기계공학과 연구실과 협업 연구과제를 하면서 IR 이미지에 대한 객체인식을 위해 FLIR데이터셋 커스텀학습이 필요하게 되었다.
FLIR데이터셋은 공개된 데이터로 쉽게 구할 수 있었다.
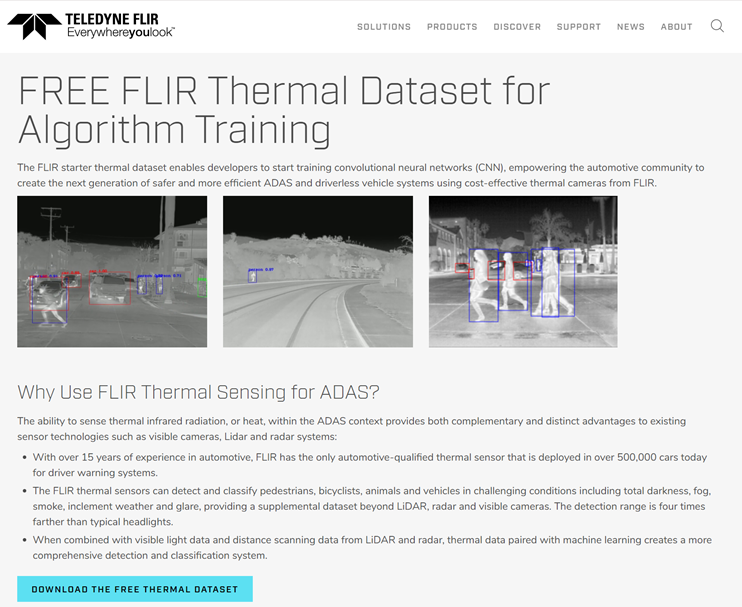

해당 데이터셋은 json 형식이며 coco 포맷이었다.
coco는 xmin ymin width height 이다.
yolo는 center x center y width height 이며 각각 이미지 크기의 비율
json은 처음 보았을 때, 어렵게 보였지만. 자세히 보면 python 딕셔너리 자료형과 리스트들의 조합이다.
즉, key와 values로 이루어진 자료라고 생각하면 전처리하기가 훨씬 용이하다.
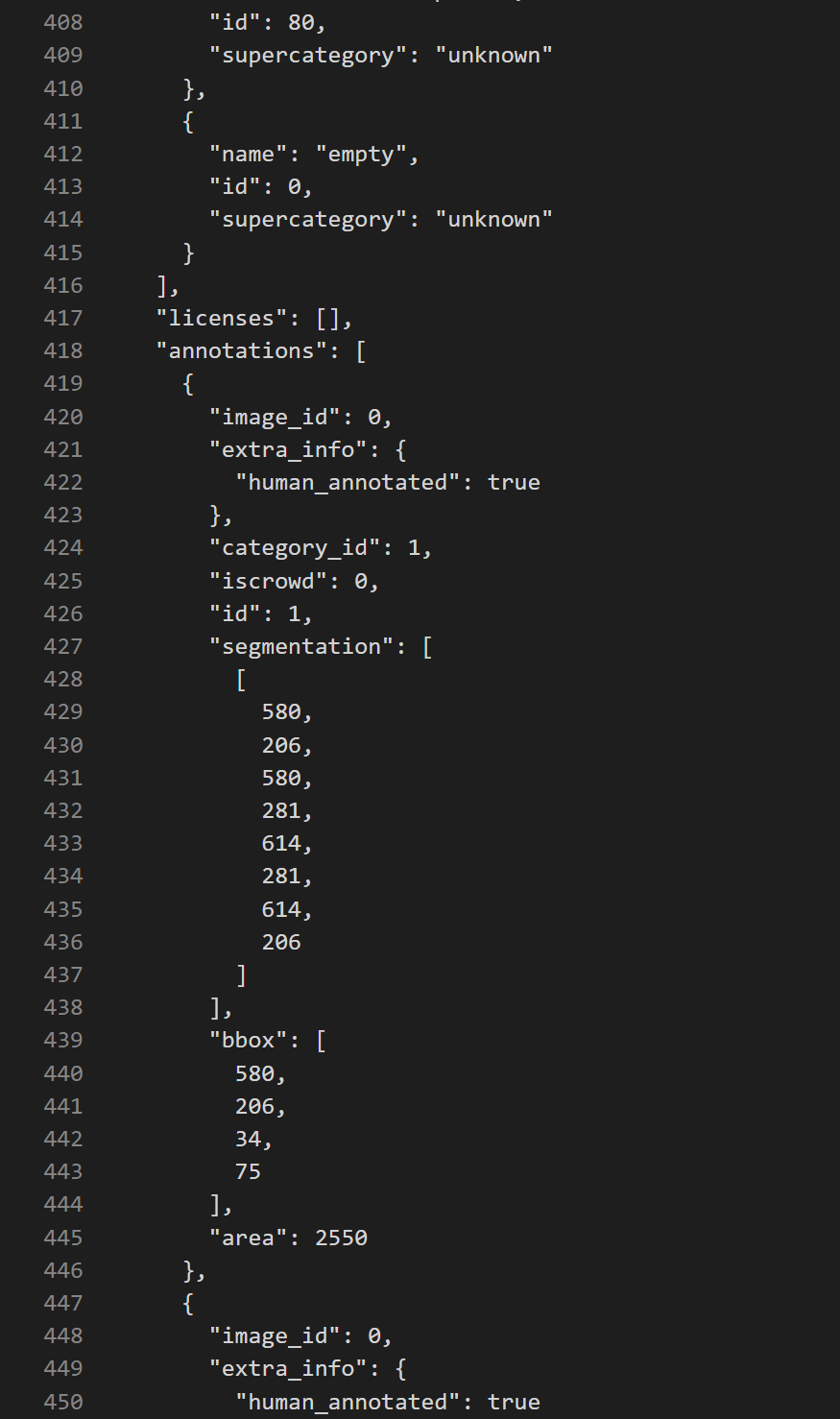
다음과 같이 annotation 파일 하나에 모든 이미지에 대한 라벨 정보가 들어 있다.
전처리 코드
import json
def convert(size, box): #box: coco형식 xmin , ymin , w , h
dw = 1/size[0]
dh = 1/size[1]
w = box[2]
h = box[3]
x = box[0]+ w/2
y = box[1]+ h/2
x = round(x*dw,6)
w = round(w*dw,6)
y = round(y*dh,6)
h = round(h*dh,6)
if w <0 or h < 0:
return False
return (x,y,w,h)
with open('./val_annotation.json') as f:
data=json.load(f)
## 라벨 추출
# label_list=open('label_list.txt','w')
# for i in data['categories']:
# label_name=i['name']
# label_id=i['id']
# line=f'{label_name}\n'
# label_list.write(line)
# label_list.close()
size=[640,512]
#annotation 분리
for i in data['annotations']:
file_number=i['image_id']+8863
file_number=f'label_val/FLIR_{file_number:0>5}.txt'
b=i['bbox']
bb=convert(size, b)
if bb==False:
continue
label_file=open(file_number,'a')
label_number=i['category_id']
line=f'{label_number} {bb[0]} {bb[1]} {bb[2]} {bb[3]}\n'
label_file.write(line)
label_file.close()
progress=i['id']
print(f'{progress}/11696')
print('finish')다음과 같이 각 이미지 마다 txt 라벨 파일을 만들어 주었다.

공부노트