8.1 메모리 계층 구조와 메모리 관리 핵심
메모리 계층 구조란?
메모리 계층 구조는 컴퓨터 시스템 내의 다양한 메모리 장치들이 계층적으로 조직된 구조를 말한다. 각 계층은 용량, 가격, 속도의 차이에 따라 구성되며, CPU가 데이터를 처리할 때 성능과 효율성을 극대화하기 위해 설계되었다.
메모리 계층 구조의 주요 특징
-
구성 계층
-
CPU 레지스터: 가장 빠르지만 용량이 매우 적다. CPU가 명령을 즉시 실행하기 위해 데이터를 저장하는 메모리.
-
CPU 캐시 메모리 (L1/L2/L3): CPU와 메인 메모리 간의 속도 차이를 줄이기 위해 사용되며, 속도가 빠르고 용량이 적음.
-
메인 메모리 (RAM): 주 메모리로 데이터를 저장하고 처리 속도가 빠르지만 캐시보다 느림.
-
보조 기억 장치: 하드 디스크(HDD), SSD 등으로 대용량 데이터를 저장하는 데 사용되며, 속도는 상대적으로 느리다.
-
-
속도와 용량의 반비례 관계
- 메모리 계층 구조에서 CPU에 가까울수록 속도는 빠르고, 용량은 적어짐.
- 반대로 CPU에서 멀어질수록 용량은 증가하지만, 속도는 감소함.
-
계층의 역할
- 레지스터와 캐시: CPU 작업을 빠르게 처리.
- 메인 메모리: 현재 실행 중인 프로그램과 데이터를 저장.
- 보조 기억 장치: 장기적으로 데이터를 저장하고 백업.
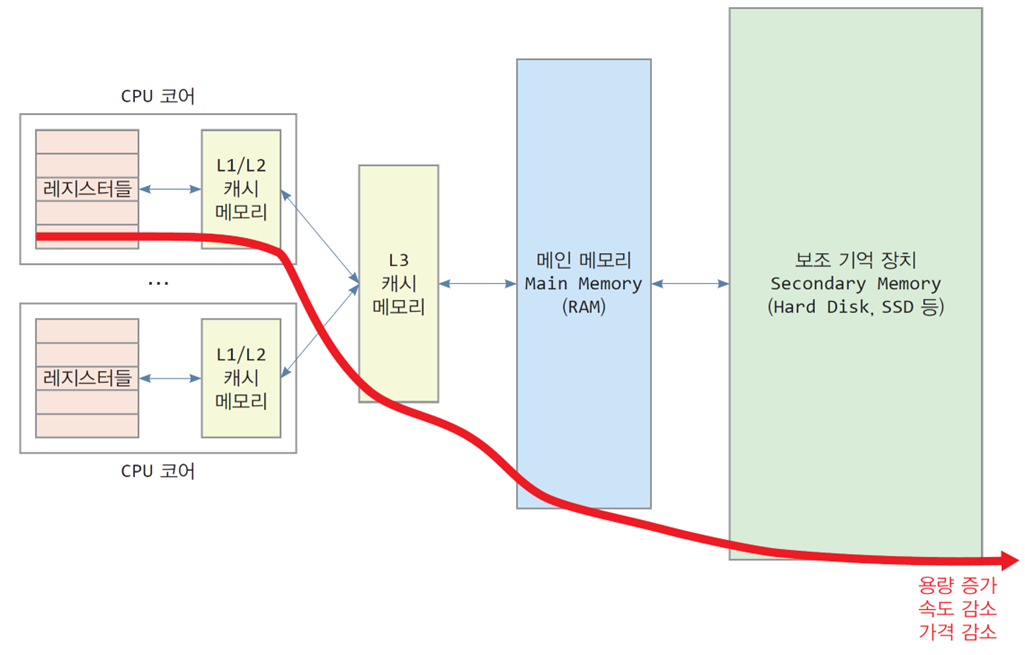
- CPU 코어에는 레지스터와 L1/L2 캐시 메모리가 위치하며, 가장 높은 속도를 제공한다.
- L3 캐시 메모리는 여러 CPU 코어가 공유하며, 메인 메모리와 CPU 캐시 간의 다리 역할을 한다.
- 메인 메모리 (RAM)는 시스템에서 가장 중심이 되는 메모리로, 대부분의 데이터가 여기에 저장된다.
- 보조 기억 장치는 하드 디스크나 SSD와 같은 저장 장치로, 가장 큰 용량을 가지지만 속도가 가장 느리다.
- 빨간 곡선은 용량 증가와 속도 감소의 관계를 나타낸다.
메모리 계층 구조의 주요 특징
메모리 계층 구조는 CPU 레지스터부터 보조 기억 장치까지 다양한 메모리 유형을 포함하며, 각각의 계층은 성능, 용량, 속도, 가격에 따라 구분된다. 아래는 주요 메모리 계층의 특징을 표로 정리한 것이다.
| 메모리 계층 | 용도 | 용량 | 속도 | 가격 | 휘발성 |
|---|---|---|---|---|---|
| CPU 레지스터 | 명령어와 데이터 저장 | 8~30개, 1KB 미만 | <1ns | 높음 | 휘발성 |
| L1/L2 캐시 | 한 코어의 데이터 저장 | 32KB/256KB | <5ns | 높음 | 휘발성 |
| L3 캐시 | 멀티 코어 데이터 공유 저장 | 8MB | <5ns | 높음 | 휘발성 |
| 메인 메모리 | 전체 프로그램과 데이터 저장 | 최소 8GB 이상 | <50ns | 보통 | 휘발성 |
| 보조 기억 장치 | 파일, 데이터베이스 등 장기 저장 | TB 단위 | <20ms | 저렴 | 비휘발성 |
메모리 계층화의 목적과 역사
메모리 계층화는 CPU와 메모리 간의 데이터 전송 속도를 높이고, 시스템 비용을 절감하기 위한 중요한 설계 전략이다.
1. 메모리 계층화의 역사적 과정
-
CPU 성능 향상
CPU가 점점 더 높은 성능을 요구함에 따라, 더 빠른 메모리가 필요해졌다.
- 초기에는 작은 크기의 off-chip 캐시가 등장.
- 이후, CPU 내부에 on-chip 캐시가 추가되며, L1, L2, L3 캐시 구조로 발전.
-
컴퓨터 성능 및 데이터 대형화
컴퓨터가 더 많은 데이터를 처리하기 시작하면서 저장 장치의 요구사항도 커졌다.
- 기존 하드 디스크의 대형화와 더불어, 빠른 접근이 가능한 SSD가 등장하며 성능과 효율성이 증대되었다.
-
결론
메모리 계층화는 성능과 비용의 균형을 맞추기 위한 과정의 산물이다.
2. 메모리 계층화의 목적
-
액세스 시간 단축
CPU와 메모리 간 데이터 접근 시간을 최소화하여, CPU가 대기하지 않고 작업을 수행할 수 있도록 한다.
- 특히 프로그램 실행 속도를 높이기 위한 필수적인 설계.
-
시스템 성능 극대화
각 메모리 계층은 속도와 용량의 차이를 활용하여 성능을 최적화하며, 필요한 데이터를 적시에 제공한다.
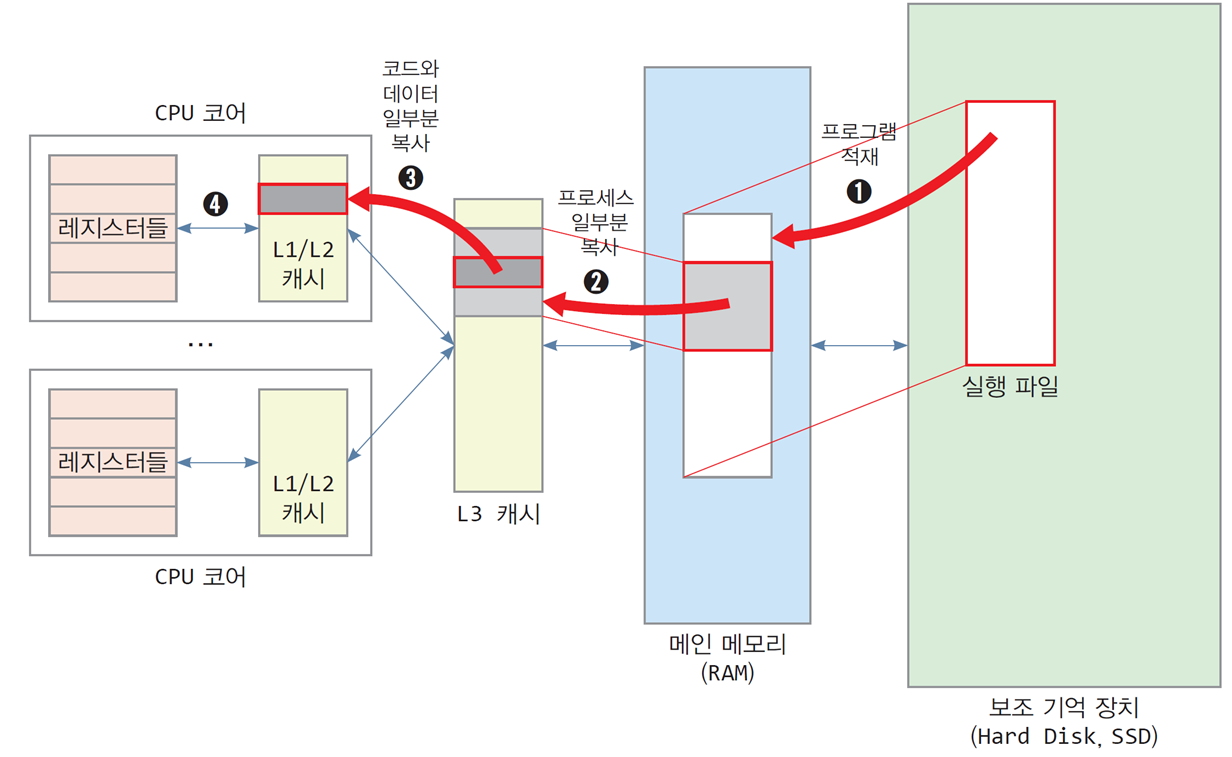
메모리 계층에서 코드와 데이터 이동 과정
컴퓨터 시스템의 메모리 계층에서는 CPU가 효율적으로 작업을 수행할 수 있도록 데이터를 단계적으로 이동시키는 과정이 이루어진다. 이를 통해 보조 기억 장치에 저장된 데이터가 CPU 레지스터까지 전달된다.
1. 메모리 계층의 데이터 이동 단계
-
보조 기억 장치 → 메인 메모리 (RAM)
-
프로그램이 실행될 때, 보조 기억 장치(Hard Disk 또는 SSD)에 저장된 실행 파일이 메인 메모리로 복사된다.
-
이 과정은 파일 시스템에서 실행 코드와 데이터를 로드하여 메인 메모리에 적재하는 단계이다.
-
-
메인 메모리 → L3 캐시
-
실행 중인 프로그램의 일부 코드와 데이터가 L3 캐시로 복사된다.
-
L3 캐시는 다중 CPU 코어가 공유하는 캐시로, 메인 메모리와 CPU 간의 병목 현상을 줄이는 역할을 한다.
-
-
L3 캐시 → L1/L2 캐시
-
프로그램 실행에 필요한 데이터 일부가 CPU 코어 내의 L1/L2 캐시로 전달된다.
-
L1 캐시는 속도가 가장 빠르며, CPU가 자주 사용하는 데이터를 저장한다. L2 캐시는 L1 캐시의 용량 부족을 보완한다.
-
-
L1/L2 캐시 → CPU 레지스터
-
CPU가 명령어를 실행할 때 필요한 데이터를 L1/L2 캐시에서 레지스터로 전달한다.
-
레지스터는 CPU 내에서 가장 빠른 메모리로, 즉각적인 명령 처리에 사용된다.
-
2. 데이터 이동의 핵심
-
점진적 최적화: 데이터는 느리고 용량이 큰 저장 장치에서 빠르고 용량이 작은 메모리로 단계적으로 이동하며, 이를 통해 데이터 액세스 시간을 줄인다.
-
계층 간 협력: 각 계층은 CPU의 데이터 요구를 예측하고 필요한 데이터를 미리 로드하여 CPU의 작업을 지원한다.
메모리 계층화는 성공 이유
Q. 작은 캐시에 실행할 프로그램 코드와 데이터를 일부만 저장하는데, 이것이 효율적일까?
A. 효율적이다. "참조의 지역성" 원리 때문이다.
📌 참조의 지역성이란?
-
시간적 지역성 (Temporal Locality)
-
최근 사용된 데이터는 다시 참조될 가능성이 높다.
-
예를 들어, 반복문에서 같은 변수나 배열 요소를 반복적으로 사용하는 경우이다.
-
-
공간적 지역성 (Spatial Locality)
-
현재 참조된 데이터의 근처에 있는 메모리 영역이 곧 사용될 가능성이 높다.
-
예를 들어, 배열의 요소를 순차적으로 접근할 때 발생한다.
-
참조의 지역성과 메모리 계층화의 관계는?
-
메모리 계층은 속도와 용량의 균형을 맞추기 위해 설계되었다.
-
캐시는 용량은 작지만, 참조의 지역성 덕분에 자주 사용되는 데이터만 효율적으로 저장해 CPU가 빠르게 접근할 수 있다.
-
이로 인해 캐시 히트율이 높아지고, 전체 시스템 성능이 크게 향상된다.
운영체제에 의한 메모리 관리의 필요성
운영체제는 컴퓨터 시스템에서 메모리를 효율적으로 관리하는 핵심적인 역할을 한다. 메모리 관리가 필요한 이유는 다음과 같다.
1. 메모리는 공유 자원이기 때문
메모리는 여러 프로세스가 동시에 접근하고 사용하는 공유 자원이다.
-
하나의 시스템에서 여러 프로그램이 실행되면서 자원 충돌이 발생할 가능성이 있다.
-
운영체제는 각 프로세스에 적절한 메모리를 분배하여 효율적인 동시 실행 환경을 제공한다.
2. 메모리는 보호되어야 하기 때문
- 프로세스 간 독립성: 각 프로세스는 고유한 메모리 공간을 가져야 하며, 다른 프로세스의 메모리에 침범할 수 없다.
- 커널 보호: 사용자 프로그램이 운영체제의 핵심 영역(커널)에 접근하지 못하도록 보호함으로써 시스템 안정성과 보안을 유지한다.
3. 메모리 용량 한계를 극복하기 위해
현대의 많은 프로그램은 물리적 메모리보다 더 많은 메모리를 요구하는 경우가 많다.
-
가상 메모리 기술: 운영체제는 가상 메모리를 사용하여 물리적 메모리 용량을 초과하는 프로그램도 실행 가능하게 한다.
-
효율적인 자원 활용: 여러 프로세스의 메모리 요구량이 물리적 메모리를 초과하더라도 효율적으로 조율하여 실행할 수 있다.
4. 메모리 효율성을 증대하기 위해
운영체제는 제한된 메모리 자원을 최대한 활용하여 가능한 많은 프로세스를 동시에 실행할 수 있도록 한다.
-
다중 작업 환경 지원: 효율적인 메모리 관리를 통해 시스템 성능을 극대화한다.
-
프로세스 스케줄링과의 연계: 메모리 관리와 프로세스 스케줄링은 밀접하게 연결되어 있다. 운영체제는 CPU와 메모리 자원을 적절히 분배하여 전체 성능을 최적화한다.
8.2 메모리 주소
물리 주소와 논리 주소
컴퓨터에서 메모리는 오직 주소를 통해 접근하며, 이 주소는 물리 주소(Physical Address) 와 논리 주소(Logical Address) 로 나뉜다. 두 주소 체계는 메모리 접근의 효율성과 보안을 위해 구분되어 사용된다.
1. 물리 주소(Physical Address)
- 정의: 물리 메모리(RAM)에 할당된 실제 주소로, 하드웨어적으로 고정된 주소이다.
- 특징:
- 0번 주소에서 시작하며 연속적인 형태를 가진다.
- 시스템 주소 버스를 통해 물리 메모리에서 데이터를 읽거나 쓸 때 사용된다.
- 사용자나 프로세스는 직접적으로 물리 주소에 접근할 수 없다.
- 주요 사용처: 하드웨어와의 직접적인 데이터 전송.
2. 논리/가상 주소(Logical Address / Virtual Address)
- 정의: 프로세스가 실행되는 동안 사용하는 주소로, 물리 주소와 독립적으로 운영체제에 의해 생성된다.
- 특징:
- 프로세스 내에서 상대적으로 정의되며, 0번 주소에서 시작한다.
- 실행 중인 프로세스마다 독립적으로 관리되어, 다른 프로세스의 논리 주소와 중복될 수 있다.
- 물리 주소로 변환되지 않으면 실제 메모리에 접근할 수 없다.
- 주요 사용처: 프로세스의 메모리 공간에서 데이터를 다룰 때.
3. MMU (Memory Management Unit)
- 역할:논리 주소를 물리 주소로 변환하는 하드웨어 장치이다.
- 특징:
- CPU가 생성한 논리 주소를 MMU를 통해 물리 주소로 매핑한다.
- 이 매핑 과정을 통해 사용자 프로그램은 실제 메모리의 물리적 위치를 알지 못하고도 작업을 수행할 수 있다.
- 현대 CPU 패키지에 내장되어 있으며, 인텔과 AMD의 x86 CPU는 80286부터 MMU를 포함한다.
4. 물리 주소와 논리 주소의 관계
- 논리 주소는 프로그램 실행의 편의성을 제공하고, 물리 주소는 메모리의 실제 하드웨어 위치를 나타낸다.
- 운영체제와 MMU가 협력하여 논리 주소를 물리 주소로 변환하여 안정적이고 효율적인 메모리 관리가 가능하다.
논리 주소와 물리 주소, MMU에 의한 주소 변환
컴퓨터 시스템에서 프로그램은 논리 주소를 사용하여 메모리에 접근하며, 실제 메모리 작업은 물리 주소를 통해 이루어진다. 이 두 주소 간의 변환은 MMU(Memory Management Unit)에 의해 처리된다.
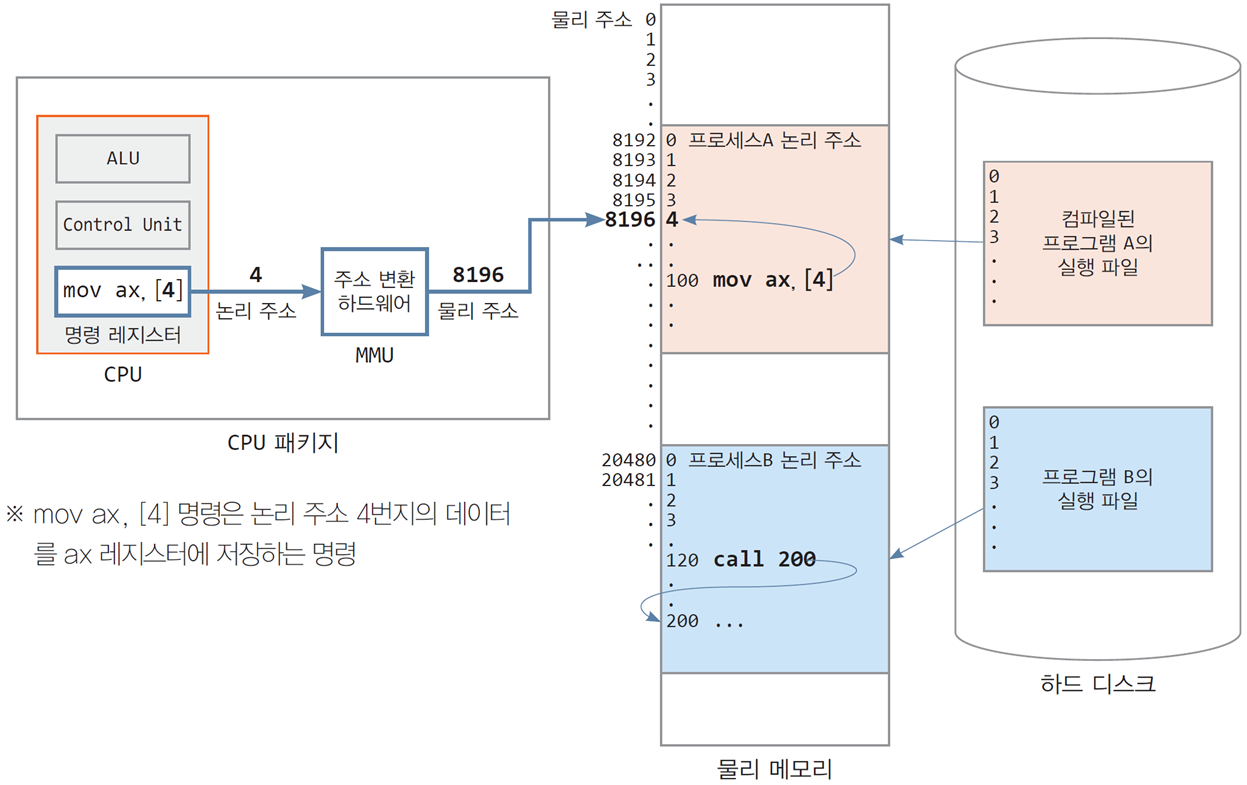
- 왼쪽: CPU가 생성한 논리 주소와 명령어 실행 과정.
- 중앙: MMU가 논리 주소를 물리 주소로 변환하는 과정.
- 오른쪽: 변환된 물리 주소를 통해 메모리(RAM)에서 데이터를 읽고 쓰는 모습.
1. CPU의 명령 실행 (논리 주소 생성)
사진의 왼쪽 부분은 CPU 내부 구조와 명령 실행 과정을 보여준다.
- CPU가 실행 중인 명령은
mov ax, [4]로, 이는 논리 주소 4번지의 데이터를 읽어와 레지스터에 저장하라는 의미이다. - 이때 CPU는 논리 주소만을 생성하며, 물리 메모리에 접근하기 위해서는 논리 주소를 물리 주소로 변환해야 한다.
2. MMU를 통한 논리 주소 → 물리 주소 변환
사진의 중앙 부분은 논리 주소를 물리 주소로 변환하는 과정을 나타낸다.
- CPU가 생성한 논리 주소(예: 4)는 MMU를 거치며, 물리 주소(예: 8196)로 변환된다.
- 변환 과정은 주소 매핑 테이블을 통해 이루어진다. 이는 논리 주소를 대응하는 물리 주소에 매핑하는 데이터 구조이다.
3. 변환된 물리 주소를 통한 메모리 접근
사진의 오른쪽 부분은 물리 메모리 구조를 보여준다.
- 변환된 물리 주소 8196번지는 실제 메모리(RAM)에서 데이터를 읽거나 쓰기 위한 위치를 나타낸다.
- 프로그램 A와 프로그램 B는 독립적인 논리 주소 공간을 사용하며, 동일한 논리 주소(예: 4)를 사용하더라도 MMU는 이를 각기 다른 물리 주소에 매핑한다.
4. 요약
- CPU는 논리 주소만 생성하고, 실제 데이터는 물리 주소를 통해 접근한다.
- MMU는 논리 주소를 물리 주소로 변환하는 핵심 하드웨어 장치로, 메모리 접근의 효율성과 보안을 동시에 제공한다.
- 프로그램 간의 메모리 독립성은 MMU와 주소 매핑 테이블을 통해 보장된다.
80386 CPU 구조를 통해 논리 주소, 물리 주소, MMU 작동 원리 설명
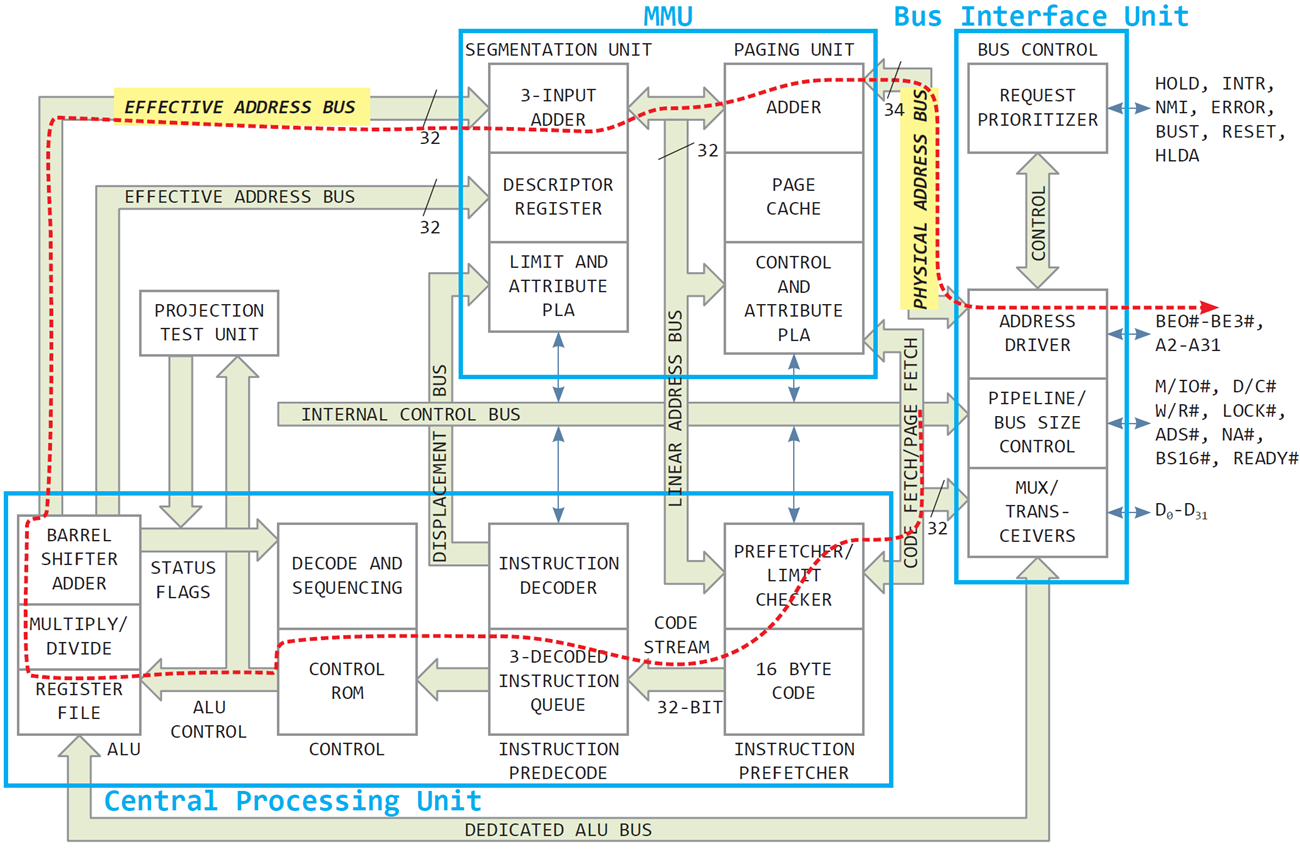
이 그림은 80386 CPU에서 논리 주소가 물리 주소로 변환되는 과정이다. 특히, MMU(Memory Management Unit)와 각 구성 요소의 역할을 설명하고 있다.
1. 논리 주소 생성 (CPU 내부)
-
CPU의 중앙 처리 장치(Central Processing Unit) 내부에서 논리 주소(Logical Address)가 생성된다.
-
주요 과정:
- Instruction Decoder: 명령어를 해석하여 실행 준비를 한다.
- Effective Address Bus: 명령어 실행 중 필요한 주소를 생성하며, 이는 아직 논리 주소 단계에 있다.
2. MMU를 통한 주소 변환
-
Segmentation Unit:
- Descriptor Register와 Limit and Attribute PLA를 활용하여 세그먼트 기반 주소 변환을 수행한다.
- 논리 주소를 선형 주소(Linear Address)로 변환한다.
-
Paging Unit:
- Page Cache와 Adder를 사용하여 선형 주소를 물리 주소로 변환한다.
- 이 과정에서 페이지 테이블(Page Table)을 참조하여 변환을 완료한다.
3. 물리 주소 전달 (Bus Interface Unit)
- 물리 주소는 Physical Address Bus를 통해 메모리나 외부 장치로 전달된다.
- Address Driver는 변환된 물리 주소를 시스템 버스에 적합한 형태로 출력한다.
4. 주요 구성 요소 설명
-
Central Processing Unit (CPU):
- 명령어 디코딩, 주소 계산, 논리 주소 생성의 중심.
- ALU(산술 논리 연산장치)와 Register File이 포함되어 계산 및 데이터 저장을 담당한다.
-
MMU (Memory Management Unit):
- 논리 주소 → 선형 주소 → 물리 주소로 변환하는 핵심 역할.
- 세그먼트와 페이지 기반의 주소 변환 과정을 모두 포함.
-
Bus Interface Unit (BIU):
- 변환된 물리 주소를 시스템 메모리나 I/O 장치로 전달.
5. 데이터 흐름
-
CPU 내부에서 명령어를 해석하고, 실행을 위해 논리 주소를 생성한다.
-
MMU가 논리 주소를 선형 주소로 변환한 뒤, 페이지 기반 매핑을 통해 물리 주소로 변환한다.
-
변환된 물리 주소는 Physical Address Bus를 통해 메모리나 외부 장치로 전달된다.
컴파일과 논리 주소
1. 컴파일 과정에서 논리 주소 생성
-
컴파일러의 역할: 소스 코드를 분석하여 명령어와 변수들을 논리 주소로 변환한다.
- 프로그램의 코드와 전역 변수는 컴파일 단계에서 논리 주소로 매핑된다.
- 이 논리 주소는 물리 메모리의 위치와 무관하게 생성된다.
2. 응용프로그램 적재 시
운영체제는 응용프로그램(프로세스)을 메모리에 적재하면서 논리 주소를 물리 주소로 연결하는 과정을 수행한다.
-
운영체제의 역할:
- 프로그램을 물리 메모리의 적절한 위치(비어 있는 영역)에 배치.
- 매핑 테이블 생성: 논리 주소와 물리 주소 간의 변환 정보를 저장.
-
매핑 테이블의 활용:
- 프로세스 간의 독립적인 메모리 공간을 보장.
- 충돌 방지 및 효율적인 메모리 사용 가능.
3. 응용프로그램 실행 시 (프로세스 동작)
프로그램이 실행되면, CPU가 생성하는 논리 주소는 MMU에 의해 물리 주소로 변환된다.
-
MMU의 역할:
- CPU로부터 발생된 논리 주소를 매핑 테이블을 참조하여 물리 주소로 변환.
- 변환된 물리 주소를 통해 실제 메모리에 접근.
-
중요성:
- 사용자 프로그램은 물리 메모리의 실제 위치를 알 필요가 없다.
- 메모리 접근이 효율적이고 안전하게 이루어진다.
[탐구✨] C 프로그램에서 변수의 주소는 논리 주소인가, 물리 주소인가?
1. 프로그램 예제 분석
#include <stdio.h>int n = 0; // 전역 변수
int main() {
printf("변수 n의 주소는 %p\n", &n); // 변수 n의 주소 출력
return 0;
}위 코드는 전역 변수 n의 주소를 출력하는 C 프로그램이다. 여기서 출력된 주소는 변수 n의 논리 주소이다.
2. 실행 결과
- 컴파일 및 실행:
$ gcc -o logical logicaladdress.c
$ ./logical
변수 n의 주소는 0x60103c
동일한 프로그램을 여러 번 실행하면 출력되는 주소 값은 동일하다.
- 이유:
전역 변수n의 주소는 논리 주소로, 프로그램이 실행될 때마다 논리 주소 공간에서 동일한 위치를 가지기 때문이다.
3. 정리
-
전역 변수
n의 주소는 논리 주소이다. -
PIE 및 ASLR과 같은 보안 기능이 활성화된 환경에서는 실행마다 논리 주소가 달라질 수 있지만, 기본적으로 이는 프로그램의 논리 주소 공간에서 결정된 값이다.
-
PIE를 비활성화하면, 실행 결과의 주소는 항상 동일하다.
[TIP✨] ASLR(Address Space Layout Randomization)
ASLR은 메모리 공격을 방어하기 위해 도입된 기술로, 프로그램이 실행될 때마다 메모리의 주소 공간을 랜덤하게 배치하여 공격자가 메모리 구조를 예측하기 어렵게 만든다.
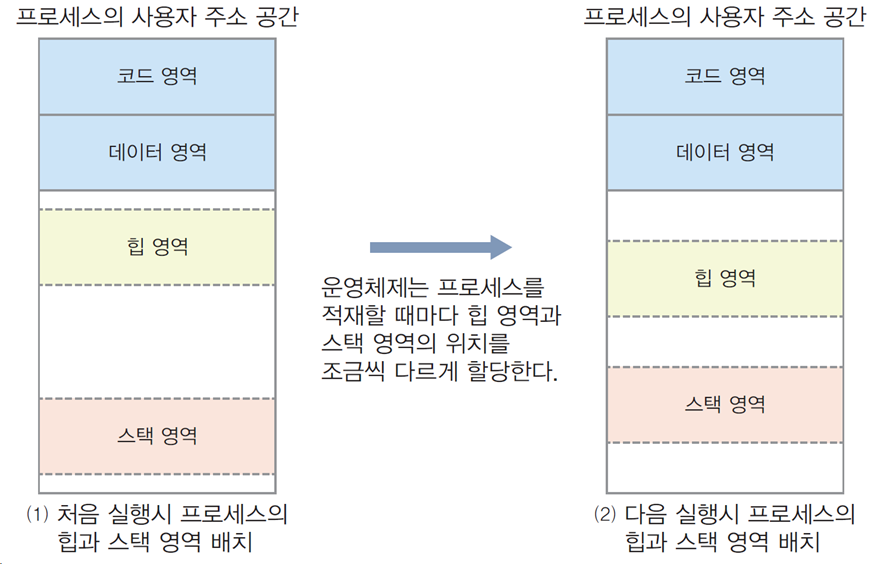
- 왼쪽: ASLR 적용 전, 힙과 스택 영역이 고정된 위치에 배치.
- 오른쪽: ASLR 적용 후, 힙과 스택 영역이 매 실행마다 다른 위치에 배치.
1. ASLR의 주요 특징
-
도입 배경:
- 2001년경 해커들의 메모리 기반 공격(예: 버퍼 오버플로우)을 방어하기 위해 설계되었다.
- 오늘날 대부분의 운영체제가 ASLR을 활용하여 보안을 강화한다.
-
작동 방식:
- 프로세스의 주소 공간에서 코드, 데이터, 힙, 스택과 같은 주요 메모리 영역을 랜덤하게 배치한다.
- 동일한 프로그램이라도 실행할 때마다 힙과 스택의 메모리 시작 위치가 달라진다.
2. ASLR의 효과
-
보안 강화:
-
메모리 레이아웃이 매 실행마다 변하므로, 공격자가 특정 메모리 주소를 겨냥하기 어렵다.
-
메모리 기반의 익스플로잇 공격(예: 리턴 투 리브(Return-to-libc))을 방어하는 데 효과적이다.
-
-
랜덤화 예시:
- 첫 실행 시: 힙 영역과 스택 영역의 주소가 특정 위치에서 시작.
- 다음 실행 시: 힙과 스택의 시작 위치가 다른 곳으로 이동.
3. 한계점
-
PIE(Position Independent Executable) 필요:
- 프로그램이 PIE 실행 파일로 컴파일되지 않은 경우, ASLR 적용이 제한될 수 있다.
-
전역 변수 및 코드 영역:
- ASLR은 주로 힙과 스택 영역에 적용되며, 코드 영역의 주소는 고정되는 경우가 있다.
8.3 물리 메모리 관리
메모리 할당 (Memory Allocation)
1. 메모리 할당의 개념
- 정의: 운영체제가 프로세스에 필요한 메모리 공간을 물리 메모리(RAM)에 할당하는 과정.
2. 메모리 할당 과정
-
프로세스 생성 시:
- 운영체제는 각 프로세스를 위한 논리 주소 공간을 생성한다.
- 물리 메모리의 비어 있는 공간에 프로세스의 코드, 데이터, 스택 등을 배치한다.
-
실행 중 메모리 요청 시:
- 프로세스가 실행 중 추가 메모리를 요청하면 운영체제는 메모리 공간을 동적으로 할당한다.
- 필요에 따라 물리 메모리 부족 시 하드 디스크(가상 메모리)를 활용하기도 한다.
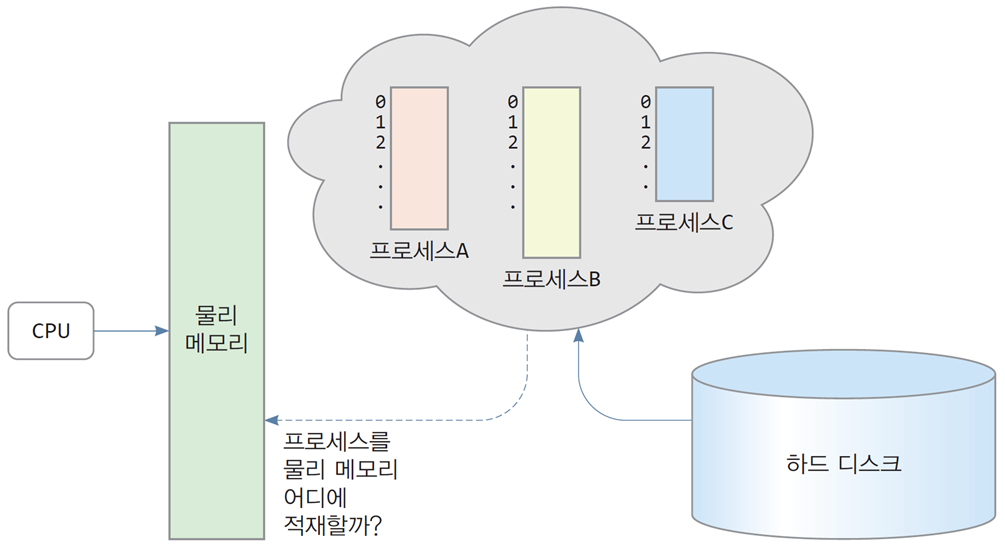
-
CPU와 물리 메모리:
- CPU는 물리 메모리에 접근하여 프로세스를 실행한다.
- 각 프로세스는 운영체제에 의해 고유한 메모리 공간을 할당받는다.
-
프로세스 A, B, C:
- 프로세스들은 독립적인 논리 주소 공간을 갖는다.
- 운영체제는 물리 메모리의 적절한 위치에 이를 배치하여 프로세스 간 충돌을 방지한다.
-
하드 디스크의 역할:
- 물리 메모리가 부족할 경우, 운영체제는 하드 디스크를 사용하여 데이터를 임시로 저장(스와핑)한다.
4. 메모리 할당의 주요 문제
-
공간 분배:
- 어떤 물리 메모리 영역에 프로세스를 배치할지 결정하는 것이 중요하다.
- 효율적인 메모리 활용을 위해 연속 할당, 분산 할당 등의 기법이 사용된다.
-
메모리 부족 문제:
- 메모리가 부족할 경우, 가상 메모리와 스와핑을 통해 문제를 해결한다.
- 하지만 스와핑은 속도를 저하시킬 수 있다.
메모리 할당 기법
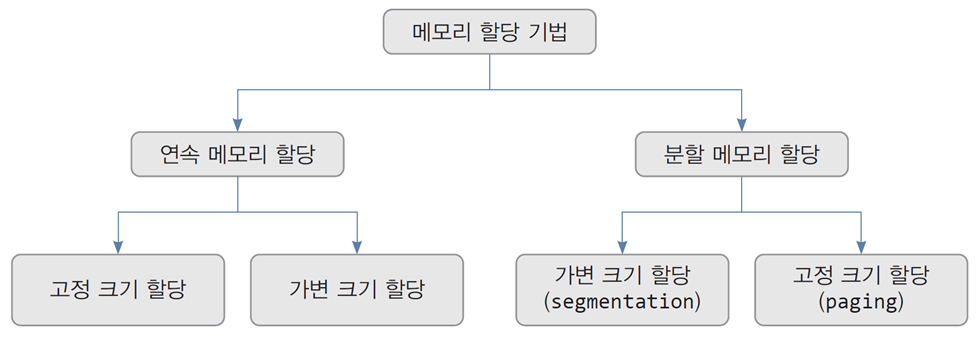
1. 연속 메모리 할당
-
정의: 프로세스별로 연속된 메모리 영역을 할당하는 방식.
-
특징:
- 하나의 프로세스는 하나의 연속된 메모리 블록을 사용.
- 관리가 간단하지만, 메모리 조각화(Fragmentation)가 발생할 수 있음.
-
세부 유형:
- 고정 크기 할당:
- 동일 크기의 메모리 블록(파티션)으로 나누어 프로세스에 할당.
- 효율성은 떨어지지만 구현이 간단.
- 가변 크기 할당:
- 프로세스가 요청한 크기만큼 메모리를 동적으로 할당.
- 외부 조각화(External Fragmentation)가 발생할 수 있음.
- 고정 크기 할당:
2. 분할 메모리 할당
-
정의: 프로세스별로 메모리를 여러 블록(분할된 영역)으로 나누어 할당.
-
특징:
- 메모리 공간을 더 효율적으로 사용할 수 있음.
- 메모리 관리가 복잡해질 수 있음.
-
세부 유형:
- 고정 크기 할당 (페이징, Paging):
- 메모리를 고정 크기의 페이지 단위로 나누어 프로세스에 할당.
- 내부 조각화(Internal Fragmentation)는 발생할 수 있으나, 외부 조각화는 없음.
- 논리 주소와 물리 주소 간의 매핑을 통해 구현.
- 가변 크기 할당 (세그먼테이션, Segmentation):
- 메모리를 다양한 크기의 세그먼트로 나누어 프로세스에 할당.
- 프로세스의 논리 구조(예: 코드, 데이터, 스택)를 반영하여 메모리를 나눔.
- 외부 조각화가 발생할 가능성이 있음.
- 고정 크기 할당 (페이징, Paging):
3. 주요 차이점
| 기법 | 장점 | 단점 |
|---|---|---|
| 연속 메모리 할당 | 관리가 간단, 구현이 쉬움 | 외부 조각화 발생 가능 |
| 분할 메모리 할당 | 메모리 사용 효율성 증가 | 관리 복잡, 테이블 관리 필요 |
| 페이징 | 외부 조각화 없음 | 페이지 테이블 관리로 오버헤드 발생 |
| 세그먼테이션 | 논리 구조에 맞는 메모리 할당 가능 | 외부 조각화 발생 가능 |
연속 메모리 할당
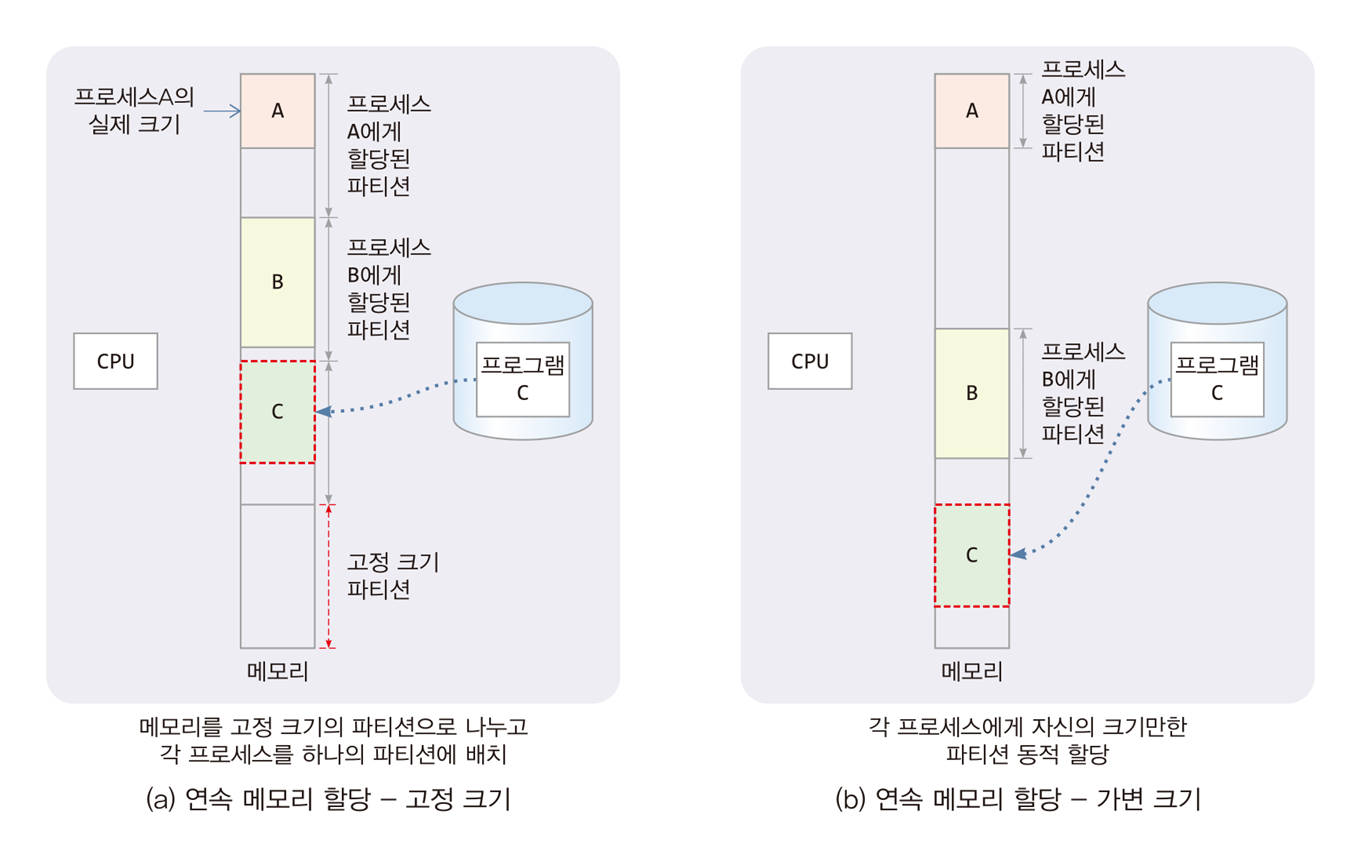
1. 고정 크기 할당 (Fixed Partition Allocation)
-
설명: 메모리를 미리 정해진 고정 크기의 파티션으로 나눈 뒤, 각 프로세스에 하나의 파티션을 할당한다.
-
특징:
-
파티션 크기는 동일하거나, 다양한 크기로 고정될 수 있다.
-
각 파티션은 프로세스 크기와 상관없이 정해진 크기를 차지한다.
-
메모리 조각화 발생:
- 프로세스 크기가 파티션 크기보다 작으면, 내부 조각화(Internal Fragmentation)가 발생한다.
-
-
그림 (a):
- 프로세스 A와 B는 각각 고정된 크기의 파티션에 할당되었다.
- 프로세스 C는 파티션 크기보다 작은 크기로 할당되었지만, 파티션의 남은 공간은 사용할 수 없다.
2. 가변 크기 할당 (Variable Partition Allocation)
-
설명: 프로세스가 요구하는 메모리 크기만큼 동적으로 할당한다.
-
특징:
- 메모리 낭비를 줄일 수 있으나, 외부 조각화(External Fragmentation)가 발생할 수 있다.
- 동적 메모리 관리 기법(최초 적합, 최적 적합, 최악 적합 등)이 사용된다.
-
그림 (b):
- 프로세스 A와 B는 필요한 메모리 크기만큼만 동적으로 할당되었다.
- 프로세스 C는 요구 크기만큼 동적으로 할당되었으며, 추가적인 메모리 공간이 효율적으로 사용되고 있다.
분할 메모리 할당
1. 세그먼테이션(Segmentation)
-
설명:
-
메모리를 가변 크기의 세그먼트로 나누고, 각 세그먼트는 프로세스의 논리적 단위(코드, 데이터, 스택 등)에 맞춰 할당된다.
-
각 세그먼트는 독립적으로 관리되며, 크기가 다를 수 있다.
-
-
특징:
-
논리적 분할: 프로세스의 구조를 반영하여 논리적인 메모리 관리가 가능.
-
외부 조각화 발생: 세그먼트 크기가 가변적이므로 외부 조각화(External Fragmentation)가 발생할 수 있다.
-
주소 구성: 세그먼트 번호(Segment Number)와 세그먼트 내 오프셋(Offset)으로 구성된 논리 주소를 사용한다.
-
-
그림 (c):
- A, B, C 프로세스의 코드, 데이터, 스택 세그먼트가 메모리의 서로 다른 위치에 배치되었다.
- 각 세그먼트의 크기와 위치는 프로세스의 필요에 따라 다르다.
2. 페이징(Paging)
-
설명:
-
메모리를 고정 크기의 페이지로 나누고, 프로세스도 동일한 크기의 페이지로 분할하여 메모리에 할당한다.
-
프로세스의 페이지는 물리 메모리의 다양한 위치에 저장될 수 있다.
-
-
특징:
-
고정 크기 분할: 모든 페이지가 동일한 크기를 가지므로 관리가 단순.
-
내부 조각화 발생 가능: 마지막 페이지에 남는 공간이 낭비될 수 있음.
-
주소 구성: 페이지 번호(Page Number)와 페이지 내 오프셋(Offset)으로 구성된 논리 주소를 사용한다.
-
외부 조각화 없음: 고정 크기 페이지로 나뉘기 때문에 외부 조각화가 발생하지 않는다.
-
-
그림 (d):
- A, B, C 프로세스의 페이지들이 고정된 크기로 나뉘어 메모리의 다양한 위치에 저장되었다.
- 메모리 내 빈 공간을 효율적으로 활용하여 조각화를 방지한다.
8.4 연속 메모리 할당
연속 메모리 할당
연속 메모리 할당은 하나의 프로세스를 메모리의 연속된 공간에 배치하는 방식으로, 초기 운영체제에서 주로 사용된 메모리 관리 기법이다.
1. 연속 메모리 할당의 기본 개념
-
프로세스의 배치 방식:
- 메모리를 여러 개의 파티션으로 나누어 각 프로세스에 한 개의 파티션을 할당한다.
- 모든 프로세스는 연속된 메모리 공간을 차지하며, 메모리의 단순한 분배가 가능하다.
-
초기 운영체제의 사용 사례:
- MS-DOS와 같은 단일 사용자 단일 프로세스 환경에서 사용되었다.
- MS-DOS는 프로세스가 전체 메모리를 독점적으로 사용하는 방식으로 설계되었다.
2. 연속 메모리 할당의 유형
-
고정 크기 할당 (Fixed Size Partition):
- 메모리를 고정된 크기의 파티션으로 분할.
- 특징:
- 파티션 크기가 동일하거나, 사전에 정의된 다양한 크기로 나뉜다.
- 단순한 구현이 가능하지만, 내부 조각화(Internal Fragmentation)가 발생할 수 있다.
- 사례:
- IBM OS/360 MFT(Multiple Programming with a Fixed Number of Tasks)
-
가변 크기 할당 (Variable Size Partition):
- 프로세스가 요구하는 크기에 따라 메모리 파티션을 동적으로 생성 및 할당.
- 특징:
- 메모리를 효율적으로 사용할 수 있지만, 외부 조각화(External Fragmentation)가 발생 가능.
- 사례:
- IBM OS/360 MVT(Multiple Programming with a Variable Number of Tasks)
3. 연속 메모리 할당의 장단점
-
장점:
- 메모리 관리가 단순하고 구현이 쉬움.
- 초기의 단일 사용자 환경에서는 적합한 방식.
-
단점:
- 내부 및 외부 조각화 문제로 인해 메모리 공간의 낭비가 발생.
- 동시 실행 가능한 프로세스 수가 제한됨.
IBM 360의 연속 메모리 할당
IBM OS/360 운영체제에서 사용된 연속 메모리 할당 기법의 두 가지 방식, 즉 고정 크기 할당(MFT)과 가변 크기 할당(MVT) 이 있다.
1. 고정 크기 할당 (MFT: Multiple Fixed Tasks)

-
설명:메모리를 고정된 크기의 파티션으로 나누고, 각 파티션에 프로세스를 할당하는 방식.
-
그림 설명:
- 메모리는 운영체제 영역과 사용자 영역으로 나뉨.
- 사용자 영역은 고정된 크기의 파티션으로 구성되어 있으며, 각 프로세스는 고정 크기 파티션에 할당.
- 예: 파티션 1, 2, 3, 4 등이 미리 정의된 고정 크기를 갖고 있다.
2. 가변 크기 할당 (MVT: Multiple Variable Tasks)

-
설명: 프로세스가 요청한 메모리 크기에 따라 동적으로 파티션을 생성하고 할당하는 방식.
-
그림 설명:
- 메모리는 운영체제 영역과 사용자 영역으로 나뉘며, 사용자 영역은 프로세스 요청에 따라 가변적으로 파티션이 생성.
- 예: Region 1, Region 2, Region 3이 프로세스의 요구에 따라 할당된 영역.
3. 비교
| 특징 | 고정 크기 할당 (MFT) | 가변 크기 할당 (MVT) |
|---|---|---|
| 파티션 크기 | 고정 | 가변 |
| 조각화 유형 | 내부 조각화 발생 | 외부 조각화 발생 |
| 메모리 활용 효율성 | 낮음 | 높음 |
| 관리 복잡도 | 단순 | 복잡 |
단편화 (Fragmentation)
단편화는 프로세스에 메모리를 할당할 때, 사용할 수 없는 조각 메모리(홀, hole)가 발생하는 현상을 말한다. 이는 메모리 관리의 효율성을 저하시키며, 내부 단편화와 외부 단편화로 나뉜다.
1. 단편화의 정의
- 단편화 (Fragmentation):
- 프로세스의 메모리 요청에 따라 메모리가 할당되고 해제되는 과정에서 발생.
- 메모리 공간에 사용하지 못하는 조각 메모리(hole)이 생기는 현상.
2. 내부 단편화 (Internal Fragmentation)

-
설명:
- 메모리 파티션의 크기가 프로세스의 요구 크기보다 클 때, 파티션의 남은 공간이 낭비되는 현상.
- 파티션 내부의 사용되지 않는 공간이 문제.
-
특징:
- 고정 크기 할당 방식에서 주로 발생.
- 프로세스 크기에 맞춰 메모리를 정확히 할당하지 못하기 때문에 발생.
-
그림 설명:
- 파티션 4, 3, 2, 1의 내부에 남는 공간(홀)이 발생.
- 이 공간은 파티션 내부에 포함되어 있지만, 다른 프로세스가 사용할 수 없다.
3. 외부 단편화 (External Fragmentation)

-
설명:
- 메모리의 여러 할당된 영역 사이에 작은 조각들이 남아, 새로운 프로세스를 배치할 수 없는 현상.
- 메모리의 빈 공간이 분산되어 있어도, 프로세스의 요구 크기를 만족하지 못할 수 있음.
-
특징:
- 가변 크기 할당 방식에서 주로 발생.
- 조각화된 메모리 공간이 늘어나면서 메모리 낭비를 초래.
-
그림 설명:
- Region 3과 Region 1 사이에 할당되지 않은 조각 공간(홀)이 존재.
- 이러한 공간은 새로운 프로세스가 요구하는 크기를 만족하지 못해 비효율을 초래.
4. 내부 단편화 vs 외부 단편화
| 특징 | 내부 단편화 (Internal) | 외부 단편화 (External) |
|---|---|---|
| 발생 원인 | 고정 크기 할당 | 가변 크기 할당 |
| 문제 위치 | 파티션 내부 | 파티션과 파티션 사이 |
| 영향 | 메모리 공간 낭비 | 메모리 공간 분산으로 인한 배치 불가 |
5. 단편화 해결 방법
-
압축(Compaction):
- 외부 단편화를 해결하기 위해 메모리 조각들을 한쪽으로 모아 큰 연속 공간을 만드는 방법.
- CPU 오버헤드 발생 가능.
-
페이징(Paging):
- 고정 크기 블록으로 메모리를 나누어, 외부 단편화를 방지.
- 내부 단편화는 일부 발생할 수 있음.
-
세그먼테이션(Segmentation):
- 가변 크기 블록으로 메모리를 나누어 논리적 단위로 관리.
- 외부 단편화를 줄이지만, 일부 발생 가능.
연속 메모리 할당 구현
연속 메모리 할당은 하드웨어와 운영체제의 협력을 통해 구현된다.
1. 하드웨어 지원
-
필요한 레지스터:
-
Base 레지스터:
- 물리 메모리에서 프로세스가 시작되는 물리 메모리의 시작 주소를 저장.
- 프로세스 실행 중, 메모리 접근을 위한 기준점 역할.
-
Limit 레지스터:
- 해당 프로세스가 사용할 수 있는 메모리 크기를 저장.
- 메모리 접근 범위를 제한하여, 프로세스가 자신의 메모리 공간을 초과하지 않도록 보호.
-
주소 레지스터:
- 현재 접근 중인 메모리의 논리 주소를 저장.
- Base 레지스터와 더해져 실제 물리 메모리 주소를 계산.
-
-
주소 변환 하드웨어 (MMU):
- MMU(Memory Management Unit)는 논리 주소를 물리 주소로 변환.
- Base 레지스터와 주소 레지스터의 값을 더해 물리 주소를 계산.
- Limit 레지스터를 사용해 접근 범위를 검사하여, 메모리 보호를 수행.
2. 운영체제 지원
-
프로세스별 메모리 정보 관리:
- 운영체제는 각 프로세스의 물리 메모리 시작 주소(Base)와 크기 정보(Limit)를 저장.
- 이 정보를 바탕으로 메모리 접근을 관리하고 보호.
-
비어 있는 메모리 영역 관리:
- 할당되지 않은 메모리 공간(홀)을 관리하여 효율적인 메모리 할당 가능.
-
스케줄링과 레지스터 갱신:
- 프로세스를 스케줄링하여 실행할 때마다, 해당 프로세스의 Base와 Limit 정보를 CPU 레지스터에 적재.
- 이는 각 프로세스가 자신만의 독립된 메모리 공간을 사용하는 것처럼 보이도록 함.
3. 구현 흐름
-
운영체제가 새로운 프로세스를 메모리에 적재.
-
Base 레지스터와 Limit 레지스터에 프로세스의 메모리 시작 주소와 크기 정보를 설정.
-
MMU가 Base 레지스터와 논리 주소를 사용하여 물리 주소를 계산.
-
Limit 레지스터로 메모리 접근 범위를 확인, 초과 시 접근을 차단.
연속 메모리 할당에서 주소 변환과 메모리 보호
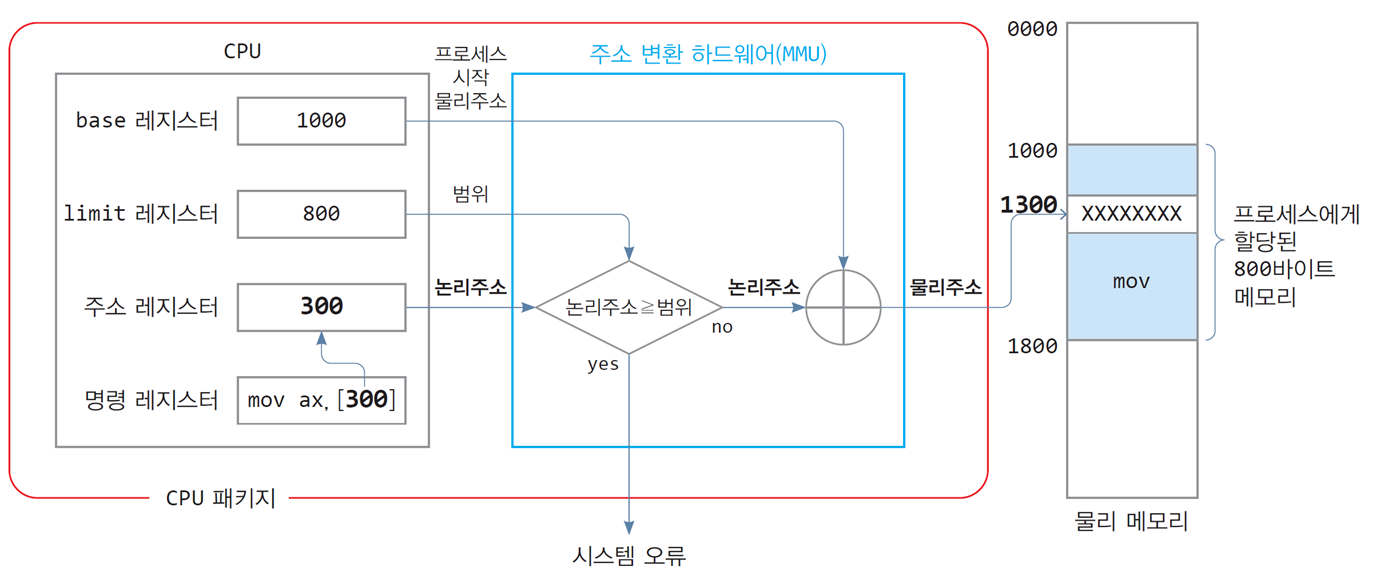
1. 주소 변환 과정
논리 주소 → 물리 주소 변환:
-
CPU가 명령어(
mov ax, [300])를 실행하며 논리 주소300을 참조. -
MMU(Memory Management Unit)가 Base 레지스터 값을 더해 물리 주소
1300번지 계산. -
Limit 레지스터를 확인하여 논리 주소가 범위를 초과하지 않는지 검증.
2. 메모리 보호
- 범위 확인:
- 논리 주소가
0에서799사이에 있는 경우, 메모리 접근이 허용. - 논리 주소가 범위를 초과하면 시스템 오류(System Error)를 발생시켜 보호.
- 논리 주소가
3. 그림 설명
-
CPU 내부:
- Base 레지스터:
1000 - Limit 레지스터:
800 - 주소 레지스터:
300 - 명령어 레지스터:
mov ax, [300] - 논리 주소
300은 Base 레지스터를 통해 물리 주소1300으로 변환.
- Base 레지스터:
-
메모리 구조:
- 물리 메모리
1000~1799번지가 프로세스에 할당. - 물리 주소
1300번지에 접근해 데이터를 처리.
- 물리 메모리
연속 메모리 할당의 장단점
1. 장점
-
간단한 주소 변환 과정:
- 논리 주소를 물리 주소로 바꾸는 과정이 단순하다.
- Base 레지스터와 Limit 레지스터를 이용하여 주소를 계산하므로, CPU 메모리 접근 속도가 빠르다.
-
운영체제의 부담 경감:
- 운영체제가 관리해야 할 정보량이 적다.
- 프로세스별로 메모리 시작 주소(Base)와 크기(Limit)만 관리하면 되므로 효율적이다.
2. 단점
-
메모리 할당의 유연성 부족:
- 연속된 메모리 공간이 필요하므로, 충분한 크기의 메모리가 존재하더라도 조각화(Fragmentation)로 인해 할당할 수 없는 경우가 발생.
- 작은 조각(홀)을 합쳐도 하나의 프로세스에 필요한 연속된 공간을 확보할 수 없으면 메모리 낭비가 발생.
-
단편화 문제:
- 내부 단편화: 고정 크기 파티션 할당 시, 프로세스가 파티션 크기보다 작으면 낭비되는 메모리가 발생.
- 외부 단편화: 가변 크기 할당 시, 메모리의 남은 공간이 분산되어 프로세스가 요구하는 연속된 메모리 공간을 확보하지 못함.
-
해결 방안:
- 메모리 압축(Compaction):
- 메모리의 조각(홀)을 한쪽으로 모아 연속된 메모리 공간을 확보.
- 하지만 메모리 압축 과정에서 CPU와 I/O 오버헤드가 발생할 수 있음.
- 메모리 압축(Compaction):
홀 선택 알고리즘과 동적 메모리 할당
1. 할당 리스트 (Allocation List)
-
운영체제의 역할:
- 메모리의 할당된 파티션과 비어 있는 공간(hole)에 대한 정보를 관리.
- 할당된 위치, 크기, 사용 여부 등을 유지.
-
목적:
- 메모리 공간을 효율적으로 관리하고, 단편화를 최소화.
- 프로세스의 메모리 요청을 신속하게 처리.
2. 홀 선택 전략
동적 메모리 할당 요청에 대해, 운영체제는 비어 있는 메모리 공간(홀) 중 하나를 선택하여 할당한다. 대표적인 선택 알고리즘 세 가지는 다음과 같다:
(1) First-Fit (최초 적합)
- 설명:
- 메모리 리스트에서 첫 번째로 요청 크기 이상인 홀을 선택하여 할당.
- 장점:
- 검색 속도가 빠름.
- 구현이 간단하며, 할당 요청 처리 시간이 짧음.
- 단점:
- 사용하지 못하는 작은 조각(홀)이 메모리의 앞부분에 축적되어 단편화 발생 가능.
(2) Best-Fit (최적 적합)
- 설명:
- 메모리 리스트에서 요청 크기에 가장 근접한 크기의 홀을 선택하여 할당.
- 장점:
- 메모리 낭비를 줄여 단편화를 최소화.
- 단점:
- 크기별로 홀을 정렬하지 않으면 리스트 전체를 검색해야 하므로 속도가 느릴 수 있음.
(3) Worst-Fit (최악 적합)
- 설명:
- 메모리 리스트에서 가장 큰 홀을 선택하여 할당.
- 장점:
- 가장 큰 공간을 사용하므로, 남은 공간을 큰 조각으로 유지.
- 단점:
- 단편화가 더 심각해질 수 있음.
- 크기별 정렬이 없을 경우, 검색 속도가 느림.
3. 비교
| 전략 | 장점 | 단점 |
|---|---|---|
| First-Fit | 빠른 검색 및 간단한 구현 | 단편화 발생 가능 |
| Best-Fit | 메모리 낭비 최소화 | 검색 속도가 느림 |
| Worst-Fit | 큰 홀 유지로 대형 요청 처리 가능 | 단편화 증가 가능성 |
3가지 홀 선택 알고리즘의 실행 사례
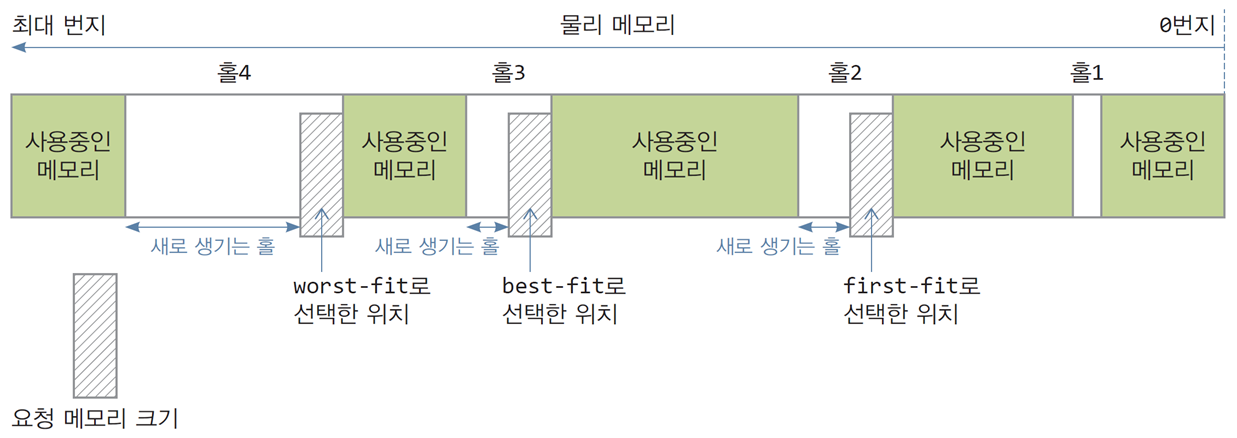
1. 메모리 구조
-
메모리에는 비어 있는 공간(홀)과 사용 중인 메모리가 존재.
-
홀은 크기가 각각 다르며, 슬라이드에서는
홀4,홀3,홀2,홀1로 구분됨. -
비어 있는 홀 중 하나를 선택하여 메모리를 할당해야 한다.
2. 각 알고리즘의 동작
(1) First-Fit (최초 적합)
-
설명:요청된 크기 이상인 첫 번째 홀을 선택하여 할당.
-
결과:
홀2가 선택됨.- 메모리 리스트의 앞부분부터 검색하며, 처음으로 크기가 요청 크기보다 큰 홀을 선택.
(2) Best-Fit (최적 적합)
-
설명:요청된 크기에 가장 근접한 크기의 홀을 선택하여 할당.
-
결과:
홀3이 선택됨.- 모든 홀을 탐색한 후, 요청 크기에 가장 근접한 크기의 홀을 선택.
- 메모리 낭비를 최소화.
(3) Worst-Fit (최악 적합)
-
설명:요청된 크기 이상인 가장 큰 홀을 선택하여 할당.
-
결과:
홀4가 선택됨.- 가장 큰 홀을 선택하여 남은 공간을 최대한 크게 유지.
4. 비교
| 전략 | 선택된 홀 | 장점 | 단점 |
|---|---|---|---|
| First-Fit | 홀2 | 검색 속도가 빠름 | 단편화가 앞부분에 축적될 가능성 |
| Best-Fit | 홀3 | 메모리 낭비를 최소화 | 검색 시간이 오래 걸릴 수 있음 |
| Worst-Fit | 홀4 | 남은 공간을 큰 조각으로 유지 | 단편화가 심해질 가능성 |
8.5 세그먼테이션 메모리 관리
세그먼테이션(Segmentation) 개요
세그먼테이션은 프로그램을 구성하는 논리적 단위(세그먼트)로 메모리를 분할하여 관리하는 기법이다. 각 세그먼트는 고유한 크기를 가지며, 프로세스의 논리적 구조를 반영한다.
1. 세그먼트란?
-
정의:
- 세그먼트는 프로그램을 구성하는 논리적 단위로, 프로세스는 여러 개의 세그먼트로 이루어져 있다.
- 세그먼트마다 크기가 다르며, 프로그램의 기능적/구조적 요소를 기반으로 구분된다.
-
일반적인 세그먼트 종류:
- 코드 세그먼트: 실행할 명령어 저장.
- 데이터 세그먼트: 전역 변수 등 데이터 저장.
- 스택 세그먼트: 함수 호출 및 반환 주소 저장.
- 힙 세그먼트: 동적 메모리 할당 영역.
2. 세그먼테이션 기법
-
논리 세그먼트로 분리:
- 프로세스는 논리적 세그먼트들로 나뉘며, 각 세그먼트를 물리 메모리의 물리 세그먼트에 매핑하여 저장.
- 예: 코드, 데이터, 스택, 힙 등 각 세그먼트를 별도로 관리.
-
주소 공간:
- 프로세스의 주소 공간은 논리 세그먼트로 구성된다.
- 각 논리 세그먼트는 컴파일러와 링커에 의해 물리 메모리의 세그먼트로 변환되어 적재.
-
논리 → 물리 주소 변환:
- 시스템 전체에 하나의 세그먼트 테이블을 두어 논리 주소를 물리 주소로 변환.
- 각 세그먼트의 시작 주소(Base)와 크기(Limit)가 테이블에 저장.
-
외부 단편화 발생:
- 세그먼트 크기가 가변적이므로, 외부 단편화(External Fragmentation)가 발생할 수 있다.
3. 주요 특징
-
논리적 구조 반영:
- 프로그램의 논리적 구조를 그대로 반영하여 메모리를 관리.
-
유연한 메모리 관리:
- 프로세스별로 서로 다른 크기의 세그먼트를 생성하고 관리.
-
단점:
- 외부 단편화로 인해 메모리 공간 낭비 발생 가능.
- 주소 변환 시 추가적인 오버헤드 발생.
논리 세그먼트와 물리 세그먼트 매핑
세그먼테이션(Segmentation) 기법에서 논리 세그먼트와 물리 세그먼트 간의 매핑 과정이다. 각 프로세스는 논리 세그먼트로 나뉘며, 세그먼트 테이블을 통해 물리 메모리의 적절한 위치에 매핑된다.
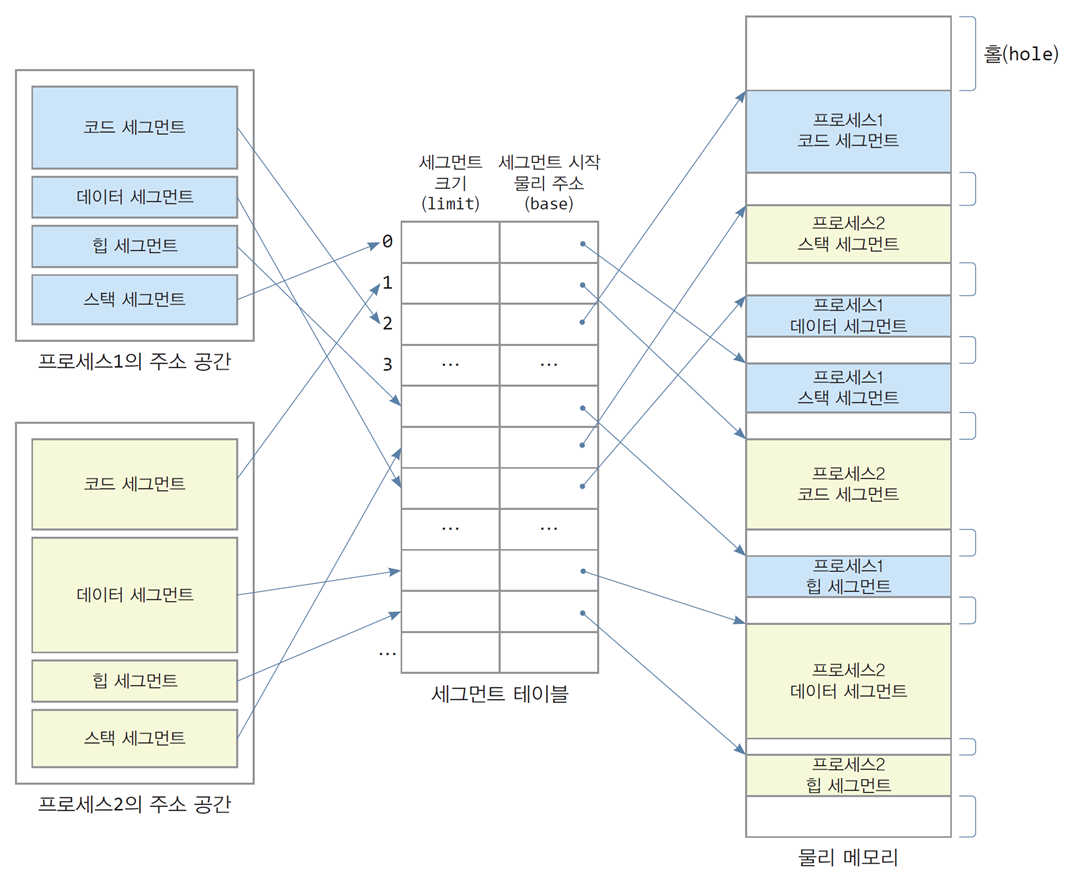
-
왼쪽: 프로세스1과 프로세스2의 논리 세그먼트.
-
가운데: 논리 세그먼트를 관리하는 세그먼트 테이블.
-
오른쪽: 물리 메모리로 매핑된 각 세그먼트.
코드,스택,힙,데이터세그먼트가 서로 다른 물리적 위치에 저장.
1. 논리 세그먼트 구조
- 논리 세그먼트:
- 프로세스는 논리적으로 코드, 데이터, 힙, 스택 세그먼트로 나뉜다.
- 각 세그먼트는 프로그램 실행에 필요한 서로 다른 목적을 담당.
- 논리적 세그먼트는 메모리 주소 공간의 구조를 반영하여 관리됨.
2. 세그먼트 테이블
-
구조:
- 세그먼트 테이블은 각 세그먼트의 크기(Limit)와 물리 메모리 시작 주소(Base)를 저장.
- 예:
코드 세그먼트: Limit = 크기, Base = 물리 주소 시작 위치.데이터 세그먼트,스택 세그먼트,힙 세그먼트도 각각 저장.
-
역할:
- 논리 주소를 물리 주소로 변환하는 데 사용.
- 프로세스가 메모리에 접근할 때, 세그먼트 테이블을 참조하여 주소를 변환.
3. 물리 메모리 매핑
- 매핑 과정:
- 프로세스의 논리 세그먼트는 물리 메모리의 빈 공간(Hole)에 매핑.
- 예:
- 프로세스1의
코드 세그먼트는 물리 메모리의 첫 번째 홀에 매핑. - 프로세스1의
스택 세그먼트는 두 번째 물리 공간에 매핑. - 프로세스2의 세그먼트들도 물리 메모리의 남은 공간에 매핑.
- 프로세스1의
4. 주요 특징
-
유연한 메모리 관리:
- 각 프로세스는 독립적으로 논리적 세그먼트를 물리 메모리에 할당받음.
- 프로세스별로 필요한 크기만큼 메모리를 할당받아 낭비를 줄임.
-
주소 변환:
- 논리 주소는 세그먼트 테이블을 통해 물리 주소로 변환.
물리 주소 = Base + Offset, Offset이 Limit을 초과하면 메모리 보호.
-
외부 단편화 문제:
- 물리 메모리에 빈 공간(Hole)이 분산되면서 외부 단편화 발생 가능.
세그먼테이션의 구현
세그먼테이션(Segmentation) 기법은 하드웨어와 운영체제의 협력을 통해 구현된다.
1. 하드웨어 지원
-
논리 주소 구성:
- 논리 주소는
[세그먼트 번호, 옵셋]의 형태로 구성. - 세그먼트 번호는 세그먼트 테이블의 인덱스로 사용되고, 옵셋은 세그먼트 내의 특정 위치를 지정.
- 논리 주소는
-
CPU 레지스터:
- 세그먼트 테이블 베이스 레지스터 (STBR):
- 세그먼트 테이블의 시작 주소를 가리키는 레지스터.
- CPU는 세그먼트 테이블을 참조하여 논리 주소를 물리 주소로 변환.
- 세그먼트 테이블 베이스 레지스터 (STBR):
-
MMU (Memory Management Unit):
- 논리 주소의 옵셋이 세그먼트 크기(Limit)를 초과했는지 확인.
- 초과 시 메모리 보호를 위해 접근을 차단.
-
세그먼트 테이블:
- 메모리에 저장되며, 각 세그먼트의 시작 주소(Base)와 크기(Limit) 정보를 포함.
- 주소 변환 및 메모리 보호 기능 지원.
2. 운영체제 지원
-
세그먼트의 동적 관리:
- 세그먼트 테이블을 동적으로 갱신하며, 새로운 세그먼트의 할당 및 기존 세그먼트의 반환 처리.
- 메모리에서 자유 공간 관리.
-
컨텍스트 스위칭:
- 프로세스 전환 시, 해당 프로세스의 세그먼트 테이블 정보를 CPU 레지스터에 로딩.
- 이 과정에서 세그먼트 테이블 베이스 레지스터(STBR) 값도 변경.
3. 컴파일러, 링커, 로더 지원
-
컴파일러:
- 논리적 세그먼트를 정의하고, 각 세그먼트의 코드 및 데이터를 분리.
-
링커:
- 세그먼트를 연결하여 논리 주소 공간을 생성.
-
로더:
- 생성된 논리 주소를 실제 물리 메모리에 적재.
4. 주요 특징
-
주소 변환:
- CPU는
[세그먼트 번호, 옵셋]을 기반으로 논리 주소를 계산. 물리 주소 = Base + Offset(Offset이 Limit을 초과하지 않을 경우).
- CPU는
-
메모리 보호:
- 각 세그먼트의 범위(Limit)를 벗어나는 접근을 MMU에서 차단.
-
유연한 메모리 관리:
- 세그먼트 크기가 가변적이므로 메모리를 효율적으로 활용 가능.
세그먼테이션에서 논리 주소의 물리 주소 변환
세그먼테이션(Segmentation) 기법에서 논리 주소를 물리 주소로 변환하는 과정이다. 각 논리 세그먼트는 세그먼트 테이블을 통해 물리 메모리에 매핑되며, MMU(Memory Management Unit)가 주소 변환과 보호 기능을 수행한다.
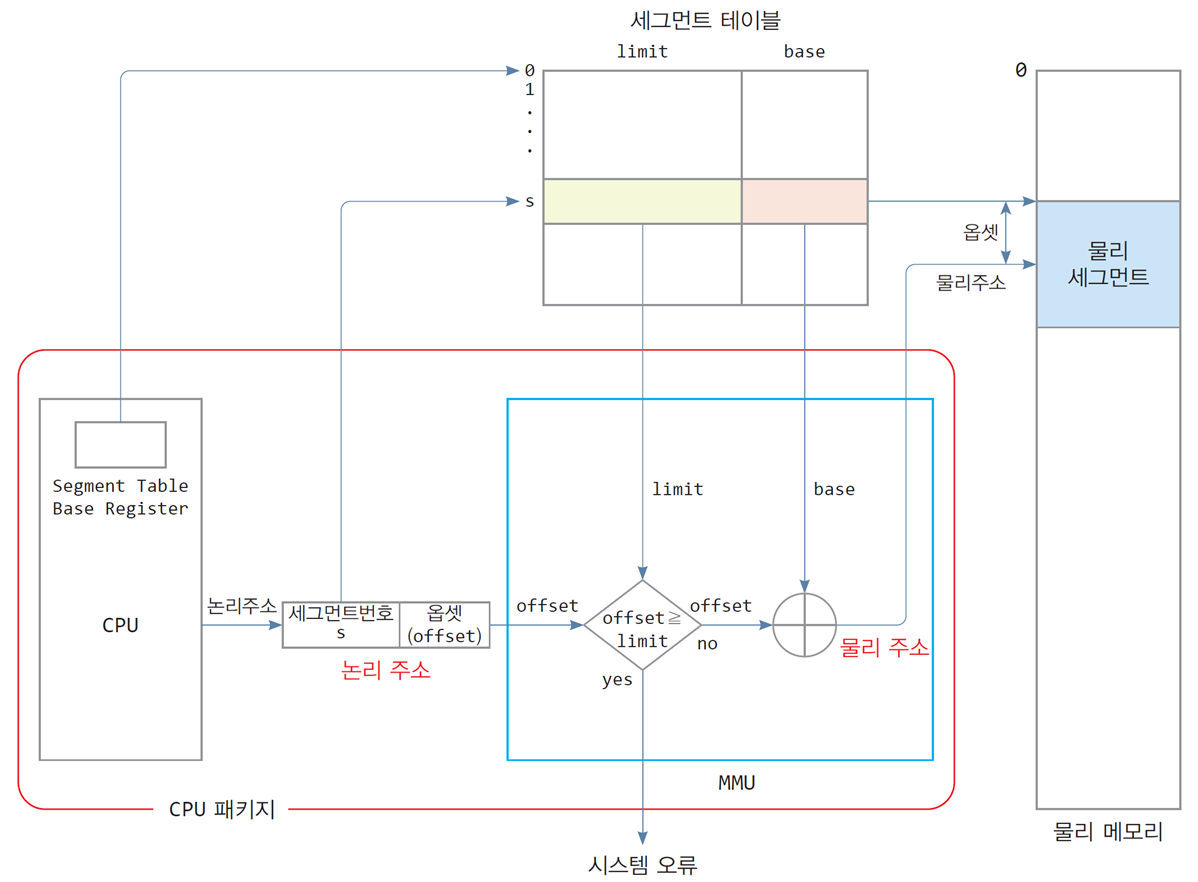
- 논리 주소:
[s, offset]으로 구성. - 세그먼트 테이블:
- 각 세그먼트의 Base와 Limit 정보를 포함.
- MMU:
- 논리 주소의 Offset이 Limit를 초과하지 않으면, Base와 Offset을 더하여 물리 주소를 계산.
- 물리 메모리:
- 변환된 물리 주소를 참조하여 데이터에 접근.
1. 논리 주소의 구성
- 논리 주소는 세그먼트 번호(s)와 옵셋(offset)으로 구성된다.
- 세그먼트 번호: 세그먼트 테이블의 인덱스 역할.
- 옵셋: 세그먼트 내에서의 위치를 지정.
2. 물리 주소 변환 과정
-
CPU의 논리 주소 생성:
- 프로그램은 논리 주소
[s, offset]를 생성. - CPU는 세그먼트 테이블 베이스 레지스터(STBR)를 통해 세그먼트 테이블에 접근.
- 프로그램은 논리 주소
-
세그먼트 테이블 참조:
- 세그먼트 번호
s를 기반으로 세그먼트 테이블에서 해당 세그먼트의 시작 주소(Base)와 크기(Limit)를 가져옴.
- 세그먼트 번호
-
주소 변환:
- 물리 주소 =
Base + Offset - Offset이 Limit를 초과하면 시스템 오류(System Error) 발생.
- 물리 주소 =
-
MMU를 통한 검증:
- MMU가 Offset 값이 세그먼트 크기(Limit)보다 작거나 같은지 확인.
- Offset ≥ Limit인 경우, 접근을 차단하고 시스템 오류를 반환.
-
물리 주소로 변환:
- Offset이 유효한 경우, 물리 메모리의 해당 세그먼트 위치로 매핑.
3. 메모리 보호
-
유효성 검증:
- MMU가 논리 주소의 유효성을 검사하여, 잘못된 접근으로부터 메모리를 보호.
-
오류 처리:
- Offset이 Limit 범위를 초과하면, 시스템 오류를 반환하여 메모리 오염 방지.
5. 주요 특징
-
주소 변환의 단순성:
- 간단한 수식(
Base + Offset)으로 물리 주소를 계산.
- 간단한 수식(
-
메모리 보호:
- MMU가 유효성 검사를 수행하여 잘못된 메모리 접근을 방지.
-
유연한 메모리 관리:
- 세그먼트별로 독립적인 크기를 가지므로 메모리 사용 효율성 증가.
세그먼테이션과 단편화
단편화는 메모리를 효율적으로 관리하지 못하여 사용할 수 없는 메모리 공간(Hole)이 발생하는 현상을 말한다.
-
세그먼테이션에서는 외부 단편화가 발생할 수 있음.
- 논리 세그먼트의 크기가 다양하기 때문에 물리 메모리에서 비어 있는 공간들이 발생.
-
내부 단편화는 발생하지 않음.
- 세그먼트 크기가 동적으로 조정되므로, 할당된 공간 내에서 낭비가 발생하지 않음.
