인코딩과 디코딩
컴퓨터는 0과 1로 이루어진 데이터를 이해할 수 있다. 반면에 우리는 다양한 문자와 숫자를 사용하며 이를 컴퓨터에 입력한다. 이때, 컴퓨터가 이해할 수 있도록 0과 1로 이루어진 데이터로 변환하는 것을 인코딩이라고 한다. 반대로 컴퓨터의 언어를 사람의 언어로 변환하는 것은 디코딩이다.
2진법과 16진법
컴퓨터는 0과 1로 이루어진 2진법 체계의 데이터를 이해한다.
이때 0과 1을 표현할 수 있는 가장 작은 단위를 bit(2가지 정보 표현가능)라고 한다.
그리고 8bit(2^8 가지 정보 표현가능)는 1byte로 변환할 수 있다.
CPU가 한번에 처리할 수 있는 데이터 양은 워드(word)이며, 컴퓨터 사양 중 32비트, 64비트는 워드를 나타낸다.
하지만 이러한 2진법 체계는 데이터를 나타내는데 많은 자리수를 필요로 한다. 예를 들어 10진수 11을 나타내는데 이진법으로는 1011(2)의 네자리가 필요하다.
이 같은 현상을 해소하기 위해 컴퓨터에서 16진법도 자주 사용한다. 굳이 16진법인 이유는 16진수가 2진수로 쉽게 변환가능하기 때문이다.
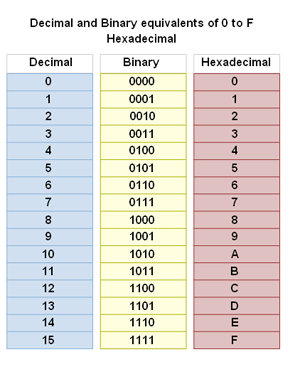
16진수 1자리를 표현하기 위해서는 2진수 4자리(2^4=16)가 필요하다. 따라서 16진수를 2진수로 변환하려면 16진수 한자리를 각각 4자리의 2진수로 변환하면 된다.(중간에 10진수를 경유)
ex) 4B(16) -> 4(16) = 4(10), B(16) = 11(10)
-> 4(10) = 0100(2), 11(10) = 1011(2) => 1001011(2)
컴퓨터 상에서 2진수는 0b, 16진수는 0x를 앞에 붙여 표기한다.
2진법에서 음수는 2의 보수로 표현하며, 2의 보수로 바꾸기 위해서는 각자리의 0과 1을 서로 바꾸고 1을 더하면 된다.
ex) 0011의 보수는 1100 + 1 해서 1101이다.
문자집합(Charactor set)
컴퓨터는 문자집합을 사용해서 인코딩과 디코딩을 수행한다. 문자집합은 code point라는 개념의 숫자와 문자가 매칭된 집합을 의미한다.
다음은 초창기 문자집합인 아스키(ASCII)이다.
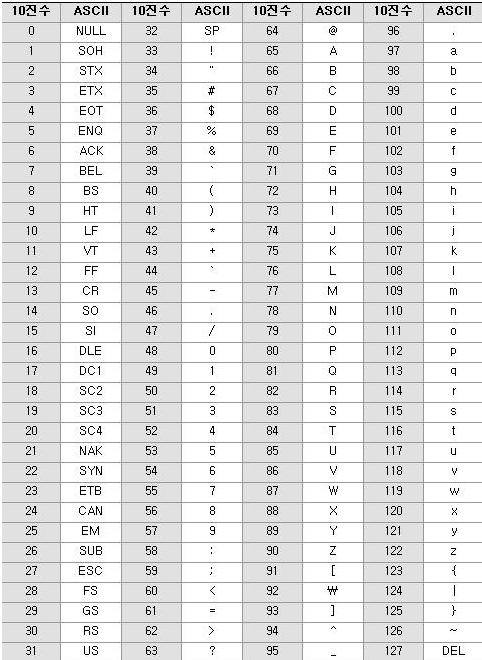
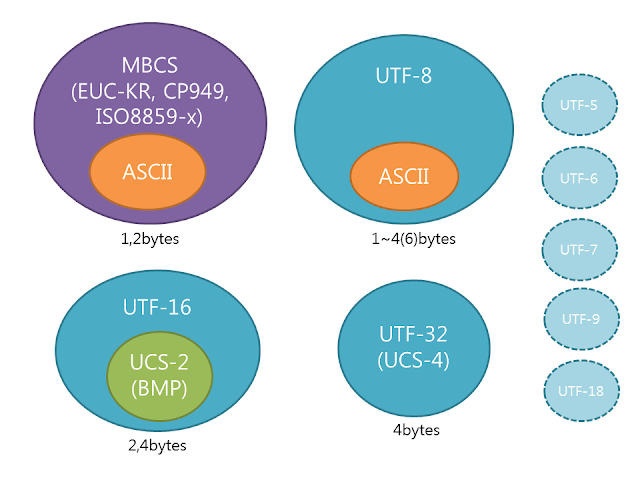
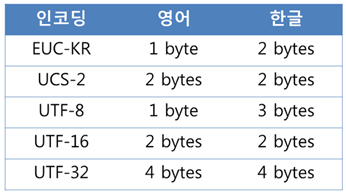
128개의 문자를 표현하는 아스키코드로는 한계점이 많았는데 예를 들어 한글은 표현할 수 없다. 그래서 후에 한글을 위한 EUC-KR 코드(완성형 인코딩)가 나오기도 하였지만 '쀍'과 같은 언어를 표현할 수는 없었다. 이러한 모든 문제를 해결하기 위해 대부분의 나라의 문자, 특수문자, 이모티콘까지도 코드로 표현하는 UTF(Unicode Transformation Format)가 등장하였다. 유니코드는 인코딩방식에 따라 UTF-8, UTF-16, UTF-32 등으로 나뉜다. UTF-8의 경우 ASCII와 호환가능하며, 영어의 경우 사용되는 용량이 매우 작다는 장점이 있어 가장 인기있다. 윈도우, 자바, 임베디드를 제외한 거의 모든 환경에서의 문자열 처리 표준으로 여겨진다.