OT와 CRDT
CRDT란?
Conflict-free Replicated Data Type의 약자로, 동시 편집에 사용되는 기술 중 하나입니다. 실시간 협업 툴 또는 프로그램에 주로 사용 되며, 예시로, 피그마가 CRDT를 통해 실시간 동시 편집 기술을 구현했어요.
CRDT를 직역 해보면, ‘충돌에 자유로운 복제된 데이터 타입’ 인데, 왜 이러한 이름이 붙었으며, 실시간 동시 편집에 빠지지 않는 키워드가 되었을까요?
CRDT 이전의 OT
CRDT 이전에는 OT(Operational Transformation)를 활용하여 동시 문서 편집을 구현했다고 해요. 대표적으로 Google Docs, MS Office가 OT라는 기술을 통해 구현되었습니다.
대략 2006년 정도를 기준으로, 2006년 까지는 OT라는 기술을 통해 동시 문서 편집 기술을 구현했고, 그 이후에는 CRDT라는 기술을 통해 구현했다고 하는데, 각각 특징을 통해 어떠한 장 단점이 있는지 알아보겠습니다!
OT의 동작 원리 및 특징
시간의 순서대로, OT에 대해 먼저 알아보도록 하겠습니다.
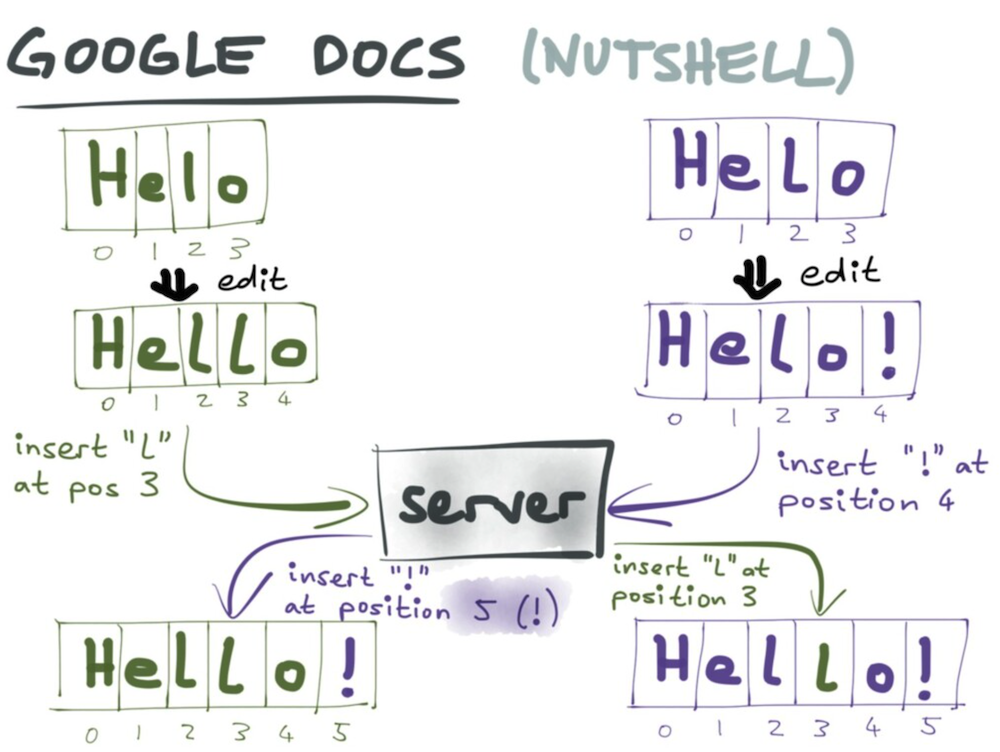
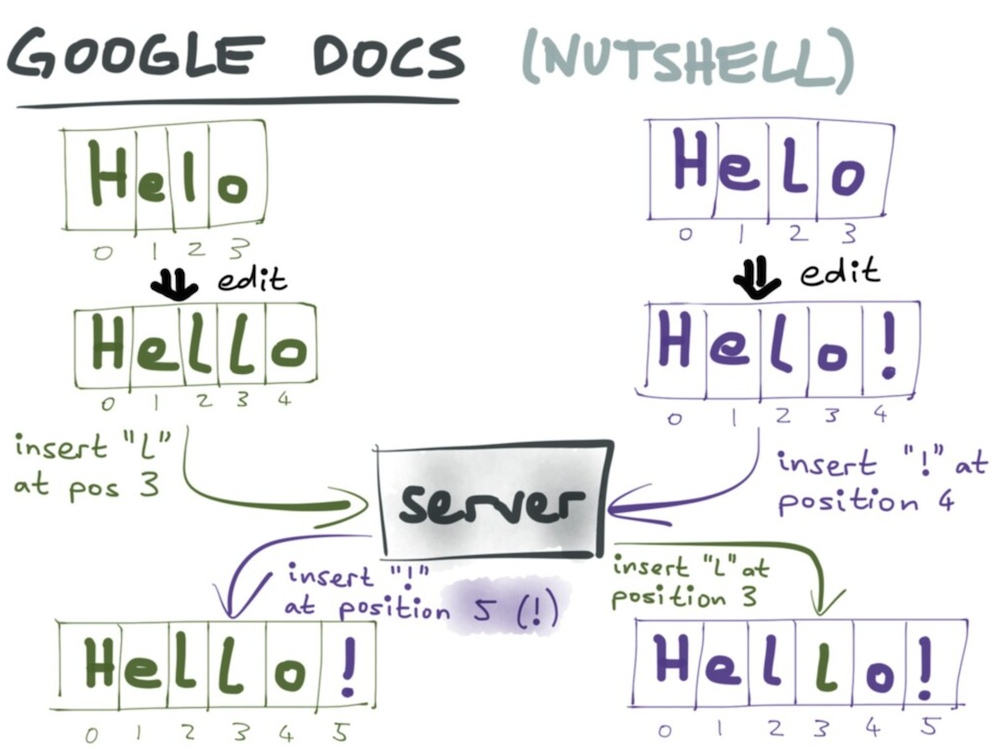
위의 사진 자료에서, 만약 ‘helo’ 라는 텍스트에 두 명이 동시에 작업을 한다고 가정 했을 때, 왼쪽에 한 명은 2와 3사이에 ‘l’이라는 문자를 넣고, 오른 쪽 한 명은 3뒤에 ‘!’라는 문자를 넣는다고 가정해 봅시다.
그렇다면 어떻게 동작하고, 어떤 결과를 가져올까요?
OT의 동작은, 입력한 순서에 따라 서버가 결정하여 문자를 완성시킵니다. 왼쪽과 오른쪽 둘중 누가 먼저 입력하게 되느냐에 따라 달라지게 됩니다.
왼쪽이 먼저 입력 하는 경우, ‘helo’에서 ‘l’(2번 인덱스)과 ‘o’(3번 인덱스) 사이에 ‘l’을 입력하면, ‘hello’가 되며, 인덱스 가장 끝의 숫자는 4가 됩니다. 하지만 ‘hello’가 먼저 입력되기 전 오른 쪽 입장의 경우, ‘helo’ 의 가장 끝에 ‘!’(3번 인덱스 뒤)라는 문자를 입력하게 됩니다. 서버는 ‘hello’를 먼저 만들고 그 뒤에 오른 쪽의 입력을 반영하여 3번 인덱스 뒤가 아닌, 4번 인덱스 뒤에 ‘!’를 반영하여, ‘hello!’라는 문자를 완성하게 됩니다.
오른쪽이 입력하는 경우 또한 마찬가지 입니다.
이처럼, 동작의(Operational) 순서에 따라 다음 순서의 동작을 변환(Transform)시켜 줘야 하는 기술을 OT라고 합니다. 이러한 동작은 서버에서 실행합니다. 마치 실시간 git의 rebase와 동작이 비슷합니다.
이러한 OT의 문제점은 중앙 집중식 서버가 필요하다는 것입니다. 동시 문서 편집의 경우, 결국 동시에 문자를 입력하는 경우, 문자의 순서를 결정짓는 건 서버이기 때문에, 만약 서버에 많은 트래픽이 몰리는 경우, 과부하가 올 수 있다는 단점이 있습니다.
CRDT의 동작 원리 및 특징
인덱스와 입력 순서에 따라 결정되는 OT에 비해 CRDT는 어떤 동작 원리를 가지고 있을까요?
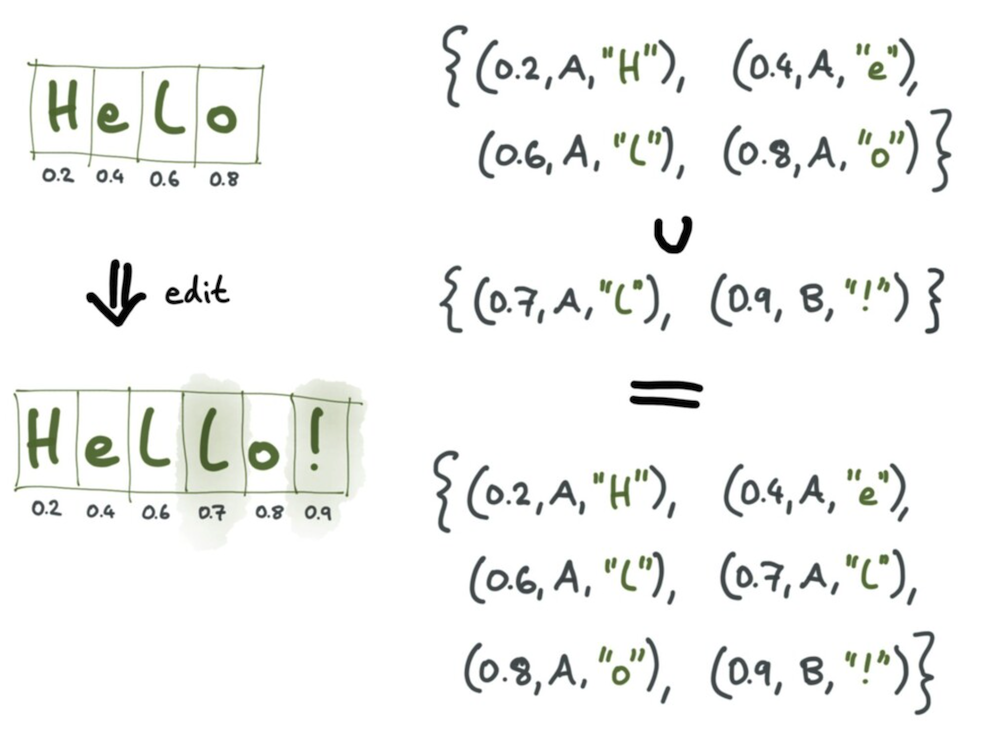
만약 ‘helo’에 두 명이 각각 한 명은, ‘hello’를, 나머지 한 명은 ‘helo!’를 작성하게 되면, 위의 사진처럼 자료구조가 형성되어 ‘hello!’라는 문자가 완성됩니다. 이전의 OT에서는, 인덱스에 의해 문장이 결정되는 반면, CRDT는 각각 문자에 고유한 인덱스가 있어, 문자가 추가되는 경우, 각각 유니크한 인덱스를 만들어, 완성하려는 문장 사이에 값이 추가됩니다. 이러한 경우, 서버에 문자 추가를 기다릴 필요 없다는 게 CRDT의 장점입니다.
반대로, crdt의 단점도 존재합니다. 아래의 자료를 보면,
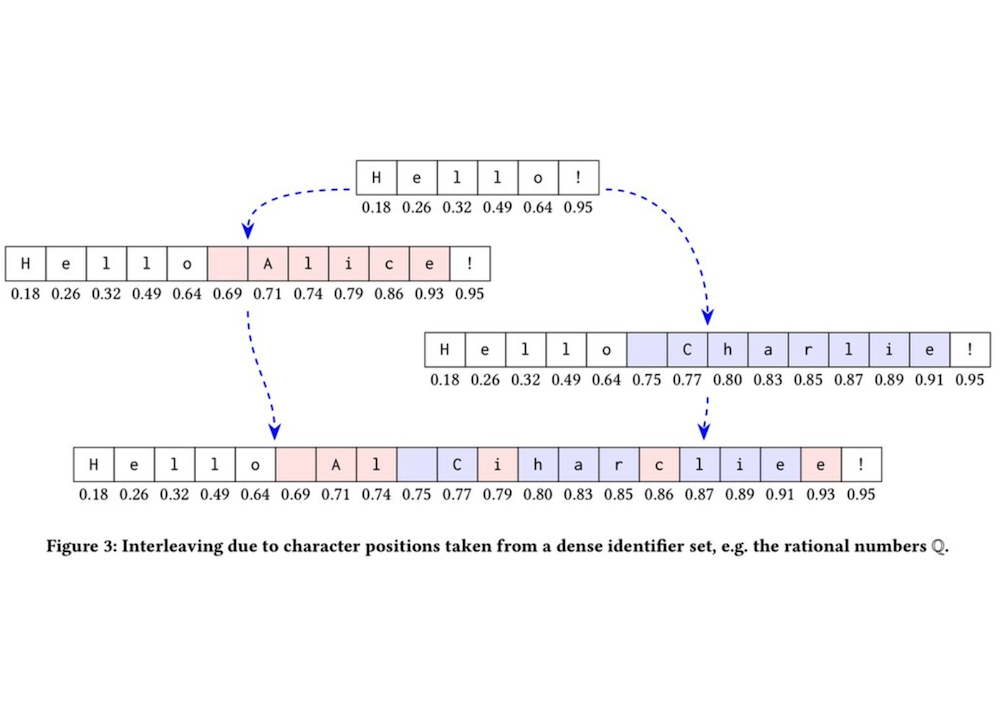
동시에 두 단어를 입력하게 되면, 각 단어의 알파벳이 섞이게 되어, 의도하지 않은 결과가 나올 수 있습니다. 단어 안의 각각의 알파벳은 모두 랜덤하게 부여된 고유한 인덱스를 갖게 되는데, 이러한 인덱스가 합쳐지게 되면, 예상치 못한 결과를 가져올 때도 발생하게 됩니다.
이전에는 OT보다 문서를 작성했을 때 편집 속도도 느렸고, 복잡하고 어렵다는 단점이 있었는데, 현재는 많이 보완되었습니다.
References
https://channel.io/ko/blog/crdt_vs_ot
https://www.figma.com/blog/how-figmas-multiplayer-technology-works/
