본 글은 Hierachical Structure의 글쓰기 방식으로, 글의 전체적인 맥락을 파악하기 쉽도록 작성되었습니다.
또한 본 글은 CSF(Curation Service for Facilitation)로 인용된(참조된) 모든 출처는 생략합니다.
[요약정리]Stanford University CS231n. Lecture 05. | Convolutional Neural Networks
1. CONTENTS
1.1 Table
| Velog | Lecture | Description | Video | Slide | Pages |
|---|---|---|---|---|---|
| 작성중 | Lecture01 | Introduction to Convolutional Neural Networks for Visual Recognition | video | slide | subtitle |
| 작성중 | Lecture02 | Image Classification | video | slide | subtitle |
| 작성중 | Lecture03 | Loss Functions and Optimization | video | slide | subtitle |
| 완료 | Lecture04 | Introduction to Neural Networks | video | slide | subtitle |
| 완료 | Lecture05 | Convolutional Neural Networks | video | slide | subtitle |
| 완료 | Lecture06 | Training Neural Networks I | video | slide | subtitle |
| 완료 | Lecture07 | Training Neural Networks II | video | slide | subtitle |
| 작성중 | Lecture08 | Deep Learning Software | video | slide | subtitle |
| 작성중 | Lecture09 | CNN Architectures | video | slide | subtitle |
| 작성중 | Lecture10 | Recurrent Neural Networks | video | slide | subtitle |
| 작성중 | Lecture11 | Detection and Segmentation | video | slide | subtitle |
| 작성중 | Lecture12 | Visualizing and Understanding | video | slide | subtitle |
| 작성중 | Lecture13 | Generative Models | video | slide | subtitle |
| 작성중 | Lecture14 | Deep Reinforcement Learning | video | slide | subtitle |
| 작성중 | Lecture15 | Invited Talk: Song Han Efficient Methods and Hardware for Deep Learning | video | slide | subtitle |
| 작성중 | Lecture16 | Invited Talk: Ian Goodfellow Adversarial Examples and Adversarial Training | video | slide | subtitle |
2. Flow
2.1 뉴런의 구조에 대한 이해
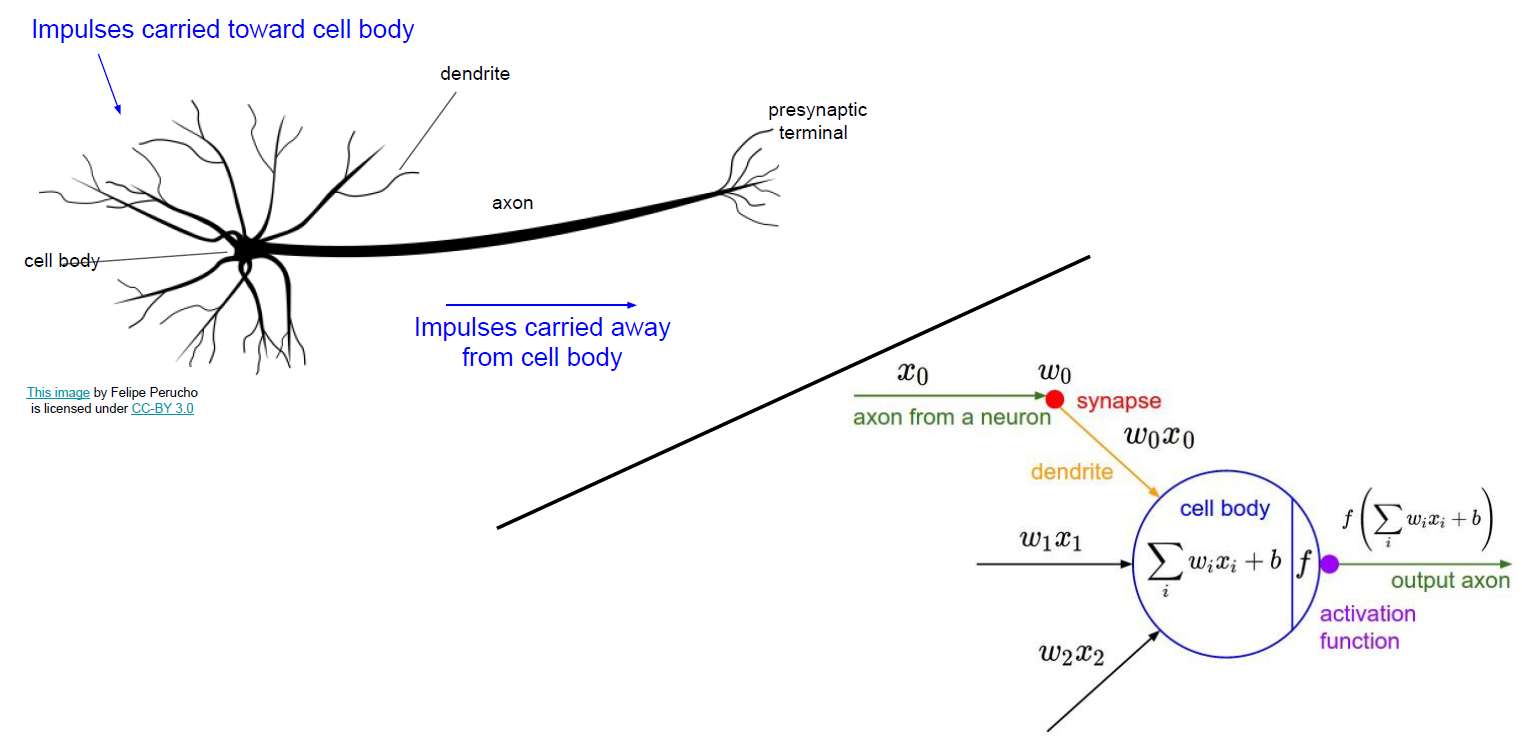
2.2 뉴런의 아키텍쳐
- 선형 함수와 비선형 함수의 합으로 이어짐
- 보통 Sigmoid 함수와 ReLU함수를 많이 사용

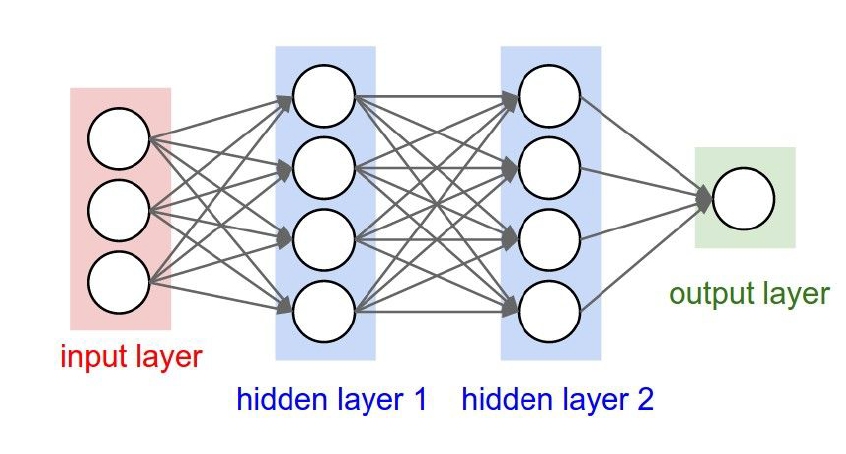
2.3 Fully Connected Layer
- 모든 Layer가 모두 연결됨.
2.4 Convolution Neural Networks
- 공간적인 구조를 유지하는 Layer를 가짐
- 필터를 만들고 그 필터가 움직이면서 내적
- 필터는 하나의 특징을 잡음
- 예를 들어
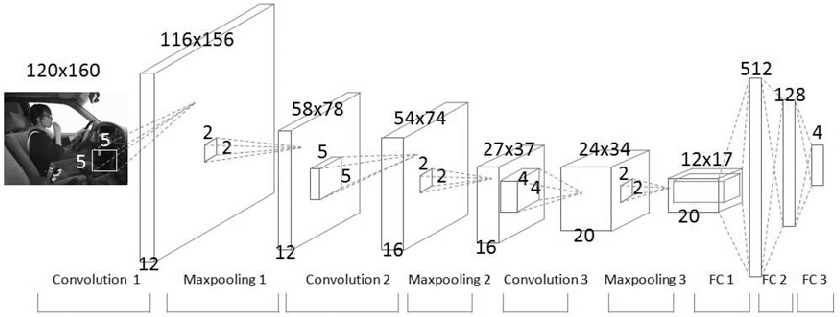
- 5x5x3의 image에서 특징을 잡아내는 5x5x3의 filter를 쓰면 3x3x1의 Convolved Feature가 나옴!
- 합성곱 신경망- 32x32x3(convolution map:image) 에서 5x5x3(filter)를 쓰면 28x28x1(activation map)이 나옴
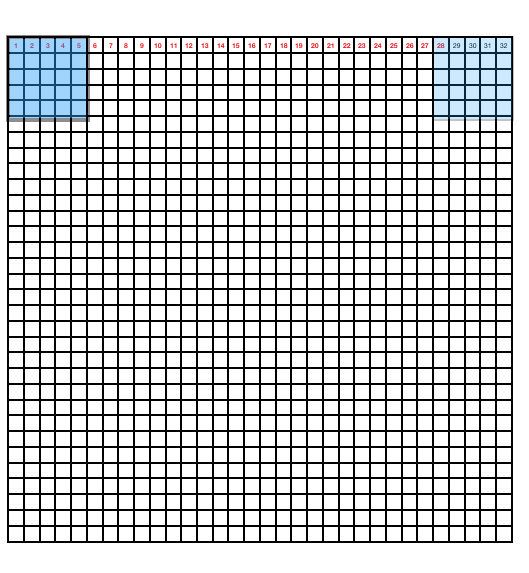
- 이 때
- Stride 는 픽셀씩 이동할 것인지 필터가 이미지를 넘어가면 안됨
- convolution 과정시 input사이즈와 activation map의 사이즈를 맞추기 위해 Zero-Padding
- Pooling은 강제로 downsampling을 하고 싶을 떄 depth에 영향을 주지 않고 파라미터의 수를 줄이는 역할 주로 Maxpooling을 사용
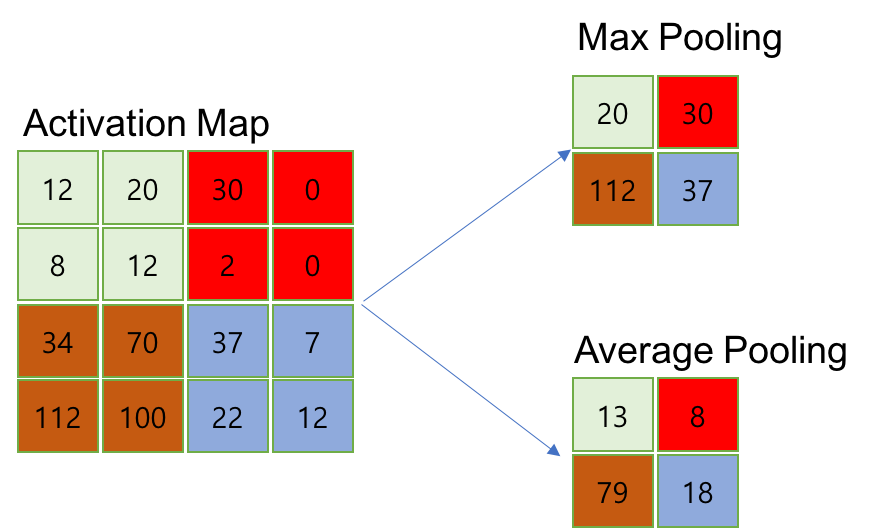
- 보통 pooling은 모든 픽셀이 한번씩만 연산에 참여하도록(window size와 Stride는 같은 값으로 설정하면 됨)
- Stride 는 픽셀씩 이동할 것인지 필터가 이미지를 넘어가면 안됨
- Feature Map 크기를 결정하는 식 - 자연수가 되어야 함
- Feature Map의 행, 열 크기는 Pooling 크기의 배수
- 입력 높이 : H / 폭 : W
- 필터 높이 : FH / 폭 : FW
- Stride : S
- 패딩 사이즈 : P
- {(입력데이터의 높이 +(2x패딩사이즈)- 필터높이)/Stride의 크기}+1 = 출력높이
- CNN 구성 예
- 32x32x3(convolution map:image) 에서 5x5x3(filter)를 쓰면 28x28x1(activation map)이 나옴
- CNN 딥러닝 모델 예
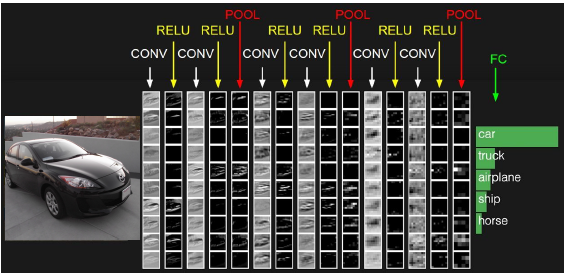
- Convolution layer를 여러개 사용하고 Fully connected layer를 마지막에 사용하면 CNN 딥러닝 모델이 만들어 짐 - 이렇게 Neural Newtwork를 Training 시킬 때 고려해야 할 것에 대해 알아보자
{kind=link}
2.5 Neural Newtwork를 Training 시킬 때 고려해야 할 것
2.5.1 Neural Network Traing이란?
- network parameter를 최적화하는 방법 중 Gradient Descent Algorithm에 대해서 배웠다.
- 모든 data를 가지고 gradient descent Algorithm에 적용을 하면 계산량이 많기 때문에 SGD(Stochastic Gradient Descent) Algorithm을 이용
- Sample을 뽑아내 Gradient Desscent Algorithm을 사용하는 방법
- 여기서 생각해볼 것.
Q1. 모델을 어떻게 선정해야 하는가
Q2. Training 할 때 유의할 사항
Q3. 평가는 어떻게 할 것인가.
2.5.2 Activation Function
2.5.2.1 Sigmoid Function
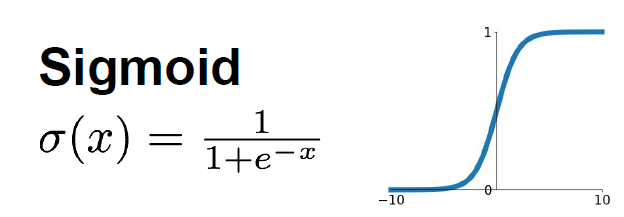
- 출력이 0~1 사이의 값이 나오도록 하는 선형 함수
- 단점
- Saturated neurons가 Gradient값을 0으로 만든다.
- 원점 중심이 아니다.
- 지수함수가 계산량이 많다.
-
- Saturate : ‘포화’라고 해석을 하는데, 입력이 너무 작거나 클 경우 값이 변하지 않고 일정하게 1로 수렴하거나 0으로 수렴하는 것을 포화라고 생각하고 Gradient의 값이 0인 부분을 의미- Gradient가 0이 되는 것이 문제가 되는 이유
- Chain Rule 과정을 생각했을 때, Global gradient값이 0이 되면 즉 결과 값이 0이 되면 local gradient 값도 0이 된다. 따라서 Input에 있는 gradient 값을 구할 수 없다.- 원점 중심이 아닌 것이 문제가 되는 이유
- output의 값이 항상 양수면 다음 input으로 들어갔을 때도 항상 양수이게 된다. 그렇다면 다음 layer에서 의 값을 update할 때 항상 같은 방향으로 update가 된다. 다음 그림의 예로 설명하면 우리가 원하는 vector가 파란색일 때, 의 같은 경우 제 1사분면과 제 3사분면으로 update가 되기 때문에 우리가 원하는 방향으로 update를 하기 힘들다.
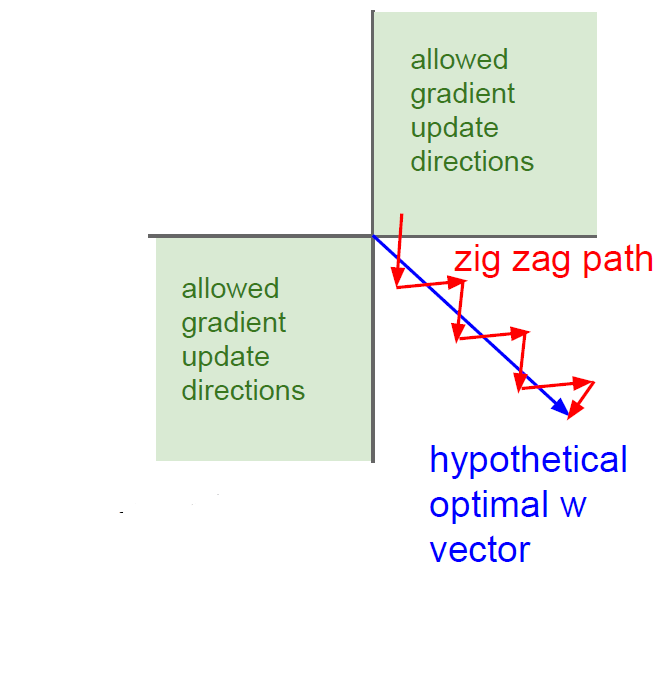
- 원점 중심이 아닌 것이 문제가 되는 이유
- Gradient가 0이 되는 것이 문제가 되는 이유
- Sigmoid이 원점중심이 아닌 것을 보완하기 위해 나온 함수가 바로
2.5.2.2
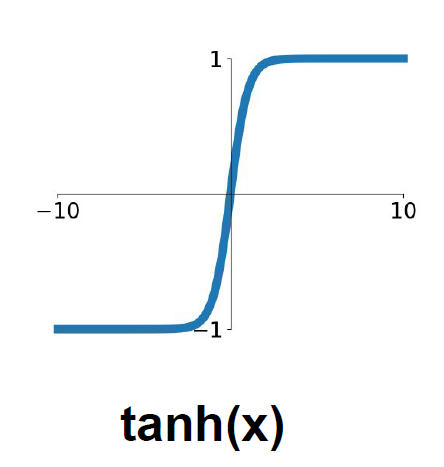
- 여전히 saturated한 뉴런일 때, gradient값이 0으로 된다.
- 그래서 새로운 활성함수가 필요 ReLU
2.5.2.3 ReLU
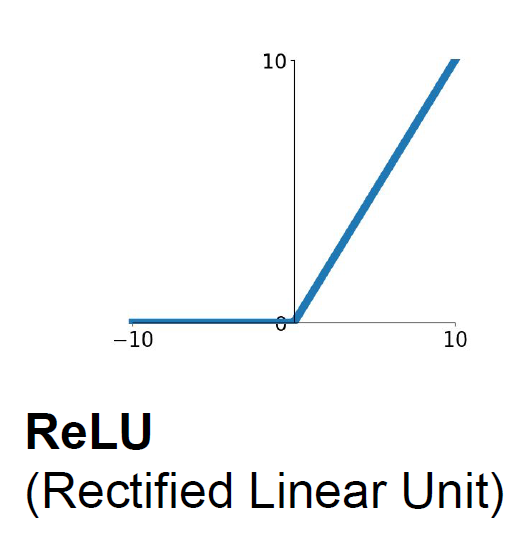
- 특징
- (+) 영역에서 saturate하지 않고,- 계산 속도도 element-wise 연산이기 때문에 sigmoid/tanh보다 훨씬 빠르다
- 단점
- (-)의 값은 0으로 만들어 버리기 때문에 Data의 절반만 activate하게 만든다는 것
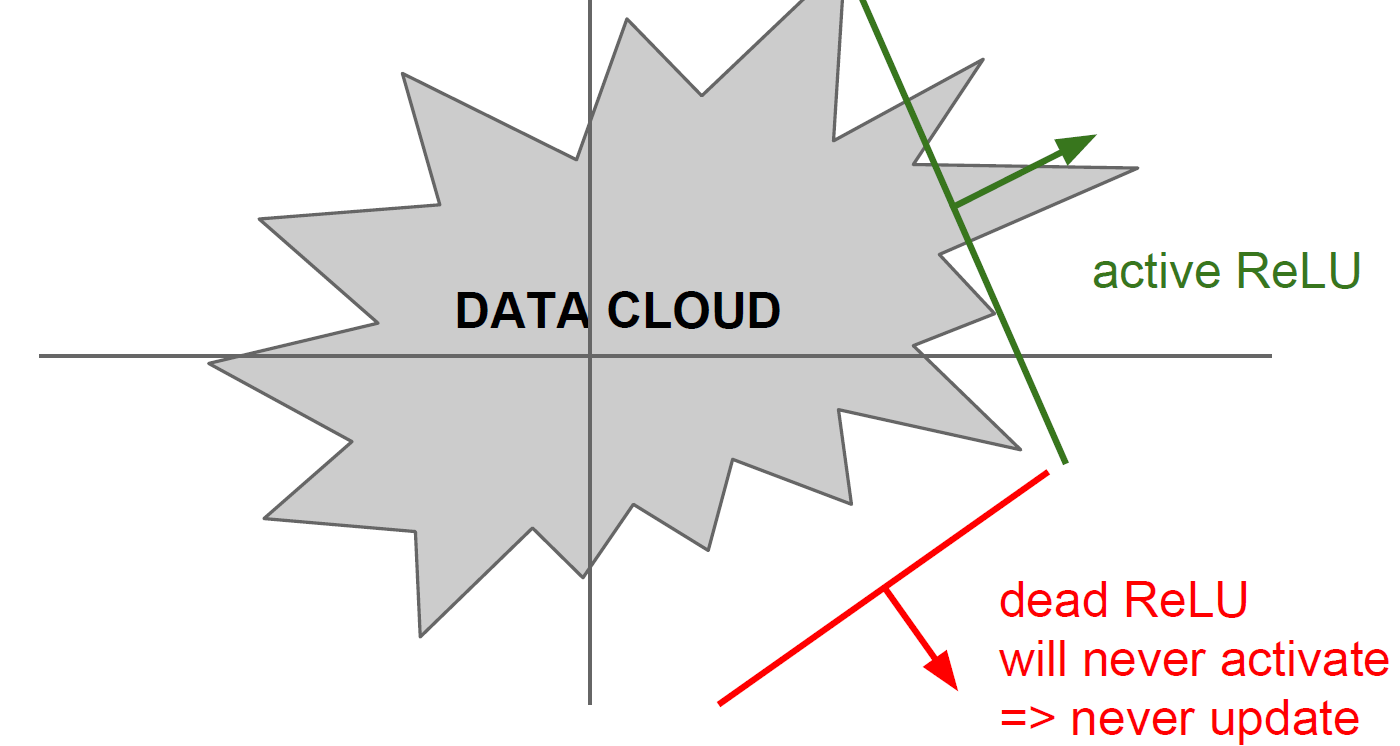
- 이 단점을 보완하기 위해 Leaky ReLU와 Exponential Linear Unit 과 Maxout
2.5.2.4 Leaky ReLU
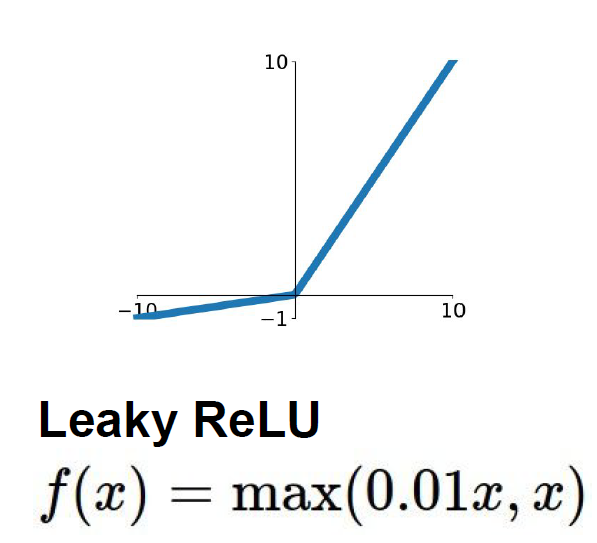
2.5.2.5 Exponential Linear Unit
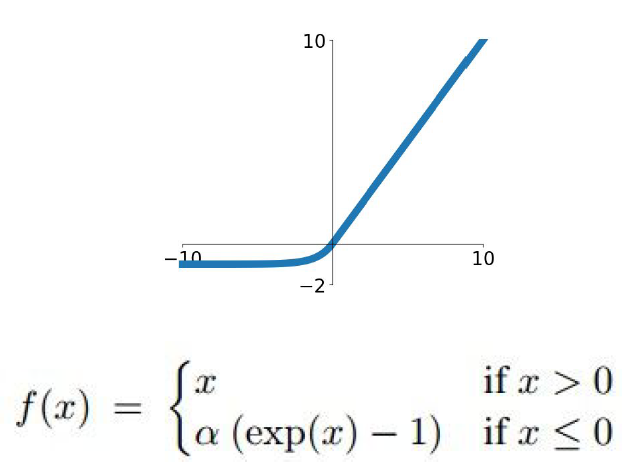
2.5.2.6 Maxout
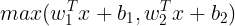
- 이 함수를 사용하려면 parameter가 기존 function보다 2배 있어야 한다
2.5.3 Data processing
- 데이터 전처리 과정에서는 주로 Zero-centered, Normalized, PCA, Whitening같은 처리들을 한다.
- Zero-centered 나 Normalized를 하는 이유는 모든 차원이 동일한 범위에 있어 전부 동등한 기여를 할 수 있도록 하는 것
- PCA나 Whitening은 더 낮은 차원으로 projection하는 느낌인데 이미지 처리에서는 이런 전처리 과정은 거치지 않는다.
- 기본적으로 이미지는 Zero-Centered 과정만 거침
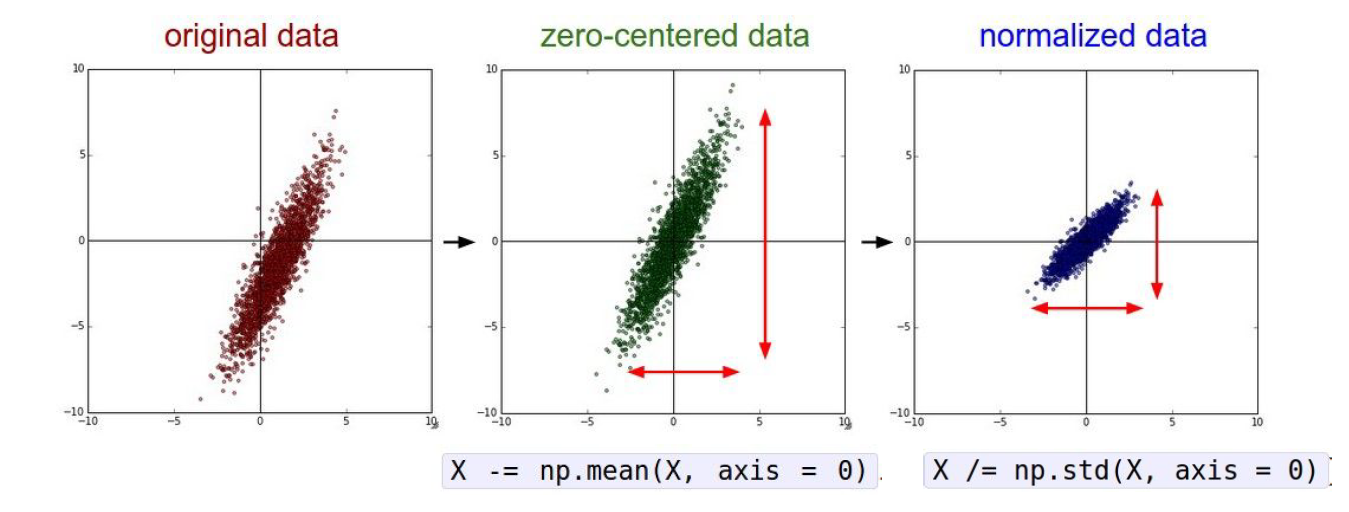
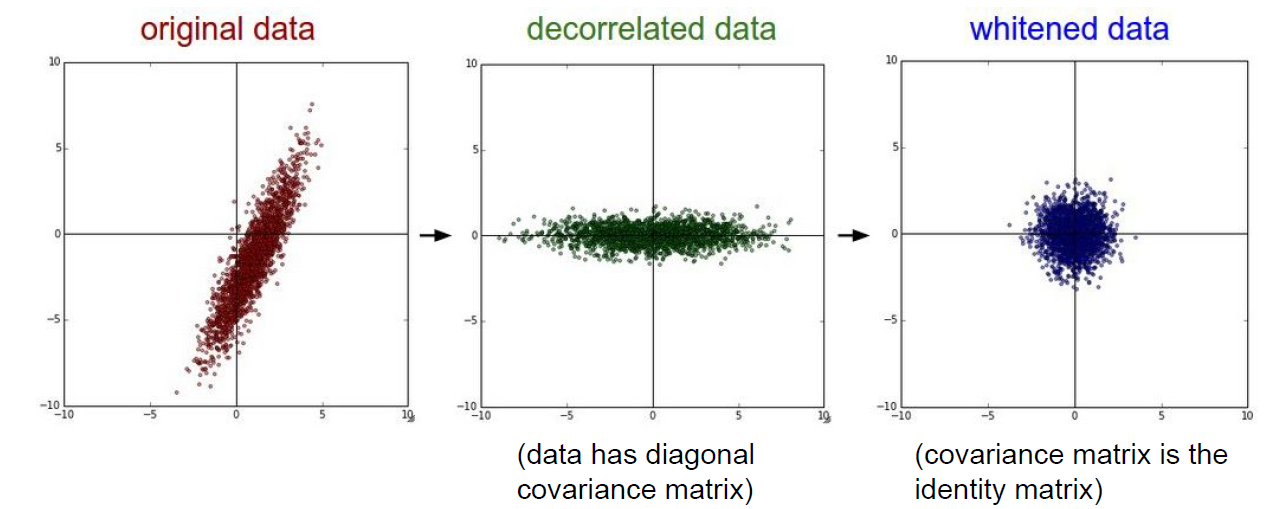
- 실제 모델에서는 train data에서 계산한 평균을 test data에도 동일하게 적용
2.5.4 Weight Initialization
- 초기값을 몇으로 잡아야 최적의 모델을 구할 수 있을까?
- 만약 초기값을 0으로 한다면, 모든 뉴런은 동일한 일을 하게 될 것이다. 즉 모든 gradient의 값이 같게 될 것이다. 이렇게 하는 것은 의미가 없다.
- 그래서 생각한 첫번째 Idea는 ‘작은 random한 수로 초기화’를 하는 것이다.
- 초기 Weight는 표준정규분포에서 Sampling을 한다.
- 하지만 이런 경우 얕은 network에서는 잘 작동을 하지만 network가 깊어질 경우 문제가 생긴다.
- 왜냐하면 network가 깊으면 깊을수록, weight의 값이 너무 작아 0으로 수렴하기 때문이다.
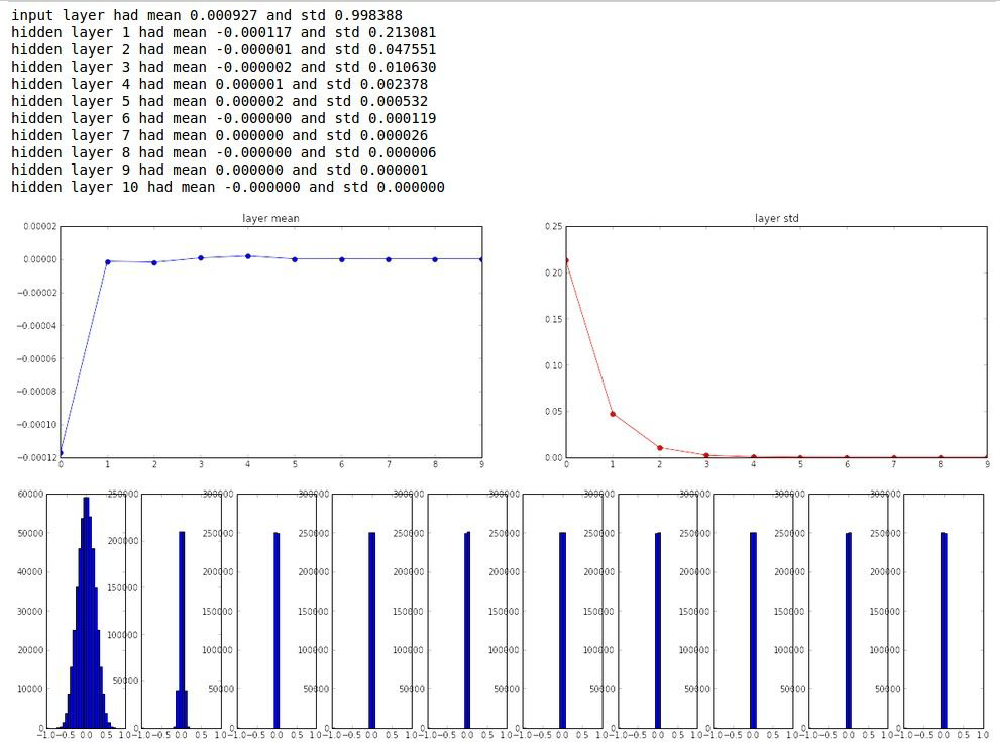
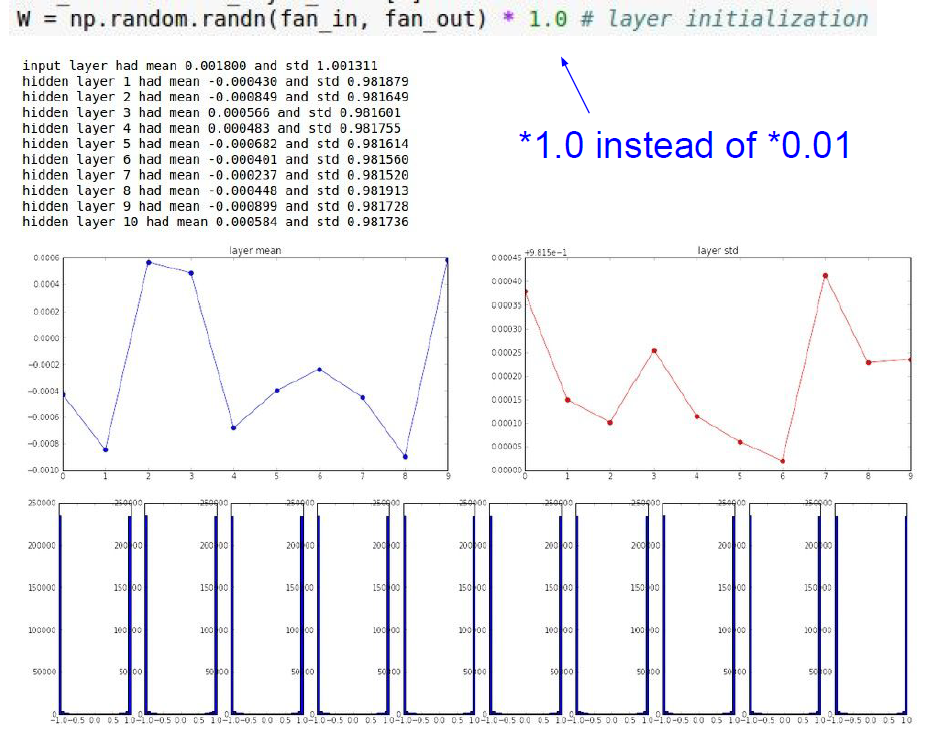
- 만약 표준 편차를 키우면 어떻게 될까?
- activaton value의 값이 극단적인 값을 가지게 되고, gradient의 값이 모두 0으로 수렴할 것
- 이런 초기값 문제에 대해서 ‘Xavier initialization’이라는 논문이 제시 되었는데 일단 activation function이 linear하다는 가정하에 다음과 같은 식을 사용하여 weight의 값을 초기화

- 이 식을 이용하면 입/출력의 분산을 맞출 수 있음
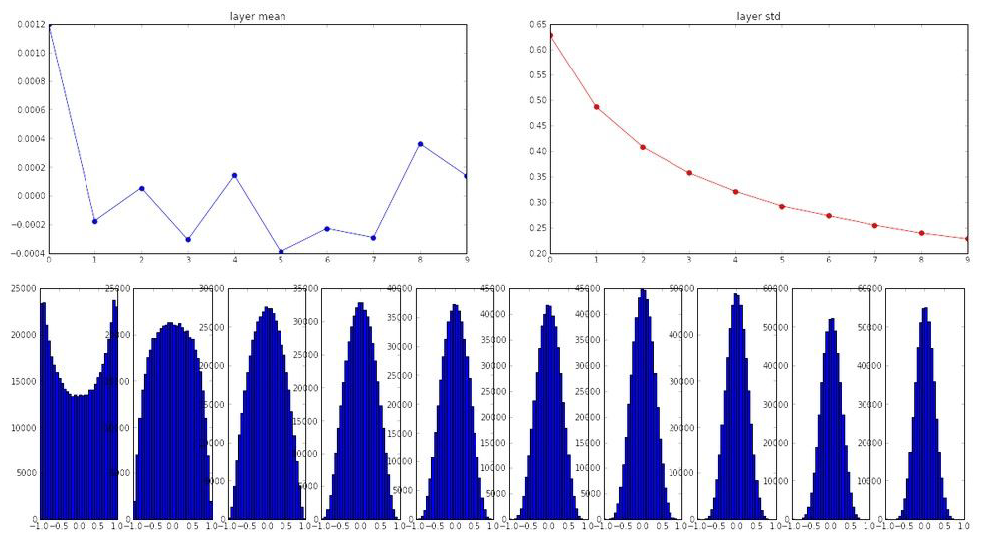
- 하지만 activation function을 ReLU로 정한 경우, 출력의 분산이 반토막 나기 때문에 이 식이 성립하지 않음
- 보통 activation function이 ReLU인 경우에는 He Initialization을 사용
2.5.5 Batch Normalization
-
만약 unit gaussian activation을 원하면 그렇게 직접 만들어보자!
-
현재 Batch에서 계산한 mean과 variance를 이용하여 정규화를 해주는 과정을 Model에 추가해주는 것이다.
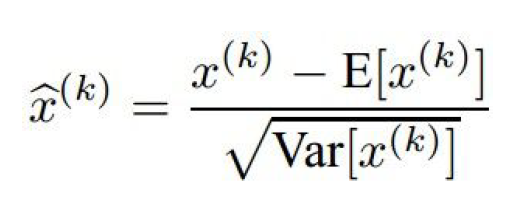
-
각 layer에서 Weight가 지속적으로 곱해져서 생기는 Bad Scaling의 효과를 상쇄시킬 수 있다.
-
하지만 unit gaussian으로 바꿔주는 것이 무조건 좋은 것 인가? 이에 유연성을 붙여주기 위해 분산과 평균을 이용해 Normalized를 좀 더 유연하게 할 수 있게 했다.
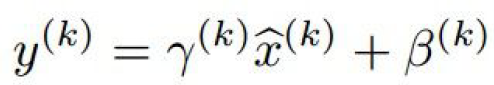
- 논문에 나와있는 Batch Normalization의 알고리즘은 다음과 같다.

-
Batch Normalization의 특징을 살펴보면
- Regularization의 역할도 할 수 있다. (Overfitting을 방지할 수 있다.) - weight의 초기화 의존성에 대한 문제도 줄였다. - Test할 땐 미니배치의 평균과 표준편차를 구할 수 없으니 Training하면서 구한 평균의 이동평균을 이용해 고정된 Mean과 Std를 사용한다. - 학습 속도를 개선할 수 있다.
2.5.6 학습 과정을 설계하는 법
-
첫번째로 고려야 할 사항은 데이터 전처리 과정이다.
-
두번째로는 어떤 architecture를 선택해야 하는 것인지 골라야 한다.
-
그렇다면 이제 가중치가 작은 값일 때 loss값이 어떻게 분포하는지 살펴봐야 한다.
-
우선 training data를 적게 잡고 loss의 값이 제대로 떨어지는지 한번 살펴보자.
-
여러 Hyperparameter들이 있는데 그 중 가장 먼저 고려야 해야하는 것은 Learning rate이다.
-
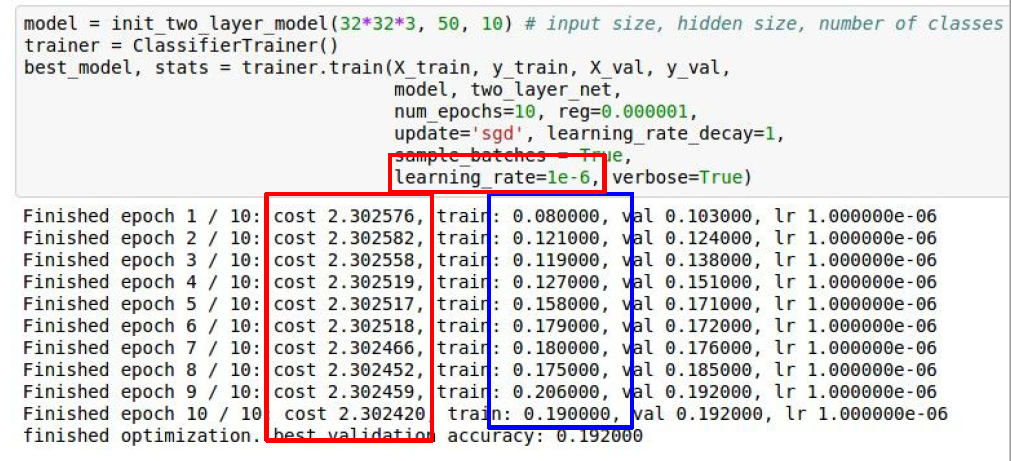
training 과정에서 cost가 줄어들지 않으면 Learning rate가 너무 작은지 의심을 한번 해보자.
-
단, activation function이 softmax인 경우 가중치는 서서히 변하지만 accurancy값은 갑자기 증가할 수 있는데 이것은 옳은 방향으로 학습을 하고 있다는 것을 의미한다.
-
cost값이 너무 커서 발산한다면, Learning rate가 너무 큰지 의심을 한번 해보고 계속해서 값을 조정해야 한다.
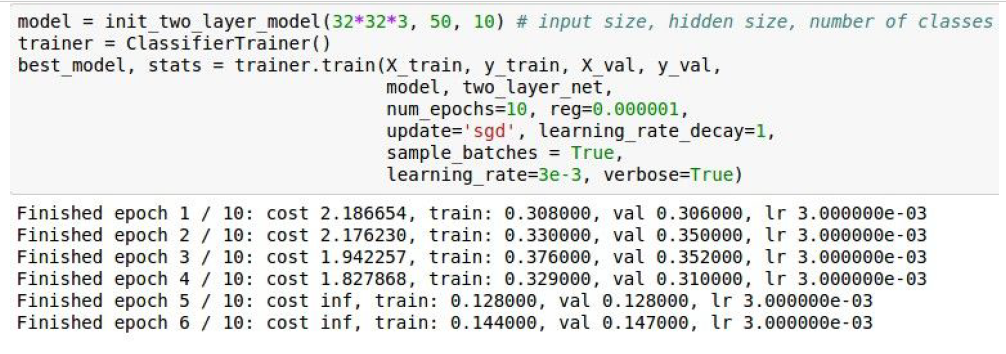
2.5.7 Hyperparameter Optimization
-
딥러닝 모델을 만들 때, 고려해야 할 Hyperparameter들이 정말 많다.
-
보통 training set으로 학습을 시키고 validation set으로 평가를 한다.
-
만약 Hyperparameter를 바꿨는데 update된 cost의 값이 원래 cost의 값보다 3배 이상 빠르게 증가할 경우 다른 parameter를 한 번 써보자.
-
Hyperparameter의 값을 여러 시행착오를 거쳐서 정하는 것도 하나의 방법이지만, 시간이 없다면 이러한 방법으로 hyperparameter를 찾는 것이 한계가 있다.
-
따라서 Grid Search vs Random Serach 두가지 방법이 제시되었다.
- Grid Search는 탐색의 대상이 되는 특정 구간 내의 후보 hyperparameter 값들을 일정한 간격을 두고 선정하여, 이들 각각에 대하여 측정한 성능 결과를 기록한 뒤, 가장 높은 성능을 발휘했던 hyperparameter 값을 선정하는 방법이다. - 반면 Random Search는 Grid Search와 큰 맥락은 유사하나, 탐색 대상 구간 내의 후보 hyperparameter 값들을 랜덤 샘플링(sampling)을 통해 선정한다는 점이 다르다. Random Search는 Grid Search에 비해 불필요한 반복 수행 횟수를 대폭 줄이면서, 동시에 정해진 간격(grid) 사이에 위치한 값들에 대해서도 확률적으로 탐색이 가능하므로, 최적 hyperparameter 값을 더 빨리 찾을 수 있는 것으로 알려져 있다.
따라서 실제로는 random search가 더 좋은 방법이라고 알려져 있다.
-
실제로 Hyperparameter Optimization는 다음과 같은 과정으로 일어난다.
1. Hyperparameter 값을 설정한다. 2. 1에서 정한 범위 내에서 파라미터 값을 무작위로 추출한다. 3. 검증 데이터(Validation Set)을 이용하여 평가한다. 4. 특정 횟수를 반복하여 그 정확도를 보고 Hyperparameter 범위를 좁힌다. -
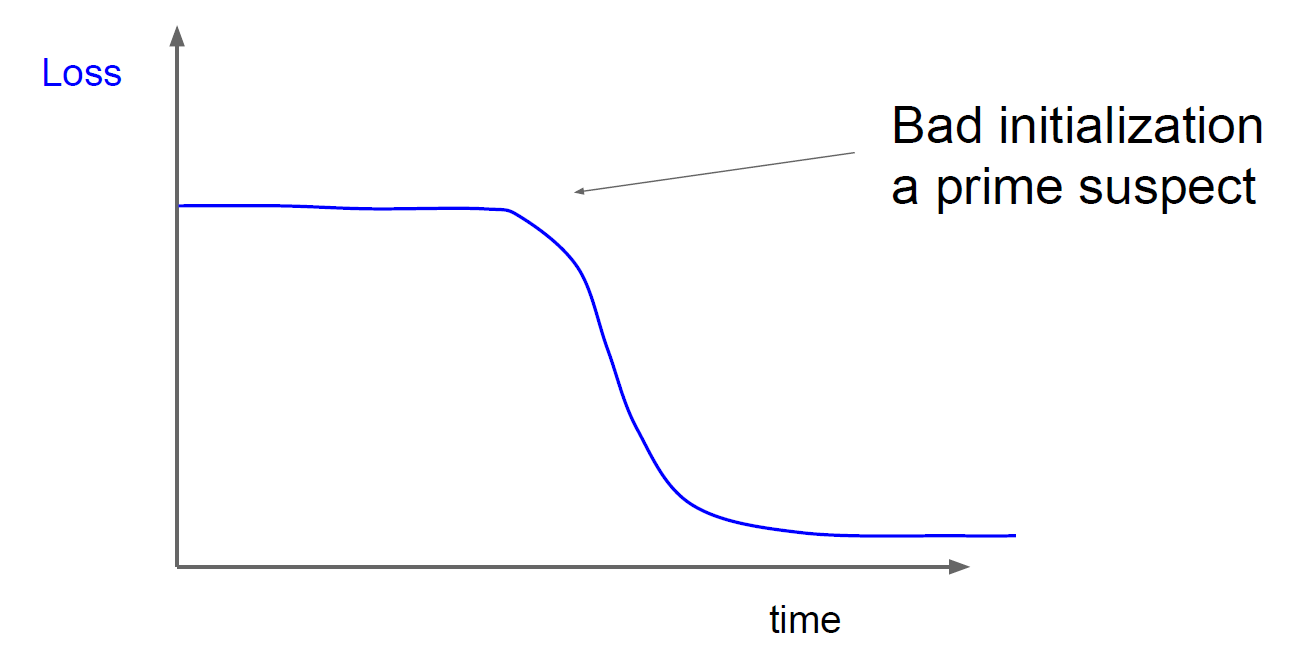
Hyperparameter를 정할 때 loss curve를 보고 이 hyperparameter가 적합한지 아닌지 평가를 하는 경우가 많다.
-
만약 loss curve가 초기에 평평하다면 초기화가 잘못될 가능성이 클 것이다.
-
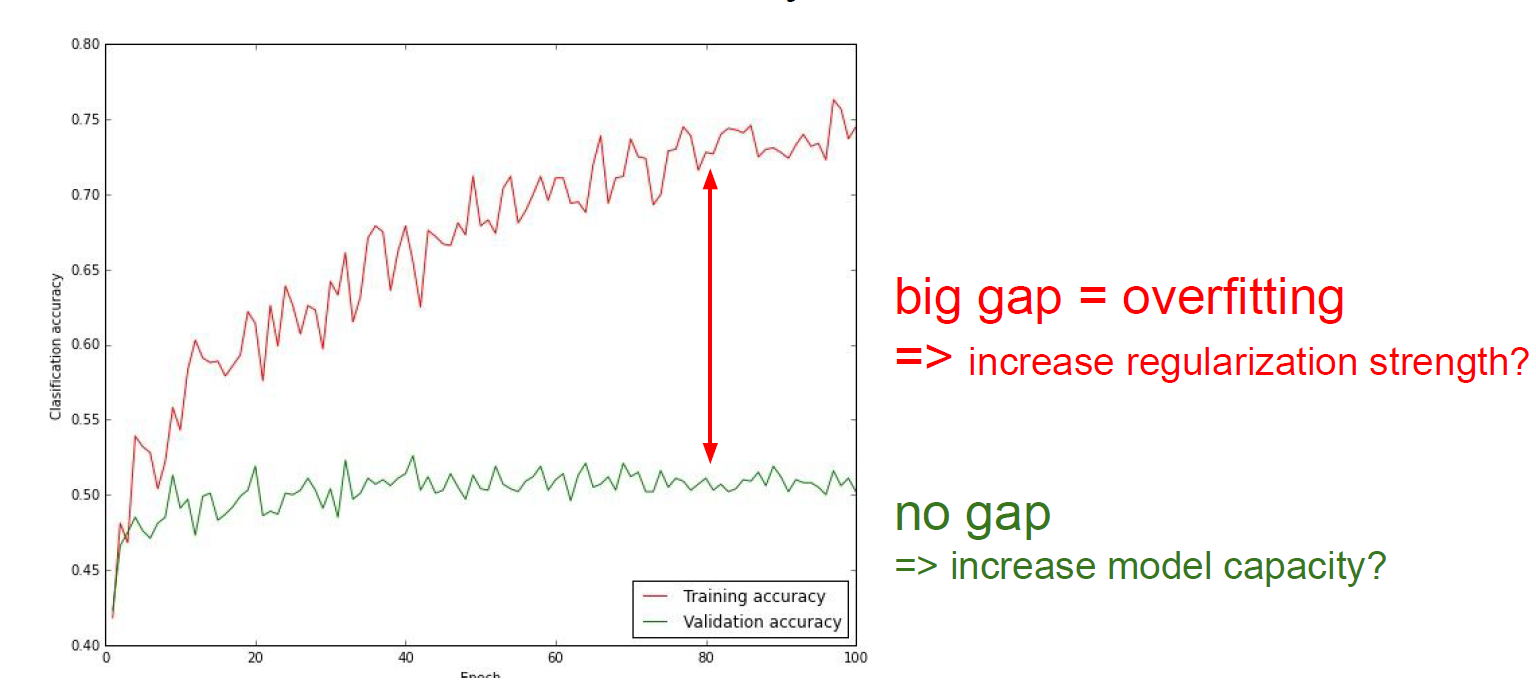
그리고 training accuracy와 validation accuracy가 gap이 클 경우 overfitting이 된 가능성이 매우 높은 것이다.
-
그 gap이 없을 경우 model capacity를 늘리는 것을 고려해봐야 한다. 즉, training한 dataset이 너무 작은 경우일 수도 있다.
2.5.8 Optimization의 여러가지 기법들
- 다양한 Optimization Algorithm 소개Permalink
지금까지 배운 최적화 기법은 SGD Algorithm이 있다.
간단하게 SGD Algorithm에 대해 설명해보면,
Mini batch 안에 있는 data의 loss를 계산
Gradient의 반대 방향을 이용하여 update를 한다.
1번과 2번 과정을 계속해서 반복한다.
하지만 SGD Algorithm에는 문제점이 존재하는데,
- Loss의 방향이 한 방향으로만 빠르게 바뀌고 반대 방향으로는 느리게 바뀐다면 어떻게 될 것인가?
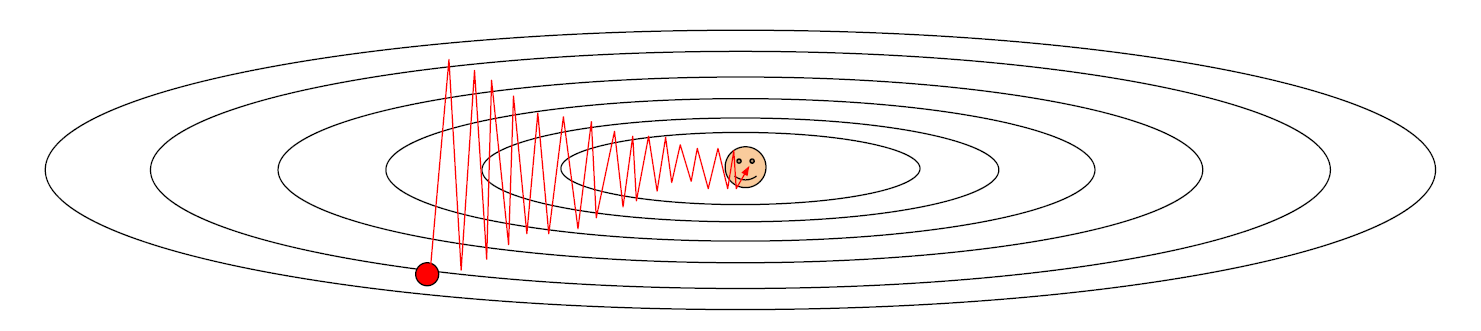
이렇게 불균형한 방향이 존재한다면 SGD는 잘 동작하지 않는다.
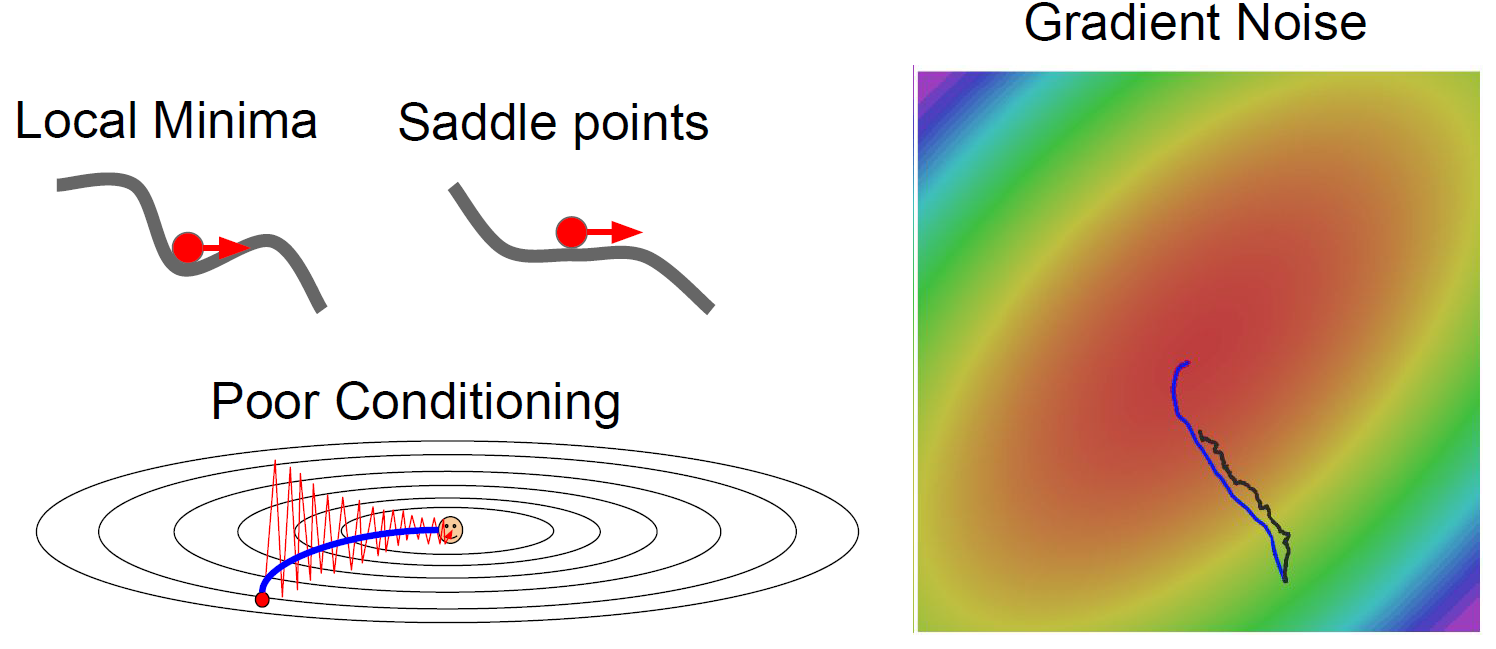
- Local minima나 saddle point의 빠지면 어떻게 될 것인가?

최솟값이 더 있는데 local minima에 빠져서 나오지 못하거나,
기울기가 완만한 구간에서 update가 잘 이루어지지 않을 수 있다.
- Minibatches에서 gradient의 값이 노이즈 값에 의해 많이 변할 수 있다.
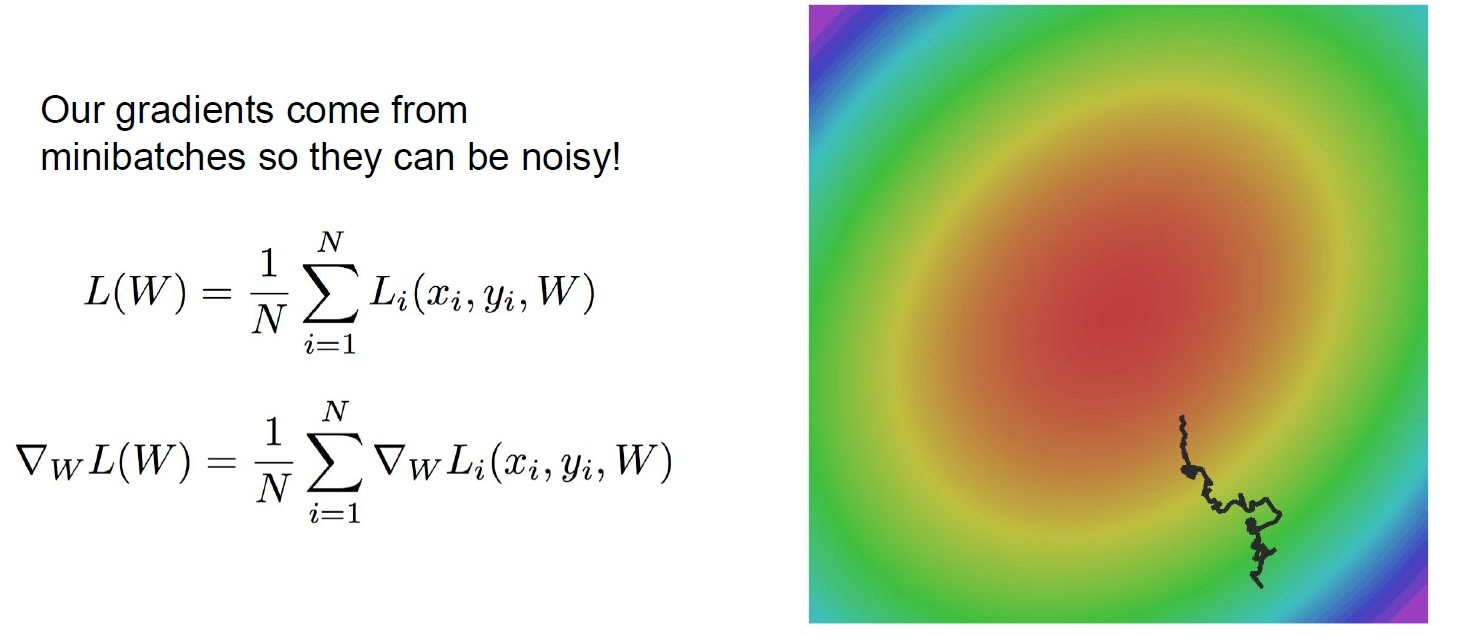
그림처럼 꼬불꼬불한 형태로 gradient 값이 update 될 수 있다.
위와 같은 문제점들을 해결하기 위해서 Momentum이라는 개념을 도입한다.
Momentum이란 자기가 가고자 하는 방향의 속도를 유지하면서 gradient update를 진행하는 것을 말한다.
- momentum을 추가하는데 기존에 있는 momentum과는 다르게 순서를 바꾸어 update를 시켜주는 방법도 있는데 Nesterov Momentum이라고 한다.
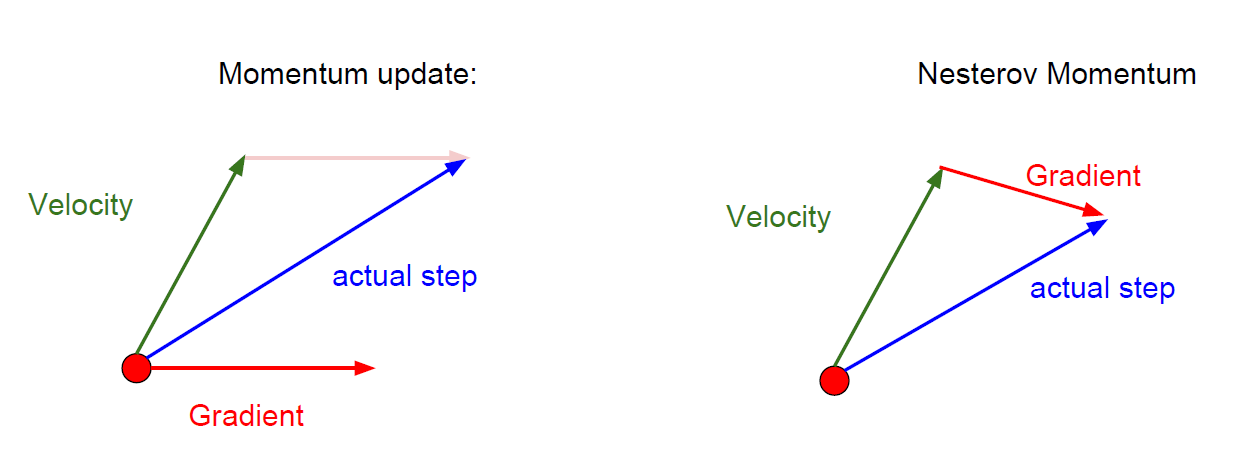

- 식의 의미를 잘 이해하진 못했지만,
강의에서는 현재 / 이전의 velocity 간의 에러 보정이 추가되었다고 설명했다.
기존의 SGD, SGD+Momentum, Nesterov의 결과값을 한 번 비교해보면,
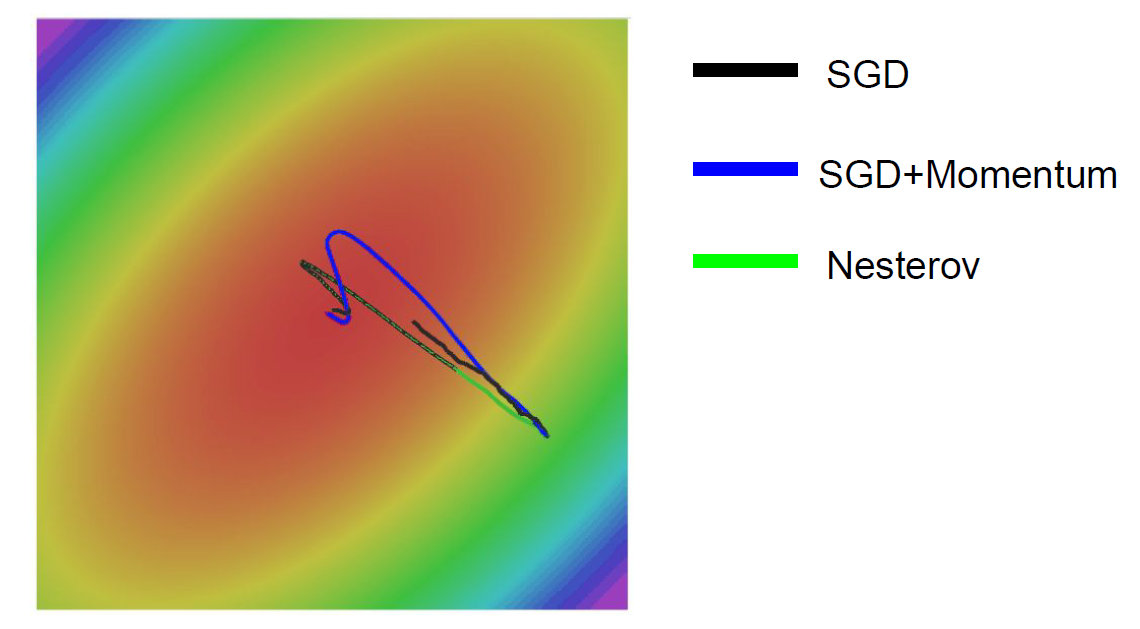
좀 더 Robust하게 algorithm이 작동하는 것을 볼 수 있다.
Velocity term 대신에 grad squared term을 이용하여
gradient를 update하는 방법도 제안되었는데,
이 방법은 AdaGrad라고 부른다.
AdaGrad는 학습률을 효과적으로 정하기 위해 제안된 방법이다.
grad squared term를 추가하게 되면, 각각의 매개변수에 맞춤형으로 값을 정해줄 수 있다.
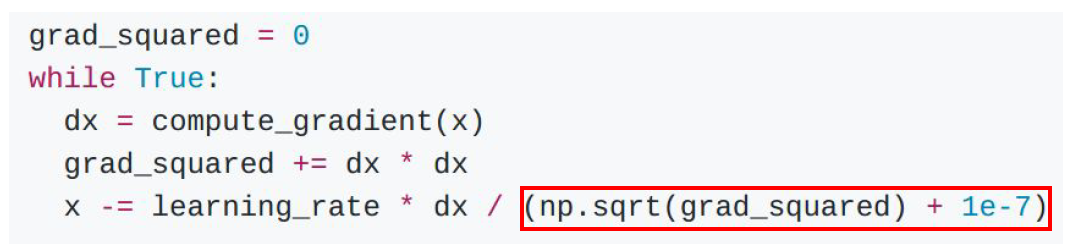
이러한 방식으로 update를 계속 진행하게 되면,
small dimension에서는 가속도가 늘어나고,
large dimension에서는 가속도가 줄어드는 것을 볼 수 있다.
그리고 시간이 지나면 지날수록 step size는 점점 더 줄어든다.
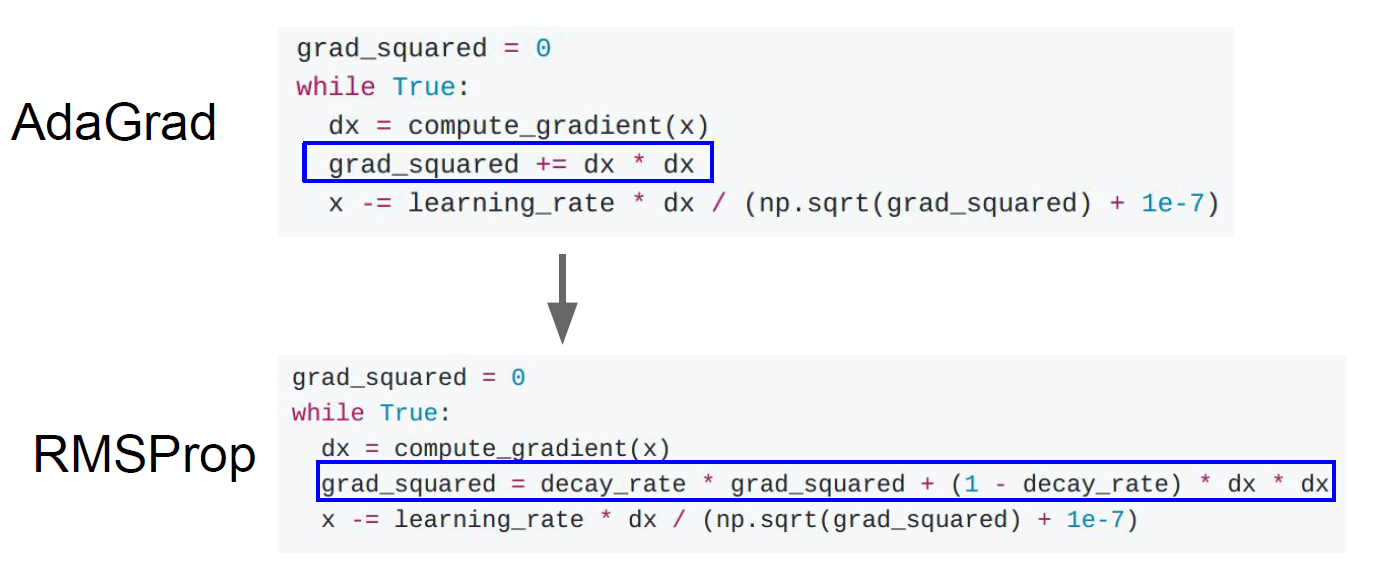
이 방법에서 또 하나가 추가가 되어 decay_rate라는 변수를 통해서
step의 속도 가 / 감속을 할 수 있는 방법이 제안되었는데,
이 방법을 RMSProp이라고 한다.
RMSProp는 AdaGrad의 단점을 보완한 방법이다.
과거의 모든 기울기를 균일하게 반영해주는 AdaGrad와 달리,
RMSProp은 새로운 기울기 정보에 대하여 더 크게 반영하여 update를 진행한다.
정말 수많은 알고리즘들이 제안되었는데,
이제 대중적으로 널리 쓰이고 있는 Adam에 대해서 알아보자.
Adam은 쉽게 생각하면 momentum + adaGrad 라고 생각하면 된다.

초기화를 잘 해주어야 하기 때문에, bias correction을 추가하여
초기화가 잘 되도록 설계해 주었다.
앞선 알고리즘과 한번 비교를 해보면,
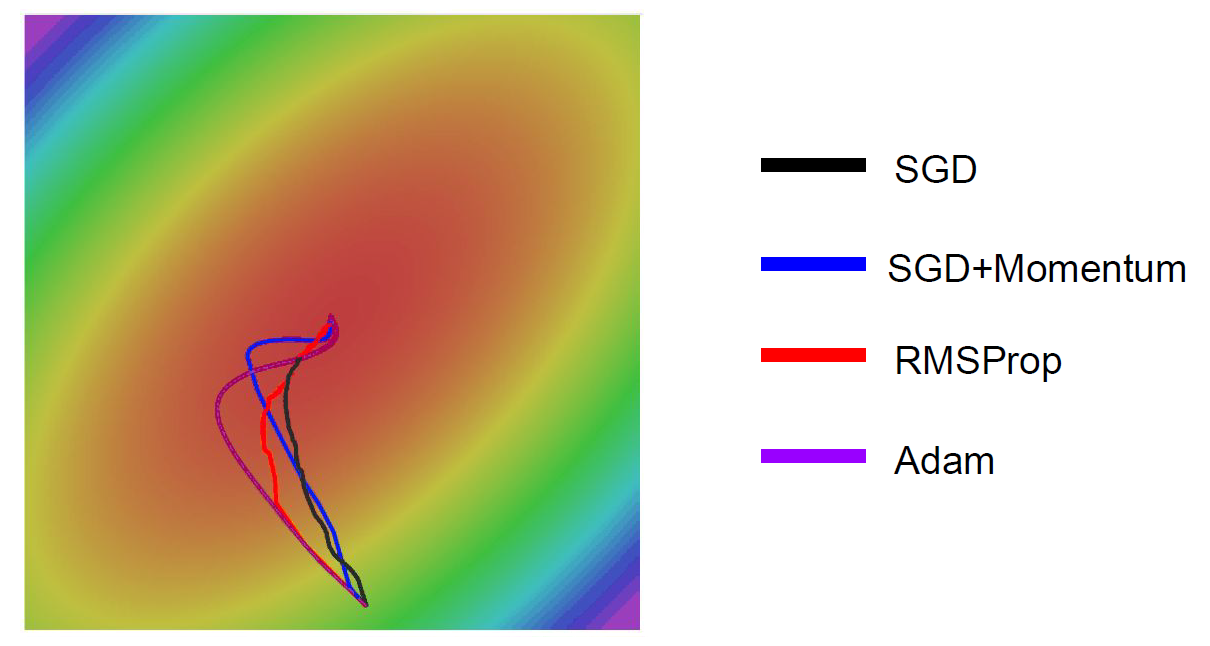
-Adam이 제일 대중적으로 쓰인다고 했는데
여기 보여준 예제에서는 좀 멀~리 돌아서 update가 된 것 같긴하다.
최적화 기법은 상황에 따라 최적의 최적화 기법이 모두 다르다!
지금까지 보여준 최적화 알고리즘은
모두 Learning rate를 hyperparameter로 가지고 있다.
Learning rate decay도 있지만
처음에는 없다고 생각하고 딥러닝 모델을 설계한 다음,
나중에 고려해주도록 하자.
First-Order & Second-Order OptimizationPermalink
일차 함수로 근사화를 시켜 최적화를 시킬 때는 멀리 갈 수 없다는 단점이 있다.
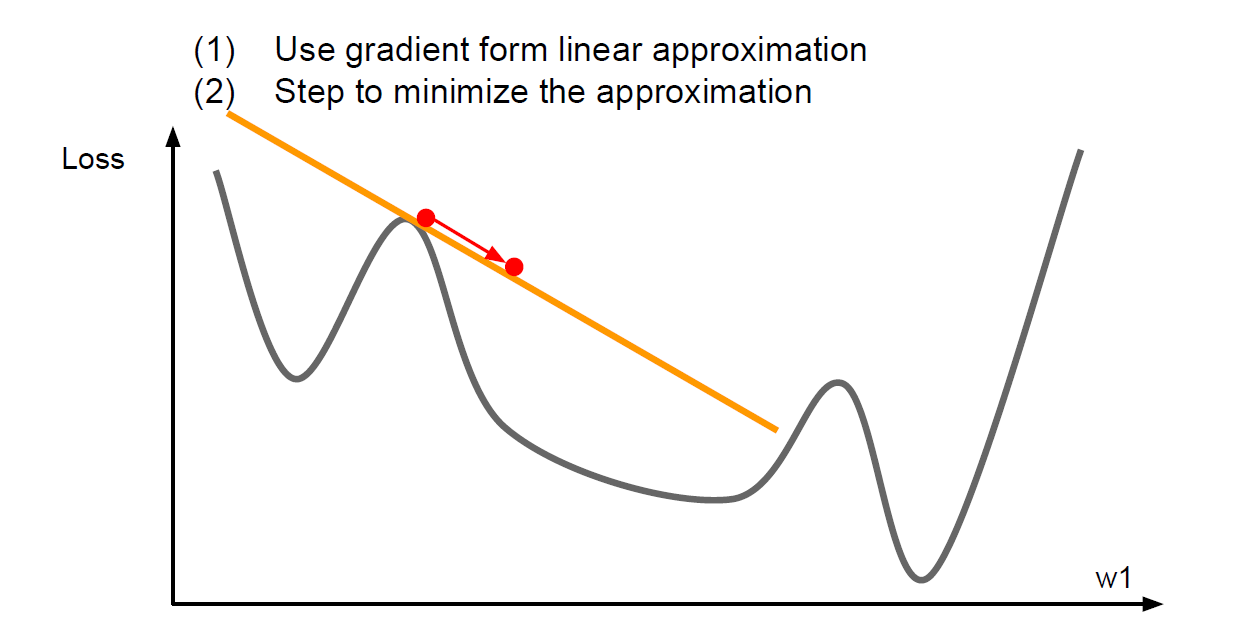
이차 함수로 근사화를 시킬때는 주로 테일러 급수를 이용해서 근사화를 시킨다.
이러한 방법으로 update를 시키면 기본적으로 learning rate를 설정해 주지 않아도 된다는 장점이 있다. (No Hyperparameters!)
하지만 복잡도가 너무 크다는 단점이 있다.
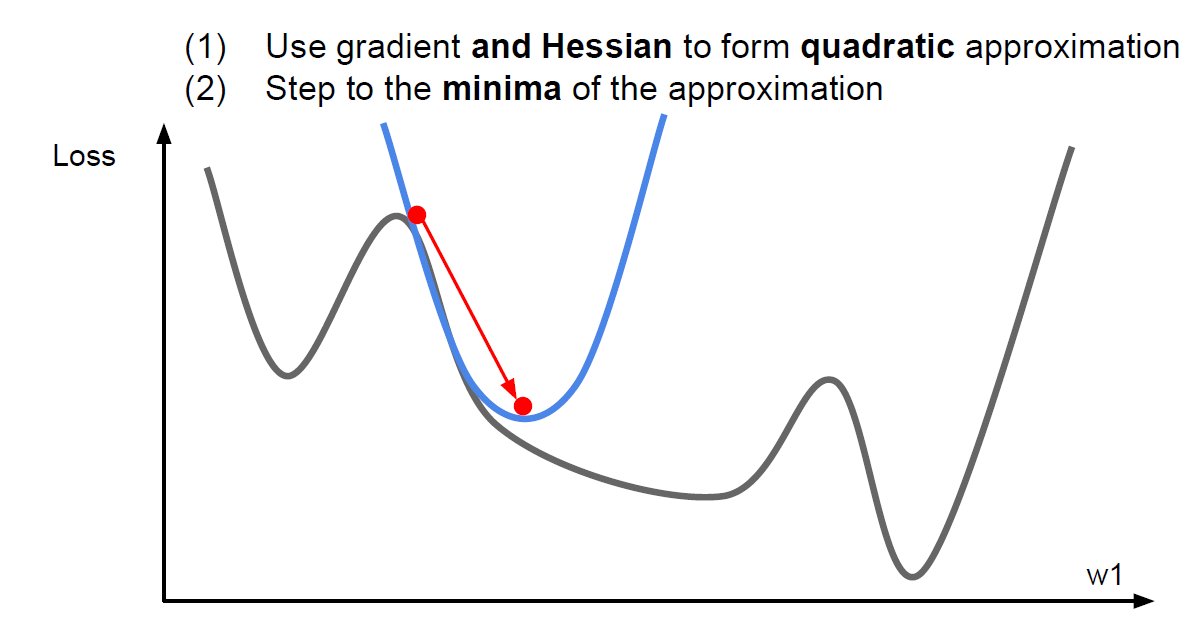
이차 함수로 근사화 시키는 일은 Quasi-Newton 방법으로
non-linear한 최적화 방법 중에 하나이다.
Newton methods보다 계산량이 적어 많이 쓰이고 있는 방법이다.
그 중 가장 많이 쓰는 알고리즘은 BGFS와 L-BGFS이다.
이러한 알고리즘들은 full-batch일 때는 좋은 성능을 보이기 때문에,
Stochastic(확률론적) setting이 적을 경우 사용해 볼 수 있다.
지금까지 배운 방법들은 모두
Training 과정에서 error를 줄이기 위해 사용하는 방법들이다.
그렇다면 한 번도 보지 못한 데이터에서 성능을 올리기 위해서는 어떻게 해야할까?
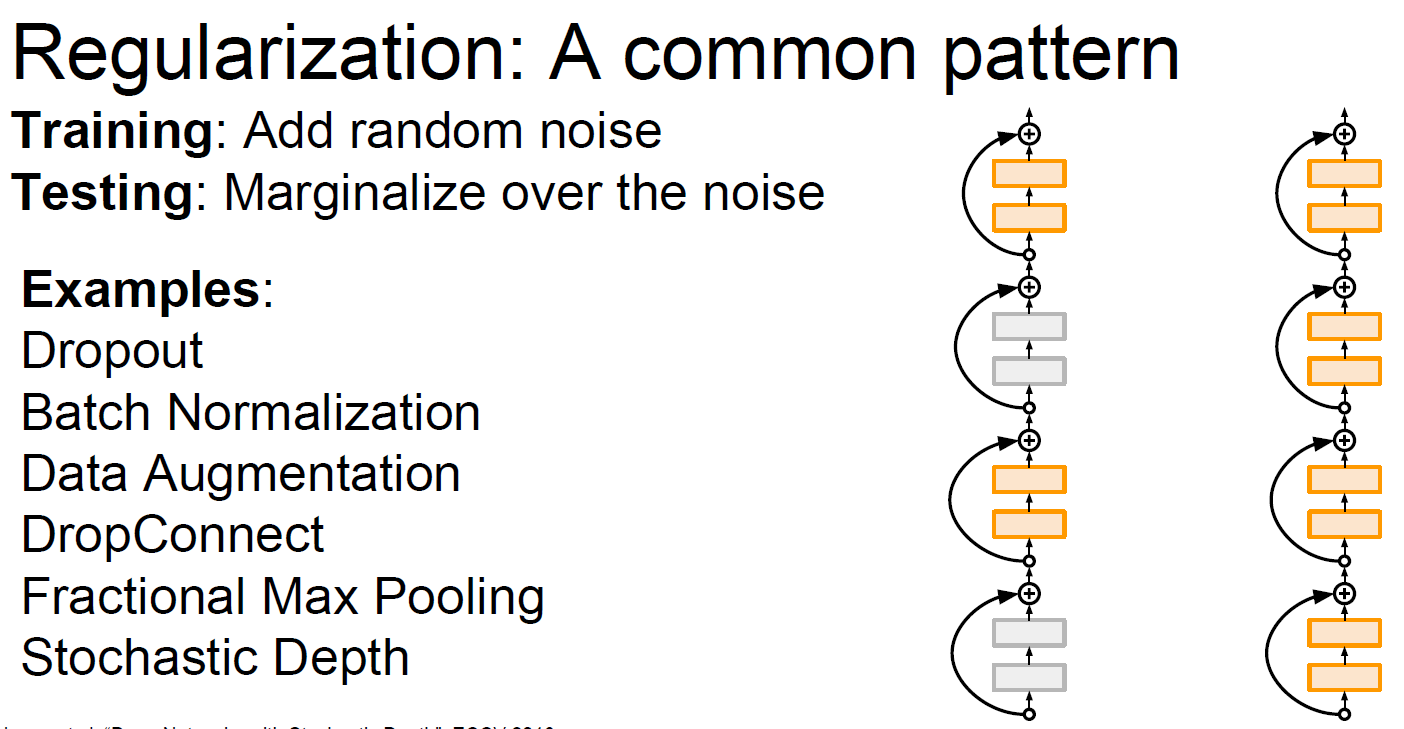
2.5.9 Regularization
Regularization 기법을 설명하기 전에, Model Ensembles에 대해서 한 번 정리하자.
Model Ensembles은 간단히 말하면 다양한 모델로 train을 시키고,
test를 할 때 그 것들을 짬뽕(?)해서 쓰는 것을 말한다.
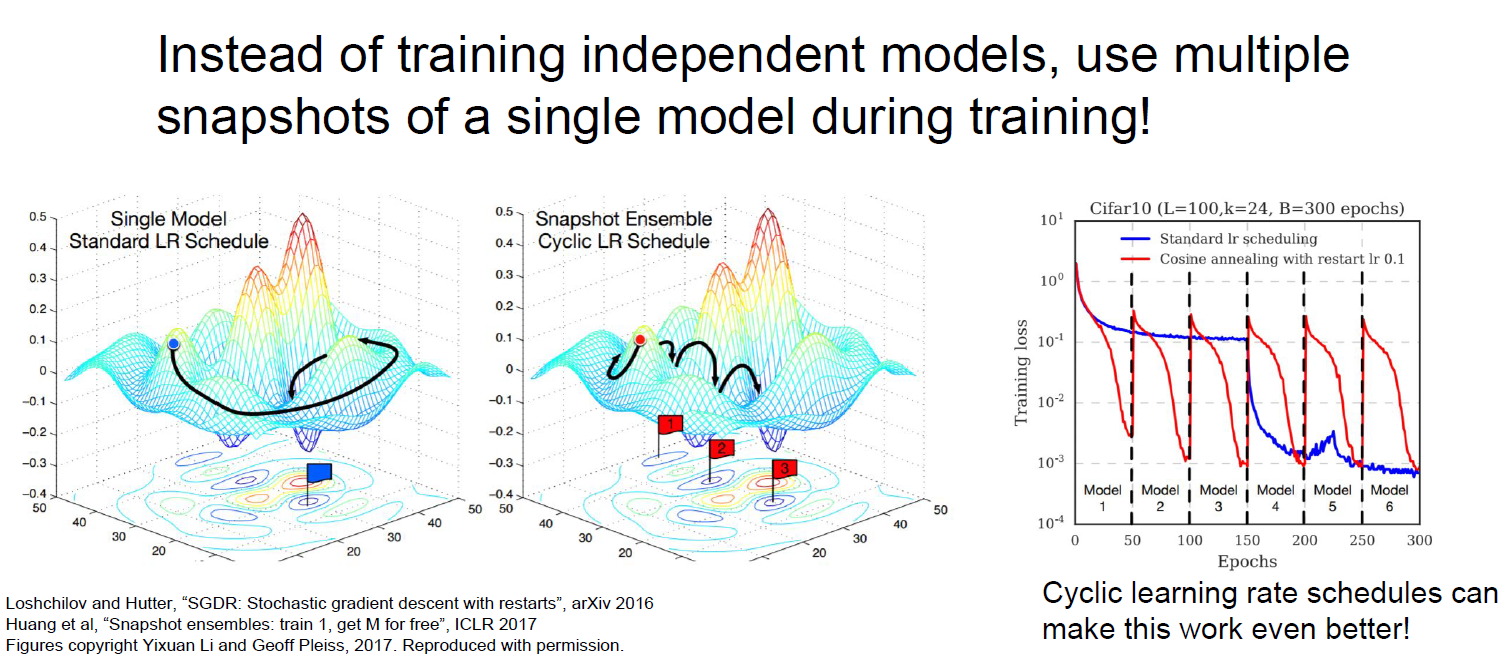
Test를 할 때, parameter vector들을 Moving average값을 사용하여
test를 하는 방법도 있다. (Polyak averaging)
지금까지의 방법들은 모두 Test를 하는데 좋은 성능을 내기 위해 모델을 좀 더 robust하게 만들기 위해서 사용하는 기법들이다.
그렇다면 single-model의 성능을 좋게 하기위해선 어떤 방법을 쓸까?
답은 Regularization이다.
Regularization은 간단히 loss function을 구현할 때,
regularization에 대한 function을 추가해주기도 한다.

또 다른 방법으로는 dropout이라는 기법도 있다.
Dropout이 효과가 있는 이유는 다양한 feature를 이용하여 예측을 하기 때문에 어떤 특정 feature에만 의존하는 경우를 방지한다.
또한 단일 모델로 앙상블 효과가 날 수 있도록 한다.
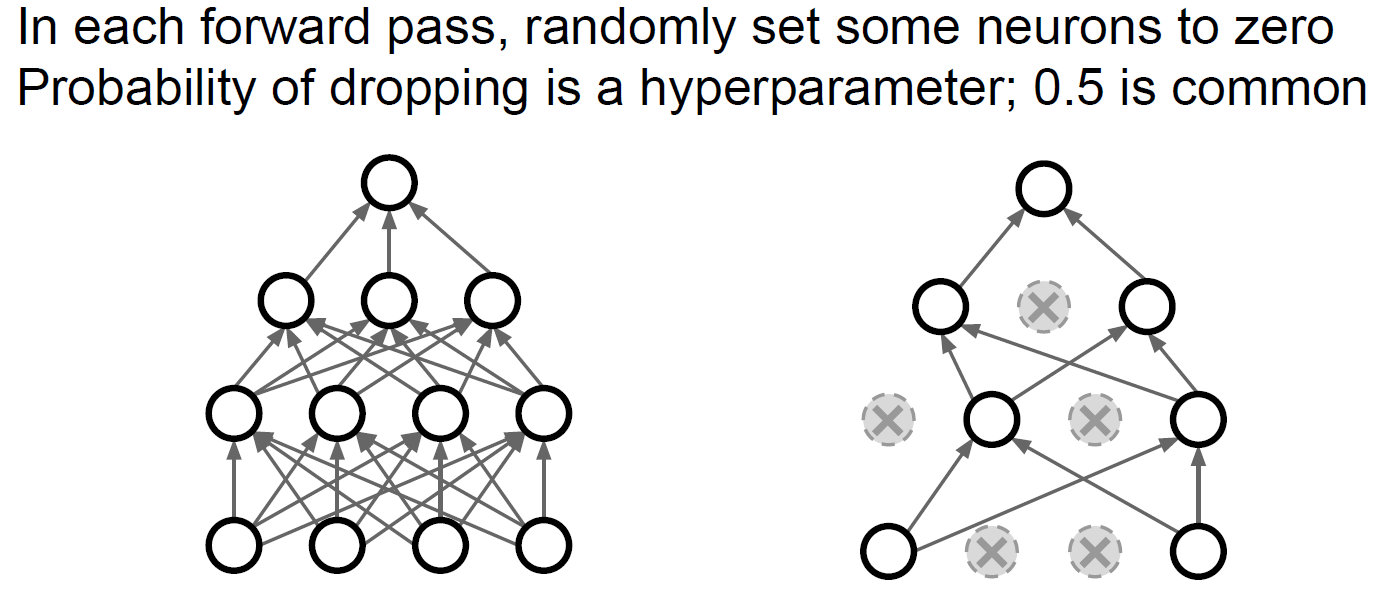
Test-time에서 임의성에 대해 평균을 내고 싶을 때..

Dropout을 하게 되면 test time도 줄어들게 할 수 있다.
또 다른 regularization 방법으로는 Data Augmentation이 있다.
Training을 시킬 때, 이미지의 patch를 random하게 잡아서 훈련을 시키거나,

이미지를 뒤집어서 train dataset에 추가해 훈련을 해주거나,
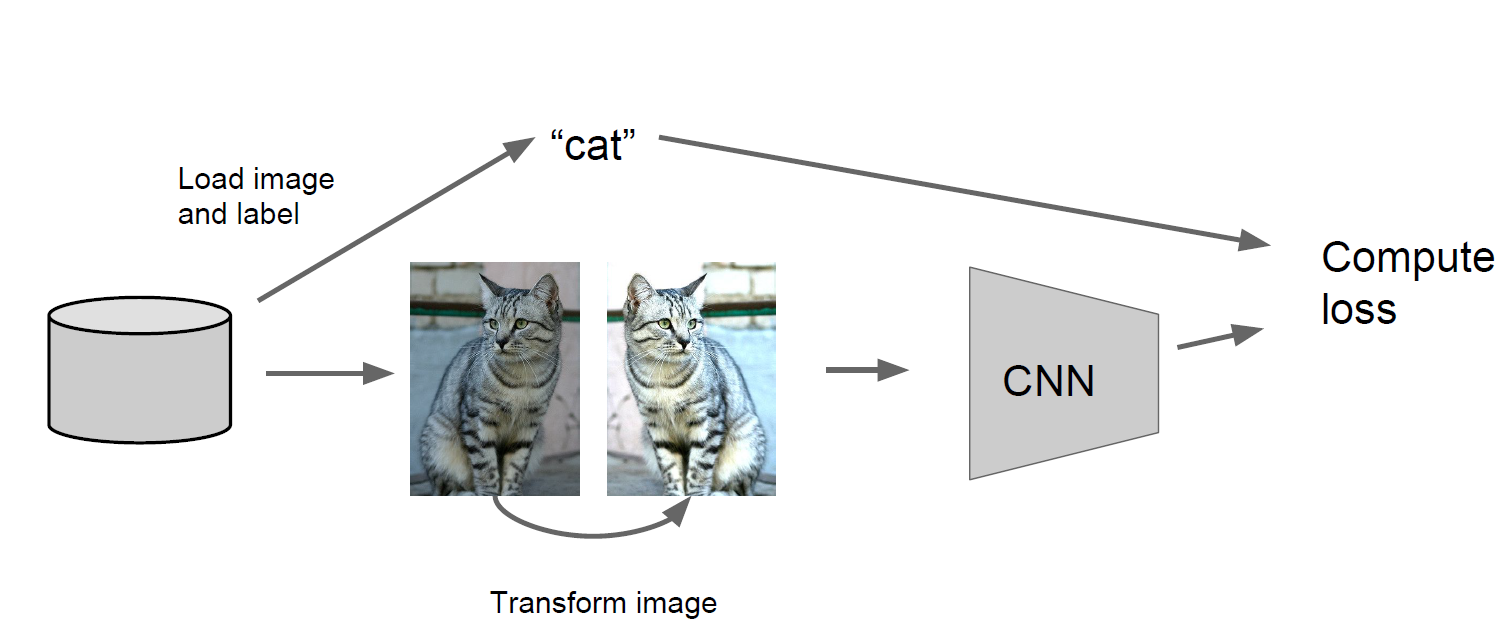
밝기값을 다르게 해서 train dataset에 추가하고 훈련을 해주는 경우도 있다.

이 외에도 다양한 regularization 방법들이 존재한다.
2.5.10 Transfer Learning
전이학습은 간단히 말하면 이미 pretrained된 모델을 이용하여 우리가 이용하는 목적에 맞게 fine tuning하는 방법을 말한다.
Small Dataset으로 다시 training 시키는 경우
보통의 learning rate보다 낮춰서 다시 training을 시킨다.
DataSet이 조금 클 경우, 좀 더 많은 layer들을 train 시킨다.
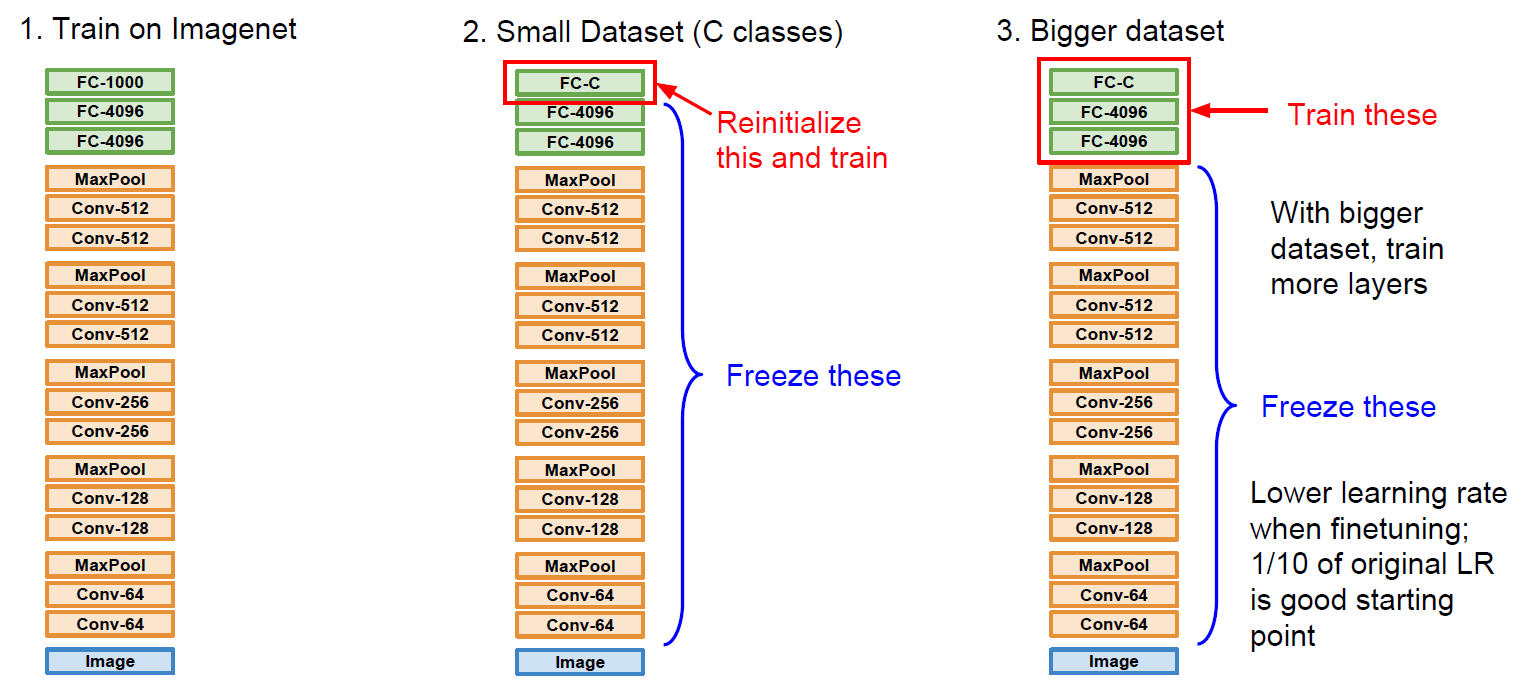
한 번 더 표로 정리해보면, 아래와 같이 나타낼 수 있다.
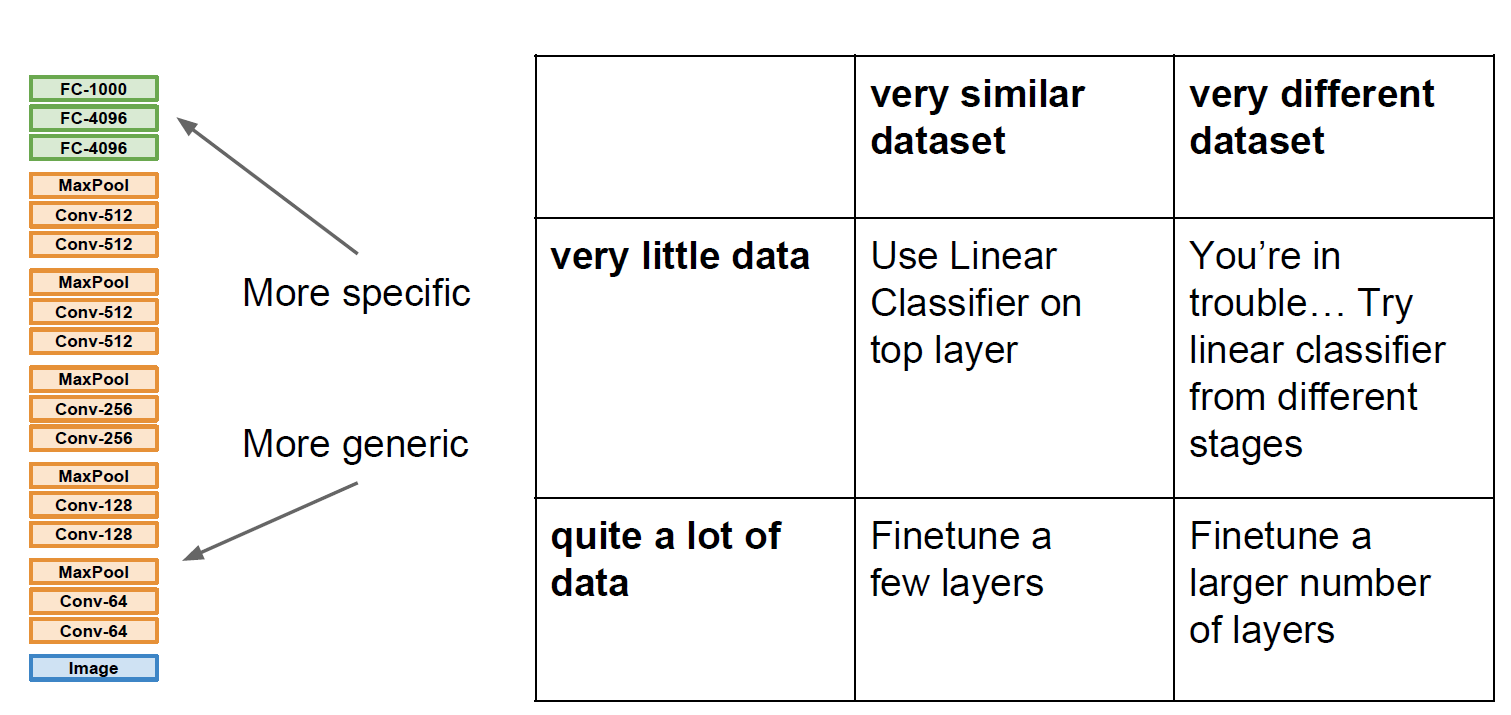
전이학습은 많이 사용하는 방법이니 꼭 알아두자!
