2015년에 Diffusion 방법을 처음 다룬 논문 이 나왔었다. 실제 확산 현상 같은거에서 아이디에이션을 했다는 요 논문을 가지고 좀 더 발전시켜서 고퀄리티 생성에 Diffusion Model을 쓸 수 있음을 보여준게 DDPM 모델이다.
DDPM 자체도 사실 맨처음 나왔을 때는 그렇게 주목 받는 정도는 아니었는데, 이후 속도도 개선하고 성능도 더 끌어올리면서 Diffusion Model을 적용한 제품들이 충격과 공포를 가져다 주었고... 그제서야 부랴부랴 디퓨전 논문 뒤적거렸던 나같은 범부놈은 완전히 새로운 개념과 수식에 충격과 공포를 느꼈다.
아무튼 왜 2015 Diffusion이 좀 들 언급되는지는 모르겠을 정도로 이론관련 내용의 상당부분은 2015 Diffusion 내용과 겹치기는 하는데...
사실 DDPM 수식이 토나와서 그렇지 뭐랄까 더 친절한거 같기는 하다.. 이거만 봐도 이전 Diffusion 이해가 쌉가능하기도 하고.. 그래서 DDPM 보면서 공부 시작하게된 사람이 많지 않았을까.. 아무튼 여기서는 기존 Diffusion의 내용들도 다 같이 설명하는 것으로..
뭐랄까 핵심요약이라기엔 그냥 썰풀이 인트로 같지만 abstract 배껴쓰기:
Diffusion Probabilistic Models을 이용해 고품질 이미지 합성 결과를 제시함.
새로운 변분 하한 설계를 통해 모델을 학습함. 이를 통해 더 나은 최적화가 가능해지고, 높은 품질의 샘플을 생성할 수 있음.
DPM은 자연스럽게 Progressive Lossy Decompression 구조를 가지며, 이를 Autoregressive 디코딩의 일반화된 형태로 해석할 수 있음.
CIFAR-10 최고 성능
Inception Score(IS): 9.46
FID(Fréchet Inception Distance): 3.17 (SOTA, 최고 성능)
LSUN(256×256) 데이터셋에서도 ProgressiveGAN 수준의 샘플 품질을 달성함.
개인적으로 abstract가 몬가 핵심적이라는 느낌이 안든다.. (알못이라면 ㅈㅅ합니다)
기술 개요
Diffusion Model 기본 개념
t 시점의 상태는 t-1 시점의 상태에만 의존하는 확률 과정을 Markov property를 띠는 Markov process 라고 한다.
p(xt∣xt−1,...,x2,x1,x0)=p(xt∣xt−1)
이 Markov process를 기반으로 한 연속적인 상태 전이 모델을 Markov Chain이라고 한다.
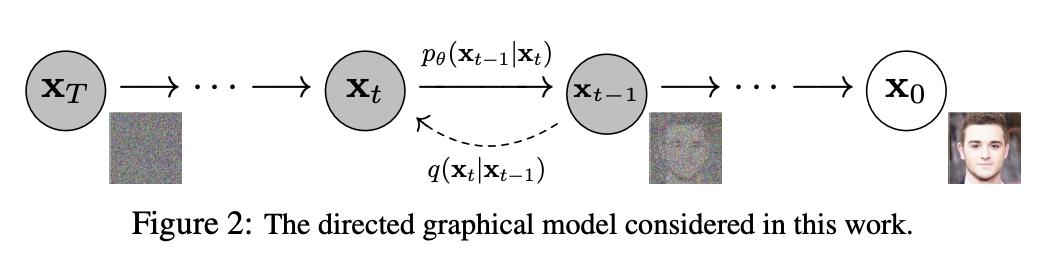
Diffusion Model은 데이터에 점진적으로 노이즈를 추가하는 과정을 학습하고, 반대로 노이즈를 제거하는 방식으로 샘플을 생성하는 parameterized Markov chain 이다.
Markov property를 유지해가며, x0 상태에서 점진적으로 noise를 추가해가는 과정을 forward process라고 하며, 역시 Markov property를 유지하여 noise를 점진적으로 제거하는 과정을 reverse process 라고 한다.
Forward Process
Markov 가정 하에서 forward process의 분포 q는 다음과 같은 조건부 확률로 분해된다:
q(x1:T∣x0)=t=1∏Tq(xt∣xt−1)
이 Forward process에서 각 스텝의 조건부 확률 분포는
q(xt∣xt−1)=N(xt;1−βtxt−1,βtI)
(베타는 노이즈 얼마나 많이 넣을건지)
이렇게 설계했다. → 왜 이렇게 설계했을까?
이렇게 설계하면 다음 세 가지 조건을 만족할 수 있기 때문이다. (어 논문에 실제 이렇게 있는건 아니고 제가 이해하기 편한 방식대로 서술한건데.. 틀렸다면 말해주세요 근데 보는사람 없는거같음)
(i) q(xT)가 가우시안에 근접하게 됨
Forward 확산의 목표는 데이터 x0에서 시작해서 점진적으로 노이즈를 추가하여, 마지막 xT가 완전한 가우시안 노이즈 N(0,I)가 되도록 만드는 것이다.
xT=t=1∏T1−βtx0+t=1∑Tβtϵt
결과적으로 t→T가 되면 원본 데이터 정보가 사라지고 순수한 가우시안 노이즈가 남게 된다.
q(xT)≈N(0,I)
(ii) 확률 분포를 선형 Gaussian으로 유지할 수 있음
Forward 과정의 확률 분포가 항상 Gaussian 형태로 유지되도록 설계해야 한다. 이를 위해, 각 스텝에서 선형 변환만 수행하도록 만들었다.
이렇게 하면 reverse process에서도 Gaussian 형태를 유지할 수 있어서, 복원이 쉬워진다.
(iii) 선형 Gaussian이므로 닫힌 형태 해(closed-form solution)로 xt를 샘플링할 수 있음
Forward 과정이 선형 Gaussian이면, 여러 단계 계산 없이 x0에서 바로 xt를 샘플링할 수 있는 공식을 유도할 수 있다:
xt=αˉtx0+1−αˉtϵ,ϵ∼N(0,I)
여기서:
αt=1−βt
αˉt=∏s=1tαs (누적곱)
이를 통해 forward process에서 효율적인 샘플링을 수행할 수 있다.
Reverse Process
Forward 과정의 분포 q(xt−1∣xt)를 직접 계산하는 것은 intractable하다. 베이즈 정리로 풀어보면 알수 있다.
q(xt−1∣xt)=q(xt)q(xt∣xt−1)q(xt−1)
여기서 분모 q(xt)를 계산하기 위해 모든 가능한 xt−1에 대해 적분해야 하므로, closed-form solution을 얻기가 어렵다.
따라서 직접 계산하는 대신, 모델 pθ(xt−1∣xt)를 학습하여 근사하는 방식을 사용한다.
Reverse Kernel 정의
Reverse 과정의 확률 분포를 다음과 같은 정규 분포로 가정한다:
pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),θ∑(xt,t))
즉, xt로부터 xt−1을 생성하는 분포를 정규 분포로 가정하고,
그 평균 μθ(xt,t)와 분산 ∑θ(xt,t)을 신경망 파라미터 θ로 결정되는 함수로 두는 것이다.
논문에서는 분산 ∑θ를 시간에 따른 고정값으로 설정하거나 간단한 형태로 제한하였다.
예를 들어, Forward 과정의 posterior 분산 값인 β~t를 사용하기도 한다.
실제로 고정값을 사용해도 성능에 큰 차이가 없었다구 한다.
Forward Posterior를 활용한 μθ(xt,t) 도출
Reverse 분포 pθ(xt−1∣xt)를 유도하기 위해, Forward Posterior를 활용한다.
Forward 과정에서 베이즈 정리를 적용하면 다음과 같은 posterior 분포를 얻을 수 있다:
LT 항: xT에 대한 모델과 실제 분포 차이.
보통 p(xT)=N(0,I) , q(xT)≈N(0,I) 이므로 그냥 상수로 간주
Lt−1 항: 각 시간 스텝 t에 대해 q(xt−1∣xt,x0)와 pθ(xt−1∣xt) 사이의 KL Divergence
즉 모델의 한 스텝 역복원 성능을 측정하는 항으로, Forward 과정의 posterior (참고값)와 모델의 예측 분포가 얼마나 가까운지를 평가한다. Forward의 posterior는 x0에 조건부이므로 학습 시에는 x0를 알고 있을 때의 target 분포로 간주할 수 있다.
요 친구가 사실상 핵심이 된다. KLD 식을 한번 다시 풀어보면,