1. 컴퓨터의 세대별 진화
| 세대 | 연도 | 주요 기술 | 대표 특징 |
|---|---|---|---|
| 1세대 | 1946~1957 | 진공관 | ENIAC, UNIVAC, Fortran 등장 |
| 2세대 | 1957~1964 | 트랜지스터 | 저전력, 소형화, IBM 7000 |
| 3세대 | 1965~1971 | SSI (소규모 집적 회로) | 수천 개 트랜지스터 집적 |
| 4세대 | 1972~1977 | LSI (대규모 집적) | 1만 개 트랜지스터 가능 |
| 5세대 | 1978~1991 | VLSI | 수천만 개 트랜지스터 집적 |
| 6세대 | 1991~현재 | ULSI | 수십억 개 트랜지스터 집적 |
2. Von Neumann vs. Harvard 구조 비교
항목 Von Neumann Harvard
구조 명령어와 데이터 메모리 공유 명령어와 데이터 메모리 분리
성능 느림 (병목 현상) 빠름 (병렬 접근 가능)
제어 간단 복잡
🔥 Von Neumann 병목(Bottleneck) 해결을 위해 캐시 메모리와 계층 구조가 도입됨.
3. 무어의 법칙 & 데너드 스케일링
• 무어의 법칙: 트랜지스터 수는 약 18~24개월마다 2배 증가
• Dennard Scaling: 트랜지스터 작아질수록 전력·전압 ↓, 주파수 ↑💡 전력 공식
Power = α × C × F × V²4. Power Wall (전력의 벽)
• 전력 누설 & 발열 문제로 인해 더 이상 클럭 속도 증가 불가
• 2003년 이후부터 주파수 증가 정체| 연도 | 클럭 속도 | 코어 수 | 유효 사이클 타임 |
|---|---|---|---|
| 2003 (P-4) | 3300 MHz | 1 | 0.3 ns |
| 2010 (i7) | 2500 MHz | 4 | 0.1 ns |
5. 멀티코어 시대의 도래

• 단일 코어 성능 향상의 한계 → 여러 코어를 한 칩에 탑재
• 명시적 병렬 프로그래밍 필요 (ILP → TLP)
• 성능 최적화와 부하 분산, 동기화가 병렬 프로그래밍의 핵심 과제
6. 차세대 아키텍처: 새로운 프론티어
Cerebras WSE
• 웨이퍼 전체를 칩으로 사용 (850,000코어)
• 2.6조 트랜지스터, 40GB 온칩 SRAM
• 대역폭: 20PB/s
• GPT-3급 AI 모델도 학습 가능
Exascale Computing
• ExaFLOPS 시대 (10¹⁸ FLOPS)
• Frontier (2022) 세계 최초 엑사스케일 슈퍼컴퓨터
Quantum & Bio Computing
• Quantum: 초전도 큐비트, 병렬성 극대화
• Bio: DNA/RNA 기반 논리 연산, 생체 내 연산 가능
7. 성능 병목 (Bottlenecks)
CPU - Memory Gap
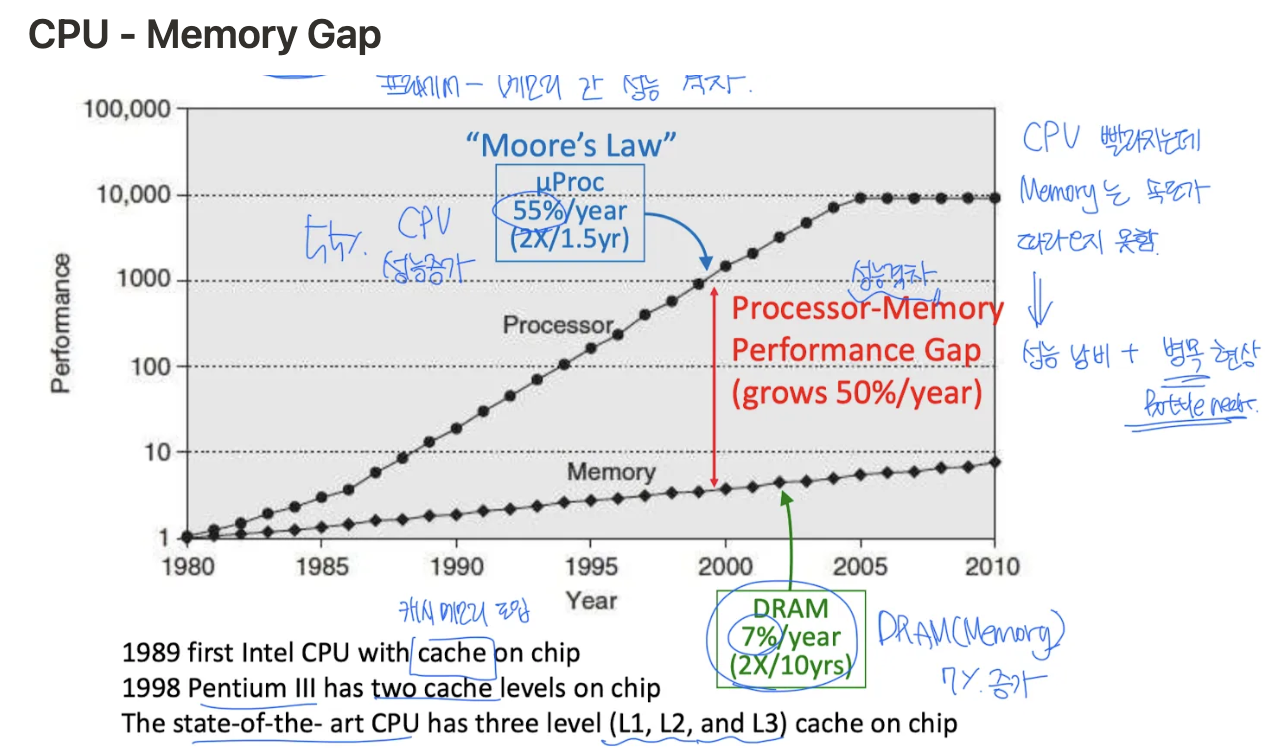
• CPU 성능: 연 55% 증가
• DRAM 속도: 연 7% 증가 → 격차 확산
해결책: L1~L3 캐시 계층 구조
CPU - Memory - Disk Gap
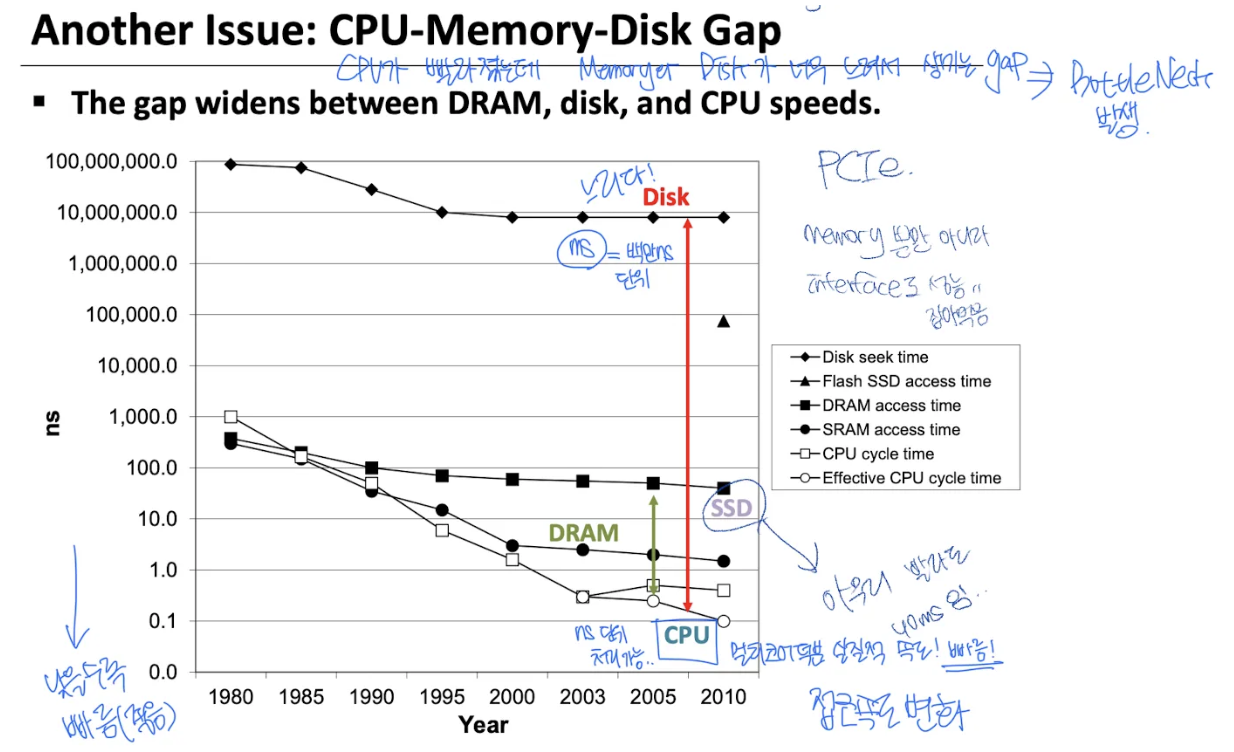
• 속도 순: CPU > SRAM > DRAM > SSD > HDD
• HDD는 수백만 ns 지연 → 병목 극심
해결책: 계층적 메모리 구조
Bandwidth vs. Latency
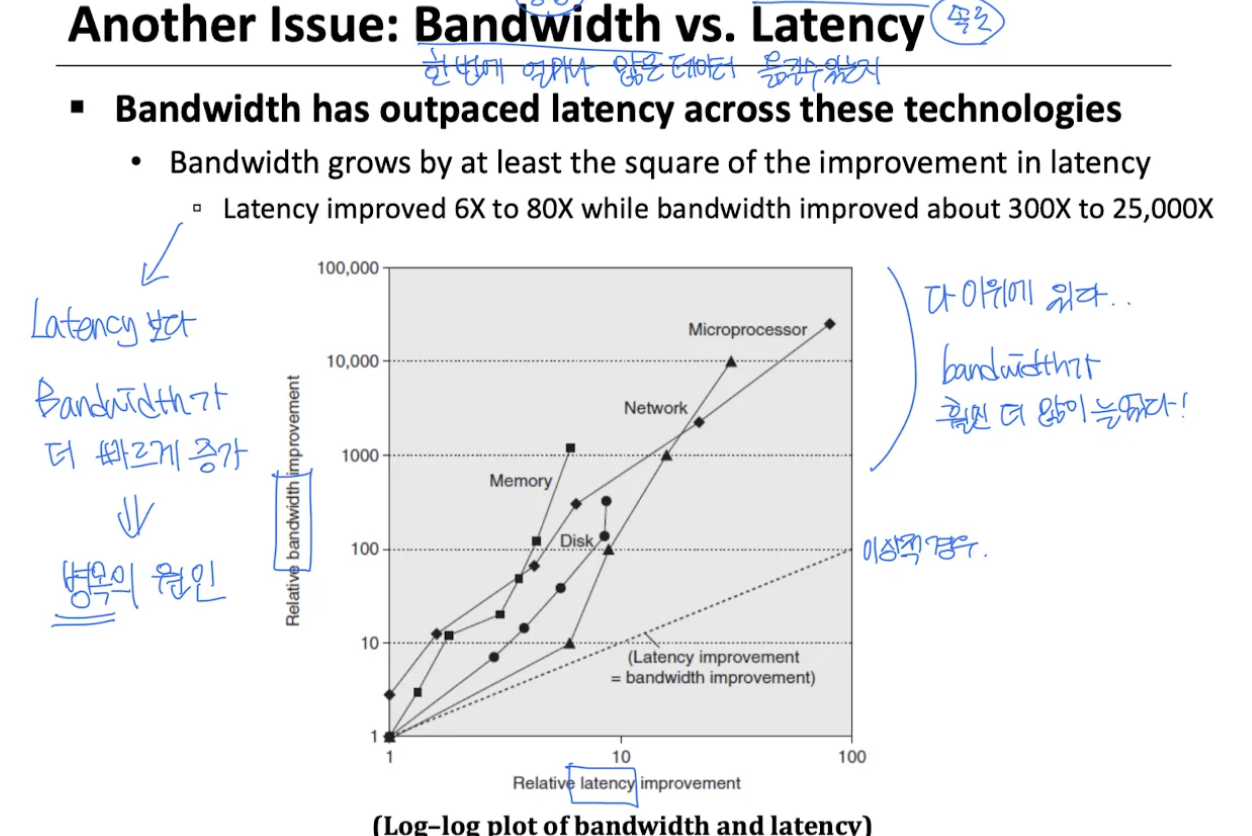
• Bandwidth: 수천~2.5만배 향상
• Latency: 고작 6~80배 향상✔️ 두 성능 지표 간 불균형 심화
