🐼 한글 깨짐 방지
import matplotlib as mpl import matplotlib.pyplot as plt %config InlineBackend.figure_format = 'retina' !apt -qq -y install fonts-nanum import matplotlib.font_manager as fm fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf' font = fm.FontProperties(fname=fontpath, size=9) plt.rc('font', family='NanumBarunGothic') mpl.font_manager._rebuild()
👁️ 네이버 랭킹뉴스(많이 본) 크롤링
😤 라이브러리 임포트
from urllib.request import urlopen
from bs4 import BeautifulSoup
import pandas as pd
import datetime
from pytz import timezone👁️ 많이 본 랭킹뉴스 크롤링
👀 네이버 랭킹뉴스 이런식으로 생겼답니다 !
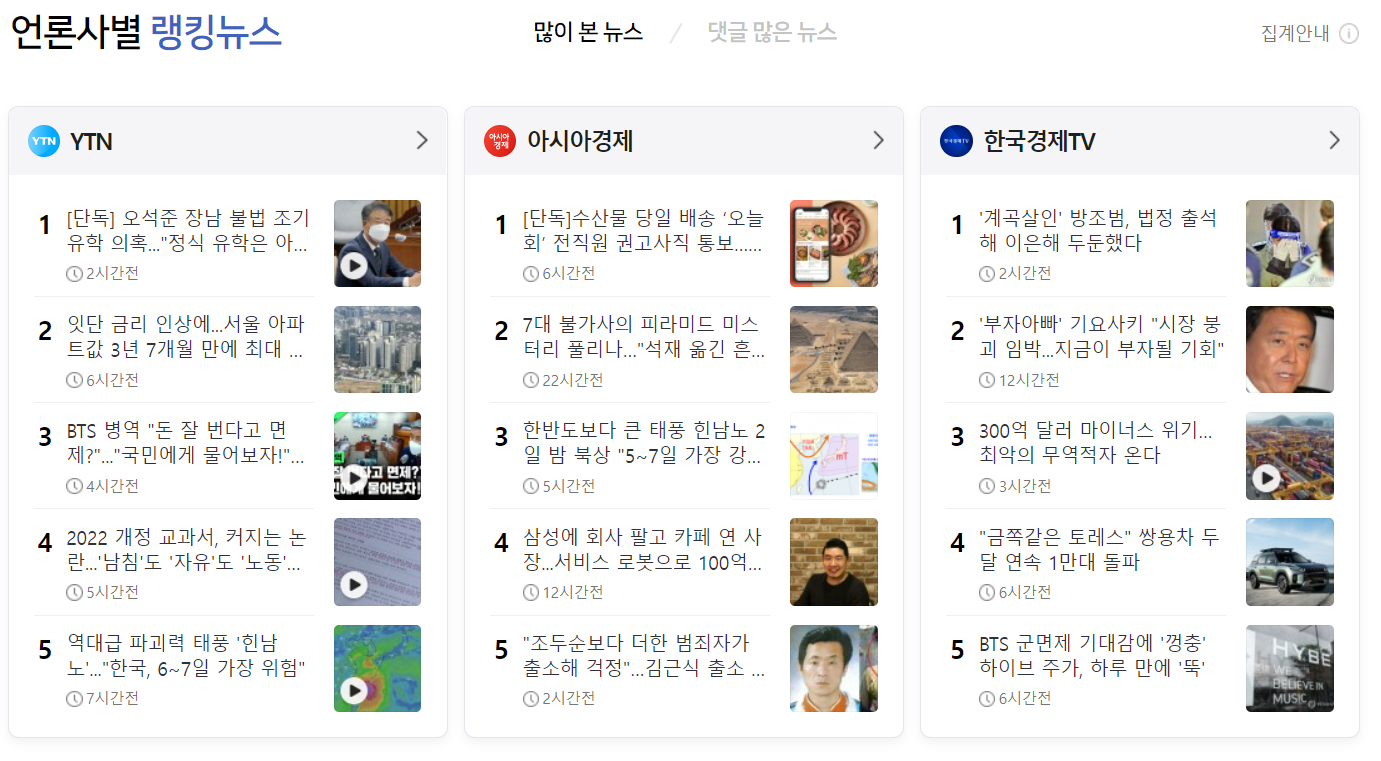
# 1) 데이터 프레임 생성
data = pd.DataFrame(columns=['언론사명', '순위', '기사제목', '기사링크', '수집일자'])
# 2) 네이버 랭킹뉴스 접속주소
url = 'https://news.naver.com/main/ranking/popularDay.naver'
# 3) url에서 html가져오기
html = urlopen(url)
# 4) HTML을 파싱할 수 있는 object로 변환
bsObject = BeautifulSoup(html, 'html.parser',from_encoding='utf-8')
# 5) 네이버 랭킹뉴스 정보가 있는 12개의 div만 가져오기
div = bsObject.find_all('div', {'class', 'rankingnews_box'})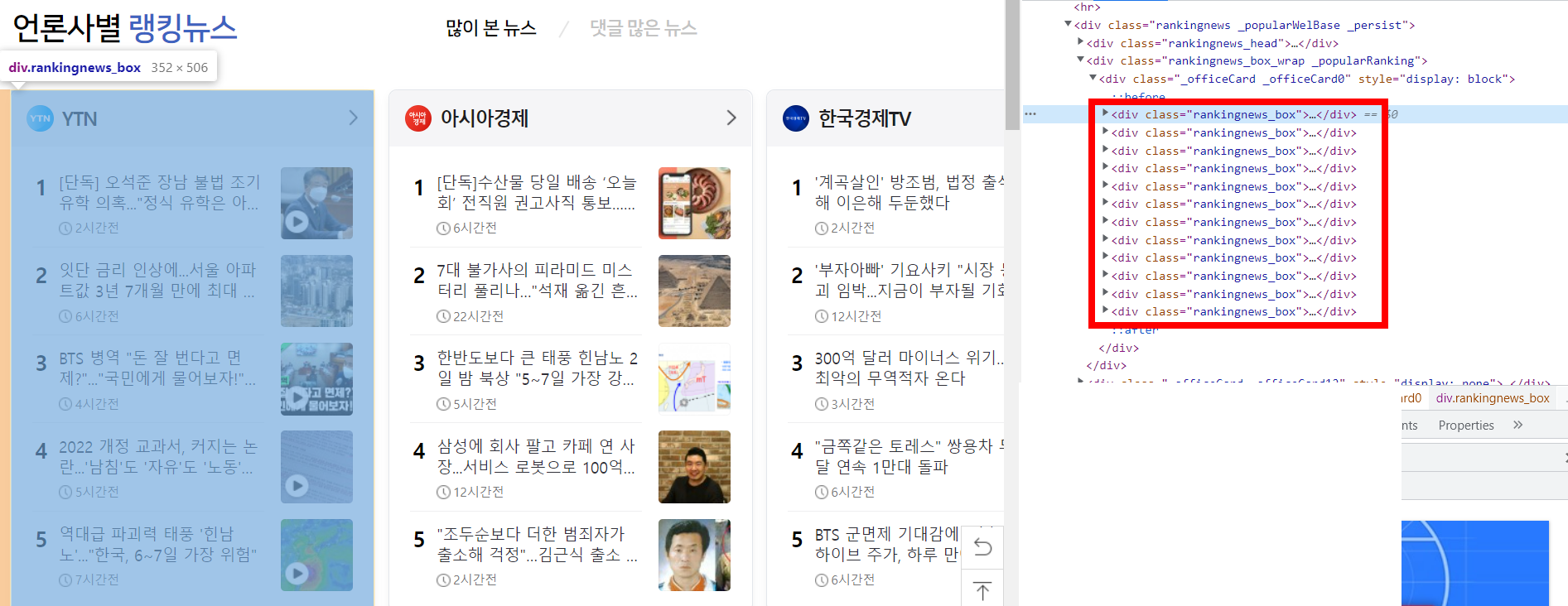 👀 이 div를 가져오는 것❗
👀 이 div를 가져오는 것❗
# 6) 네이버 랭킹뉴스 상세정보 추출
for index_div in range(0, len(div)):
# 6-1) 언론사명 추출
strong = div[index_div].find('strong', {'class','rankingnews_box'})
press = strong.text
👀 여기의 strong 태그로 언론사명을 추출하는 것❗
# 6-2) 랭킹뉴스
ul = div[index_div].find_all('ul',{'class', 'rankingnews_list'})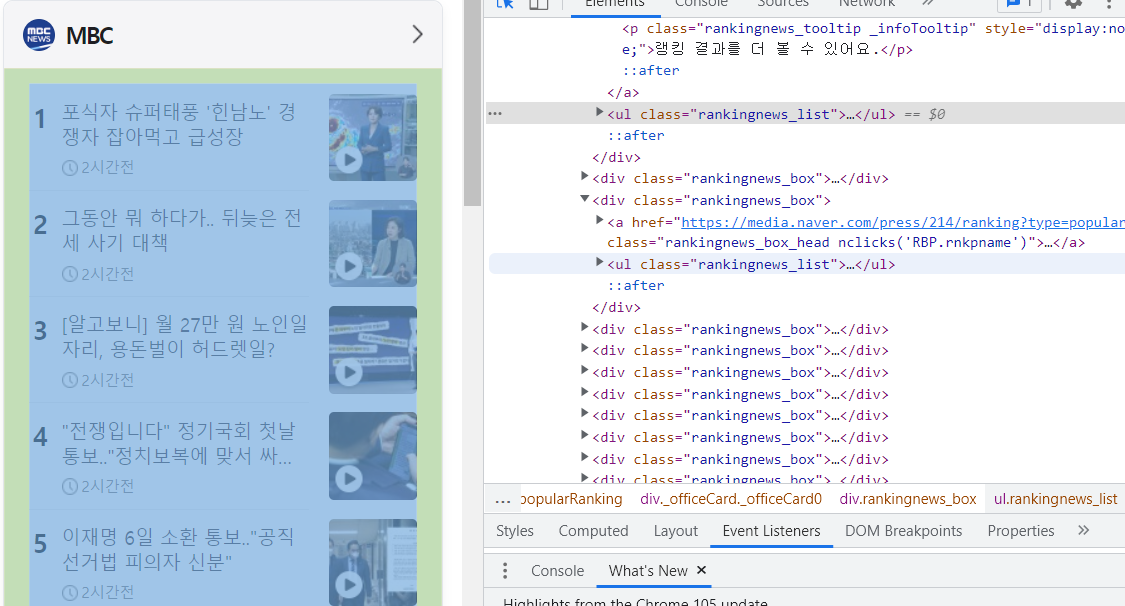
👀 여기의 ul 태그로 랭킹뉴스 추출하는 것 ❗ 밑의 과정도 위와 비슷하니 밑부분의 태그설명 사진은 생략하겠읍니다 . . .
for index_r in range(0, len(ul)):
li = ul[index_r].find_all('li') # 5개의 li태그
for index_l in range(0, len(li)):
try: # 예외처리
# 순위
rank = li[index_l].find('em',{'class', 'list_ranking_num'} ).text
# 뉴스제목
title = li[index_l].find('a').text
# 뉴스링크
link = li[index_l].find('a').attrs['href']
# 7) dataframe 저장(append)
data = data.append({'언론사명':press,
'순위' : rank,
'기사제목':title,
'기사링크': link,
'수집일자': datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S')}, ignore_index=True) # 기존 인덱스 무시
except:
pass # 오류가 나도 계속 진행 (break는 멈춤)
print('Completes of'+rank+' : '+title)
print('----------------------------------')
print(data)👍 전체코드
data = pd.DataFrame(columns=['언론사명','순위','기사제목','기사링크','수집일자']) url = 'https://news.naver.com/main/ranking/popularDay.naver' html = urlopen(url) bsObject = BeautifulSoup(html, 'html.parser',from_encoding='utf-8') div = bsObject.find_all('div', {'class','rankingnews_box'}) for index_div in range(0,len(div)): strong = div[index_div].find('strong', {'class','rankingnews_name'}) press = strong.text ul = div[index_div].find_all('ul',{'class', 'rankingnews_list'}) for index_r in range(0, len(ul)): li = ul[index_r].find_all('li') for index_l in range(0, len(li)): try: rank = li[index_l].find('em',{'class', 'list_ranking_num'} ).text title = li[index_l].find('a').text link = li[index_l].find('a').attrs['href'] data = data.append({'언론사명':press, '순위' : rank, '기사제목':title, '기사링크': link, '수집일자': datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S')}, ignore_index=True) # 기존 인덱스 무시 except: pass # 오류가 나도 계속 진행 (break는 멈춤) print('Completes of'+rank+' : '+title) print('----------------------------------') print(data)
🖨️ 출력

🙉 데이터 저장
data.tocsv('네이버랭킹뉴스댓글많은뉴스_크롤링_20220901.csv', encoding='utf-8-sig', index=False)
👏 댓글많은 뉴스는 많이 본 뉴스 코드에서 링크만 바꿔주면 됨!
✨ 많이 본 뉴스 데이터 준비
df = pd.read_csv('/content/네이버랭킹뉴스_많이본뉴스_크롤링_20220901.csv')
df.head()
🪄 데이터 전처리
df['기사제목'].replace('[^\w]',' ', regex=True, inplace=True)
day_df = pd.read_csv('/content/네이버랭킹뉴스_많이본뉴스_크롤링_20220901.csv')
memo_df = pd.read_csv('/content/네이버랭킹뉴스_댓글많은뉴스_크롤링_20220901.csv')
day_df['기사제목'].replace('[^\w]',' ', regex=True, inplace=True)
memo_df['기사제목'].replace('[^\w]',' ', regex=True, inplace=True)👀 기사제목에서의 특수문자 제거(띄어쓰기 제외)
👁️ 워드클라우드 시각화
😤 라이브러리 임포트
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator🪄 데이터 전처리
# WordCluod 라이브러리에서는 하나의 문자열로 제공해야 함
# 뉴스제목을 하나의 text로 데이터 전처리
day_text = " ".join(li for li in day_df.기사제목.astype(str)) #한 칸 떼고 join
memo_text = " ".join(clean_text(li) for li in memo_df.기사제목.astype(str))

👀 이런식으로 하나의 문자열로 만들어짐!!
🔅 많이 본 뉴스 시각화
plt.subplots(figsize=(25,15))
wordCloud = WordCloud(background_color='black', width=1000, height=700, font_path=fontpath).generate(day_text)
plt.axis('off')
plt.imshow(wordCloud, interpolation='bilinear')
plt.show() 👀 9월 1일 14시 43분 수집
👀 9월 1일 14시 43분 수집
🔆 댓글많은 뉴스 시각화
# 특정 모양을 가진 워드클라우드 만들기
# 마스크 이미지를 찾아서 적용
import numpy as np
from PIL import Image # Python Imaging Library
mask = Image.open('/content/sphx_glr_masked_002.png')
mask = np.array(mask)
plt.subplots(figsize=(15,15))
wordCloud = WordCloud(background_color='white', width=500, height=700, mask=mask,font_path=fontpath).generate(memo_text)
plt.axis('off')
plt.imshow(wordCloud, interpolation='bilinear')
plt.show()
👀 20220901 23시 2분에 데이터 수집
-
많이 본 뉴스

-
댓글 많은 뉴스

언제 수집하냐에 따라 결과는 달라진다는 것을 알 수 있음 ~~!!
글자가 클수록 기사에서 많이 언급(?)됐다는 것
👁️ 네이버 연예랭킹뉴스 크롤링
😤 준비 & 라이브러리 임포트
#이 부분은 처음 한번만 실행하면 됨. 사람이 하는 것처럼 검색하는 특징 탑재
!pip install selenium
!apt-get update
!apt install chromium-chromedriver # 마우스, 키보드 입력 효과 줄 수 있다.
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
# 라이브러리 임포트
from selenium import webdriver
from bs4 import BeautifulSoup
import time
from pytz import timezone
import datetime
import pandas as pd
import warnings
warnings.filterwarnings('ignore')🧜 연예랭킹뉴스 크롤링
# 1 데이터 프레임 준비 드라이버가 크롬을 켜고 3초 쉬고 (로봇 아닌것처럼 보이기 위해)
data = pd.DataFrame(columns = ['순위', '기사제목', '기사링크', '기사내용', '수집일자'])
options = webdriver.ChromeOptions()
options.add_argument('--headless') #
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=options)
driver.get("https://entertain.naver.com/ranking")
driver.implicitly_wait(3)
time.sleep(1.5)
driver.execute_script('window.scrollTo(0, 800)')
time.sleep(3)
html_source = driver.page_source
soup = BeautifulSoup(html_source, 'html.parser')
# class로 css 정의되어있으면 .classname
# id로 css가 정의되어있으면 #idname 로 쓰면 된다.
# div > ul > li 상위 테그가 있으면 상위태그 > 자식태그 > 자식의 자식태그 로 이동가능
li = soup.select('ul#ranking_list > li') # #ranking_list = > id가 ranking_list인거/ ulxprmdml id가 ranking_list인 것들의 li를 가져와줌
for index_l in range(0, len(li)):
try:
# 순위
rank = li[index_l].find('em', {'class', 'blind'}).text.replace('\n', '').replace('\t', '').strip()
# 기사제목
title = li[index_l].find('a', {'class', 'tit'}).text.replace('\n', '').replace('\t', '').strip()
# 기사내용
summary = li[index_l].find('p', {'class', 'summary'}).text.replace('\n', '').replace('\t', '').strip()
# 기사링크
link = li[index_l].find('a').attrs['href']
data = data.append({'순위' : rank,
'기사제목' : title,
'기사링크' : 'https://entertain.naver.com'+link,
'기사내용' : summary,
'수집일자' : datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S')},
ignore_index=True)
print('complets of '+ rank + ' : ' + title)
except:
pass
print('---------------------------------------------------')
print(data)
# 저장
data.to_csv('네이버연예뉴스.csv', encoding='utf-8-sig')👁️ 워드클라우드 시각화
😤 라이브러리 임포트 & 특수문자 제거
# clean_text함수로 특수기호 없애기(전처리 필요없음)
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import re
def clean_text(inputString):
text_rmv = re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', ' ', inputString)
return text_rmv🔅 연예뉴스랭킹 시각화
👀 20220901 23시 2분 기준!
df = pd.read_csv('/content/네이버연예뉴스.csv')
df = df.astype({'기사제목' : 'string'})
df['기사제목'].replace('[^\w]', ' ', regex = True, inplace = True)
text = ' '.join(clean_text(li) for li in df.기사제목.astype(str))
plt.subplots(figsize = (25, 15))
wordcloud = WordCloud(background_color = 'black', width = 1000, height = 700, font_path = fontpath).generate(text)
plt.axis('off')
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.show()
🔆 마스크모양으로 시각화
👀 네이버 댓글많은 뉴스에서 마스크 썼던 것처럼 연예뉴스도 적용
# 특정모양을 가진 워드 클라우드 만들기
import numpy as np
from PIL import Image # Python Imaging Library
mask = Image.open('/content/img3.png')
mask = np.array(mask)
plt.subplots(figsize = (25, 15))
wordcloud = WordCloud(background_color = 'black', width = 500, height = 700, mask = mask, font_path = fontpath).generate(text)
plt.axis('off')
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.show() 👀 탐정모양으로 적용 ~~
👀 탐정모양으로 적용 ~~
🚩 소감 🚩
오늘 하루도 이번주도 정말 길다 . . . . . . 그래도 집와서 오늘 기술 블로그 여기까지 정리한 나 ,, 칭찬해^😛🙃^ 데이터분석시각화 팀프로젝트 한 코드도 정리하려고 했는데 오늘은 너무 피곤해서 뉴스 크롤링 한 부분만 정리 . . ~~ 벌써 내일 금요일인게 믿기지않지만 너무조타.너무너무.그리고너무배고프다 빨리자야지 ㅇ ㅏ 오늘 뉴스들을 워드클라우드로 시각화 하면 글자들이 눈에 딱 보여서 재밌었다. 연예뉴스 크롤링 한 부분이 아직 완벽히 숙지는 안된 것 같으니 주말에 꼭 다시 봐보기 !

배고파용.