
특징
데이터를 선입선출(FIFO) 기반으로 관리하는 자료구조입니다. 즉, 먼저 추가된 데이터의 우선순위가 가장 높음을 의미합니다. 이때, 데이터 추가(Enqueue)와 삭제(Dequeue) 연산은 O(1)의 시간복잡도를 가지고 있습니다.
구현 방법
Queue를 구현하는 방법은 2가지(Array, Linked List)가 존재합니다.
Array-Based Queue
Array 자료 구조를 기반으로 Queue를 구현한 것을 의미합니다. Array의 단점과 동일하게 고정된 크기를 가지고 있어 메모리 효율성이 떨어지는 단점을 가지고 있습니다. 하지만, 이러한 한계를 보완하기 위한 방법으로 Cicular Queue가 있습니다.
그림으로 두 Queue의 차이점을 살펴보도록 하겠습니다.
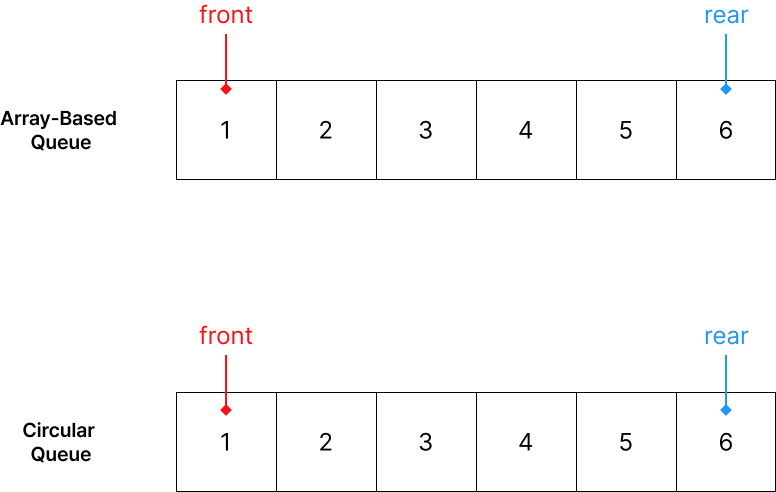
우선, 위 그림을 보면 6의 크기를 가지는 Queue이며 용량을 모두 사용하고 있습니다. 다음으로 차이가 발생하는 상황을 만들기 위해 2개의 데이터를 삭제하겠습니다.
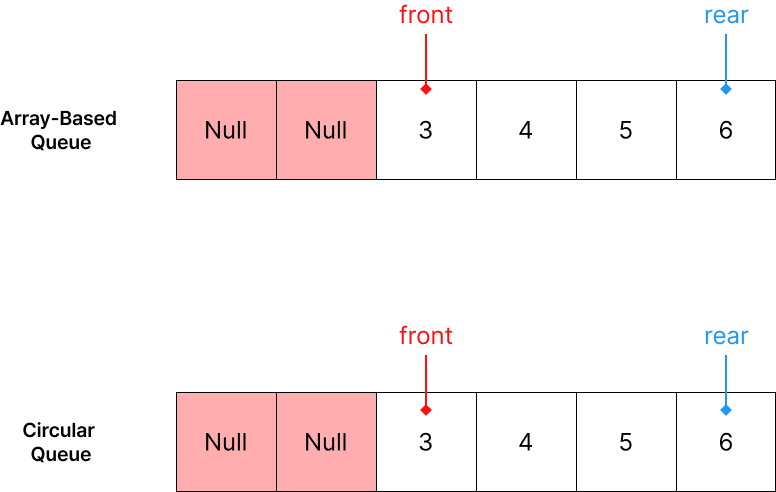
위 그림을 통해 2개의 데이터를 삭제해 앞 부분을 가르키는 포인터가 2칸 이동한 것을 확인할 수 있습니다. 만약, 이 상황에서 1개의 데이터를 추가하겠습니다.
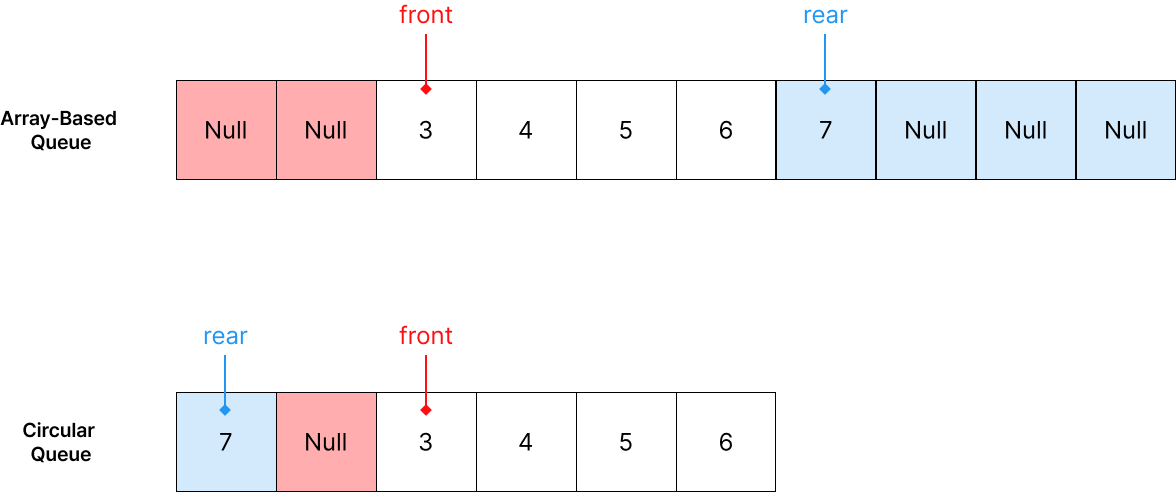
이제 두 Queue의 차이가 보이시나요?
Array-Based는 Resize 수행으로 크기가 증가했지만, Circular Queue는 다시 처음부터 데이터를 보관하는 모습을 볼 수 있습니다.이렇게 처음과 끝이 연결된 형태처럼 구현하여 메모리를 효율적으로 사용할 수 보완한 것을 Circular Queue라고 합니다.
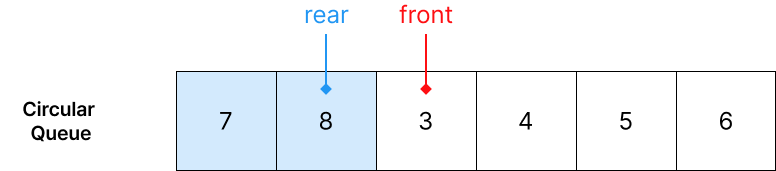
하지만, 위 그림과 같은 상황에서 데이터 추가를 수행해야 하는 경우 Circular Queue 또한 Resize를 수행해야 하기 때문에 완벽히 한계를 보완하는 것은 아닙니다.
Linked-Based Queue
Linked List 자료 구조를 기반으로 Queue를 구현한 것을 의미합니다. Array-Based Queue와 달리 데이터를 추가할 때 메모리를 동적 할당하기 때문에 메모리를 효율적으로 사용할 수 있습니다. 하지만, 이로 인해 데이터 추가/삭제 작업에 대한 메모리 할당/해제가 빈번히 수행되어 전반적인 Runtime이 느릴 수 있습니다.
이제, 그림을 통해 어떻게 데이터를 어떻게 보관하고 있는지 살펴보겠습니다.

위 그림을 살펴보면 데이터를 보관하고 있는 각 노드들이 서로 연결되어 있습니다. 추가 작업시 노드를 할당하고 Tail 포인터를 이동하고, 삭제 작업시 Head 포인터가 가르키는 노드를 변경한 후 삭제 대상인 Node를 해제하면 됩니다.
확장
Queue의 개념을 조금 더 확장하면 Deque(Double-Ended Queue)와 Priorty Queue가 있습니다.
- Dequeue
- 출구와 입구에서 모두 Enqueue, Dequeue 작업을 수행할 수 있는 자료구조
- Priority Queue
- 선입선출이 아닌 정의한 우선순위를 기준으로 조회/삭제할 데이터를 결정하는 자료구조
활용
Queue는 다음과 같은 경우에서 활용합니다.
- 공유 프린터
- Cache 활용
- CPU Task Scheduling
- BFS
결론
두 가지 구현 방법을 모두 살펴보았습니다. 이를 정리하면 다음과 같습니다.
- 메모리 효율성
- Linked-Based Queue가 더욱 효율적으로 사용 가능하다.
- 하지만, 크기를 예측할 수 있다면 Array-Based Queue도 효율적인 사용이 가능하다.
- 성능
- 전반적으로 Array-Based Queue가 우수하다.
- 하지만, Resize 작업이 많이 수행되면 Linked-Based Queue가 더 우수할 수 있다.
예상 질문
Queue는 어떤 자료구조인가요?
선입선출 형태를 가지는 자료구조입니다.
Qeueue를 구현하는 방법은 무엇이 있나요?
Array와 Linked List를 사용하여 구현할 수 있습니다. 추가로, Array 구현은 Circular Queue 형태로 구현하는 것이 메모리 사용에 대한 한계를 보완할 수 있는 방법입니다.
Array-Based와 Linked-Based의 차이점은?
데이터를 추가하는 방식에 따라 둘의 차이점이 존재합니다. Array-Based의 경우 고정된 크기를 가지기 때문에 한계를 넘어서면 Resize 작업을 수행하고, Linked-Based의 경우 데이터 추가 작업에 대하여 동적으로 메모리 할당을 수행합니다. 하지만, Resize작업이 빈번하게 수행되는 최악의 경우가 아니라면 Array-Based는 분할 상환 시간 복잡도가 O(1)이므로 전반적으로 성능이 우수합니다.
