보행자 데이터셋 전처리하기
보행자 데이터셋 Link
https://data.vision.ee.ethz.ch/cvl/aess/dataset/
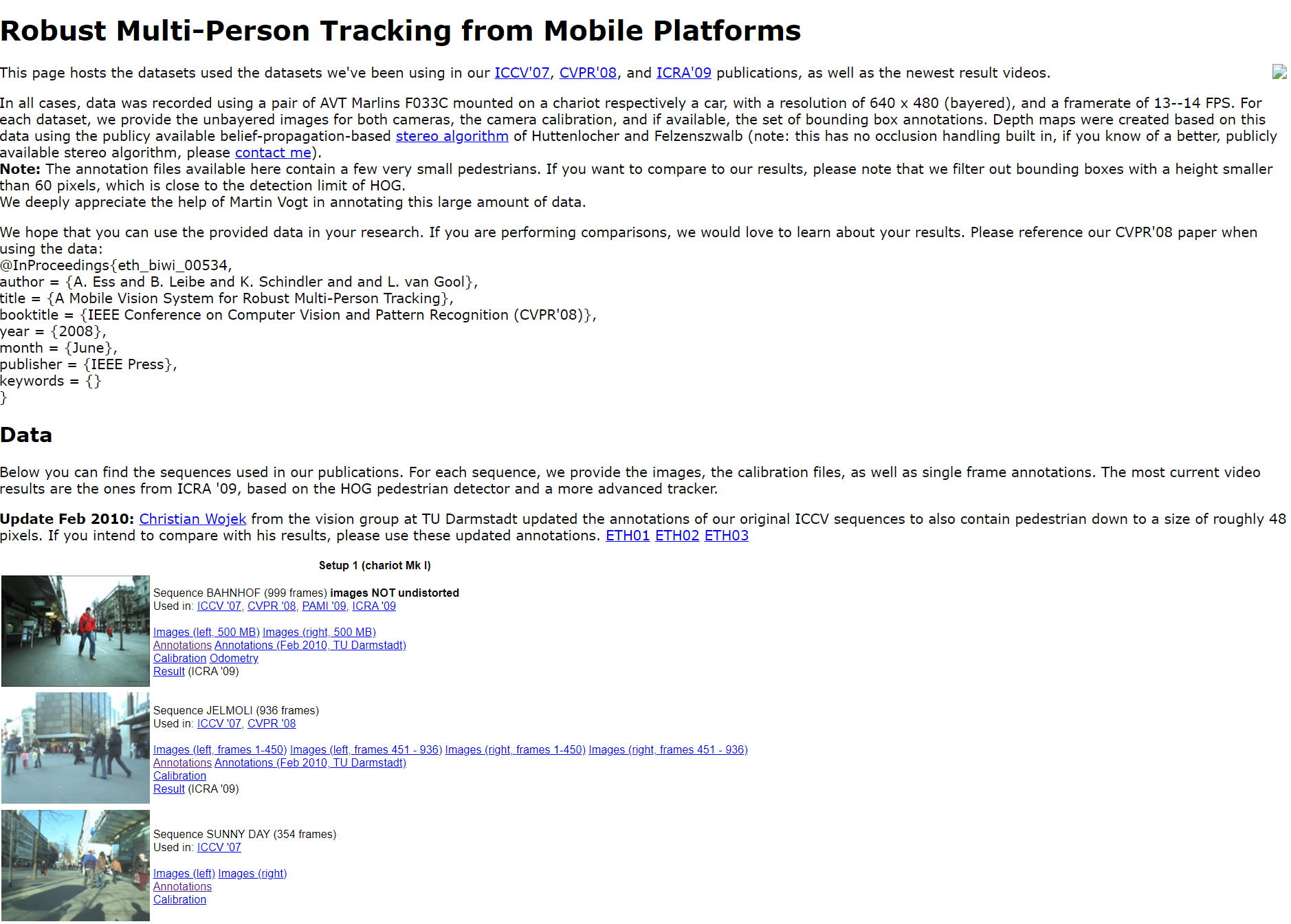

위 데이터의 사진들을 보니 이미지 수는 작지만 instance수가 많아 해당 데이터들을 사용하기로 했다. 내가 사용한 이미지는 총 2601장이다. 하지만 instance로만 따지만 1만정도 되기 때문에 학습에는 충분할 것이라고 생각되었다. 그래서 annotion 파일을 확인해 보니 .idl 형식이였다.

그래도 라벨링 형식 자체는 그 전과 같이 xmin, ymin, xmax, ymax 인 것을 확인하여, txt 파일로 변환 후 전에 했던 것과 같이 코드를 수정해 전처리를 진행했다.
- 전처리 코드
import os
from PIL import Image
output_dir = 'pedestrain4/output/'
img_dir = 'pedestrain4/images/'
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = round(x*dw,6)
w = round(w*dw,6)
y = round(y*dh,6)
h = round(h*dh,6)
if w <0 or h < 0:
return False
return (x,y,w,h)
f_input = open('pedestrain4/annos4.txt','r')
items=f_input.readlines()
if not os.path.exists(output_dir):
os.makedirs(output_dir)
for item in items:
#이미지 이름 가져오기
data=item.split(':')
img_name=data[0].split('/')
file_name=img_name[1][:-5]
#이미지 사이즈 가져오기
image = Image.open(img_dir+file_name+'.png')
width = int(image.size[0])
height = int(image.size[1])
#바운딩박스 위치 가져오기 및 변환
info=data[1].split('(')
bound=[]
for i in info[1:]:
j=i[:-3].split(', ')
xmin = j[0]
xmax = j[2]
ymin = j[1]
ymax = j[3]
b = (float(xmin), float(xmax), float(ymin), float(ymax))
bb = convert((width, height), b)
if bb == False:
continue
bound.append(bb)
#변환한거 저장하기
f = open(output_dir + file_name + '.txt', 'w')
for k in bound:
f.write('4' + " " + " ".join([str(a) for a in k]) + '\n')
print(file_name+' '+'complete')이전 글(yolov5 custom train2)에 썻던 코드를 베이스로 여러개의 instance를 하나의 txt에 담아내기 위해 for문을 추가했다. 또한 이미지크기보다 라벨범위가 넘어간 것이 있어 실제 라벨파일에는 음수가 나오는 경우가 있었다. 따라서 convert 메소드에
if w <0 or h < 0:
return False을 추가해 주어 라벨이 음수인 경우에는 continue를 실행하도록 하였다.
- 전처리 결과
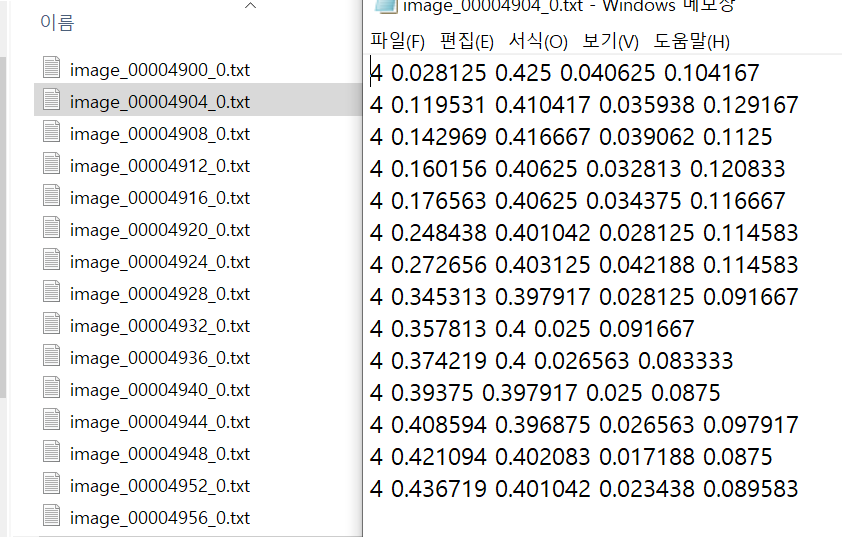

yolov5 custom train1, 2, 3에서의 전처리한 데이터를 종합해하여 yolov5 custom train을 다시 진행하고 있다. 아직은 학습 중이기 때문에, 학습이 완료되는 대로 글을 추가하겠다.

공부노트