
- 더 나은 성능
- 모든 데이터 변경 연산은 Master 서버로만 전달되는 반면 읽기 연산은 Slave 서버들로 분산되어 병렬로 처리될 수 있는 Query 수가 늘어남
- 안정성
- 자연 재해 등의 이유로 데이터베이스 서버 가운데 일부가 파괴되어도 데이터는 보존됨
로드밸런서와 데이터베이스 다중화를 고려한 설계
로드밸런서와 데이터베이스 다중화를 고려한 설계는 다음과 같이 동작합니다.
사용자는 DNS로 부터 공인 IP 주소를 받는다.
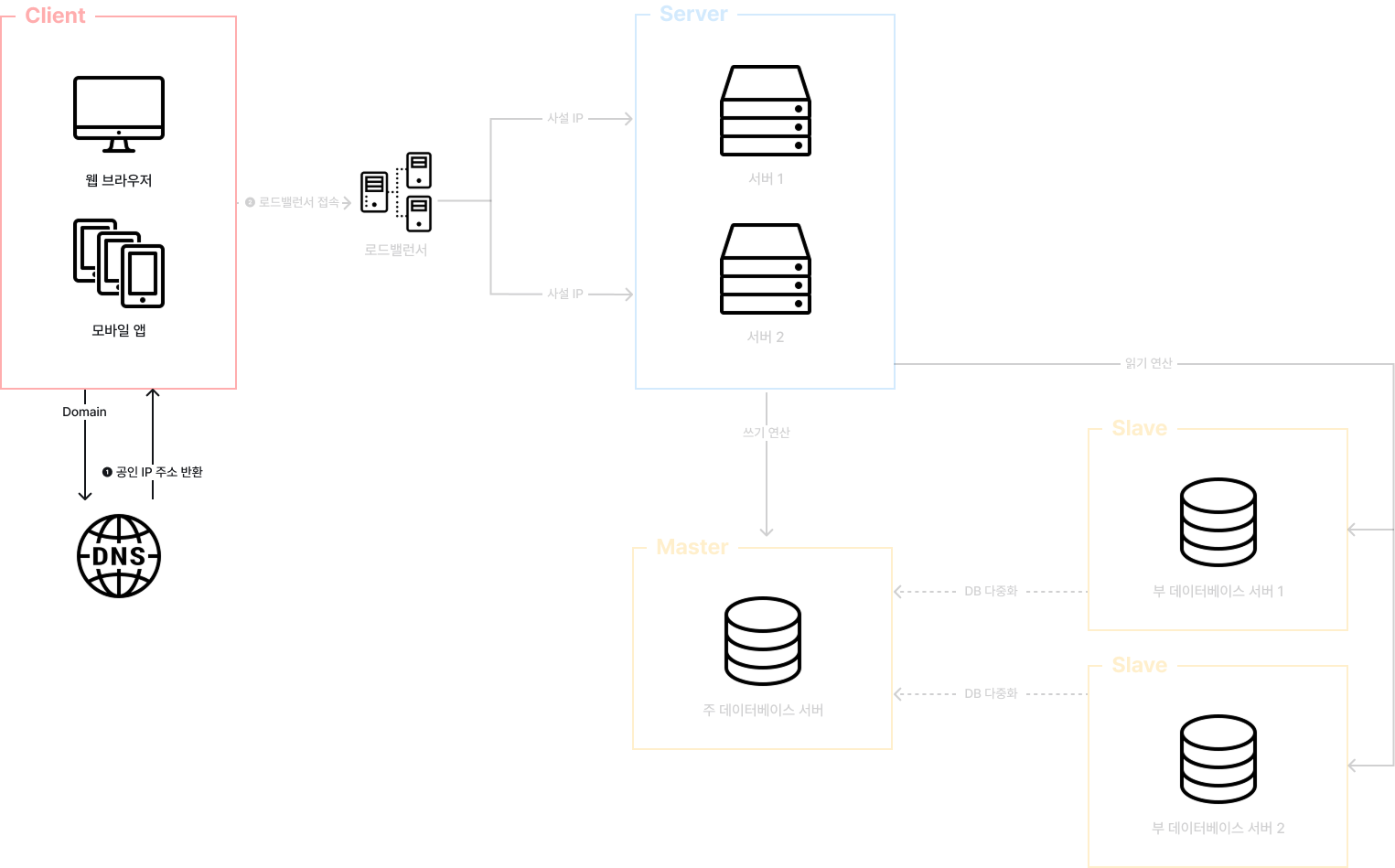
사용자는 해당 IP 주소를 사용해 로드밸런서에 접속한다.
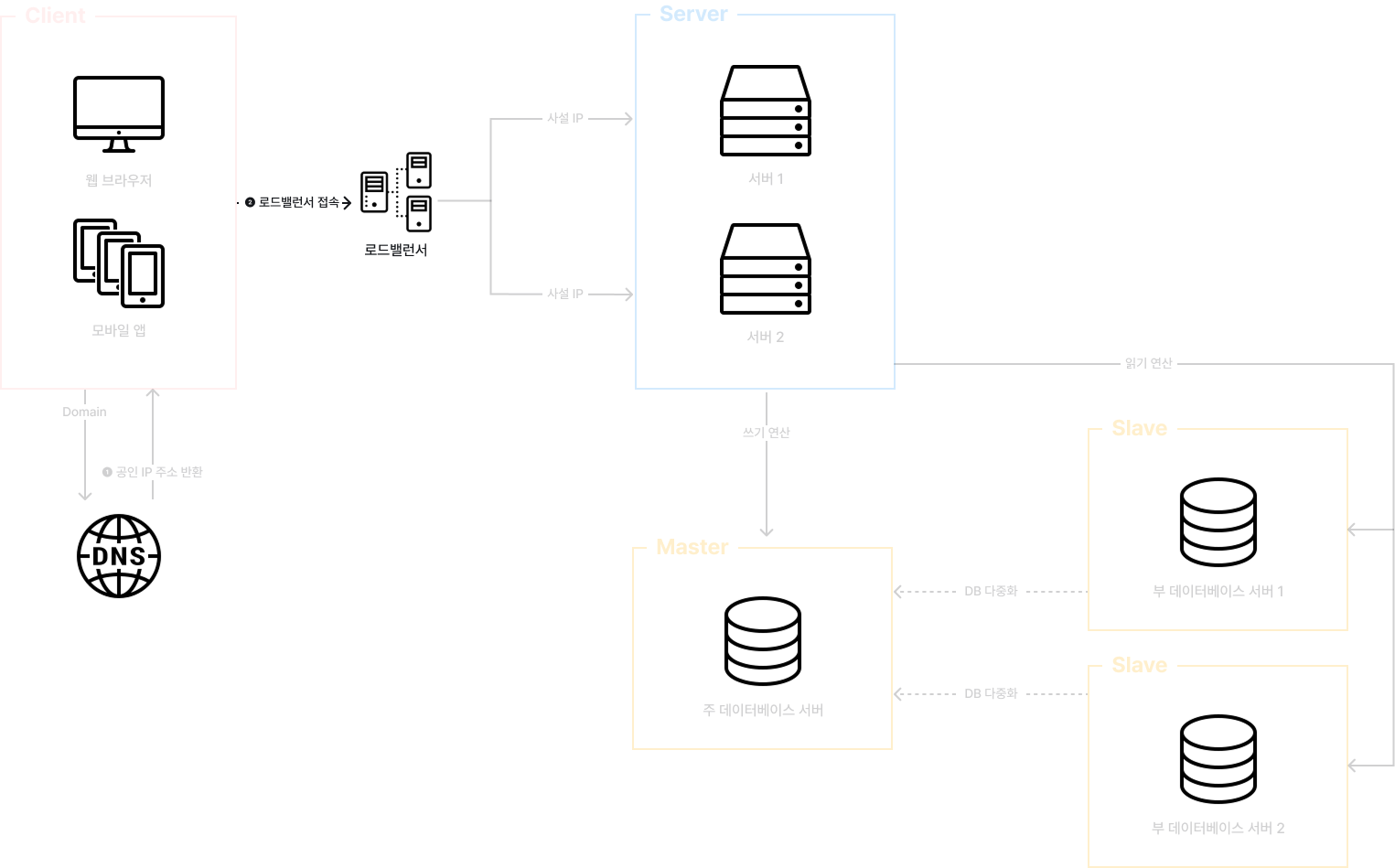
HTTP 요청은 서버 1 또는 서버 2로 전달된다.
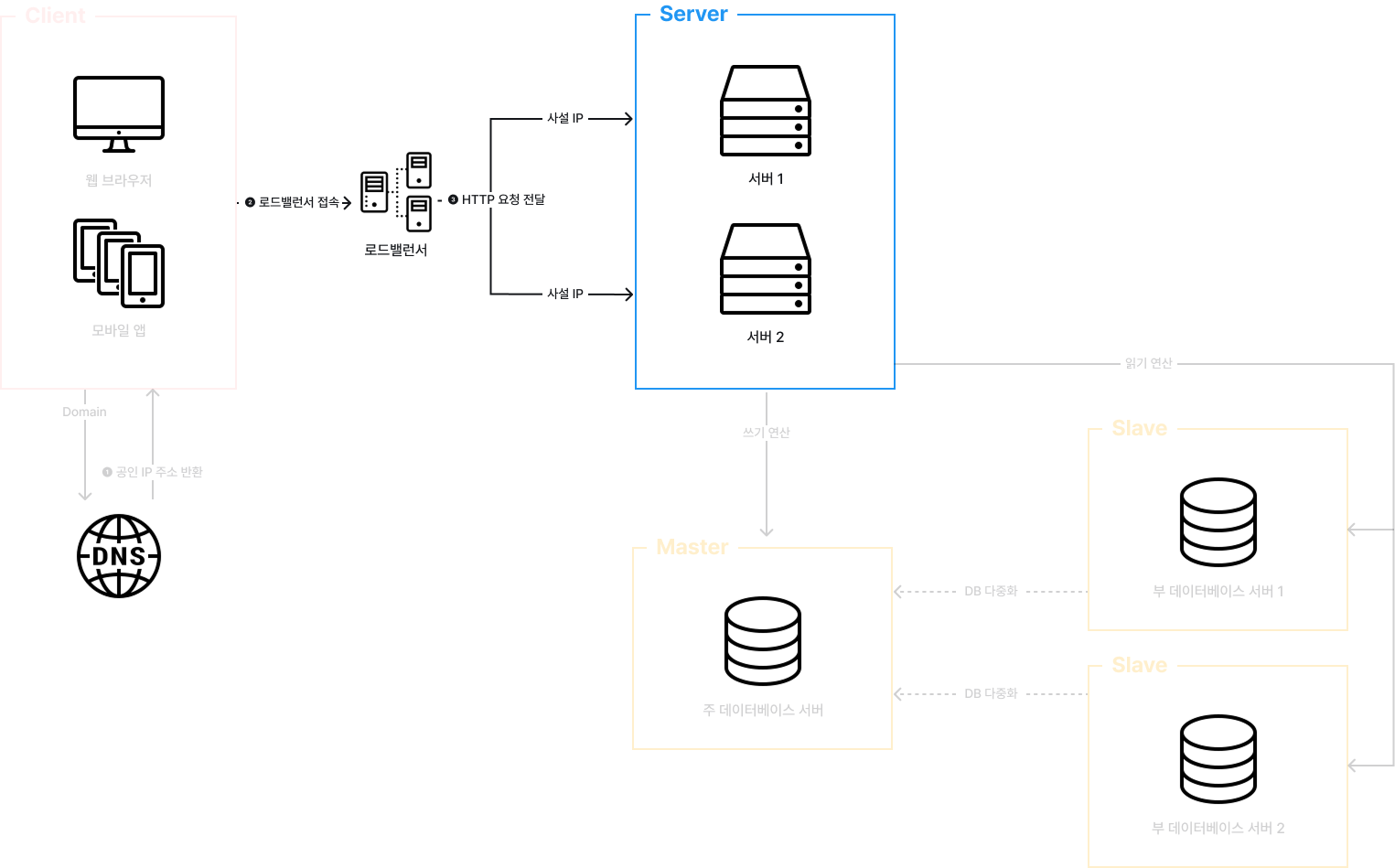
요청을 처리하기 위한 연산이 읽기일 경우 Slave로, 쓰기일 경우 Master로 전달된다.