🐼 준비
# 한글 패치 import matplotlib as mpl import matplotlib.pyplot as plt %config InlineBackend.figure_format = 'retina' !apt -qq -y install fonts-nanum import matplotlib.font_manager as fm fontpath = '/usr/share/fonts/truetype/nanum/NanumBarunGothic.ttf' font = fm.FontProperties(fname=fontpath, size=9) plt.rc('font', family='NanumBarunGothic') mpl.font_manager._rebuild() # 셀레니움 !pip install selenium !apt-get update !apt install chromium-chromedriver # 마우스, 키보드 입력 효과 줄 수 있다. !cp /usr/lib/chromium-browser/chromedriver /usr/bin # 라이브러리 임포트 및 함수 정의 from selenium import webdriver from bs4 import BeautifulSoup import time from pytz import timezone import datetime import pandas as pd import warnings warnings.filterwarnings('ignore') import matplotlib.pyplot as plt from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator import re def clean_text(inputString): text_rmv = re.sub('[-=+,#/\?:^.@*\"※~ㆍ!』‘|\(\)\[\]`\'…》\”\“\’·]', ' ', inputString) return text_rmv
👄 공감랭킹뉴스 크롤링
💋 어떻게??
- https://entertain.naver.com/ranking/sympathy 이용
- '순위', '공감종류', '기사제목', '기사링크', '기사내용', '공감수', '수집일자' 크롤링
- 사용자에게 보고싶은 뉴스를 입력받기(love, cheer, ...)
- 입력받은 뉴스 워드클라우드 시각화 진행
📎 혼자 해본 코드 (아주 복잡하고 좋은 코드는 아님 !)
# 크롬 브라우저가 뜨지 않고 크롤링 진행
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=options)
# 데이터프레임 생성
data = pd.DataFrame(columns = ['순위', '공감종류', '기사제목', '기사링크', '기사내용', '공감수', '수집일자'])
# 사용자가 원하는 공감 종류 입력받기
# 대문자로 입력할 수도 있으니 lower()을 이용해 소문자로 바꾸어줌
want = input('보고싶은 공감랭킹 뉴스(love, cheer, congrats, expect, surprise, sad) : ').lower()👀 여기까진 괜찮았는데 이 다음 과정에서 공감종류와 공감수를 어떻게 가져와야 할지 막막했다. ㅜ^ㅜ
👀 네이버 공감 종류가 달라질 때마다 주소가 일정 규칙으로 바뀌는 것을 이용해야 함
- 좋아요 : https://entertain.naver.com/ranking/sympathy
- 응원해요 : https://entertain.naver.com/ranking/sympathy/cheer
- 축하해요 : https://entertain.naver.com/ranking/sympathy/congrats
- 기대해요 : https://entertain.naver.com/ranking/sympathy/expect
- 놀랐어요 : https://entertain.naver.com/ranking/sympathy/surprise
- 슬퍼요 : https://entertain.naver.com/ranking/sympathy/sad
- 이렇게 https://entertain.naver.com/ranking/sympathy/ + 감정 종류가 붙음
- 몰랐는데 교수님께서 https://entertain.naver.com/ranking/sympathy/ 뒤에 아무거나 입력해도 좋아요 페이지가 뜬다고 한다.
- https://entertain.naver.com/ranking/sympathy/hihellorwerw 이런거 입력해도 좋아요 페이지가 뜬대요 .........
if want == 'love':
driver.get("https://entertain.naver.com/ranking/sympathy")
num = 0
else:
driver.get("https://entertain.naver.com/ranking/sympathy/" + want)
if want == 'cheer': num = 1
elif want == 'congrats' : num = 2
elif want == 'expect' : num = 3
elif want == 'surprise' : num = 4
else: num = 5👀 일단 아무거나 입력해도 좋아요가 된다는 것을 몰랐을 때는 이렇게 분리해서 코드를 짰다. 이렇게 if문이 많이 중첩되는 경우는 좋지 않은 코드인 걸 알고있었고 .. 교수님도 좋지않은 코드라고 그러셨는데 처음 짰을 때는 도저히 어떻게 짜야할지 모르겠어서 일단 ..........................
driver.implicitly_wait(3)
time.sleep(1.5)
driver.execute_script('window.scrollTo(0, 800)')
time.sleep(3)
html_source = driver.page_source
soup = BeautifulSoup(html_source, 'html.parser')
li = soup.select('ul.news_lst.news_lst3.count_info > li')
clk = soup.select('ul.likeitnews_nav_list > li > a > div.likeitnews_nav_item_name')[num]
for index_l in range(0, len(li)):
try:
# 순위
rank = li[index_l].find('em', {'class', 'blind'}).text.replace('\n', '').replace('\t', '').strip()
# 공감종류
thumb = clk.text.replace('\n', '').replace('\t', '').strip()
# 기사제목
title = li[index_l].find('a', {'class', 'tit'}).text.replace('\n', '').replace('\t', '').strip()
# 기사내용
summary = li[index_l].find('p', {'class', 'summary'}).text.replace('\n', '').replace('\t', '').strip()
# 공감수
like = soup.select('div.tit_area > a')[2*index_l+1].text.replace('\n', '').replace('\t', '').strip()
like = like[3:]
# 기사링크
link = li[index_l].find('a').attrs['href']
data = data.append({'순위' : rank,
'기사제목' : title,
'공감종류' : thumb,
'기사링크' : 'https://entertain.naver.com'+link,
'기사내용' : summary,
'공감수' : like,
'수집일자' : datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S')},
ignore_index=True)
print('complets of '+ rank + ' : ' + title)
except:
pass
print('---------------------------------------------------')
print(data)
# 저장
data.to_csv('one.csv', encoding='utf-8-sig')👀 여기서 공감종류와 공감수 때문에 네시간 .......... . ..
공감종류 설명
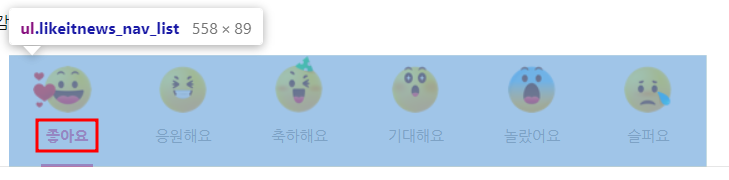 ⬆️ 이 박스에서 글자를 추출
⬆️ 이 박스에서 글자를 추출
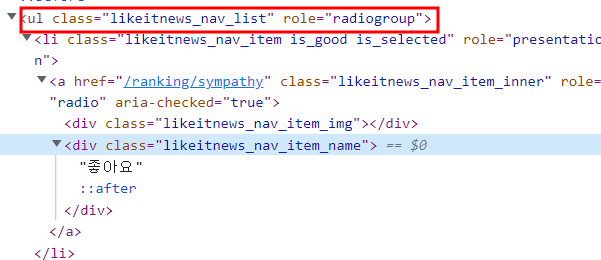
# class명이 likeitnews_nav_list인 ul태그의 자식 타고타고 class명이 likeitnewss_nav_item_name 인 div태그에 도착
# 처음에 사용자에게 입력받은 공감 종류에 따라 부여한 num 값으로 글자 추출
# 진짜 내가 생각해도 어거지로 쥐어짠 코드라고 생각함미다 . . ..
clk = soup.select('ul.likeitnews_nav_list > li > a > div.likeitnews_nav_item_name')[num]공감수 설명
 ⬆️ 이 공감수 text를 추출
⬆️ 이 공감수 text를 추출
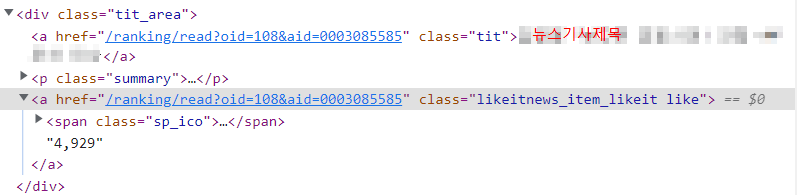 👀 저기서 4929를 가져와야 함 쟤는 span태그 안이 아니라 a태그 이용해서 가져와야 하는데 .. 방법을 도저히 모르겠었다.
👀 저기서 4929를 가져와야 함 쟤는 span태그 안이 아니라 a태그 이용해서 가져와야 하는데 .. 방법을 도저히 모르겠었다.
# tit_area 클래스명을 가진 div태그의 자식인 a태그도착~~
#
like = soup.select('div.tit_area > a') 👀 계속 도전하다가 겨우 방법 발견........~~ 별로인건 알았지만 최선이었닥.
 ⬆️ 이건 기사들이에여
⬆️ 이건 기사들이에여
 soup.select 뒤의 대괄호에 2*순위(0부터29까지)+1을 한 숫자를 넣으면 해당 기사의 공감 수가 포함된 문자열이 출력된다는 걸 알았다 ㅋㅋㅋㅋ ㅜㅜ 완전 어거지죠 ..?저도알아여..^^ 그때는 이게 최선이었답니다^~^!! 그래서 밑의 코드가 나온거예여
soup.select 뒤의 대괄호에 2*순위(0부터29까지)+1을 한 숫자를 넣으면 해당 기사의 공감 수가 포함된 문자열이 출력된다는 걸 알았다 ㅋㅋㅋㅋ ㅜㅜ 완전 어거지죠 ..?저도알아여..^^ 그때는 이게 최선이었답니다^~^!! 그래서 밑의 코드가 나온거예여
like = soup.select('div.tit_area > a')[2*index_l+1].text.replace('\n', '').replace('\t', '').strip()
# '글자수' 라는 문자열을 빼기위한 슬라이싱
like = like[3:] 👁️ 워드클라우드 시각화
data.to_csv('one.csv', encoding='utf-8-sig')
df = pd.read_csv('/content/one.csv', index_col = 0)
df = df.astype({'기사제목' : 'string'})
df['기사제목'].replace('[^\w]', ' ', regex = True, inplace = True)
text = ' '.join(clean_text(li) for li in df.기사제목.astype(str))
plt.subplots(figsize = (25, 15))
wordcloud = WordCloud(background_color = 'black', width = 1000, height = 700, font_path = fontpath).generate(text)
plt.axis('off')
plt.imshow(wordcloud, interpolation = 'bilinear')
plt.show()👀 surprise(놀랐어요) 20220908/23:02시에 크롤링

🛎️ 교수님 코드
data = pd.DataFrame(columns = ['순위', '공감종류', '기사제목', '기사링크', '기사내용', '공감수', '수집일자'])
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=options)
# 먼저 공감종류를 리스트에 저장
url_list = ['', '/cheer', '/congrats', '/expect','/surprise','/sad']
for n in range(0, len(url_list)):
url = 'https://entertain.naver.com/ranking/sympathy'
url += url_list[n] # 기본 url과 각각 공감종류 연결
sympathy = 'love'
# 공감 종류 추출 하기
if url_list[n] !='':
sympathy = url_list[n].replace('/','') # 공감종류 리스트에서 /를 떼서 영어만 남기기
print('수집 중 .. ' + url)
driver.get(url)
driver.implicitly_wait(3)
time.sleep(1.5)
driver.execute_script('window.scrollTo(0, 800)')
time.sleep(3)
html_source = driver.page_source
soup = BeautifulSoup(html_source, 'html.parser')
li = soup.select('li._inc_news_lst3_rank_reply')
for n in range(0, len(li)):
try:
# 순위
rank = li[n].find('em', {'class', 'blind'}).text.replace('\n', '').replace('\t', '').strip()
# 기사제목
title = li[n].find('a', {'class', 'tit'}).text.replace('\n', '').replace('\t', '').strip()
# 기사내용
summary = li[n].find('p', {'class', 'summary'}).text.replace('\n', '').replace('\t', '').strip()
# 뉴스 링크
link = li[n].find('a').attrs['href']
# 공감 수
# 밑의 과정만 수행하게 되면 '공감수7' 과 같이 '공감수'라는 문자열이 붙어서 추출됨
temp_cnt = li[n].find('a', {'class','likeitnews_item_likeit'}).text.replace('\n','').replace('\t', '').strip()
# 따라서 밑의 과정을 시행하여 문자를 제거함
cnt = re.sub(r'[^0-9]','',temp_cnt)
data = data.append({'순위' : rank,
'기사제목' : title,
'공감종류' : sympathy,
'기사링크' : 'https://entertain.naver.com'+link,
'기사내용' : summary,
'공감수' : cnt,
'수집일자' : datetime.datetime.now(timezone('Asia/Seoul')).strftime('%Y-%m-%d %H:%M:%S')},
ignore_index=True)
print('complets of '+ rank + ' : ' + title)
except:
pass
print('-------------------')
input_sympathy = input('공감 종류 입력 : ')
# 워드클라우드
# data의 공감종류와 입력받은 공감종류가 같은 것만 워드클라우드 시각화
text = ''.join(li for li in data[data.공감종류 == input_sympathy].기사제목.astype(str))
plt.subplots(figsize=(25,15))
wordcloud = WordCloud(background_color='black', width=1000, height=700, font_path=fontpath).generate(text)
plt.axis('off')
plt.imshow(wordcloud, interpolation='bilinear')
plt.show()👀 상상도 못해봤던 코드라 신기하고 새롭다 .. ㅎㅎ.
re.sub
- 교수님 코드에서 문자 제거할 때 쓰임
- re.sub('찾을 패턴', '찾은 패턴을 변경할 내용', '원본')
[^0-9] 숫자를 제외한 문자열
🚩 소감 🚩
내가 코드를 먼저 짜봤을 때 웹 페이지의 구성이 조금만 바뀌면 사용할 수 없는 코드일 정도로 잘못짰다고 생각은했다. 근데 그때는 일단 당장은 돼서 좋았다^!^!! 어거지였더라도 성공했으니까 뿌듯했었다 그래도 좋은 시도였당 ㅎㅎ.. 교수님 코드를 보고 정말 많이 공부해야겠다고 느꼈다. 교수님 처음에는 코드 이해하기 어려웠는데 벨로그 정리해보니 이해쌉가능🤪. 역시 아는거랑 이해하는게 많아야 이렇게도 생각해보고 저렇게도 생각해볼 수 있군.. 😇 오늘 열심히정리했다 내일 유튜브 댓글 크롤링만 정리해야지 ~
