
특징
Hash Table은 효율적인 탐색을 위한 자료구조입니다. 데이터는 (key, value) 형태로 저장되며, Hash Function 결과인 h(key)를 인덱스로 사용하여 Slot(Bucket)에 데이터를 저장합니다. 이는 추가, 삭제, 조회 연산에서 평균적으로 O(1) 시간 복잡도를 가지는 반면 미리 저장 공간(Slot, Bucket)을 확보해야 하므로 낮은 공간 효율성을 가지고 있습니다.
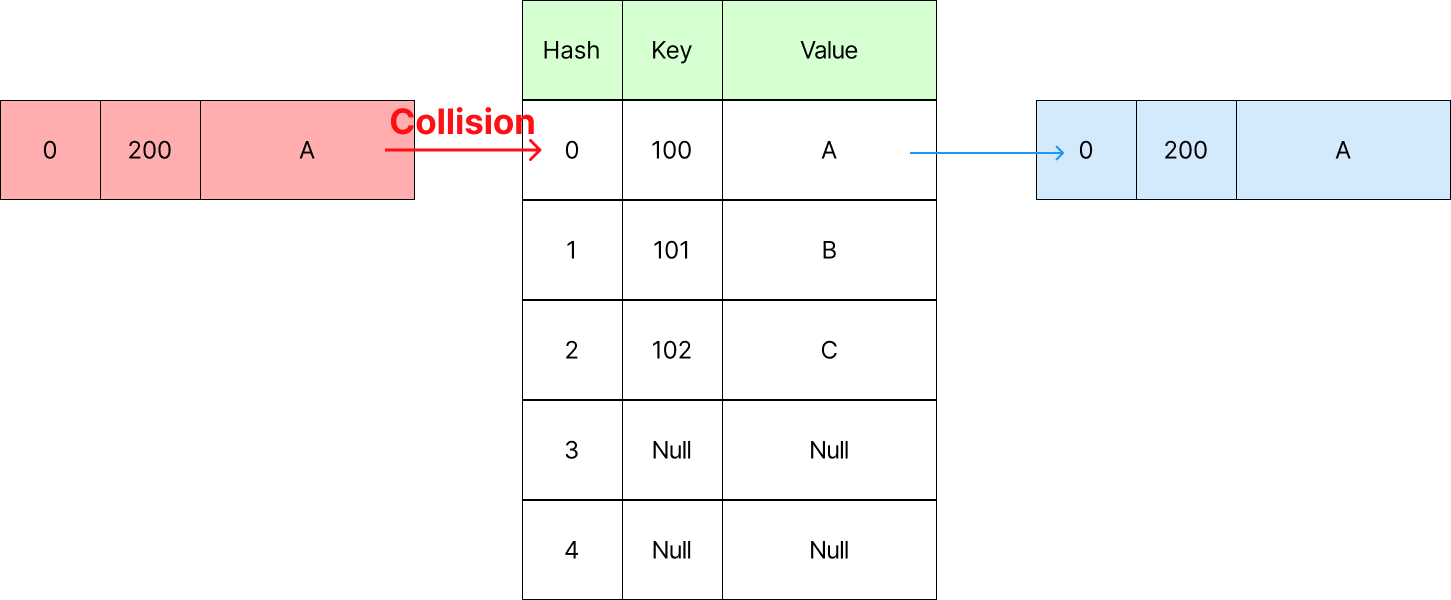
Collision
Hash Table의 경우 Hash Funtion 수행 결과를 인덱스로 사용합니다. 이에 대한 중복이 발생하는 것을 Collision이라고 합니다. 이 경우를 그림으로 살펴보겠습니다.
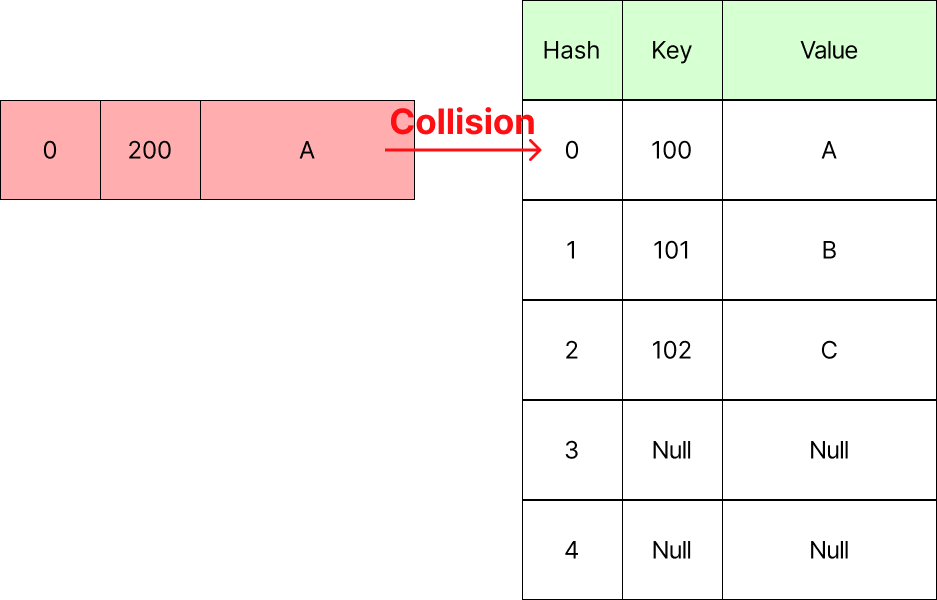
위 그림을 보면, 현재 삽입하려는 데이터의 Hash와 중복된 Hash를 가지는 데이터가 이미 존재하는 것을 볼 수 있습니다. 이를 "Collision이 발생했다"라고 합니다. 이처럼 Collision이 빈번하게 발생하게 되면 최악의 경우 모든 연산에 대하여 O(n)의 시간 복잡도를 가질 수 있습니다.
따라서, Collision을 최소화 할 수 있는 Hash Funtion을 설계해야 하고, 그럼에도 Collision이 발생할 경우 'Separate Chaining' 또는 'Open Addressing' 등의 방법을 사용하여 해결합니다.
Open Addressing
Open Addressing은 미리 정한 규칙에 따라 Hash Table의 비어있는 Slot을 찾는 방법입니다. 찾는 방법에 따라 'Linear Probing', 'Quadratic Probing', 'Double Hashing' 으로 분류합니다.
Probing (조사법)
조사법은 충돌이 발생한 해시값을 기준으로 Offset을 추가하여 빈 슬롯을 찾아 데이터를 저장하는 방법입니다. 이 방식은 Offset을 결정하는 방식에 따라 Linear와 Quadratic 두 가지로 나뉩니다.
-
Linear Probing
- 일정한 값(+1, +2, ...)
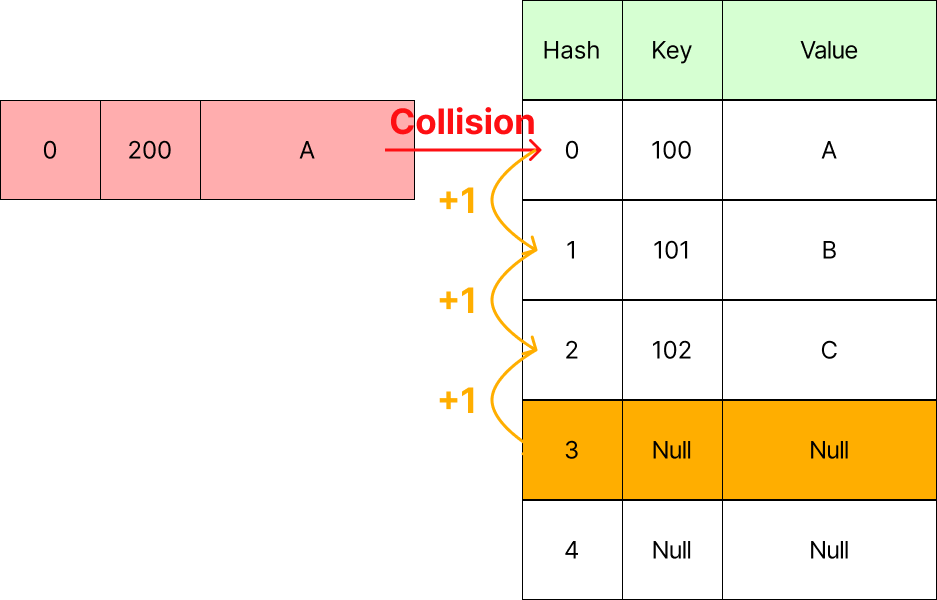
- 일정한 값(+1, +2, ...)
-
Quardatic Probing
- 제곱수(+, +, ...)
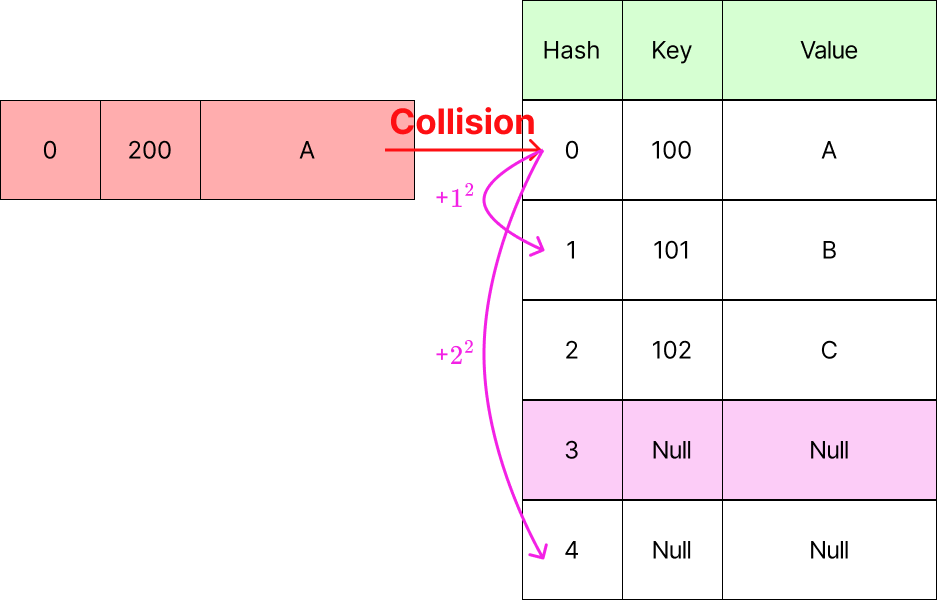
- 제곱수(+, +, ...)
또한, 조사법은 충돌 횟수가 증가할수록 클러스터링(데이터가 특정 영역에 몰리는 현상)이 발생한다는 단점이 있습니다. 이로 인해 평균 탐색 시간이 증가하게 됩니다.
Double Hashing (이중 해시)
이중 해시는 Linear Probing과 Quadratic Probing에서 Offset이 동일해 발생하는 클러스터링 문제를 해결하기 위해 2개의 Hash Function을 사용하는 방식입니다.
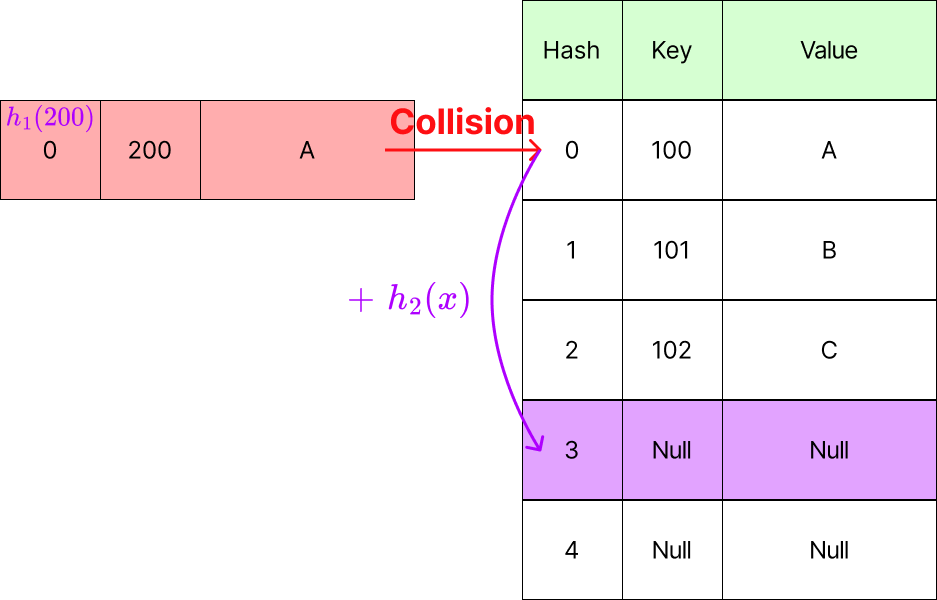
위 그림처럼 는 초기 해시값 계산을 위해, 는 Collision 발생 시 Offset을 결정하기 위해 사용합니다.
Separate Chaning (개별 연쇄법)
Separate Chaining은 충돌 해결을 위해 Linked List를 사용하여 데이터를 저장하는 방식입니다.
위 그림처럼 충돌이 발생하면 해당 슬롯에 노드를 추가하여 데이터를 저장합니다.
이 방식은 추가, 조회, 삭제의 경우 기본적으로 O(1)의 시간 복잡도를 가지지만, 최악의 경우 조회, 삭제는 O(n)의 시간 복잡도를 가집니다. 이때, 최악의 경우는 n개의 Key가 모두 동일한 해시값을 가져 길이가 n인 Linked List가 생성되는 경우를 말합니다.
예상 질문
Hash Table 자료구조는 무엇인가요?
Hash Function을 사용해 인덱스를 지정하고, Slot에 (key, value) 데이터를 저장하는 빠른 탐색을 위한 자료구조입니다.
Collision은 무엇인가요?
Hash Function 수행 결과가 이미 사용중인 인덱스인 경우를 "Collision이 발생했다"라고 합니다.
Collision을 해결하는 방법은 무엇이 있나요?
개방 주소법과 연쇄법이 있습니다.
개방 주소법엔 무엇이 있나요?
선형 조사법, 이차 조사법, 이중 해싱 등이 있습니다.
Linear Probing과 Quadratic Probing의 차이는 무엇인가요?
선형 조사법의 경우 일정한 값을 Offset으로 사용하고, 이차 조사법의 경우 제곱수를 Offset으로 사용합니다.
Probing 방법의 단점은 무엇인가요?
두 조사법의 경우 동일한 Offset 패턴을 가지고 있어 클러스터링 문제가 발생할 수 있습니다.
Probing 방법의 단점을 보완하기 위한 방법은 무엇이 있나요?
이중 해싱을 추가로 구현합니다. 하나는 초기 해시값을 계산하고, 하나는 Offest을 결정하기 위해 사용합니다.
Separate Chaning 방법은 무엇인가요?
Collision이 발생할 경우 Linked List에 노드를 추가하는 방식입니다.
Sperate Chaning의 최악의 경우는 왜 발생하고, 시간 복잡도는 무엇인가요?
만약, n개의 key가 모두 동일한 해시값을 가지게 될 경우 발생합니다. 이로 인해, 길이가 n인 Linked List가 생성되고 검색, 삭제 연산에 대해 O(n)의 시간 복잡도를 가지게 됩니다.
