RNN 기반의 번역 모델인 Sequence to Sequence를 아주 간소화하여 영어 문자열을 스페인어 문자열로 번역하는 미니 Seq2Seq를 구현해보자.
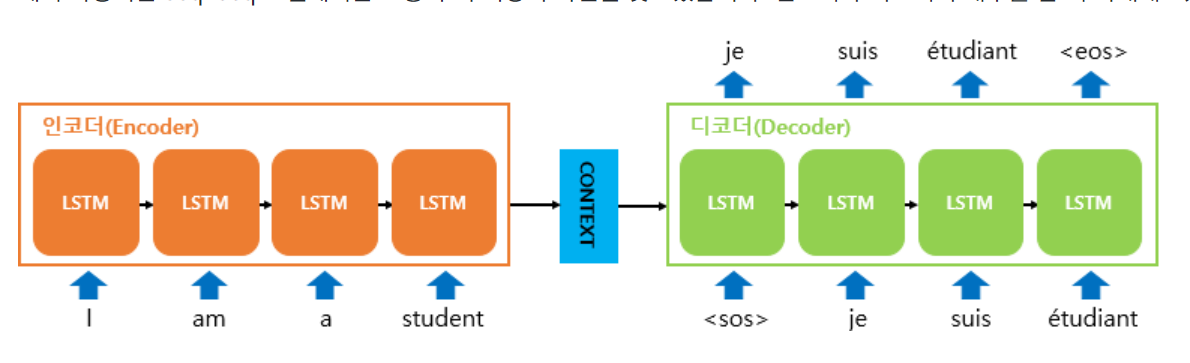
우선 Seq2Seq는 다른 두 개의 RNN을 이어붙인 모델이다.
이 때 두 개의 RNN은 각각 인코더 / 디코더라는 역할을 하게된다.
# 인코더
우선 인코더는 원문의 내용을 학습하는 RNN이다. 원문속의 모든 단어를 입력받고 뜻을 내포하는 하나의 고정 크기 텐서를 만든다. 인코더 RNN은 원문 속의 토큰을 차례대로 입력받는다. 원문 마지막 토큰에 해당하는 은닉 벡터는 원문의 뜻을 모두 내포하는 문백 벡터라고 한다.
# 디코더
인코더와 마찬가지로 디코더 또한 RNN모델이다. 인코더에서 이어받어 번역문 속의 토큰을 차례대로 예상한다.
여기서 구현하는 모델은 디코더의 첫 번째 은닉 벡터를 인코더의 내용 벡터로 정의하고, 디코더는 번역문 내 토큰들을 차례대로 예측하면서 실제 번역문 사이의 오차를 줄여나가는 모델이 학습하는 기본 원리를 사용해서 구현해보았다. 또한 보통 단어를 문장의 최소 단위로 여겨 단어 단위의 임베딩을 하지만 여기서는 간단한 영단어를 번역하기 때문에 글자 단위의 캐릭터 임베딩을 사용하였다.
Code
import torch
import torch.nn as nn
import random
import matplotlib.pyplot as plt데이터셋 속에 총 몇 종류의 토큰이 있는지 정희해주는 vocab_size -> 총 아스키 코드 개수(영문)
vocab_size = 256Seq2Seq모델에 입력될 원문과 번역문을 아스키 코드의 배열로 정의하고 파이토치 텐서로 바꿔주기
x_ = list(map(ord, "hello"))
y_ = list(map(ord, "hola"))
x = torch.LongTensor(x_)
y = torch.LongTensor(y_)Seq2Seq모델 클래스 정의
class Seq2Seq(nn.Module):
def __init__(self, vocab_size, hidden_size):
super(Seq2Seq, self).__init__()
self.n_layers = 1
self.hidden_size = hidden_size #RNN의 hidden_size를 입력받도록 설정
#hidden_size를 임베딩된 토큰의 차원값으로 정의
self.embedding = nn.Embedding(vocab_size, hidden_size)
#인코더와 디코더를 GRU객체로 정의
self.encoder = nn.GRU(hidden_size, hidden_size)
self.decoder = nn.GRU(hidden_size, hidden_size)
#디코더가 번역문의 다음 토큰을 예상해내는 작은 신경망 하나 더 생성
self.project = nn.Linear(hidden_size, vocab_size)
forward()함수로 앞에 정의한 신경망 모듈과 객체들을 서로 이어주기
인코더의 첫 번째은닉 벡터를 정의하고 인코더에 입력되는 원문을 구성하는 모든 문자 임베딩
def forward(self, inputs, targets):
initial_state = self._init_state()
embedding = self.embedding(inputs).unsqueeze(1)ㆍ원문을 인코더에 입력시켜 문맥 벡터인 encoder_state를 만들어낸다
ㆍ이 벡터를 디코더의 첫 번째 은닉 벡터 decoder_state로 지정
->문장 시작 토큰은 실제로 문장에는 나타나지 않지만 디코더가 정상적으로 작동할 수 있도록 인위적으로 넣은 토큰이기때문에, 공백 문자를 뜻하는 0으로 설정
encoder_output, encoder_state = self.encoder(embedding, initial_state)
decoder_state = encoder_state
decoder_input = torch.LongTensor([0])디코더는 문장 시작 토큰인 아스키 번호 0을 이용해 "hola"의 "h"를 예측
다음 반복에서는 'h'토큰을 이용해 'o'토큰을 예측해야한다. 이 동작을 for문으로 구현하여 순서대로 예상하고 저장하기
outputs = []
for i in range(targets.size()[0]):
decoder_input = self.embedding(decoder_input).unsqueeze(1)
decoder_output, decoder_state = self.decoder(decoder_input, decoder_state)디코더의 출력값으로 다음 글자 예측하기
projection = self.project(decoder_output)
outputs.append(projection)티처 포싱을 이용한 디코더 입력갱신 & 결과값들의 배열인 outputs 반환
티처 포싱이란
-> 디코더 학습 시 실제 번역문의 토큰을 디코더의 전 출력값 대신 입력으로 사용해 학습을 가속하는 방법
-> 학습이 아직 되지 않은 상태의 모델은 잘못된 예측 토큰을 입력으로 사용할 확률이 높기 때문에 이를 방지하기 위해 사용
decoder_input = torch.LongTensor([targets[i]])
outputs = torch.stack(outputs).squeeze()
return outputs
def _init_state(self, batch_size=1):
weight = next(self.parameters()).data
return weight.new(self.n_layers, batch_size,
self.hidden_size).zero_()교차 엔트로피 오차를 구하는 클래스와 최적화 알고리즘 정의 & 1000번의 반복을 걸쳐 모델 학습
seq2seq = Seq2Seq(vocab_size, 16)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(seq2seq.parameters(), lr=1e-3)
log = []
for i in range(1000):
prediction = seq2seq(x,y)
loss = criterion(prediction, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_val=loss.data
log.append(loss_val)
if i % 100 == 0:
print("\n 반복: %d 오차: %s" % (i, loss_val.item()))
_, top1 = prediction.data.topk(1,1)
print([chr(c) for c in top1.squeeze().numpy().tolist()])
plt.plot(log)
plt.ylabel('cross entropy loss')
plt.show()
위의 그림과 같이 오차가 줄어들면서 원문 "hello"의 번역 결과가 "hola"로 조금씩 변화하는 것을 볼 수 있다.
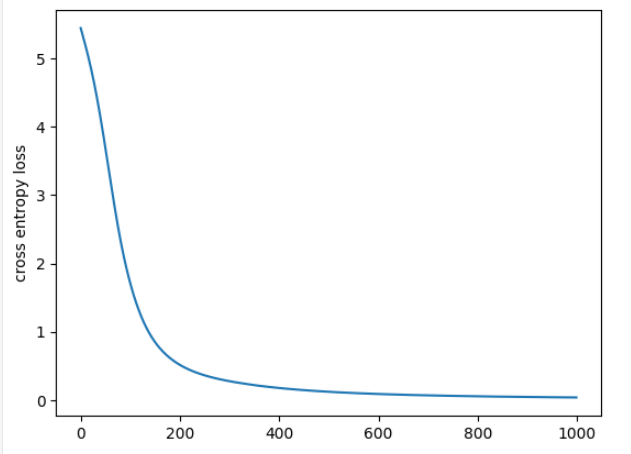
그래프를 이용하여 오차가 줄어드는 모습도 한눈에 확인 가능하다.

19011807