[논문 리뷰]Object Recognition in Very Low Resolution Images Using Deep Collaborative Learning
PaperReview
현재 연구실에서 DBPN+YOLO의 통째학습에 대한 연구과제를 진행하는데 해당 논문과 유사하여 리뷰를 하게 되었다. SR모델과 객체인식모델의 통째 학습에 중점을 두고 리뷰를 하는 것이므로 SR과 객체인식에 대한 부분은 되도록 생략한다.

ABSTRACT
본 논문은 image enhancement network(이하 초해상도 네트워크)와 object recognition network(이하 객체인식 네트워크)의 공동학습을 통해 저해상도 이미지에 대한 객체인식을 제안한다. 논문에서 제시된 이미지 향상 네트워크는 객체 인식 네트워크의 통째 학습 신호를 사용하여 저해상도의 이미지를 더 선명하고 더 많은 정보를 제공하는 이미지로 개선한다. 고해상도 이미지에 대해 훈련된 가중치를 가진 객체 인식 네트워크는 초해상도 네트워크의 학습에 관여한다. 또한 초해상도 네트워크의 출력을 augmented 데이터로 활용하여 저해상도 이미지에 대한 객체인식 성능을 높인다. 다양한 저해상도 영상 dataset에 대한 실험을 통해 제안된 방법이 영상 재구성 및 분류 성능을 향상시킬 수 있음을 확인했다.
1. INTRODUCTION
저해상도 이미지에 대한 객체인식 성능을 향상 시키려면, Super-resolution(초해상도/이하 SR) 기술이 인식 단계전에 적용되어야 한다. SR 기술은 기존에 나와있는 방법을 사용했다. 그러나 기존 SR 방법은 작은 패치의 영상 화질을 향상시키는데 초점을 두었다. 즉, 전체 영상에서 유용한 객체 정보를 추출할 필요는 없다. 또한 이러한 방법은 semantic 정보를 고려하지 않으며, 이는 noise까지도 재구성할 수 있다는 것을 의미한다. 이는 객체 인식 관점에서 바람직하지 않다. 따라서 저해상도 영상에 대한 인식 성능을 높이기 위해서는 지각적으로 의미 있는 정보를 추출하는 데 집중함으로써 보다 적극적인 초해상도 방법을 개발할 필요가 있다. 이러한 점을 고려하여, 매우 저해상도 이미지(8x8 픽셀)에서 객체 인식을 위한 통합 프레임워크를 제안한다. 이 프레임워크는 영상 향상 네트워크(IEN:image enhancement network)와 객체인식 네트워크라는 두개의 심층 신경망의 협업 훈련(통째 학습)을 기반으로 한다. IEN은 저해상도 이미지를 객체 인식 네트워크에 입력할 수 있는 해석이 가능한 이미지로 개선하도록 새로 설계 되었다. 제안된 IEN의 기본 구조에는 SR에 관한 다양한 연구에서 영감을 받았으며, 객체 인식에 중요한 글로벌 컨텍스트 정보 추출을 위한 추가적인 컨볼루션 블록을 포함한다. 또한, 우리는 일반적인 SR loss와 공동 객체 인식 네트워크와 관련된 추가 loss를 결합하여 IEN 교육을 위한 새로운 손실 함수를 제안한다. 객체 인식 네트워크는 기존의 well-trained 모델을 기반으로하며, 사전 교육된 네트워크의 기능을 효율적으로 활용하고 저해상도 이미지에 대한 인식 성능을 높이는 체계적인 재교육 전략을 제안한다. 이러한 전략을 통해 객체 인식 네트워크는 train용 신호를 제공하여 IEN을 돕고, 훈련 받은 IEN의 출력을 객체 인식을 위한 추가 교육 데이터로 사용한다. 협업 학습(통째 학습) 과정을 통해 제안된 모델이 저해상도 및 고해상도 이미지에서 높은 성능을 달성할 수 있을 것으로 예상한다.
그러나 기존 SR 방법은 작은 패치의 영상 화질을 향상시키는데 초점을 두었다. 즉, 전체 영상에서 유용한 객체 정보를 추출할 필요는 없다. 또한 이러한 방법은 semantic 정보를 고려하지 않으며, 이는 noise까지도 재구성할 수 있다는 것을 의미한다. 이는 객체 인식 관점에서 바람직하지 않다. 따라서 저해상도 영상에 대한 인식 성능을 높이기 위해서는 지각적으로 의미 있는 정보를 추출하는 데 집중함으로써 보다 적극적인 초해상도 방법을 개발할 필요가 있다. 이러한 점을 고려하여, 매우 저해상도 이미지(8x8 픽셀)에서 객체 인식을 위한 통합 프레임워크를 제안한다. 이 프레임워크는 영상 향상 네트워크(IEN:image enhancement network)와 객체인식 네트워크라는 두개의 심층 신경망의 협업 훈련(통째 학습)을 기반으로 한다. IEN은 저해상도 이미지를 객체 인식 네트워크에 입력할 수 있는 해석이 가능한 이미지로 개선하도록 새로 설계 되었다. 제안된 IEN의 기본 구조에는 SR에 관한 다양한 연구에서 영감을 받았으며, 객체 인식에 중요한 글로벌 컨텍스트 정보 추출을 위한 추가적인 컨볼루션 블록을 포함한다. 또한, 우리는 일반적인 SR loss와 공동 객체 인식 네트워크와 관련된 추가 loss를 결합하여 IEN 교육을 위한 새로운 손실 함수를 제안한다. 객체 인식 네트워크는 기존의 well-trained 모델을 기반으로하며, 사전 교육된 네트워크의 기능을 효율적으로 활용하고 저해상도 이미지에 대한 인식 성능을 높이는 체계적인 재교육 전략을 제안한다. 이러한 전략을 통해 객체 인식 네트워크는 train용 신호를 제공하여 IEN을 돕고, 훈련 받은 IEN의 출력을 객체 인식을 위한 추가 교육 데이터로 사용한다. 협업 학습(통째 학습) 과정을 통해 제안된 모델이 저해상도 및 고해상도 이미지에서 높은 성능을 달성할 수 있을 것으로 예상한다.
2. PROPOSED METHOD
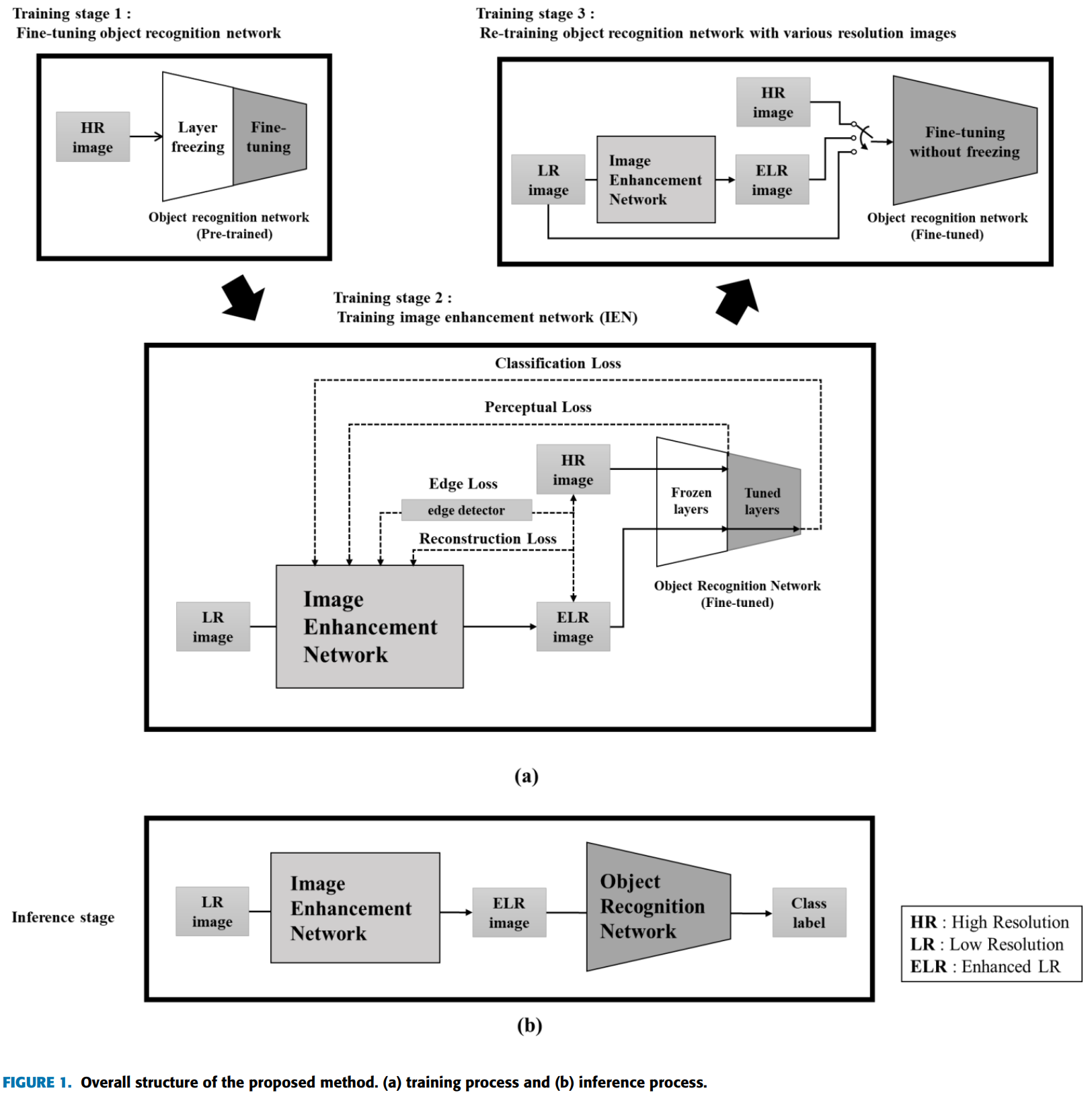
제안된 모델의 전체적인 구조와 훈련 및 추론은 그림 1에 설명되어 있다. 그림 1(b)에서 볼 수 있듯이, 전체 모델은 두개의 네트워크, 즉 IEN과 객체 인식 네트워크로 구성되어 있다. 제안된 IEN은 객체 인식에 사용할 수 있게 저해상도 이미지를 개선하도록 새롭게 설계되었다. 픽셀 단위 거리를 최소화하여 패치별로 재구성을 수행하는 기존의 SR과 달리, 제안된 IEN은 perceptual fidelity를 극대화하여 전체 영상에서 개체 정보를 재구성한다. 객체 인식 네트워크의 경우, 객체 인식 과정에서 일반화의 이점을 가질 수 있도록 잘 훈련된 기존 모델을 채택했다. 추론 단계의 처리 흐름은 두 네트워크의 단순한 조합으로 표현된다. Training 단계에서, 두 네트워크는 각 네트워크의 성능을 향상시키고 궁극적인 목표를 달성하기 위해 상호작용적으로 협력한다.
-
Training stage 1
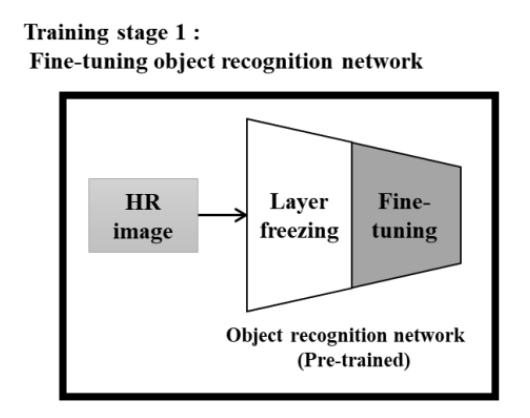
매우 낮은 해상도의 영상에서 객체인식의 정확도를 최대화하는 궁극적인 목표를 달성하기 위해, 교육과정은 그림 1(a)와 같이 3단계로 구성된다. 교육 1단계에서는 특정 데이터셋의 고해상도(HR)영상을 사용하여 잘 훈련된 파라미터가 포함된 기존 객체 인식 네트워크를 가져오고 fine-tuning을 진행한다. 이 fine-tuning 단계에서는 네트워크의 초기 계층을 freeze하여 대규모 데이터베이스를 사용한 학습을 통해 얻을 수 있는 객체 인식 네트워크의 일반적인 기능을 보존한다. 이 첫 번째 교육 단계는 특정 HR 이미지에서 양호한 인식 성능을 가진 객체 인식 네트워크를 생성하며, 두 번째 단계에서는 IEN 학습을 위한 guiding signals을 생성한다. -
Training stage 2
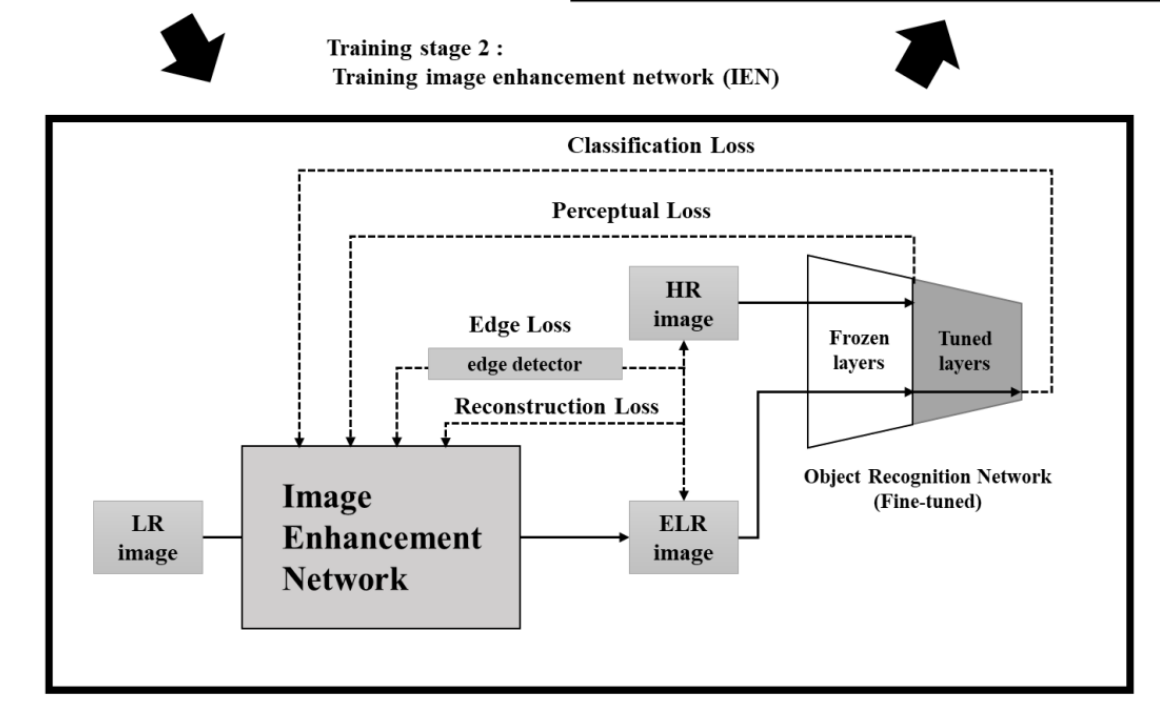
해당 단계에서는 객체 인식 네트워크의 가중치를 freeze하고 IEN은 입출력 교육 샘플과 객체 인식 네트워크를 사용하여 supervised하는 방식으로 훈련된다. 그림 1(a)에 표시된 것처럼 IEN은 LR 영상을 입력으로 캡처하고 동일한 크기의 향상된 LR(SR) 영상을 생성한다. IEN의 출력인 ELR(SR) 영상은 네 가지 유형의 손실 함수로 평가 된다. IEN의 목표 출력이 HR 영상이기 때문에 재구성 및 에지 loss는 ELR(SR)과 HR 영상간의 불일치를 사용하여 계산된다. 또한, 분류 및 지각 손실은 ELR(SR) 영상을 입력으로 취하는 객체 인식 네트워크를 사용하여 계산된다. IEN은 객체 인식에 유용한 정보에 초점을 맞춰 영상을 재구성하는 방법을 학습한다. -
Training stage 3
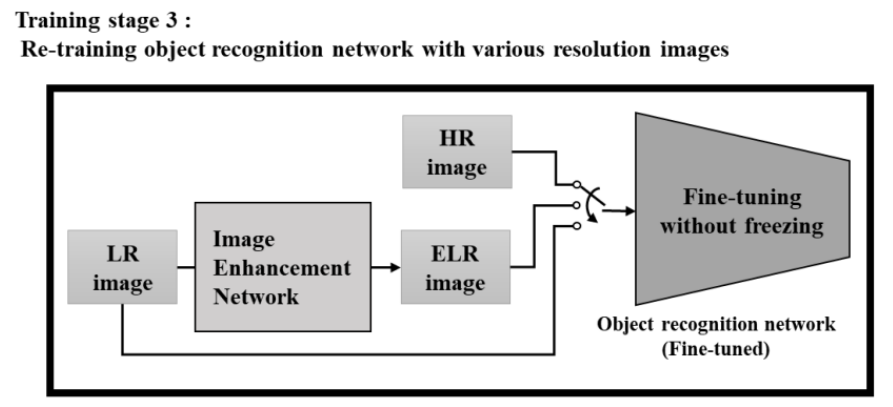
객체 인식 네트워크는 훈련을 받은 IEN에서 획득한 ELR(SR) 이미지로 재교육 된다. HR 및 LR 이미지 모두에서 인식 성능을 확보하기 위해 모든 HR, LR, ELR(SR) 이미지를 데이터 셔플링을 통해 입력한다. IEN은 이 단계에서 고정되며, 객체 인식 네트워크의 모든 layer들은 다양한 해상도의 지정된 이미지에서 객체 인식 능력을 높이기 위해 freeze 없이 재훈련된다.
세 단계가 모두 완료된 후, 추론 프로세스를 새 LR이미지에 적용할 수 있다. 그림 1(b)와 같이 IEN은 LR 이미지에 대해 SR 이미지를 생성하며, 객체 인식 네트워크에 입력으로 제공된다. 그런 다음 객체 인식 네트워크를 통해 분류 결과를 예측한다.
3. LOSS
-
RECONSTRUCTION LOSS
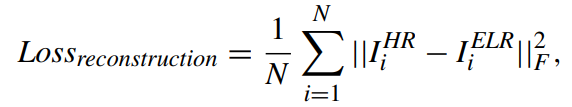 HR 이미지와 SR이미지의 차이
HR 이미지와 SR이미지의 차이 -
PERCEPTUAL LOSS
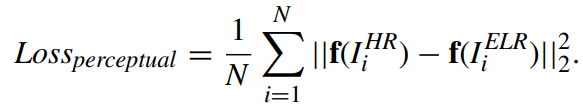 객체 인식 네트워크로 부터 나온 HR, SR이미지의 피처맵 차이
객체 인식 네트워크로 부터 나온 HR, SR이미지의 피처맵 차이 -
CLASSIFICATION LOSS
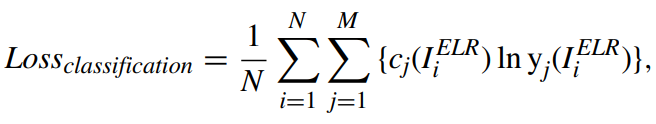 ELR(SR)에 대한 분류 loss
ELR(SR)에 대한 분류 loss -
EDGE LOSS
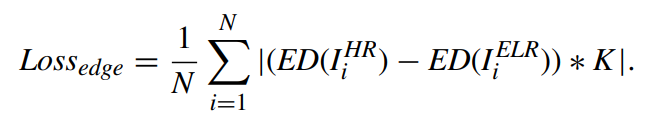 ELR(SR)과 HR의 edge의 차
ELR(SR)과 HR의 edge의 차 -
TOTAL LOSS FOR IEN
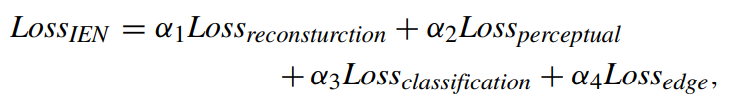
4. 객체 인식 네트워크의 train 전략
객체 인식 네트워크는 1단계에서는 HR 영상을 이용한 예비 학습, 3단계에서는 HR및 ELR(SR) 영상을 이용한 보조 학습인 2가지 학습을 진행한다. 그림 1(a)와 같이 교육 1단계에서는 원하는 데이터셋에서 HR 이미지를 사용하여 pre-trained된 객체 인식 네트워크를 가져오고 fine-tuning한다. 이 프로세스에서 초기 네트워크 계층은 동결되고 이후 네트워크 계층만 미세 조정된다. 중간 동결 블록의 출력은 지각 손실을 계산하는 데 사용되며, 네트워크의 출력은 분류 손실을 계산하는 데 사용된다. IEN 훈련 후, 우리는 그림 1(a)의 훈련 단계 3에서와 같이, 어떠한 계층도 동결하지 않고 ELR 영상으로 객체 인식 네트워크를 재훈련한다. 2차 학습 후 객체 인식 네트워크는 저분해능 및 고분해능 객체를 인식할 수 있다. 객체 인식 네트워크를 2단계로 교육한 이유는 사전 교육된 네트워크의 기능 추출 능력을 최대한 활용하고, 분류 손실 신호를 효과적으로 생성하기 위함이다. 네트워크가 첫 번째 단계에서 동결 없이 미세 조정된다면, 중간 계층에서 추출된 특징들은 인식 손실 추정을 위해 바람직하지 않은 교육 데이터에 대한 편향을 포함할 것이다. 또한 첫 번째 단계에서 HR 및 LR 이미지를 모두 사용하여 객체 인식 네트워크를 교육할 경우, IEN은 LR 이미지와 다소 유사한 초기 ELR 이미지를 학습 시작부터 잘 분류할 수 있기 때문에 학습 초기 단계에서 분류 손실을 줄이는 것을 중단한다. 따라서 1단계에서는 HR 영상으로만 객체 인식 네트워크를 교육하여 HR 영상과 유사한 해석이 가능한 영상을 더 많이 생성한다.
5. 성능