
내가 알고있던 DB에 대한 데이터를 풀어보고, 기억하고 있던 내용에 대한 상세 자료를 찾아보았다.
Database는 '데이터의 집합'이다.
기본적으로 매우 많은 데이터를 처리한다.
나는 간단하게 1~10까지의 수를 예시로 썼는데 1~10억개의 수라고 생각해보자.
나는 1~10만의 수 중 하나를 확인하고 싶다.
그럼 DB는 4만을 어떻게 찾을까?
그 작동 원리를 꺼내왔다
1)

2)
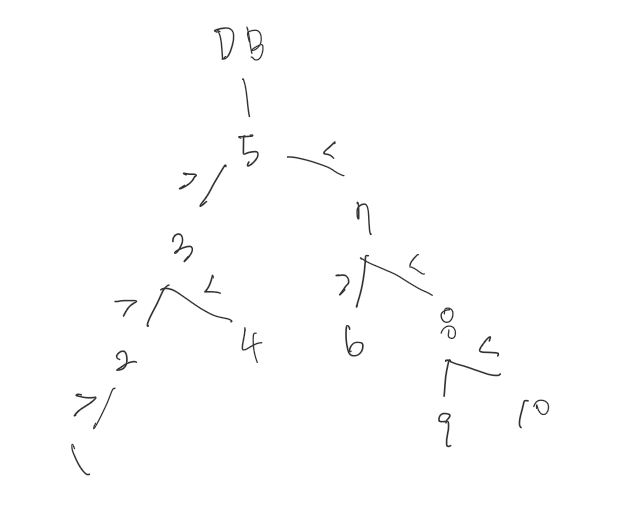
3)
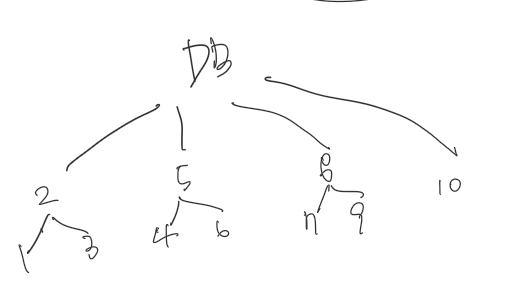
글로 내용을 풀어나갈 자신이 없어서 그려봤다.
1은 무작정 1부터 내가 원하는 수를 찾아나가고,
2는 그보다 발전하여 절반씩 묻는다.
전체 수 절반 중 (UP? DOWN?) 루프
조금 찾아 본 결과, 이는 DB의 index에 대한 설명이란 것을 알 수 있었다.
Array

Tree
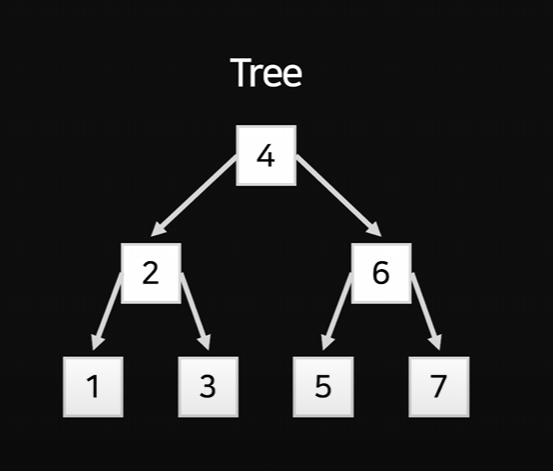
아무렇게나 흩뿌려진 데이터를 연결하고 정렬한다.
절반씩 소거하며 찾을 수 있고, 가지를 뻗는 모습이라 하여 Tree라고 부른다.
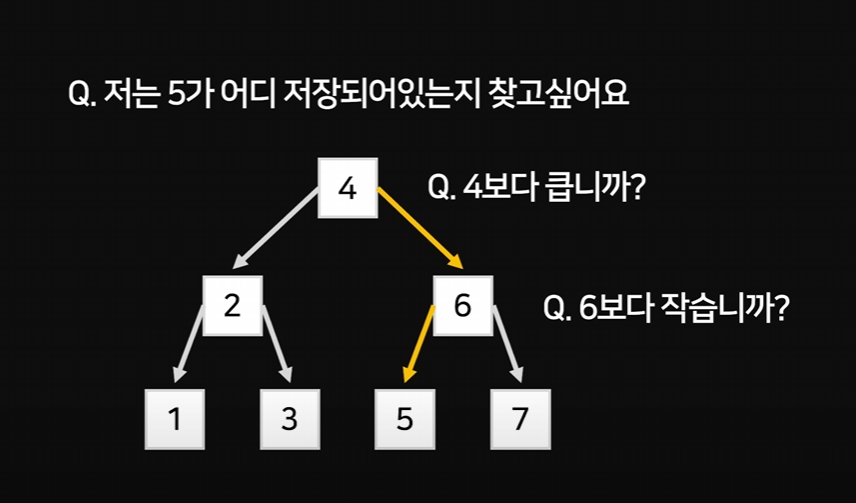
이미지와 같은 방식으로 데이터를 찾는다.
DB는 데이터를 위와 같은 형태로 저장해 두는데,
이 형태를 Binary Search Tree라고 부른다.
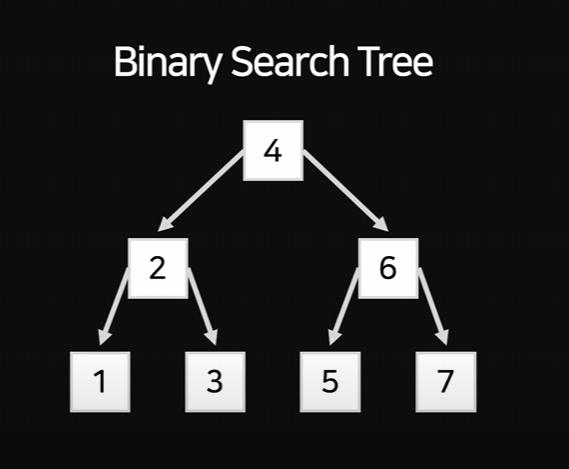
여기서 성능 개선이 이루어 질 수 있다.
B Tree
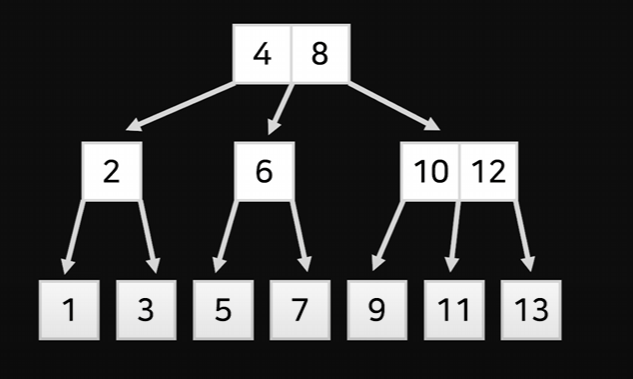
이런 식으로 더 큰 수를 3개 씩, 4개 씩 자르고 붙일 수 있다.
이것을 B-Tree라고 한다.
2번의 질문에 1~7까지 찾을 수 있던 Tree보다 약 2배가량의 성능 개선이 이루어졌다.
B+Tree
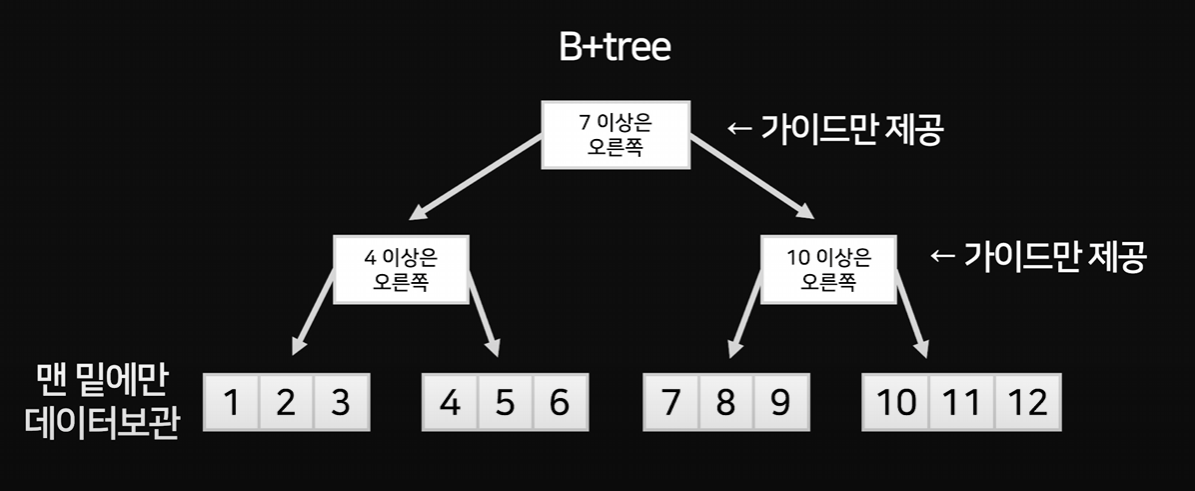
B Tree에서 더 개선이 이루어진 B+ Tree이다.
노드(데이터)는 정렬해 두고, 이 노드를 찾기위한 가이드를 두고,
123->456->789->101112
노드끼리도 연결해 범위 검색에 매우 유리한 형태를 가진다.
"4와 8을 찾아 그 사이 데이터를 출력해 줘" 라는 요청에
매우 빠르게 응답할 수 있는 방식이다.
DB를 연결하다보니 생각났던 내용인데
내용 정리를 위해 찾아보다 좋은 영상이 있었다.
나는 회사에서 실무하는 동안 많은 운영툴에서 제공되는 index를 써왔는데,
이런 개념에서 출발했다는게 신기했고, 만약 index를 내가 직접 개발에 활용할 때
보다 잘 써먹을 수 있을 것 같다.
출처 : https://www.youtube.com/watch?v=iNvYsGKelYs (코딩애플)
