RRHF: Rank Responses to Align Language Models with Human Feedback without tears
introduction
PPO로 인해 많은 RLHF 발전 이루었지만 하이퍼파라미터에 매우 민감하다. 또한 모델 용량도 많이 들고 시간도 오래 걸린다
그래서 우리는 RRHF를 제안한다. 이는 rank loss에 의해서 사람의 선호도에 따라 다양한 답변을 align하고 성능을 보존한다. 훈련 전에 RRHF는 다양한 source(다른 LLM, self , human response 등)로부터 답변을 모은다. 그 다음 다양한 답변을 training model의 log probability를 기반으로 평가한다. 그 다음 점수는 사람 선호에 대한 reward model이나 ranking loss에 의해서 align된다. 우리는 절대적 점수 대신 ranking을 선택한다.
~~
RRHF는 ref 모델도 필요 없다.
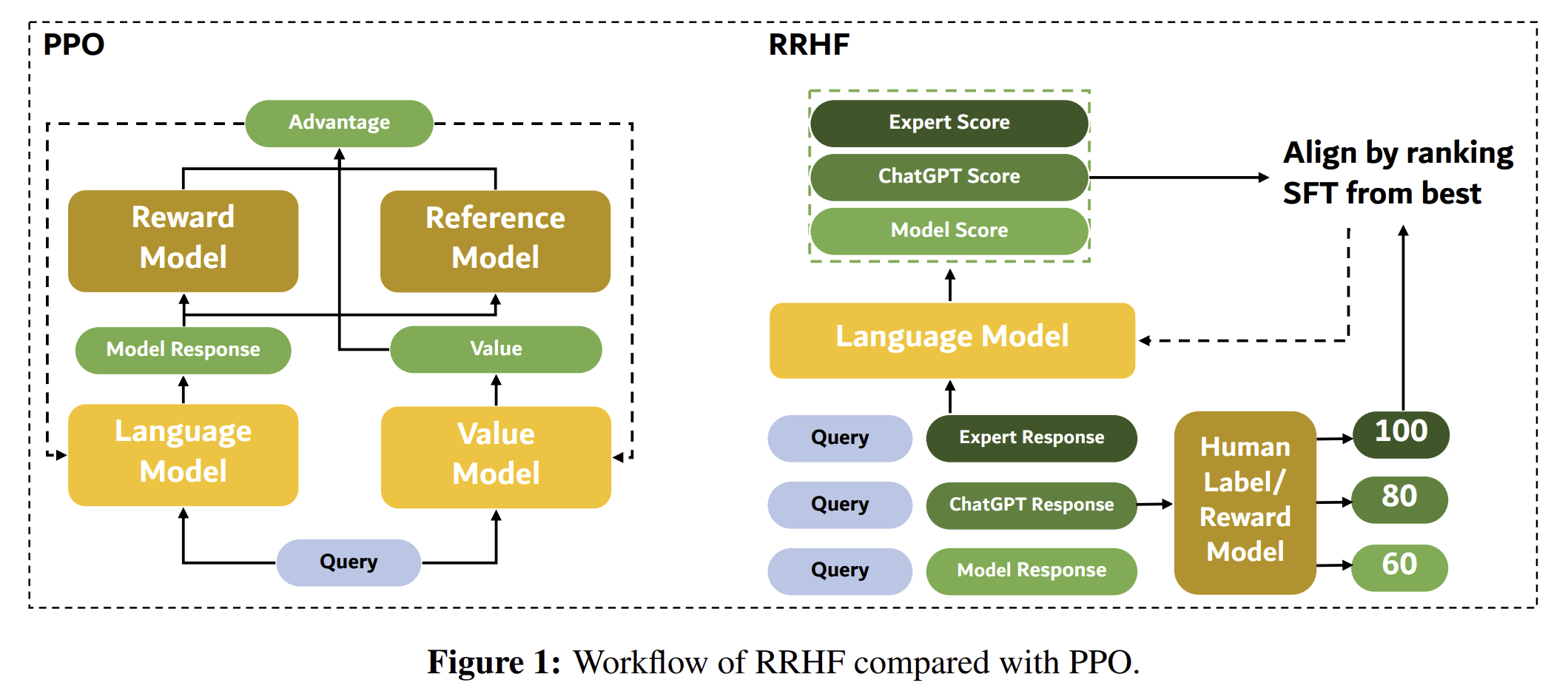
PPO와 RRHF 비교는 다음과 같다.
... 어렵ㄷ
method
우리의 목적은 어떤 reward function (trained or human)의 이익을 극대화하는 output을 출력하는 것이다.
RRHF
존재하는 다양한 source로부터 query에 대한 response를 샘플링한다. 우리의 샘플링 method는 한 모델이 아닌 human align하는데 도움이 되는 다양한 답변을 활용한다.
reward function이 있다면 이는 답변 y에 대한 score를 주는데, 이와 align하기 위해서 우리는 다음의 방법을 쓴다.
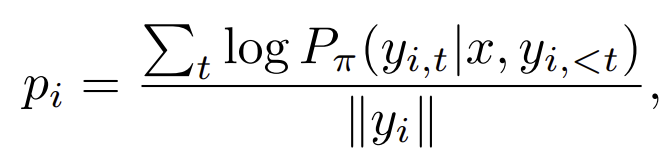
결국 이는 길이의 penalty를 한 y_i가 나올 확률이다.
아이디어는 다음과 같다. 모델이 좋은 답변을 위해서는 더 높은 확률을 , 안좋은 답변을 위해서는 더 낮은 확률을 갖고 있다는 가정.
그렇다면 loss는 다음과 같다.
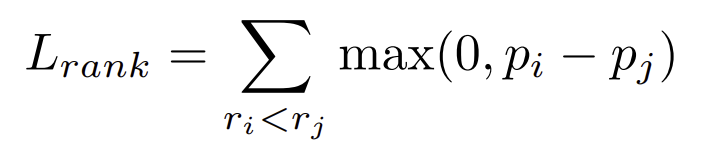
거기에 cross entropy 를 적용하는데 가장 높은 r을 사용한다