1.introduction
promblm setting
x가 음성 , y가 sequence라고 하면 Y = argmax P(Y|X) 를 하는게 best이다.
하지만 x가 같은 음소라고 하더라도 사람에 따라 x의 값은 variation이 크기 때문에
P(Y|X) ∝ P(X|Y) x P(Y) (P(X)는 동일하게 주어지므로 생략)
이므로 = argmax(Y) P(X|Y)P(Y)
architecture
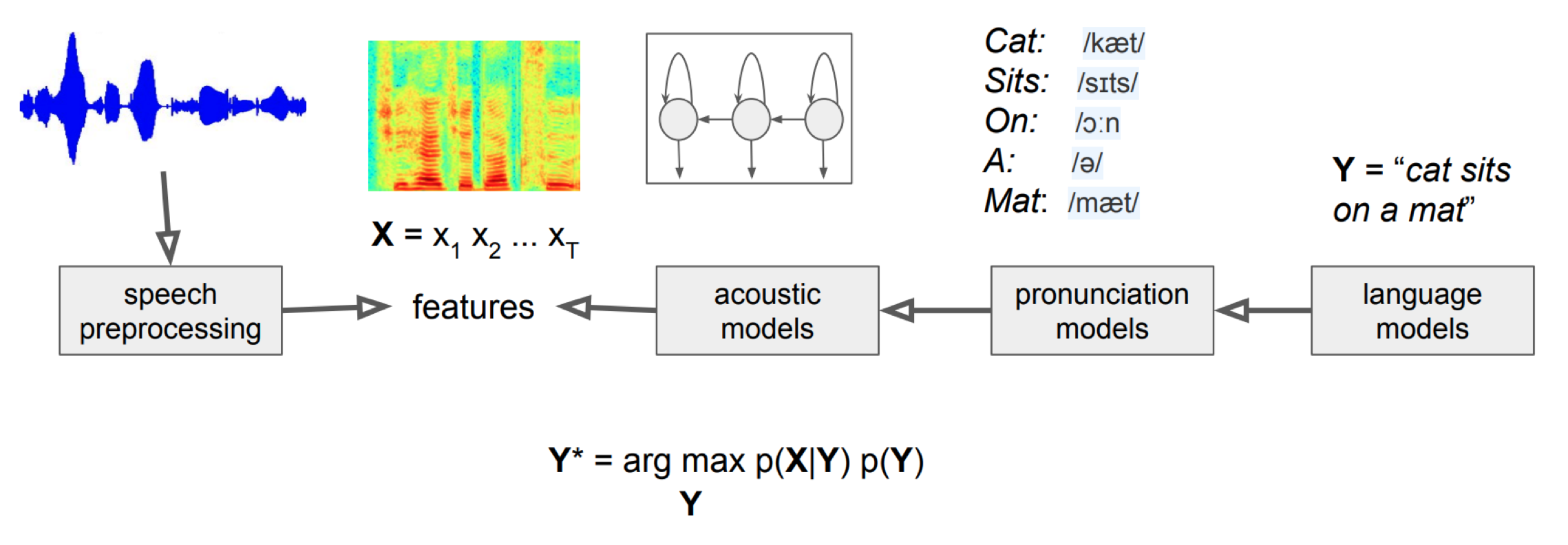
Y가 음소, X가 음성 신호면 Y는 Y에서 X 음성 신호의 확률을 최대화 하는 Y이다. 결국 음향 모델은 음성 신호와 음소의 관계를 표현한다.
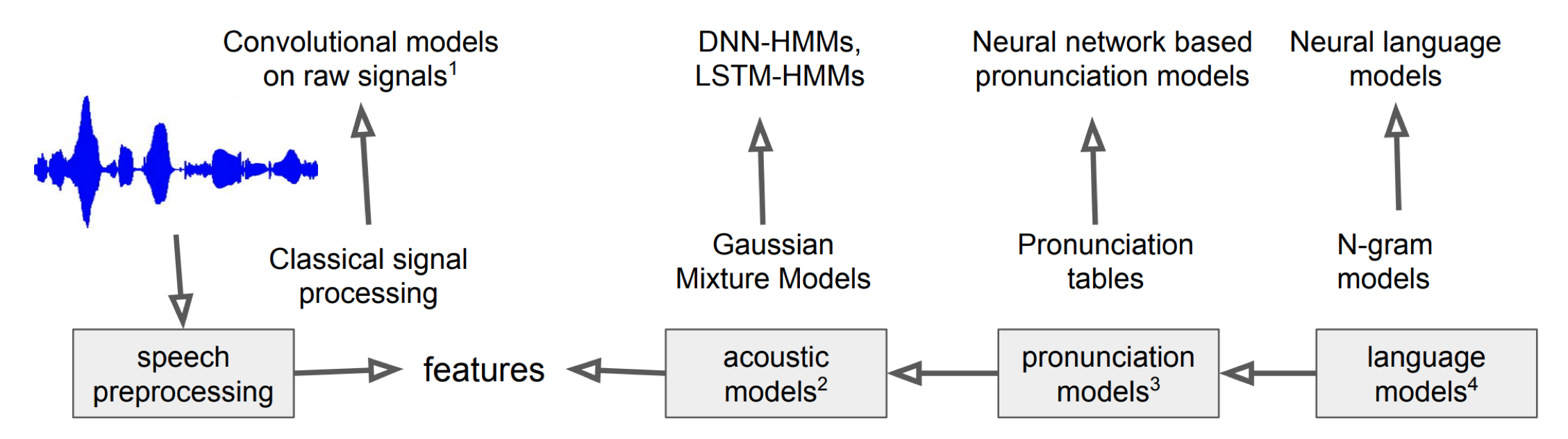
하지만 딥러닝의 발전으로 인해 요즘은 모든 component가 딥러닝으로 대체되고 P(Y|X)를 end to end 방식으로 인식하게 된다.
acoustic features
HMM+GMM으로 주로 사용하는 acoustic feature는 MFCCs이다. 이는 사람 말 소리를 부각시킨 특징이다. MFCCs는 다음과 같은 process를 가진다
audio →(framing,window..)→ chunks →(DFT)→ spectrum →(mel filter)→mel spectrum →(log,IDFT)→ MFCC
최근에는 stochastic하게 딥러닝 기반 feature를 추출하는 SINCNET이 있다.
2.Phonetics
음성학이란 , 말소리를 물리적인 관점에서 접근하는 학문이다. 특히 이 중 음향 음성학은 발음 기관의 특성에 따른 음파의 특성을 분석한다.
음운론은 머릿속에 있는 발음에 대한 지식을 분석하는 학문이다.
2-1.acoustic phonetics
wave
웨이브란 ? 반복적으로 진동하는 신호를 의미한다. 단일 여부에 따라 단순파 , 복합파가 있다.
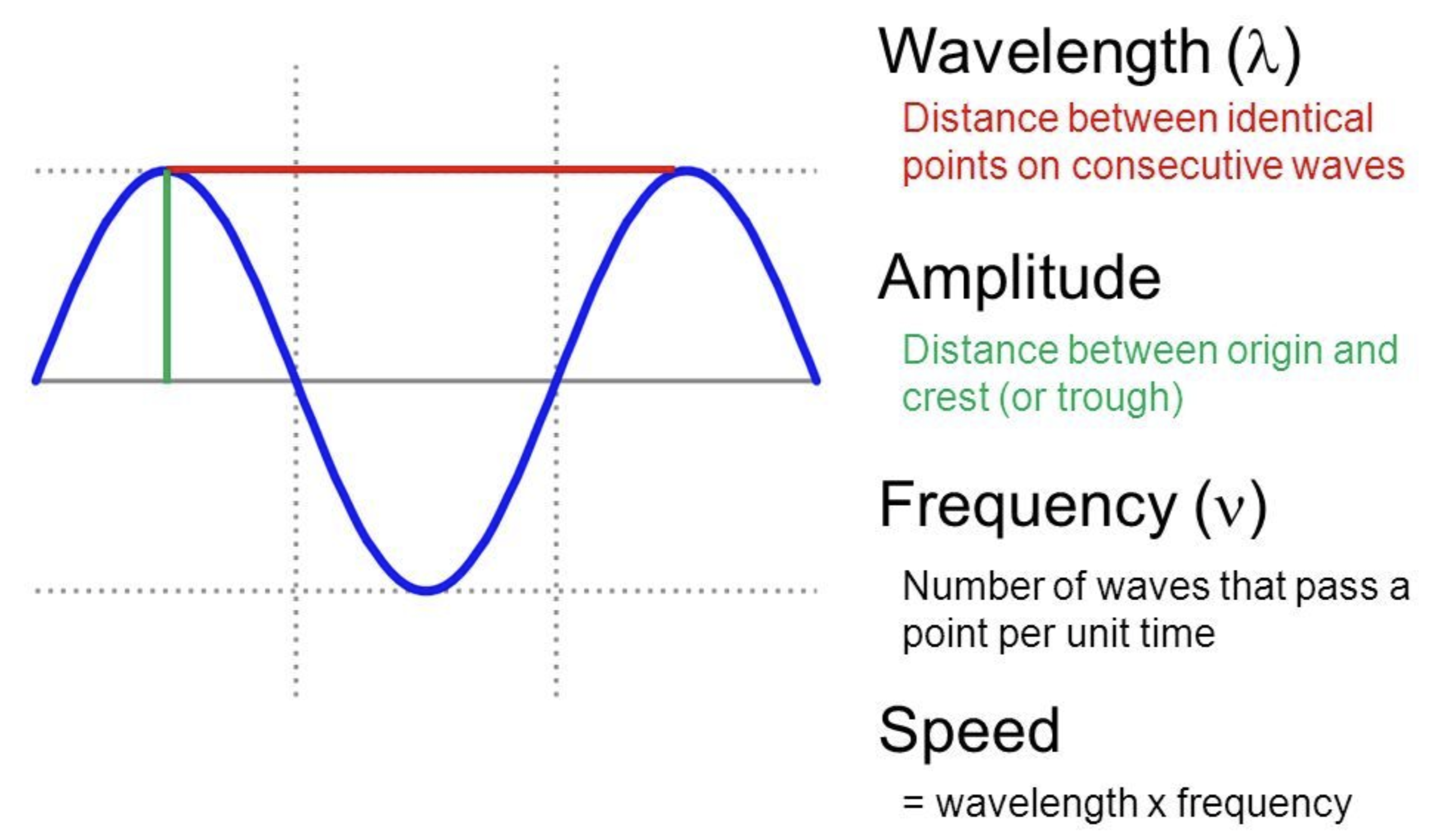
wavelength = 한 패턴이 지나가는 시간
frequency(주파수) = 1/wavelength
amplitude = 음압(진폭)
digitization
자연계에 존재하는 연속 신호를 이산 신호로 변환해야 한다
sampling rate는 1초에 몇 번 샘플링 할 것인가? 를 의미한다.
사람의 가청 주파수는 20~20000HZ인데 최대 주파수의 2배로 sampling하면 거의 모든 소리를 복원할 수 있다고 한다. 그래서 44100HZ를 많이 사용한다.
quantization
샘플링을 하였으면 이제 숫자로 변환하는 양자화를 진행해야 한다.
양자화 실시에 있어 자연 소리에 비해 noise가 손실되는 경향이 있는데 이를 최대한 줄이기 위해 압신_companding(압축 + 신장)기법을 사용한다
대표적으로 μ-law를 사용한다
여기서 μ는 로 정해진다 (n은 bit수)
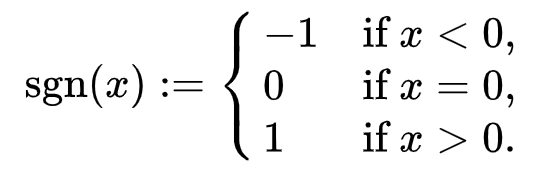
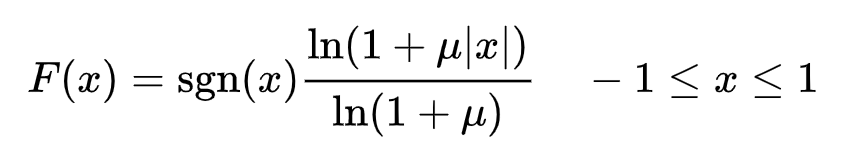
신호 x를 F(x)에다가 넣으면 해당 정수 값이 디지털 신호가 된다.
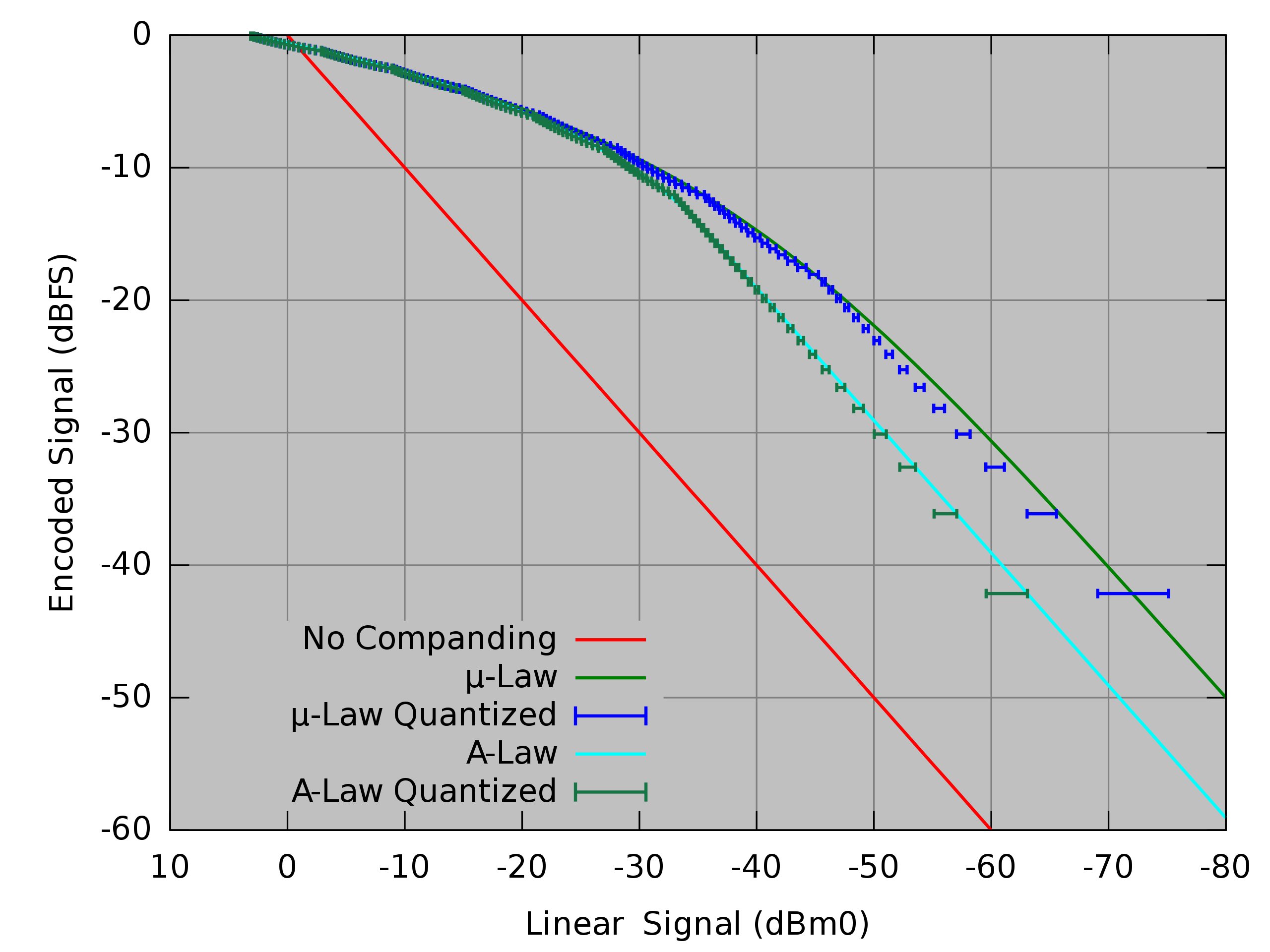
압신 기법을 쓰지 않는 것은 주파수에 따라 linear하게 양자화 되는데 , 압신 기법을 쓰면 낮은 주파수에 대해서 민감하게 값이 변하도록 exp scale로 양자화가 된다.
인코딩이란 이러한 일련의 과정으로 음성 신호를 디지털 신호로 변환,저장,압축하는 과정을 말한다.
Loudness
소리의 큰지/작은지를 나타내는 지표로 power와 관계가 있다. 또 이는 진폭과 큰 관계가 있다.
power는 다음과 같이 계산한다
power =
다만 power와 loudness가 linear하지 않고 log scale이다.
작은 주파수에 민감하게 반응하듯 , 작은 소리에 더 민감하게 반응한다.
loudness - 인식되는 소리 크기
amplitude - 물리적인 소리 크기
power - amplitude 제곱 합
energy - power 에다 주파수 곱한 것pitch
사람이 인식하는 톤은 저주파에서 민감하게 반응하는 log scale이다.
그래서 이를 도입해서 톤을 계산하는 것이 mel scale이다.
mel 값은 다음과 같이 구한다.
m=1127ln(1+700 * f)
vowels
보통 자음 보다는 모음이 좀 더 주파수가 높고 , 진폭이 크며 규칙적인 특성이 있다.
iy를 퓨리에 변환으로 나타내면 다음과 같다.
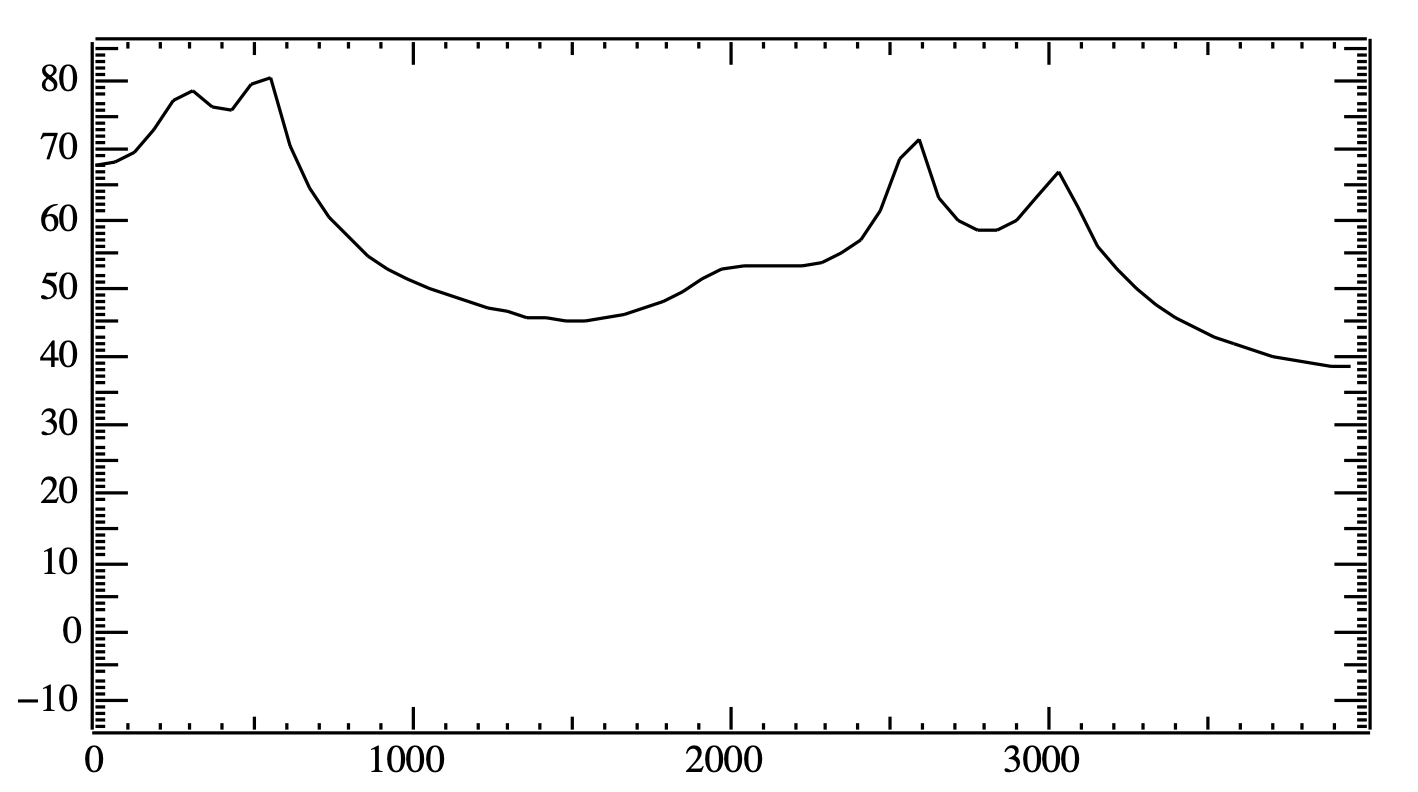
주파수 500,2500 순으로 음압이 가장 높다. 저렇게 솟아 있듯이 에너지가 몰린 부분을 포만트라고 한다. 모음이 가지는 포만트는 비슷하므로 , 포만트 부분을 보고 어떤 모음인지 추정할 수 있다. 모음은 언어의 핵이므로 이를 잘 캐치하기 위해 포만트를 잘 캐치하는게 중요하다.
한편 기본 주파수는 44khz로 , 여러 주파수 중에 최대 공약수이다. 이는 성문 (성대 사이의 틈)의 초당 진동수와 일치하다.
source filter model
모음이 생성되는 과정을 모델링한 모델.
사람의 목소리 느낌(음색)은 사람마다 다르지만 , 발음기관으로 부터 나오는 소리의 주파수는 거의 비슷하다.
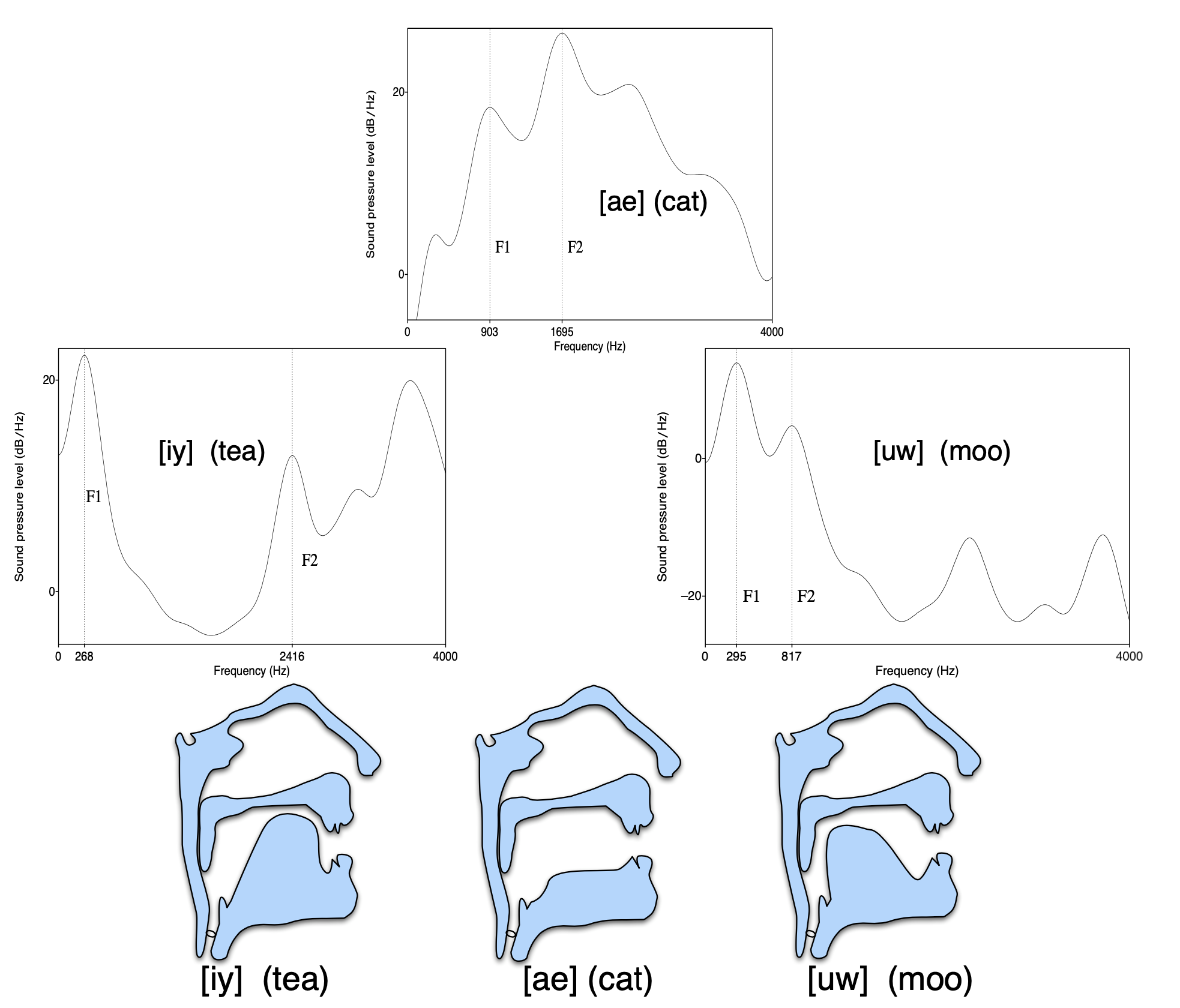
인간의 발음기관의 구조는 동일하기 때문에 누가 발음하든 스펙토그램은 비슷한 양상을 띈다. 이러한 발 별 포만트의 특징을 캐치해서 모델링한 것이다.
source(성대 or 성문)으로 부터 발생한 소리가 특정 기관(발음)을 지니면서 특정 주파수는 사라지고 , 다른건 살아남는데 이 과정을 공명이라하며 이렇게 포만트가 생성된다.
2-2 korean phonology
심리적이고 , 추상적인 말소리에 대한 특징,지식을 다루는 학문.
자음과 모음
말소리 생성과정
폐 -> 기도 -> 인두 -> 비강 또는 구강
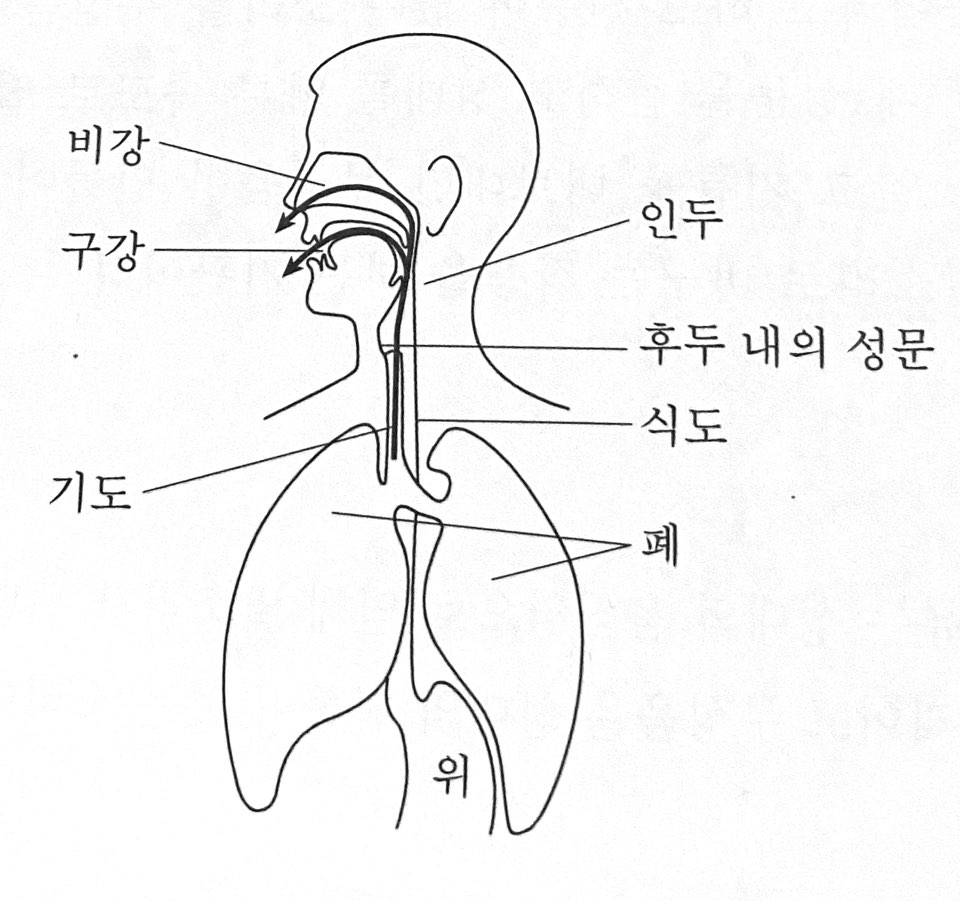
발성
복숭아 뼈라고 하는 '후두'에는 질긴 막인 성대가 있고 , 성대 사이에 공기가 통하는 틈새를 성문이라고 한다.
폐에서 나오는 공기인 '기류'는 성문을 통과하며 '말소리'가 된다.
성문의 넓고 좁음에 따라 진동의 속도가 다르다. 진동이 빠르면 유성음 / 진동하지 않고 공기가 통과하면 무성음이 된다 .
공명강
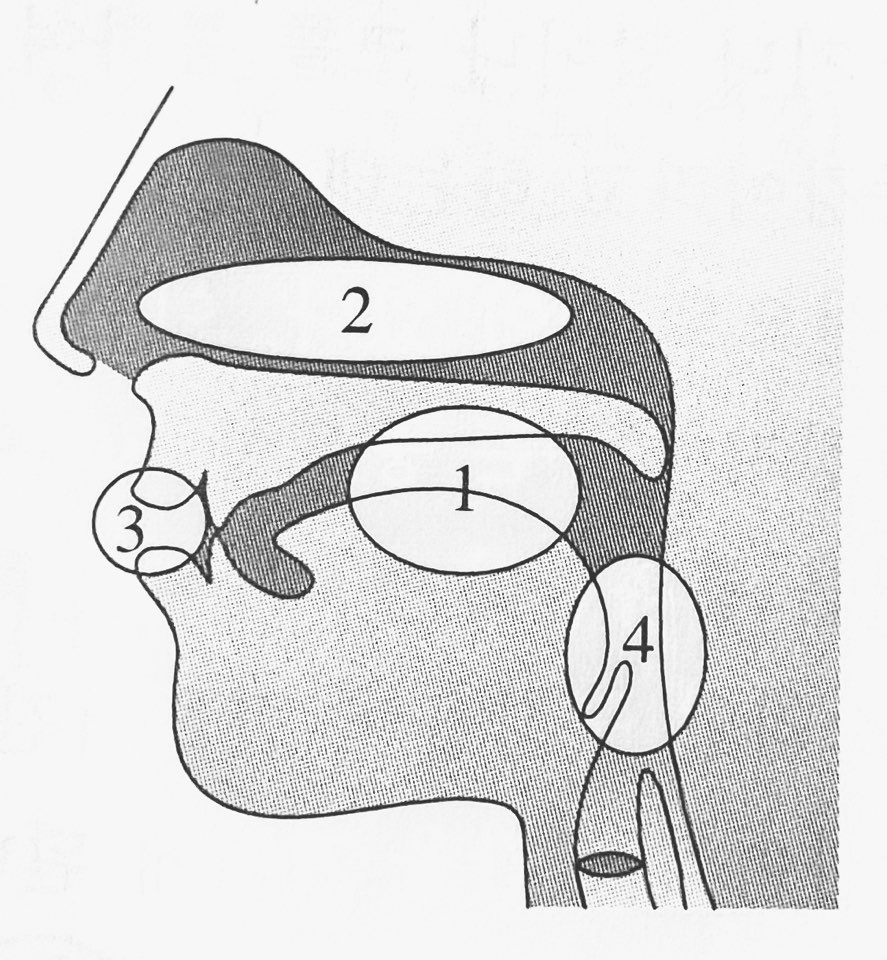
후두를 통과하면 구강,비강,순강,인두강으로 가서 이 4가지가 진동함으로 공명이 된다. 이 4가지가 공명을 결정하므로 공명강이라 불린다. 혀와 입술의 조치에 따라 공명강의 크기/모양이 결정된다.
조음기관
조음기관의 움직임에 따라 공명강의 크기,모양이 달라져서 소리를 조절할 수 있다.
조음 기관으로는 입술,치조,경구개,연구개,혀(혀끝, 혓날 , 전설 , 후설 , 혀뿌리),목젖 , 성문으로 나뉜다.
자음
자음은 조음기관에서 기류의 흐름에 방해가 되면 만들어진다.
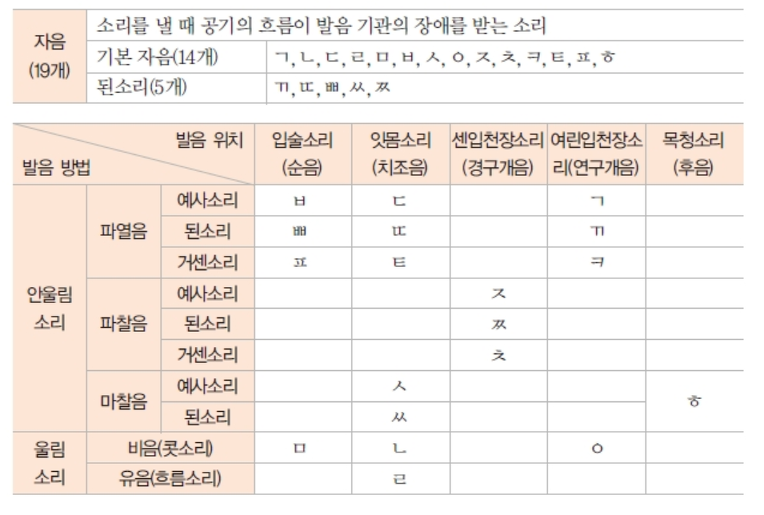
파열음 - 기류를 막았다가 터뜨리는 음
파찰음 - 파열과 마찰이 동시에 일어나는 음
마찰음 - 조음 기관의 통로를 아주 좁혀서 마찰로 소리 내는 음
비음 - 기류가 비강으로 흐르는 자음
유음 - 물흐르는 나오는 자음
모음
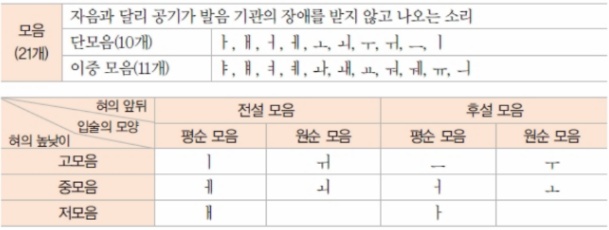
혀의 앞뒤 위치에 따라 다음과 같이 분류 가능하다.
고,중,저,전,후
원순 - 입술을 동그랗게 하고 나오는 음
평순 - 입술이 평평하게 하고 나오는 음
2-2. phonemes & syllables
음소
말을 구분하는 최소 단위를 음소라고 한다
불이 났다 vs 뿔이 났다
에서 ㅂ,ㅃ의 사용에 따라 뜻이 완전히 달라진다.
음소의 단위는 언어 마다 다르다
변이음
음소의 변화를 알아차리지 못하는 음
ex) 밥 -> 파열 / 비파열
감기 -> k / g
음운 자질
음절
음성 언어에서 발화될 수 있는 최소 단위.
음소 - ㄱ , ㄴ , ㄷ , ㅈ
음절 - 집 , 강
음절은 화자 머릿속에 확고히 있다.
운소
단어를 구분하는데 음소 외에 운율적 특징 ex)음장
2-3. pronunciation & variation
기저형과 표면형
형태소 - 의미를 가지고 있는 최소 단위
말소리의 변화
변화 - 시간에 따라 말소리가 달라지는 현상
변동 - 연결되는 말에 따라서 소리가 달라지는 현상
ex) 닭날개
변동에는 대치 , 탈락 , 첨가 , 축약이 있다
대치
한 소리가 다른 소리로 바뀌는 것
평폐쇄음화 - 평폐쇄음이 아닌 것이 평폐쇄음 (ㄱ,ㄷ,ㅂ)로 바뀌는 것
ex) 앞 -> 압
경음화 - 경음이 아닌 소리가 경음으로 대치되는 현상
ex) 국밥 -> 국빱
치조비음화 - ㄹ가 ㄴ으로 변하는 현상
ex) 십리 ->심니
유음화 - 유음이 아닌 소리가 유음으로 대치되는 현상
ex) 칼날 -> 칼랄
비음화 - 비음이 아닌 소리가 비음 앞에서 비음으로 바뀌는 현상
ex) 국물 -> 궁물
양순음화 - 뒤에 오는 양순음의 영향으로 앞에 있는 치조음이 양순음으로 대치되는 현상
ex) 기분만 -> 기붐만
연구개음화 - 뒤에 오는 연구개음의 영향을 받아 ㄴ,ㅁ가 ㅇ 으로 ㄷ,ㅂ가 ㄱ 으로 대치되는 현상
ex) 신고 -> 싱꼬
구개음화 - 치조음 (ㄷ,ㄸ,ㄹ)가 ㅣ or j 앞에서 ㅈ,ㅉ,ㅊ로 변하는 현상
ex) 읻지 -> 잊찌
움라우트 - 뒤에 있는 ㅣ,j에 의해 후설모음인 ㅏㅓㅗㅜㅡ가 애어외위이가 되는 현상
ex) 아기 -> 애기
모음조화 -
활음화 - 단모음이 활음으로 바뀌는 현상
ex) 비어 -> 겨
탈락
원래 있던 소리가 삭제되는 현상
자음군 단순화 - 두 자음으로 이루어진게 단순해지는 현상
ex) 앉다 -> 안따
ㅎ 탈락 - 공명음과 모음 사이에 ㅎ가 사라지는 현상
ex) 놓아 -> 노아
동모음 탈락 - 어간 말을 ㅏㅓ가 어미 ㅏㅓ 앞에서 탈락
ex) 가아 -> 가
활음 탈락 - 이중모음 구성하는 활음이 삭제되는 현상
ex) 지어 -> 져 -> 저
첨가
없던 소리가 삽입되는 현상
ㄴ 첨가 - 자음과 ㅣ or j의 어휘 형태소와 연결되는 ㄴ으로 변하는 현상
ex)솜이블 - 솜니불
활음 첨가 - 특정 모음 사이에 활음이 첨가됨
ex) 피어 - 펴
축약
둘 이상의 소리가 합쳐져 새로운 소리가 되는 현상
놓고 -> 노코
않던 -> 안턴
2-4 recognition by human
사람은 말소리를 단어 단위(lexicon based)로 인식한다. 그 특성 중에는 3가지가 있다
frequency - 빈도 높은 소리를 빨리 알아차림
parallelism - 여러 단어를 한번에 들을 수 있다.
cue-based processing - 음성 인식은 다양한 단서에 기반한다.
음성인식의 기반이 될 수 있는 근거는 다음과 같다.
포만트 - 스펙트럼에서 음향 진동수가 몰려 있는 봉우리
성대진동 개시 시간 - 유성 자음 (ㅂ) , 무성 자음(ㅍ)의 구분 가능
음소 복원 현상 - 해당 단어를 알기에 단어 하나를 기침으로 대체해도 알아들음
시각적 단서 - 입모양 등..
반복 점화 - 반복되는 자극이 뇌에서 빨리 처리되는 현상
인간은 언어를 듣고 segment , parsing , interpretation을 순식간에 하는데 이를 on line processing 이라고 한다.
3.Feature extraction
3-1 퓨리에 변환
discrete fourier transform (DFT)
이산 퓨리에 변환은 시간 도메인의 음성 신호를 주파수 도메인의 음성 신호로 변환하는 과정이다.

수식1은 N개 중 K번째 주파수를 N개의 시간 값으로 분해한 것이다. 역으로 주파수에 대한 값으로 n번째 시간의 값을 나타낸 것이 수식2 이다.
주파수가 K/N일때 x1 , ... , xn의 무게 중심이 Xk이다.
DFT Matrix
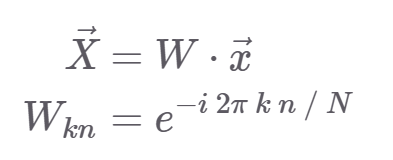
W가 k x n 의 size라고 할 때
k번째 주파수 값 Xk는 다음과 첫번째 식과 같이 나타낼 수 있다.
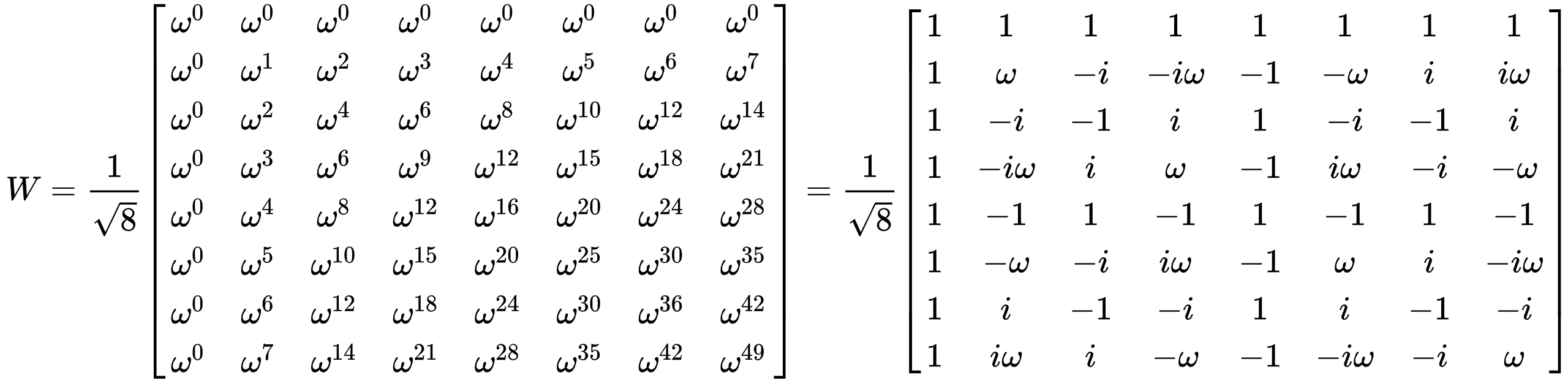
이렇게 W를 시간에 대한 값 x에다 곱해서 주파수의 값으로 변환할 수 있다.
고속 퓨리에 변환은 이산 퓨리에 변환에서 복소수 부분을 실수 부분으로 계산해 계산을 더 효율적으로 한 것이다.
3-2 MFCCs
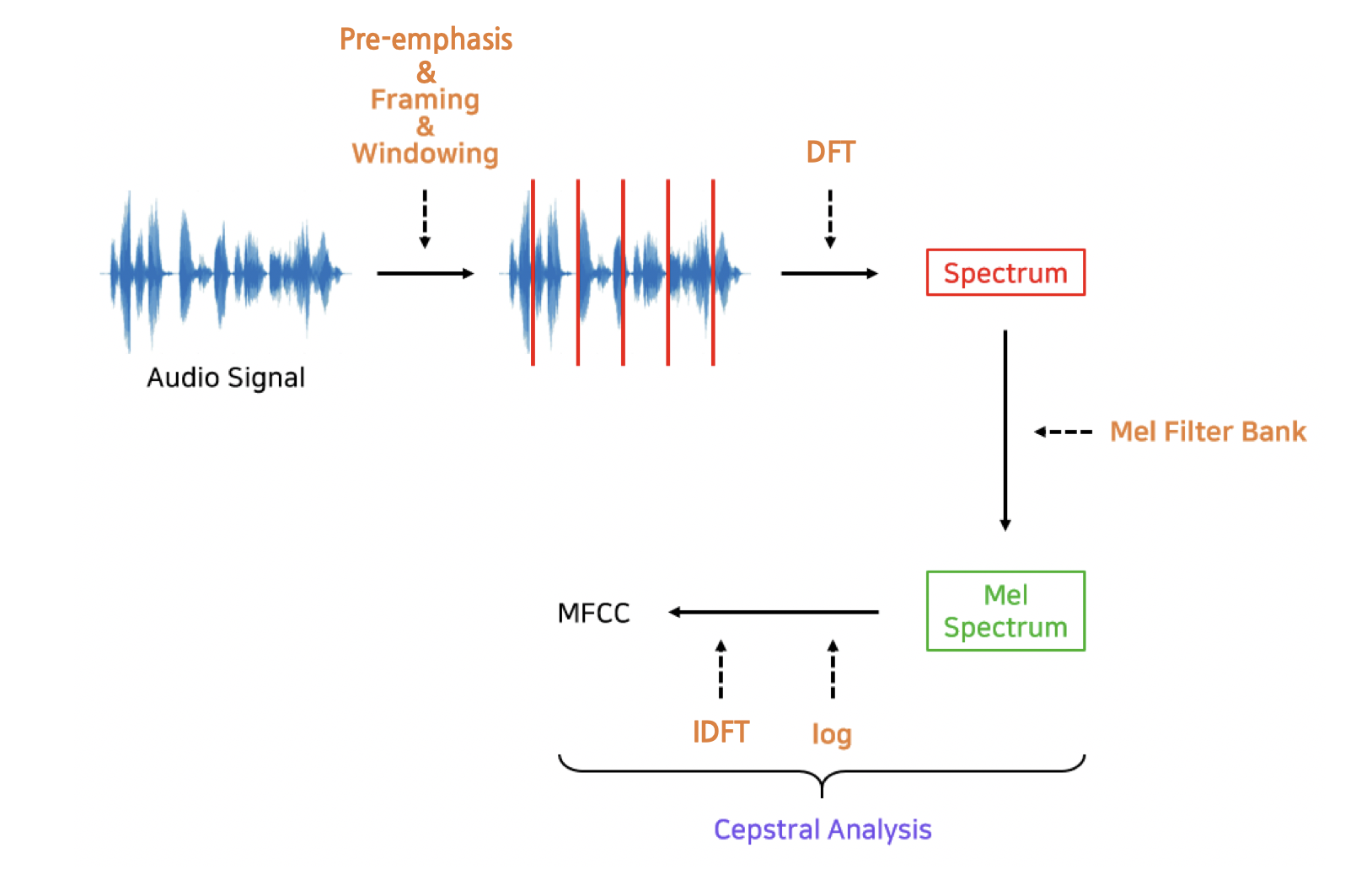
MFCC는 불필요한 정보는 버리고 중요한 특질만 남긴 feature이다.
입력 음성을 25ms 정도로 나누는데 , 이 단위를 프레임이라고 한다. 각 프레임 별로 퓨리에 변환을 수행해서 주파수 정보를 추출한다. 모든 프레임에 퓨리에 변환 한 것을 스펙트럼이라고 한다.
여기다 로그,멜 scale 적용한 것이 로그 멜 스펙토그램이다.
이에 역 푸리에변환을 적용해서 새로운 시간 도메인으로 변환한게 MFCC이다.
Raw Wave Signal
wav file을 sampling rate를 적용해서 샘플링 한다.
그렇게 디지털 신호로 변환한다
preemphasis
사람의 말소리를 스펙트럼으로 변환하면 저주파에 좀 더 에너지가 몰려있다. 이를 고려해서 고주파의 에너지를 올려주는게 필요하다. 이를 preemphasis라고 한다.
이로써 모든 주파수에서 고른 분포를 갖게 한다
Framing
음성 신호는 매우 빠르게 변화하느 non-stationary한 특성을 갖고 있다.
데이터를 변환하기 위해 stationary 한 특성으로 바꾸어 주어야 하는데
짧은 시간 동안을 stationary로 변환하는 것을 framing이라고 한다.
보통 25ms 단위로 이루어지고 음성이 뚝 끊기지 않게 일정 시간 (10ms)를 겹치게 한다
question.
framing을 일부 겹치게하면 그만큼 소리 길이가 짧아지는건가?
question2.
rectangular window를 사용하면 양끝 신호가 죽는다 하는데 그냥 rectangle 이어 붙이면 연속적인거 아닌가..?
window
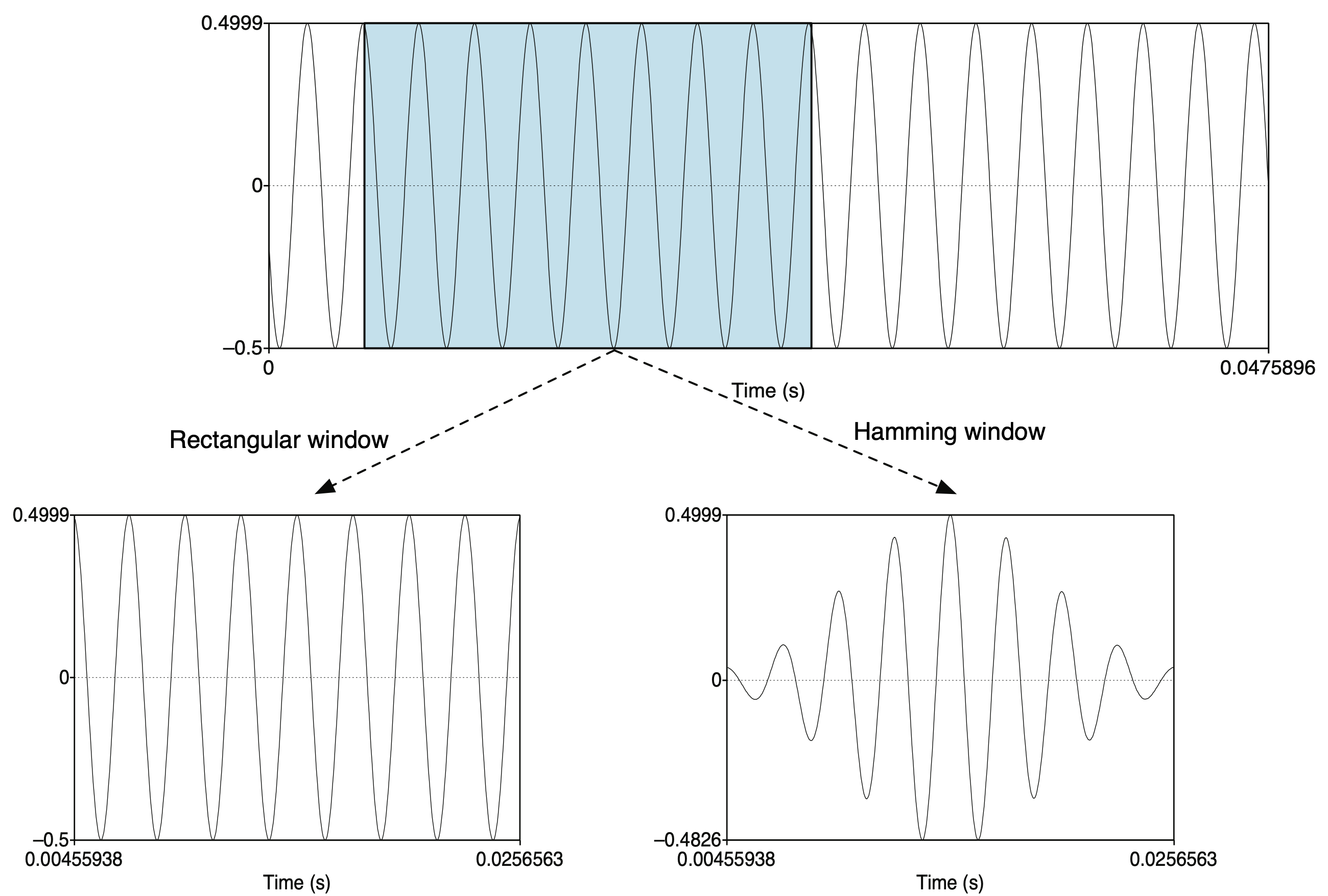
직사각형으로 framing을 하면 소리가 뚝 끊기는 현상이 있어서 hamming 윈도우를 적용하여 프레임 내에 양 끝은 0에 가까운 값을 , 중앙은 1에 가까운 값을 곱해주어서 오른쪽 그림과 같이 한 프레임내의 신호는 smooth 하게 된다.
Fourer Transform
시간 도메인을 주파수 도메인으로 변환하는 작업
이산 퓨리에 변환은 음의 주파수 , 양의 주파수에 대하여 대칭이다. 이런 대칭인 주파수에 대하여 한 번만 연산하는 것이 고속 퓨리에 변환이다.
NFFT = 512
dft_frames = np.fft.rfft(frames, NFFT)
NFFT는 프레임을 몇 개의 주파수 구간으로 나누냐를 결정한다 보통 256,512를 사용한다
magnitude
파형의 강도 정도를 나타내기에 퓨리에 변환 전 복소 좌표의 제곱 합이다.
Power Spectrum

power도 마찬가지로 파형의 강도를 나타낸다.
따라서 magnitude의 제곱.
filter bank
사람의 청각은 낮은 소리에 민감하기에 주파수에 대하여 mel scale을 적용한다.
퓨리에 변환을 n x 256 으로 나타냈다면 , 이에 대해서 filter를 적용하여 차원을 더욱 낮춘다. 저주파에서 더 민감하게 적용하는 mel scale filter (nfilt) 40여개를 가지고 적용한다. 1 x 256차원의 주파수를 40개의 필터에 대해 좌표로 나타낸다. 이는 고유값 분해에서 고유 값에 해당하는 좌표와 비슷한 원리이다.(내적의 결과라는 점에서 다르지만) 각각의 필터를 저주파,고주파 등을 담당하는 역할이 따로 있다.
log mel spectrum
사람의 소리 인식은 로그 스케일에 가깝기에 filter bank에다가 log scale을 또 적용한다.
그래서 그 필터 뱅크에 log scale을 적용하여 낮은 주파수에 더 민감하게 값이 반응하게 적용한 것이 log mel spectrum이다.
MFCCs
log mel spectrum에 역 퓨리에 변환을 실시하여 변수간 상관관계를 해소한 것이 MFCC이다.
이해 X .. 역퓨리에 변환을 하는데 왜 상관관계가 해소되지?
MFCC는 구축과정에서 버리는 정보가 많으니 log mel spectrum이 많이 쓰인다.
post procesing
normalization 등 post processing도 한다.
