1일차 복습
ORM (Object-Relational Mapping)
- 관계형 데이터베이스와 객체 지향 프로그래밍 언어의 패러다임 불일치를 해결하기 위해
- ORM 프레임워크가 중간에서 객체와 관계형 데이터베이스를 맵핑
JPA (Java Persistence API, Jakarta Persistence API)
- 자바 ORM 기술 표준
Entity / Entity Mapping
- Entity : JPA를 이용해서 데이터베이스 테이블과 맵핑할 클래스
- Entity Mapping : Entity 클래스에 데이터베이스 테이블과 컬럼, 기본 키, 외래 키 등을 설정하는 것
EntityManager와 영속성 컨텍스트
- EntityManager : Entity의 저장, 수정, 삭제, 조회 등 Entity와 관련된 모든 일을 처리하는 관리자
- 영속성 컨텍스트
- Entity를 영구 저장하는 환경
- 1차 캐시 역할
연관관계 맵핑
데이터베이스 테이블 간의 관계(relationship)
데이터베이스 정규화
- 정규화는 중복 데이터로 인해 발생하는 데이터 불일치 현상을 해소하는 과정
정규화를 통해 각각의 데이터베이스 테이블들은 중복되지 않은 데이터를 가지게 됨
- 필요한 데이터를 가져오기 위해서는
- 여러 테이블들 간의 관계(relationship)를 맺어 JOIN을 이용해서 관계 테이블을 참조
연관관계(association)
- 데이터베이스 테이블 간의 관계(relationship)를 Entity 클래스의 속성(attribute)으로 모델링
- 데이터베이스 테이블은 외래 키로 JOIN을 이용해서 관계 테이블을 참조
- 객체는 참조를 사용해서 연관된 객체를 참조
외래 키 맵핑
- @JoinColumn : 외래 키 맵핑
- @JoinColumn : 복합 외래 키 맵핑
예전에는 복합 외래키를 사용하려면 클래스에 @JoinColumns 어노테이션을 설정하고 각각의 필드에 @JoinColumn을 사용하여야 했다.
지금은 각각의 필드에 @JoinColumn만 사용하면 된다.
다중성 (Multiplicity)
- @OneToOne
- @OneToMany
- @ManyToOne
- @ManyToMany
기준은 항상 자신이 기준이다.
Fetch 전략 (fetch)
- JPA가 하나의 Entity를 가져올 때 연관관계에 있는 Entity들을 어떻게 가져올 것인지에 대한 설정
Fetch 전략
- FetchType.EAGER : 즉시 로딩
- FetchType.LAZY : 지연 로딩
다중성과 기본 Fetch 전략
- *ToOne (@OneToOne, @ManyToOne):FetchType.EAGER
- *ToMany (@OneToMany, @ManyToMany):FetchType.LAZY
@ManyToMany는 존재하긴 하지만 없다고 생각하면 된다.
이유는 @ManyToMany는 중간에 존재하는 테이블을 숨기고 이어진 두 테이블을 다중성으로 연결하는 것인데 중간에 날짜 등과 같은 column이 추가되는 경우가 있어 중간 테이블을 만들고 @OneToMany와 @ManyToOne으로 묶는 것이 좋다.
toone에서 eager를 쓰는 이유는 상대 테이블에서 하나 아니면 존재하지 않기 때문에 즉시 가져와도 부담이 되지 않아서 기본 전략이 eager이다.
tomany는 상대가 몇 개인지 모르기 때문에 lazy전략을 사용한다.
관계에서 실선과 점선 차이는 실선은 식별관계 외래키를 기본키에 사용하겠다는 것이고, 점선은 비식별관계 외래키를 기본키에 사용하지 않겠다는 의미이다.
영속성 전이
- Entity의 영속성 상태 변화를 연관된 Entity에도 함께 적용
- 연관관계의 다중성(Multiplicity) 지정 시 cascade 속성으로 설정
@OneToOne(cascade = CascadeType.PERSIST)
@OneToMany(cascade = CascadeType.ALL)
@ManyToOne(cascade = { CascadeType.PERSIST, CascadeType.REMOVE })cascade 종류
public enum CascadeType {
ALL, /* PERSIST, MERGE, REMOVE, REFRESH, DETACH */
PERSIST, // cf.) EntityManager.persist()
MERGE, // cf.) EntityManager.merge()
REMOVE, // cf.) EntityManager.remove()
REFRESH, // cf.) EntityManager.refresh()
DETACH // cf.) EntityManager.detach()
}영속성 전이는 cascade를 설정하는 것이고 이 것을 설정하면 따로 persist() 메서드를 사용하여 등록을 하지 않아도 된다.
단방향 일대다 관계에서는 다른 테이블에 외래키가 있으면 연관관계 처리를 위해 추가적인 update쿼리가 갯수만큼 실행된다.
이를 해결하기 위해서는 양방향 관계로 만들어 줘야 한다.
대부분의 경우에는 단방향으로 잡아도 되지만 OneToMany일 경우에는 양방향으로 처리하는 것이 좋다.
연관관계의 방향성
- 단방향(unidirectional)
- 양방향(bidirectional)
양방향 연관 관계
- 관계의 주인(owner)
- 연관 관계의 주인은 외래 키가 있는 곳
- 연관 관계의 주인이 아닌 경우, mappedBy 속성으로 연관관계의 주인을 지정
단방향 vs 양방향
단방향 맵핑만으로 연관관계 맵핑은 이미 완료
- JPA 연관관계도 내부적으로 FK 참조를 기반으로 구현하므로 본질적으로 참조의 방향은 단방향
단방향에 비해 양방향은 복잡하고 양방향 연관관계를 맵핑하려면 객체에서 양쪽 방향을 모두 관리해야 함
- 물리적으로 존재하지 않는 연관관계를 처리하기 위해 mappedBy 속성을 통해 관계의 주인을 정해야 함
단방향을 양방향으로 만들면 반대 방향으로의 객체 그래프 탐색 가능
- 우선적으로는 단방향 맵핑을 사용하고 반대 방향으로의 객체 그래프 탐색 기능이 필요할 때 양방향을 사용
일대일(1:1) 관계
해당 테이블에 외래키가 있는 경우는 단방향을 설정할 수 있지만 대상 테이블에 외래키가 존재하는 경우 해당 Entity에서는 단방향을 지정할 수 없다 JPA에서 지원하지 않음 이런 경우에는 외래키를 해당 테이블이 소유하게 하거나 양방향을 만들어야 한다.
양방향 일대일(1:1) 관계
- 대상 테이블에 외래키가 있는 경우
단방향 일대일(1:1) 관계
- 주 테이블에 외래 키가 있는 경우
일대일(1:1) 식별 관계
식별관계에서는 외래 키에 @MapsId를 설정해 주어야 한다.
식별관계에서 외래키가 복합 기본키에 포함되는 경우에는 @MapsId(field이름)로 필드 이름과 맵핑을 해주어야 한다.
단방향 일대다(1:N) 관계
단점
- 다른 테이블에 외래 키가 있으면 연관관계 처리를 위해 추가적인 UPDATE 쿼리 실행
해결
- 단방향 일대다(1:N) 관계보다는 양방향 맵핑을 사용하자
Repository
Reposiotry의 정의
- 도메인 객체에 접근하는 컬렉션과 비슷한 인터페이스를 사용해 도메인과 데이터 맵핑 계층 사이를 중재(mediate)
주의할 점
- Repository는 JPA 개념이 아니고, Spring Framework가 제공해주는 것임
repository는 spring의 기능이다.
jpa repository를 만들기 위해서는 JpaRepository 인터페이스를 확장해야 하는데 제네릭의 첫 인자는 엔티티의 타입이고, 두 번째 인자는 기본 키의 타입을 적어주어야 한다.
Spring Data Repository
- data access layer 구현을 위해 반복해서 작성했던, 유사한 코드를 줄일 수 있는 추상화 제공
Spring Data Repository 추상화의 목표는 다음과 같다. 상용구 코드의 양을 크게 줄이기 위해 다양한 지속성 저장소에 대한 데이터 액세스 계층을 구현하는데 필요하다.
Repository interface Hierarchy
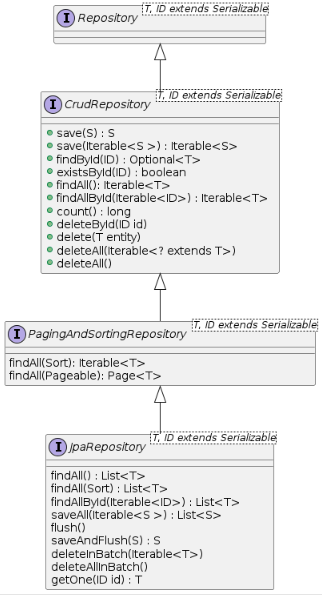
JpaRepository
- 웬만한 CRUD, Paging, Sorting 메서드 제공
@NoRepositoryBean
public interface JpaRepository<T, ID extends Serializable>
extends PagingAndSortingRepository<T, ID>, QueryByExampleExecutor<T> {
List<T> findAll();
List<T> findAll(Sort sort);
List<T> findAllById(Iterable<ID> ids);
<S extends T> List<S> save(Iterable<S> entities);
<S extends T> S saveAndFlush(S entity);
void deleteInBatch(Iterable<T> entities);
void deleteAllInBatch();
// ...
}
@NoRepositoryBean
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> {
Iterable<T> findAll(Sort sort);
Page<T> findAll(Pageable pageable);
}
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> saveAll(Iterable<S> entities);
Optional<T> findById(ID id);
boolean existsById(ID id);
long count();
void deleteById(ID id);
void delete(T entity);
void deleteAll(Iterable<? extends T> entities);
// ...
}여기서 @NoRepositoryBean은 Repository를 스캔할 때 어노테이션이 붙은 것은 제외하겠다는 의미이다.
JpaRepository가 제공하는 메서드들이 실제 수행하는 쿼리
// insert / update
<S extends T> S save(S entity);
// select * from Items where item_id = {id}
Optional<T> findById(ID id);
// select count(*) from Items;
long count();
// delete from Items where item_id = {id}
void deleteById(ID id);
// ...@Repository와 Spring Data Reposiotry의 차이점
@Repository
- org.springframework.stereotype.Repository
- Spring StereoTyppe annotation
- @Controller, @Service, @Repository, @Component, @Configuration
- @ComponentScan 설정에 따라 classpath scanning을 통해 빈 자동 감지 및 등록
- 다양한 데이터 액세스 기술마다 다른 예외 추상화 제공
- DataAccessException, PersistenceExceptionTranslator
Spring Data Repository
- org.springframework.data.repository
- @EnableJpaRepository 설정에 따라 Repository interface 자동 감지 및 동적으로 구현 생성해서 Bean으로 등록
- @NoRepositoryBean
- Spring Data Repository bean으로 등록하고 싶지 않은 중간 단계 interface에 적용
메서드 이름으로 쿼리 생성
- Spring Data JPA에서 제공하는 기능으로 이름 규칙에 맞춰 interface에 선언하면 쿼리 생성
예제
public interface ItemRepository {
// select * from Items where item_name like '{itemName}'
List<Item> findByItemNameLike(String itemName);
// select item_id from Items
// where item_name = '{itemName}'
// and price = {price} limit 1
boolean existsByItemNameAndPrice(String itemName, Long price);
// select count(*) from Items where item_name like '{itemName}'
int countByItemNameLike(String itemName);
// delete from Items where price between {price1} and {price2}
void deleteByPriceBetween(long price1, long price2);
}인터페이스로 선언해도 사용이 가능한 이유는 SimpleJpaRepository라는 JpaRepository 구현체를 spring data jpa에서 지원을 해주기 때문이다.
@Query
- JPQL 쿼리나 Native 쿼리를 직접 수행
@Query("select i from Item i where i.price > ?1")
List<Item> getItemsHavingPriceAtLeast(long price);
@Query(value = "select * from Items where price > ?1", nativeQuery = true)
List<Item> getItemsHavingPriceAtLeast2(long price);@Modifying
- @Query를 사용해서 직접 sql을 작성할 때 select문이 아닌 경우에는 @Modifying을 반드시 붙여줘야 한다. 안 붙이면 런타임에서 오류가 발생한다.
@Modifying
@Query("update Item i set i.itemName = :itemName where i.itemId = :itemId")
int updateItemName(@Param("itemId") Long itemId, @Param("itemName")String itemName);@Query 어노테이션에서 nativeQuery 속성을 기본값 false로 두면 JPQL로 실행이 되고 true로 주면 native query로 실행이 된다.
여기서 JPQL은 entity에 대해서 query를 수행하는 것이고, native query는 database를 기반으로 sql을 실행한다.
@Query 어노테이션에서 ?순서를 주지 않고 직접 주고 싶을때는 query안에서 :fieldName을 주고 parameter에서 @Param(fieldName)을 붙여주면 된다.
