
데이콘
데이콘 경진대회에 참여하여 공부중입니다
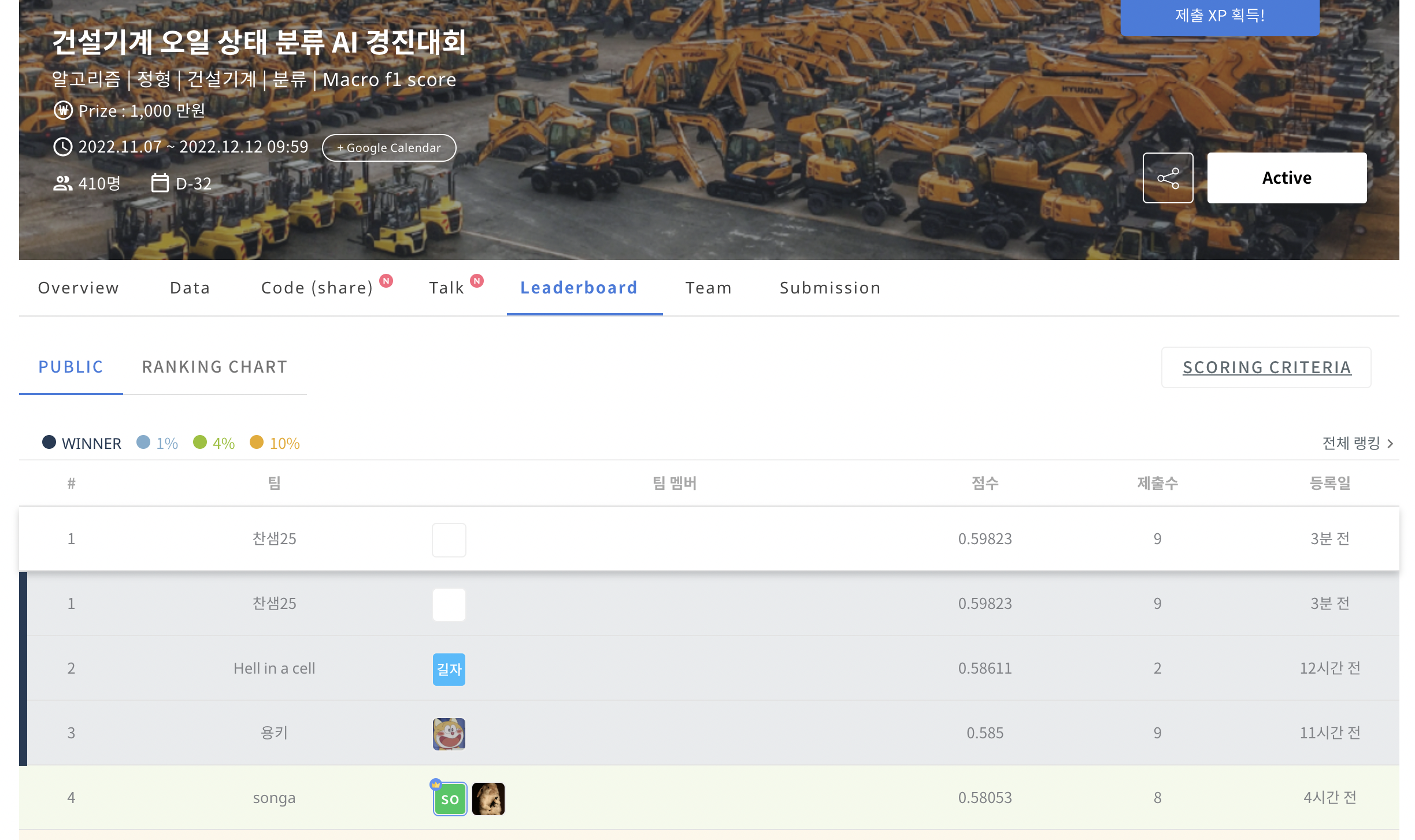
대회 초기지만 PUBLIC 1등을 잠시나마 달성하여 블로그에 기록을 남깁니다!
Knowledge Distillation
Knowledge Distillation라는 개념을 접하였고 경진대회에서의 제약사항인 테스트 데이터에서의 feature의 수 감소(54->18)를 해결하는 방법론으로 사용되었다.
최근 딥러닝 모델은 좋은 성능을 내고 있지만 그만큼 많은 자원을 필요로 한다. 다양한 산업에서 적용하기 위해 리소스를 줄이는 방법으로 많은 연구가 되고 있는 듯 하다.

부지런한 개발자가 되고싶은